
题图来自视觉中国
2000年5月,上海第一家星巴克落户淮海路力宝广场,虽然这并不是星巴克在中国的第一家店,但在随后的20多年里,上海迅速成为全球星巴克门店最多的城市,现在几乎是曾经排名第一的城市——韩国首尔的2倍。
2014年,首尔284家,上海273家。这是首尔最后一次成为全球星巴克最多的城市。
2015年,首尔312家,上海365家。上海超过首尔,至今仍不断刷新着星巴克城市规模的新纪录。
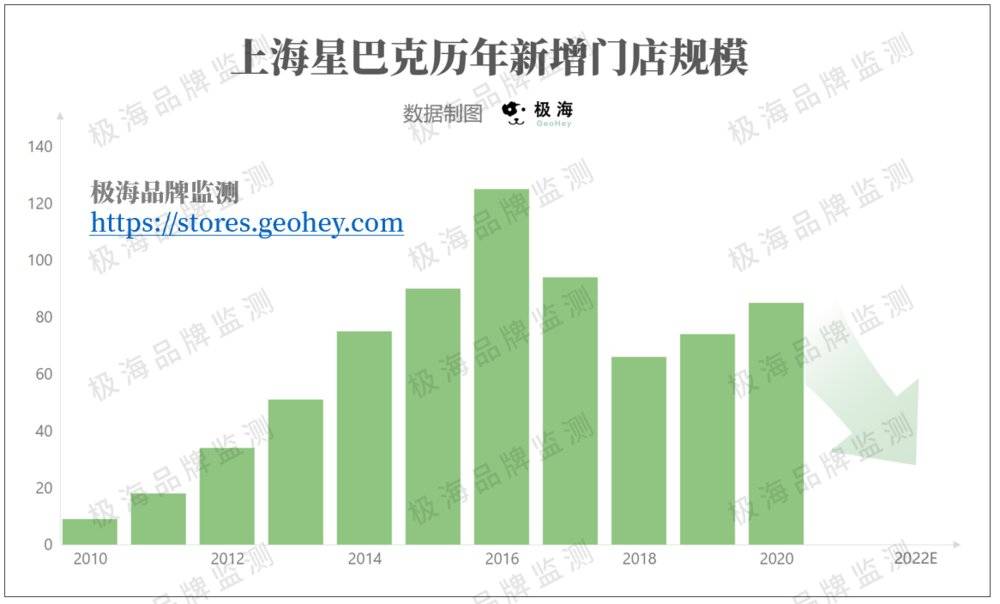
截至目前,上海已有884家星巴克在营,但我们几乎从曲线上看不到任何减速的迹象,反而是越开越快。根据极海品牌监控的数据,仅2020年,上海就新增了86家星巴克,好像这样的增长是没有尽头的。
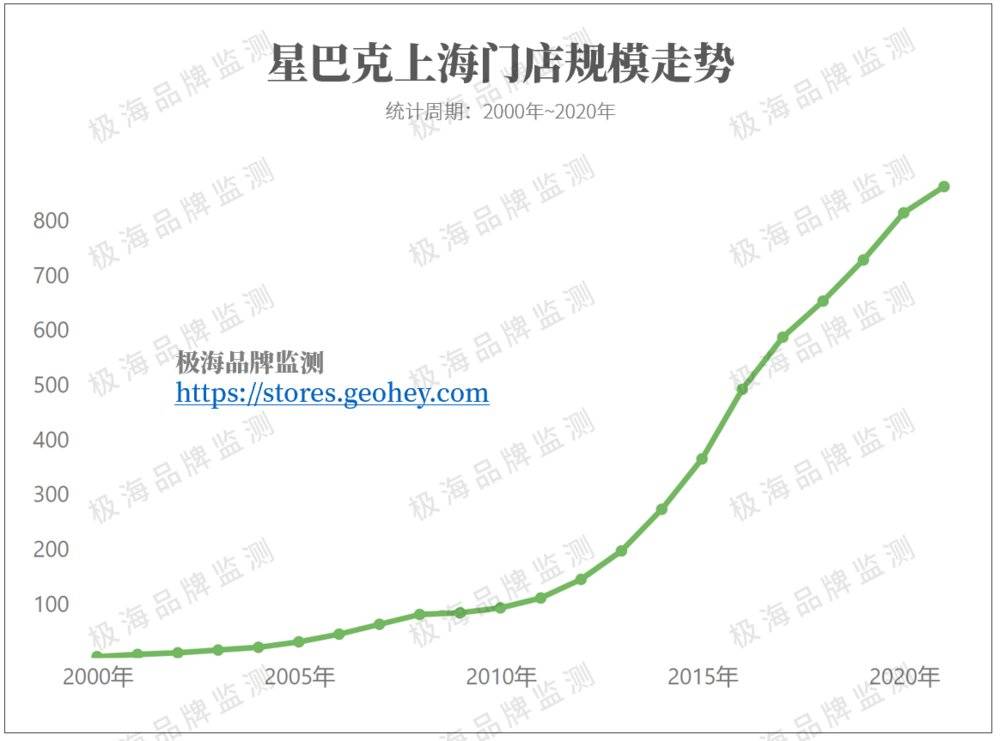
数据来源:极海品牌监控
上海的星巴克饱和了吗?
