
自2022年底ChatGPT横空出世之后,大模型的热闹一直喧嚣到现在。互联网巨头、ICT巨擘、云服务商、新创企业在这个赛道里打得难解难分之际,中国车企自研的大模型也开始陆续上车了。
去年11月的智界S7发布会上,华为盘古大模型正式上车,将大模型接入智慧助手小艺,展示了“私人用车顾问”的能力。12月份,理想汽车向L7/8/9用户推送OTA 5.0,MindGPT正式开启内测,主打助手功能,覆盖出行、用车、娱乐和知识百科四大场景。12月底的问界M9发布会上,余承东展示了盘古大模型可在实时观影的同时进行“百科问答”的能力,最近一次的大模型秀肌肉是今年1月份的比亚迪梦想日,比亚迪以旅游攻略的生成为例秀了一把自研大模型的实力。
图片来源:理想汽车
也许是车企宣传不得当,又或许是消费者期望过高,这些大模型最终并没有带给用户“wow”一般的感觉。“供需错位”的背后,既有来自用户体验的表层原因,也有来自技术的深层原因。
一、体验落差来自哪儿?
ChatGPT问世之后,正如将之比作人工智能领域iPhone时刻的黄仁勋(英伟达创始人、CEO)一样,很多人对LLM大语言模型、生成式AI萌发了极大的热情,甚至有人以宗教般的狂热喊出了“硅基文明终将取代碳基文明”的口号。这种情绪是可以理解的,经济发展缓慢,陷入存量竞争的现代人对下一次技术革命抱持热切的期盼,实属理所当然。
只不过,随着ChatGPT问世的时间越拉越远,GPT大模型带给人的新奇感变得越来越淡了。越来越多的人觉得,GPT的发展似乎与自己的工作和生活并无太大关联。
他们的感觉是对的,背后的理由却并非“大模型都是很好很好的,可我偏偏不喜欢”,也不是因为大部分人对新技术不敏感,而在于GPT目前能“超预期”发挥用武之地的设计场景本就与你我无关。
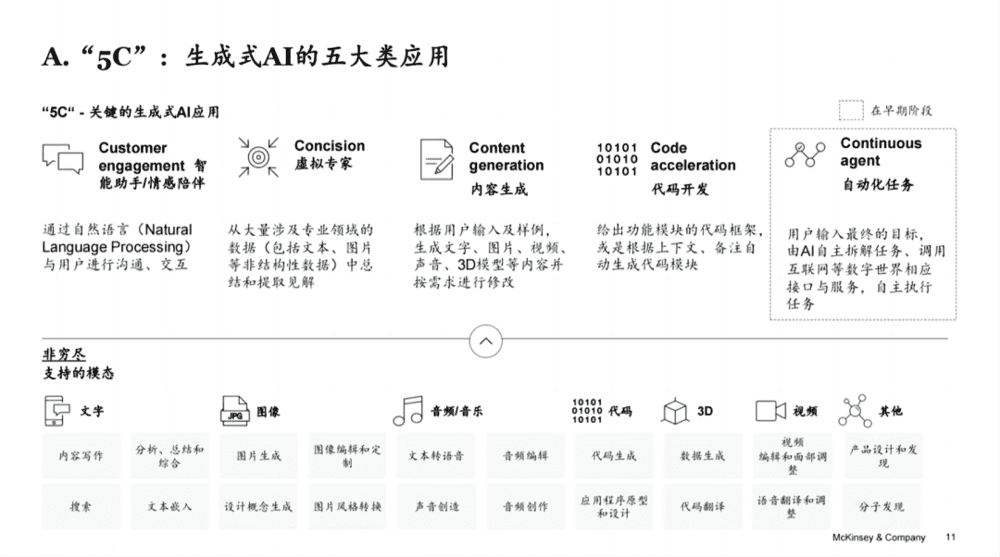
图片来源:麦肯锡
GPT有智能助手/情感陪伴、虚拟专家、内容生成、代码开发和自动化任务五大应用场景,除却处于发展早期的自动化任务,在其它应用场景里,“超预期”发挥作用的是虚拟专家(帮科研人员读论文)和代码开发(帮程序员写代码),而恰恰写代码、读论文并不适合汽车场景,于是,车载大模型的应用场景只剩下智能助手/情感陪伴和内容生成了。
不知道大家有没有发现,之前提到的三家车企在秀大模型的能力时,只展示了智能助手和内容生成应用场景。但是,内容生成可以在桌面端通过明显高出大部分本土车企大模型能力的ChatGPT或文心一言实现,没有必要在耐心耗尽之前,花着自己的流量费,让它在车上生成一张“漂浮在太空中的电动汽车”;可以帮你打开车窗、调空调温度的语音助手或者做行程攻略的出行助手,也不符合见惯了大场面的人们对“智能”的期待。