真的没有尽头吗?这在投资市场是一个严肃的问题。
规模预测是投资决策中的关键一环,尤其是中后期项目。这一阶段,品牌已经用财务数据论证了单店盈利的可行性,跨过了从0到1的“惊险一跃”,后期的估值主要落在了规模的增长上,因此如何更好的预测品牌未来发展规模尤为关键。
传统研究方法主要从“需求端”和“供给端”对市场进行拆解分析,优点是逻辑简单直接,缺点是数据获取困难且信度存疑。
以最基础的人口数据为例,首尔都市圈人口2300万门店517家,上海人口2400万门店884家,是什么导致了门店数量的巨大差异呢?其中必然要用到更加精细的人群画像标签,但人口数据不会直接告诉你有多少人喝咖啡,喝多少咖啡,喝什么咖啡,关联性人口标签质量往往也很难达到预期,很可能连目标人群规模都难以达成共识。
但门店规模的预测又有其特殊性:一个城市的地理空间是有限的,满足选址条件的地段是稀缺的,门店之间的距离也是有极限的,不可能无限加密,借助城市大数据,我们至少可以预测其中短期门店规模的天花板,从而判断品牌潜在的增长空间和方向。
上海的星巴克都开在哪了?
要预测规模,我们首先要把这个城市能开店的地方都找出来。
在极海规模预测系列的上一篇文章《如何预测下一家喜茶开在哪里?》中,我们用 “共生品牌” 策略为品牌方提供了一种挖掘潜在选址点的算法,本文将从投资者的视角,将这一算法运用到城市门店规模上限的预测中去。
我们把门店分布具有较强一致性,在一定范围内同时出现的概率较高,在选址策略趋于一致的品牌称为“共生品牌”。共生品牌的本质是拥有类似客群的品牌最终也会在位置上趋同,就像麦当劳和肯德基的关系一样。
依托我们在地理空间算法和城市大数据上的积累,我们将上海的星巴克咖啡依次与品牌库里的500+连锁品牌的地理位置进行关联性计算,得到其关联强度的排序如下:
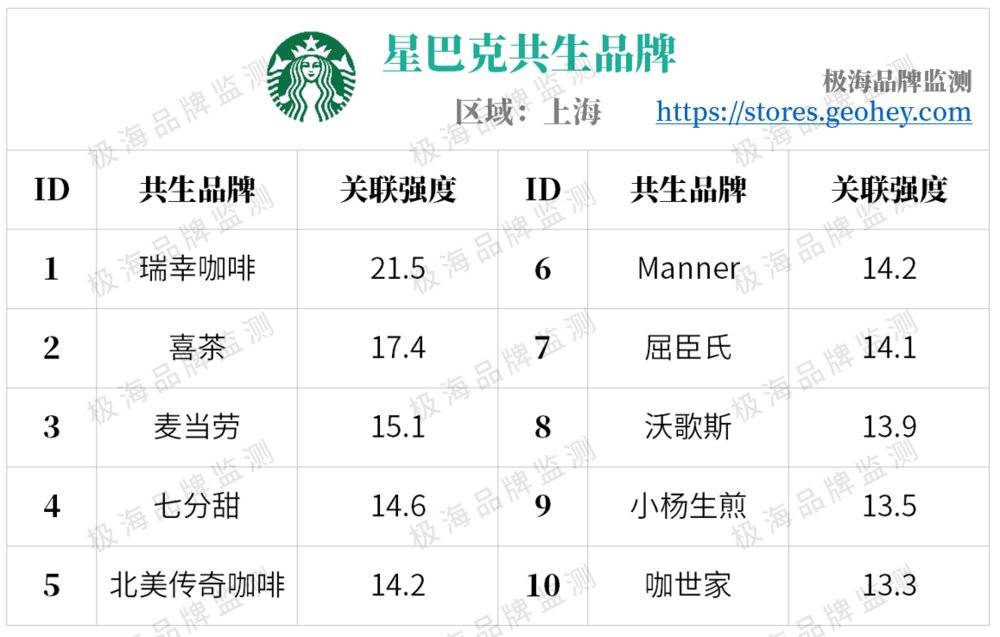
*受篇幅限制,仅显示关联度具有统计学意义的前十个品牌。
我们根据共生品牌的位置分布和关联度为基础,在地图上加权赋值生成潜在选址点的热力图,并根据热力值圈出了424个聚客区。
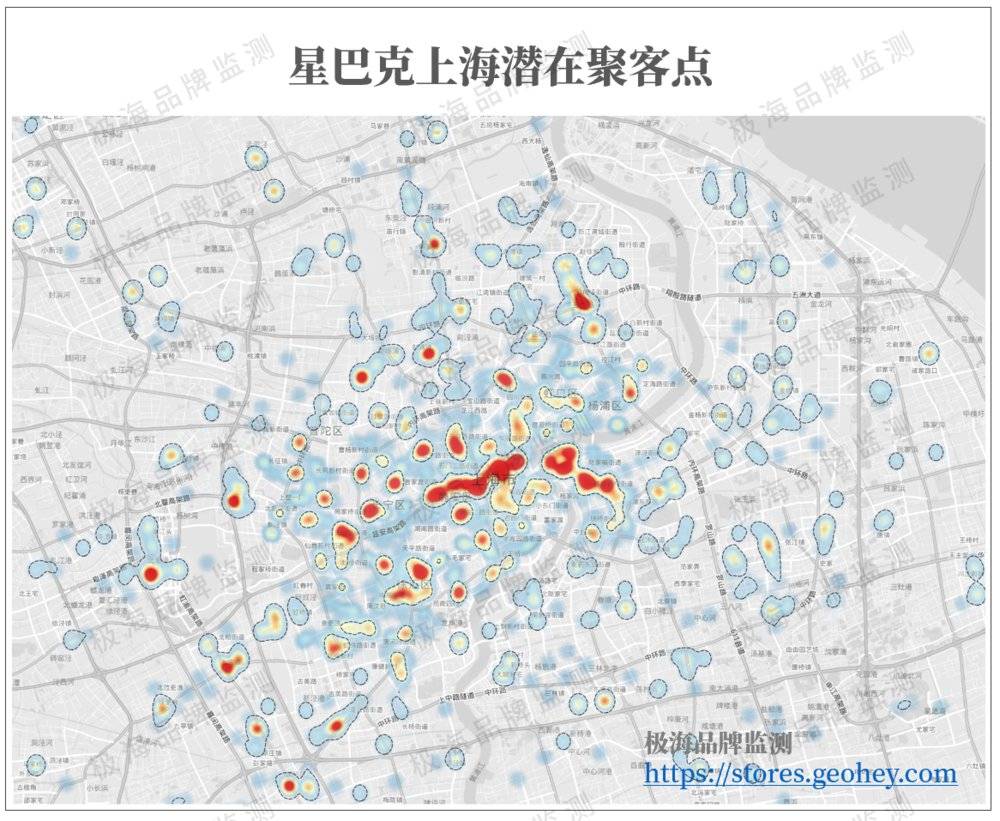
85%的星巴克在营门店都落在了我们标识的聚客区上,虽然我们可以通过扩大边界囊括更多的点,但这也会让聚客区显得过于宽泛,失去实际意义。在实际的应用中,80%以上的预测率都属于可接受的范围。
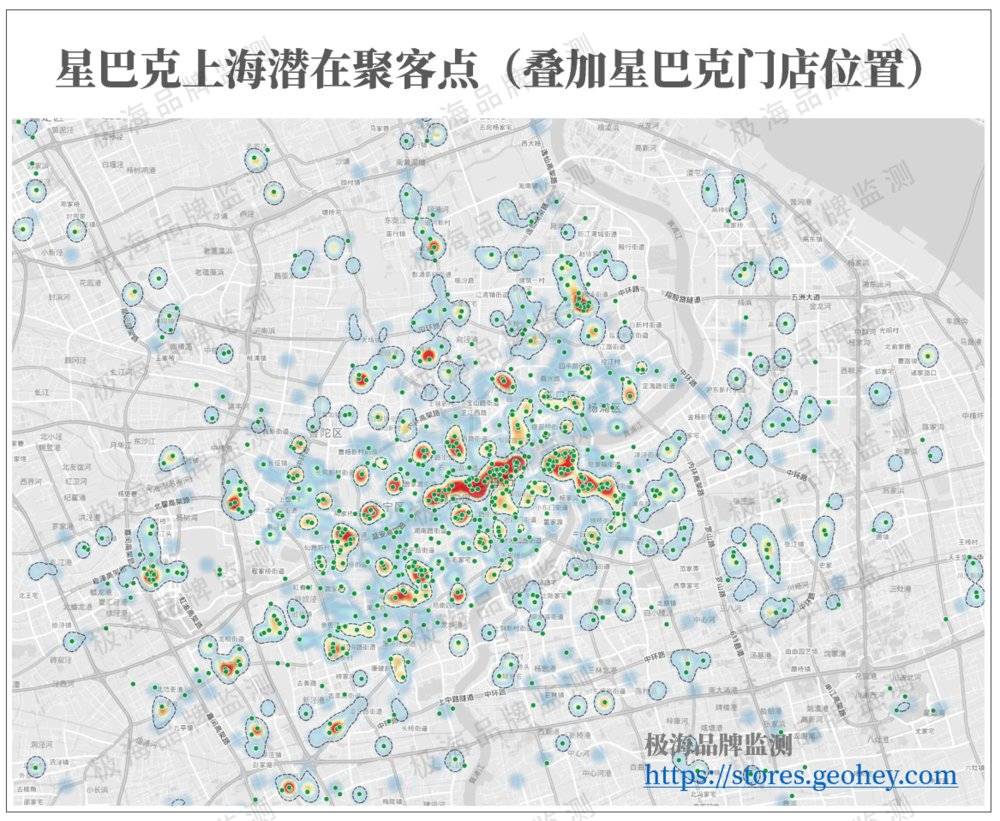
*绿色点星巴克实际门店位置,虚线框为预测的聚客区域。
这里需要额外注意的是,投资者和品牌方在选址上的思维路径有所不同,需要区别对待。
对品牌方而言,他们需要跑十几点位才能确定一个选址,所以可以接受尽可能多的预测。但投资人往往没有机会一个个点位去核实,所以必须要设定一些的规则,对这些聚客区进行筛选。
常用的筛选规则主要包含以下几类:
(1)聚客区成熟度。根据聚客区的商业成熟度对其进行分级,排除成熟度较低的聚客区。
(2)品牌门店特性。根据品牌门店对租金、面积、物业条件、所处位置的特殊需求,通过叠加相关要素图层,排除不符合品牌选址逻辑的聚客区。
(3)聚客区竞争度。根据聚客区的竞品分布对其进行分级,避免品牌门店进入优势品牌聚集、竞争压力过大的区域。
星巴克门店对物业本身的要求并不高,且处于咖啡茶饮行业的第一梯队,我们使用共生品牌的数量及关联强度综合衡量聚客区的成熟度,排除掉部分质量较差的聚客区后,剩余的253个聚客区仍能覆盖80%的现有门店,筛选后的模型仍具有较强的预测性。
上海的星巴克到底有多密?
现在我们已经知道了星巴克门店的潜在选址范围,决定规模的关键就在于他在这些地方还能开多密。
一个聚客区对应的不一定是一家门店,一些商业发达的城市核心聚客区往往会连成一片,拥有多家星巴克。在上海,最大的一个聚客区上就分布了59家门店。
我们将这些聚客区内,共生品牌门店数量为X轴,星巴克门店数量为Y轴,绘制成散点图,并用线性回归方程进行拟合。在一个较高的信度下(R²=0.94),平均每3个共生品牌周边就可以支撑一家星巴克门店。
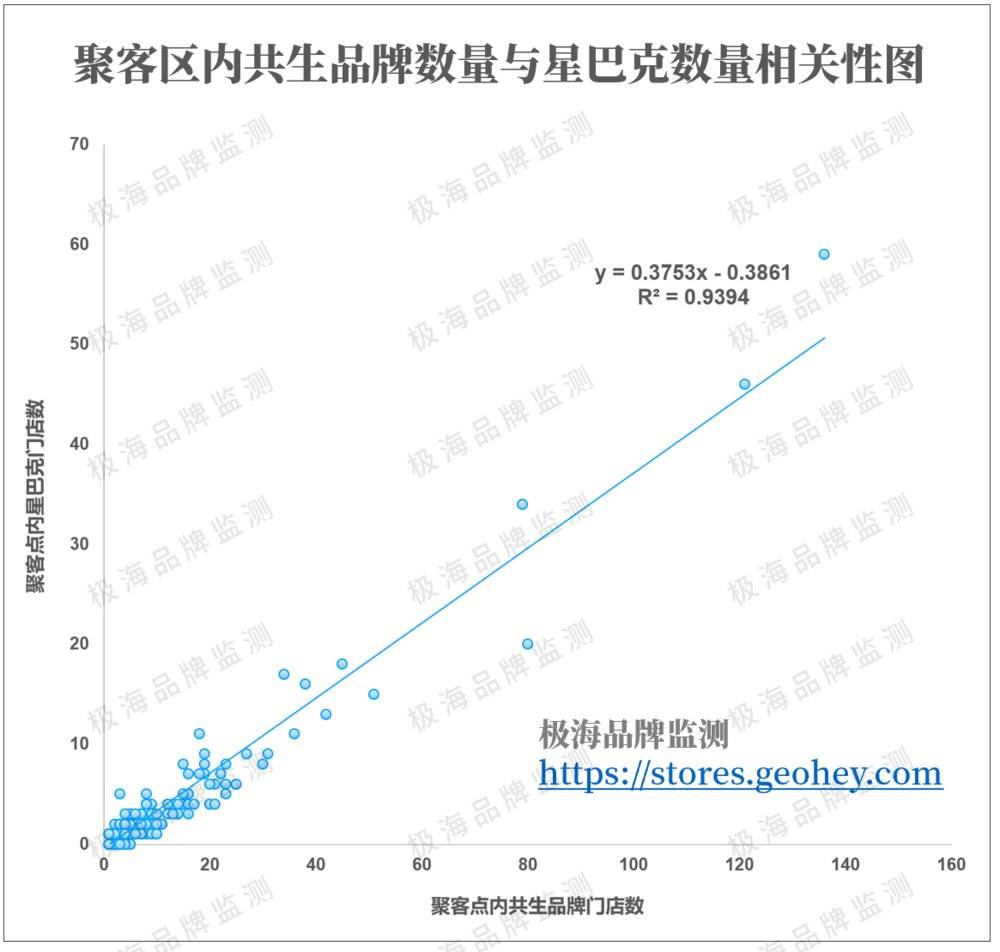
这样惊人的拟合程度一度令我感到怀疑,怀疑是不是数据做错了。因为同样的尝试我也做过喜茶,但拟合度仅有0.7上下。其中的关键在于,喜茶的门店扩张并不充分,难以构建有效的数据关联。而星巴克在上海的扩张已经趋近于饱和,数据的规律性也体现的更加明显。
这种规律性从某种程度上反映了品牌扩张最终的“稳态”,关联性越强,市场越饱和。但他还不能用于推算市场规模,尤其是新兴品牌的预测上,因为我们很难筛选出哪些才是饱和的聚客区,从而用他们来建构模型预测未饱和区域的门店规模。
还是把思路拉回门店密度这个概念上来——同样的区域,门店越密集门店规模也就越大。
我们也对“加密门店占比”这一密度指标进行过深入的剖析。我们将最早开在聚客区内的门店称之为“核心门店”,将之后开在开拓型门店周边的门店称之为“加密门店”。我们只要预估出未来加密门店的占比,就可以根据聚客点数量推算出门店规模了。
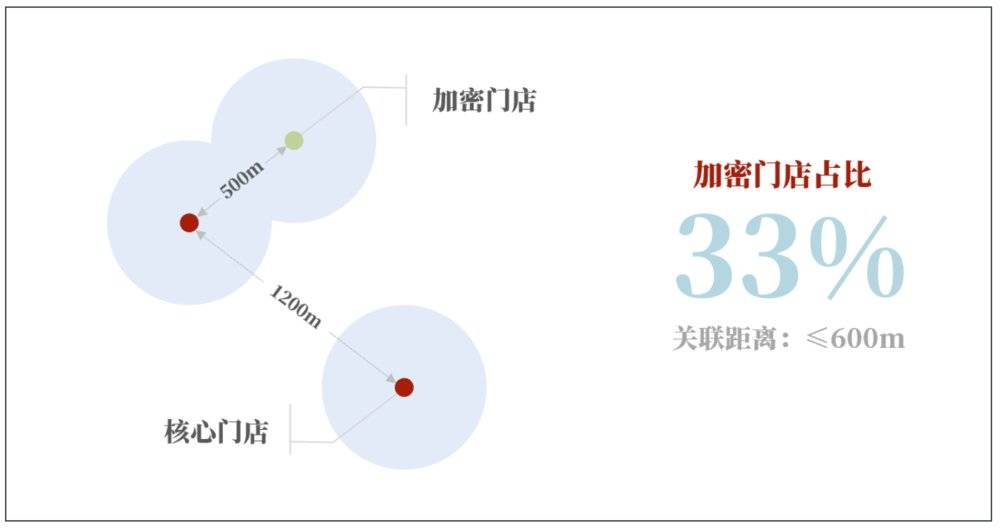
以上图为例,图中共有2个聚客区(相连的蓝色区域),核心门店数量等于聚客点数量也是2个(红色点),图中共有3家门店,开拓型门店占比 2/3≈67%,加密型门店占比为 1-37%=33%。因此,要反推门店总数,就要用 聚客点数量 /(1-加密型门店占比),如 2/(1-33%)=3 就可以了。
先来看看上海星巴克门店密度的规律。
我们按不同年份绘制了星巴克历年的密度曲线。随着星巴克门店从2015年的365家扩张到2021年的884家,加密门店的占比也从19%提升到65%。
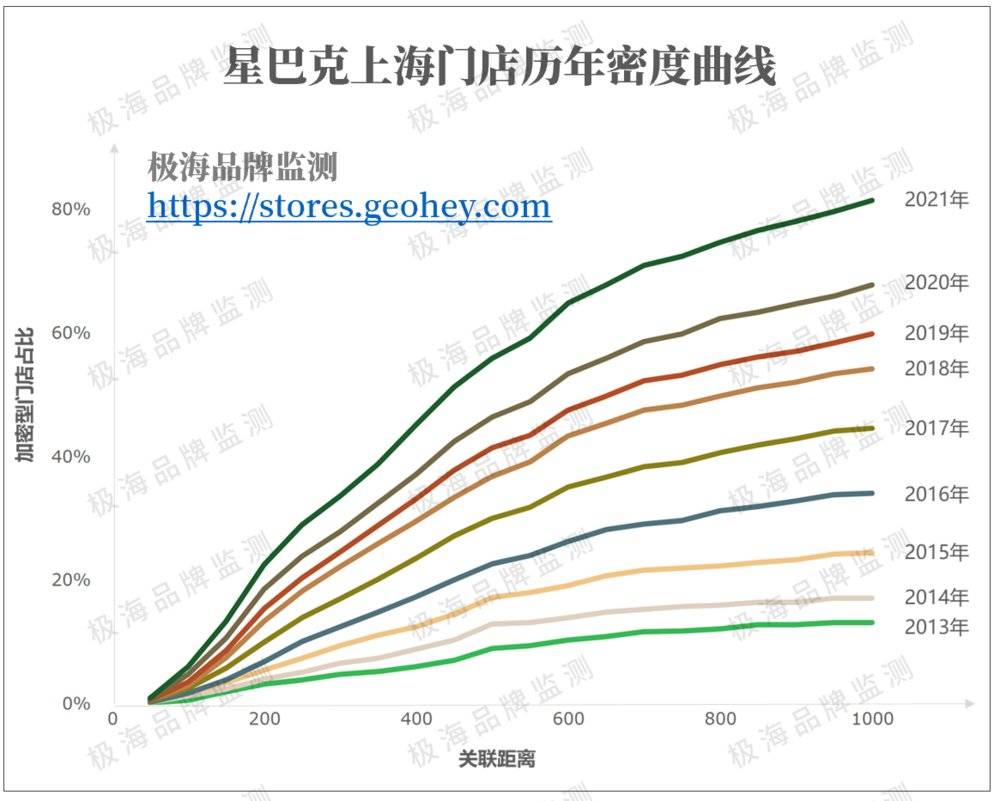
*以600的关联距离为准取值。
这是一个什么水平?就咖啡茶饮行业来说,上海找不出第二家比星巴克更加密集的品牌,瑞幸咖啡634家门店,加密门店也占比仅50%。唯一可以与之相提并论的就是以高密度开店著称的长沙茶颜悦色,占比达74%。
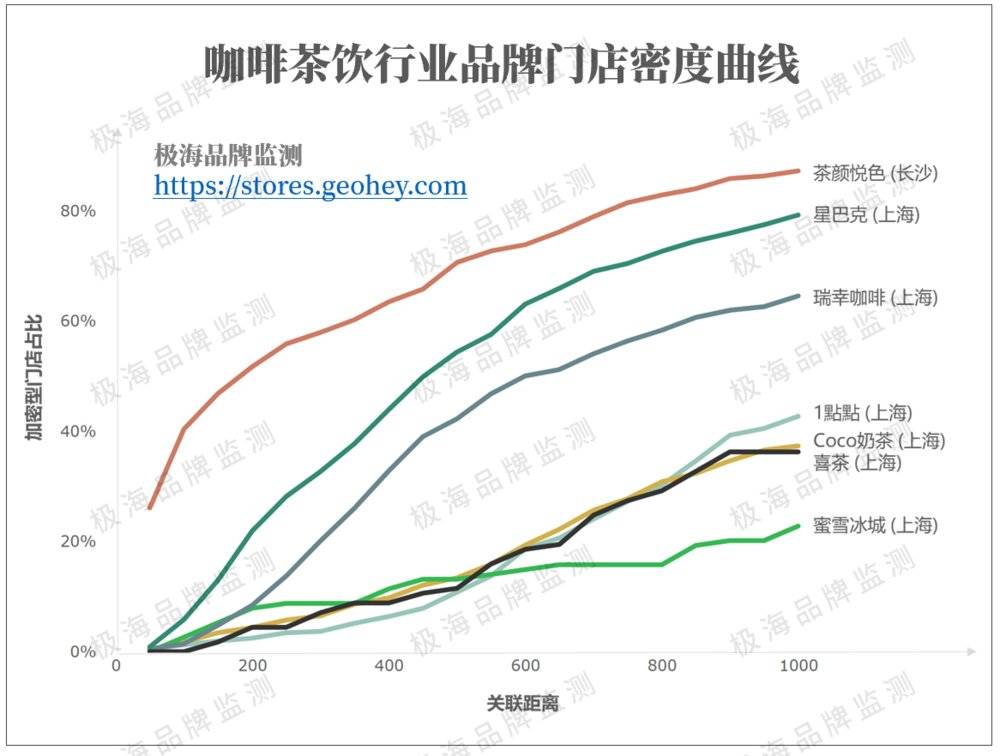
在门店规模上,唯有最密集的业态——便利店行业可与星巴克相提并论。罗森1114家门店,加密门店占比与星巴克相仿达63%。不得不感叹,星巴克在上海真的就像是便利店一样普及。
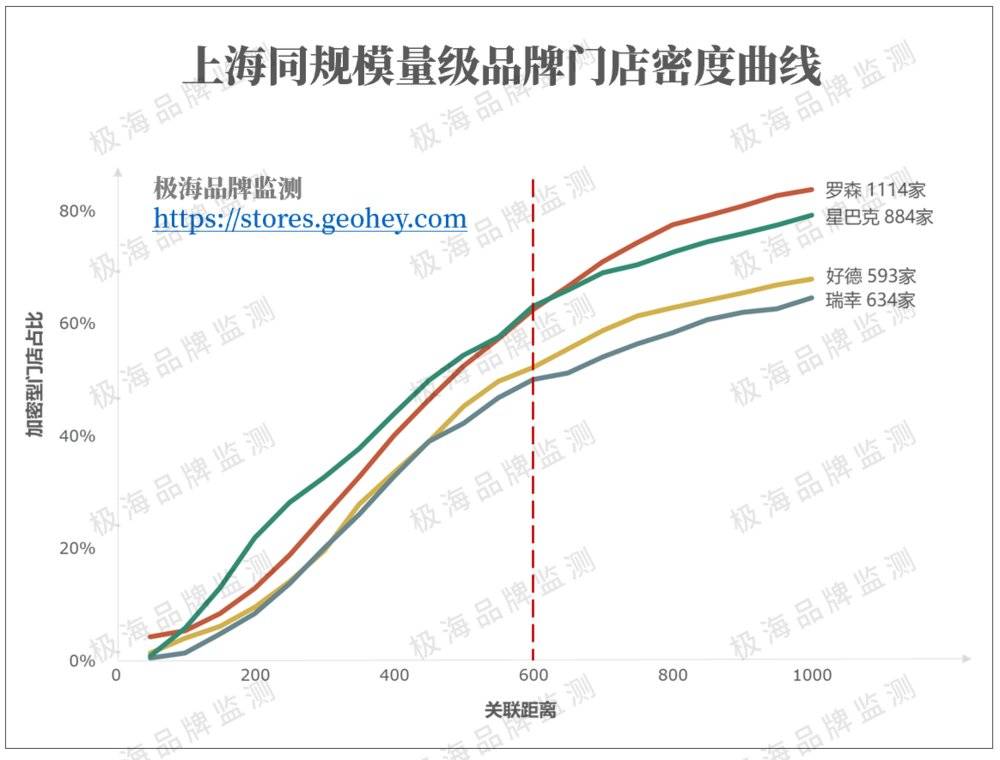
综上所述,我们判断中短期内上海星巴克加密门店占比上限在70%~75%之间。
预测上海星巴克门店市场规模:1020~1189家
有了聚客点(253个)和加密型门店占比(70%~75%)两个数据,我们可以的预估出星巴克中短期在上海的门店规模在 253 / (1- 70%) ≈ 843 到 253 / (1- 75%) ≈ 1012 家之间,加上之前不在我们预测范围内的20%的门店(177家),修正后的门店规模在1020家到1189家之间,为方便后续表述,这里统一取值1100家。
目前上海星巴克在营门店884家,饱和度 = 884/1100 ≈ 80%,已经非常接近饱和。即使是在非常理想的情况下 ,按目前80家/年的开店速度,在星巴克的选址策略和上海市城市规划不发生重大调整的前提下,星巴克在上海的快速扩张最多也只能维持2年多。
我们认为,在实现2022财年末6000家门店(大陆地区)的目标后,预计上海2023年的门店扩张速度将大幅放缓,星巴克在上海的门店策略即将迎来有一个新的调整期。
写在最后
不同于传统测算方法,我们从选址可能性的角度,运用共生品牌寻找潜在选址点,通过同类比较预测门店密度,对品牌中短期规模的上限进行了预测。思路和方法虽然比较清晰,但具体执行下来要考虑的种种参数依然是一项艰巨的任务,其中涉及的细节较多,篇幅有限无法进行详细的说明。
这里我们仅仅使用了上海星巴克的数据作为案例,同样的方法论也可以复制到其他城市,就可以预测星巴克在全国的规模。