这些都不属于“增值”体验,大模型既然上车了,在汽车这么一个封闭空间内,人们自然而然期盼着的是“情感陪伴”、有来有回的互动和温暖感,但现在,大模型给人的温暖都不及NOMI多做了几个表情那么明显。
最终造成的局面是,在汽车这个场景中,消费者本来希望的大模型是一个如沐春风的情感陪伴者,至少也得是一个知我懂我的“聊天机器人”,结果迎来的却是包括汽车知识、文旅知识在内的百科问答、专家系统这类冷冰冰的机器。车企提供的大模型和消费者的需求之间存在供需错配,在巨大的心理落差之下,失望是在所难免的了。
那么,是大模型的开发者不够努力吗?其实真不是,主要原因是消费者“想多了”或者说过于乐观。要让开发者们反思自己是不是努力了,他们一定会像对李佳琦因爱生恨的猪猪女孩那样控诉:“佳琦,我真的努力了。”
为何说消费者过于乐观,可以拆成两个问题进行回答。第一,全球最先进的大模型发展到了什么阶段;第二,本土车企自研的大模型和“尖子生”的差距有多大?
二、大模型和人脑还差得远
抛开立场先行的争论和似是而非的认知,我们可以从技术参数的维度,先客观地看一看现在最先进的GPT大模型到底发展到了什么阶段。
GPT的“智慧涌现”能力或性能取决于大模型的规模,规模衡量最为关键的两个指标是参数量和训练语料(Token)数量。在大模型的结构设计足够良好的前提下,可以认为,参数量决定了大模型性能的“理论”上限和天花板,训练语料数量决定了大模型“实际”被训练到了什么程度。
为了帮助大家理解这俩指标的意义,我们不妨拿人类大脑做一个不太严谨的类比。毕竟,人工智能领域一直把人类大脑作为灵感的最大来源。
呱呱落地时,娃娃们的大脑已经有了良好的结构和足够多的参数(100万亿规模),但懵懂无知的幼崽要发展出情商、智商和各种各样的“商”,需要在各种各样的环境中接受熏陶、捶打、激励和训练,塑形大脑的神经元、突触、皮质,才能发展出在这个有时温馨有时冷酷、时而友好时而丛林的社会中独立生存和发展的能力。或者说,人脑的结构和参数量“先天”决定了这个娃娃理论上可以把潜能发挥到什么程度,但具体发挥到什么程度,取决于后天的训练。
所以,要提升GPT的性能表现,主要有两个手段:1. 推高大模型的参数规模;2. 训练更多的数据(以Token为单位)。我们可以拿OpenAI近几年的GPT版本,说明一下参数规模和训练数据规模对性能提升的作用。
2020年,OpenAI发布GPT-3,这个模型的参数量为1750亿,训练Token数量为3000亿,这个数据真实有效,来自Andrej Karpathy(特斯拉AI和自动驾驶部门前负责人)在2023年微软Build大会上的演讲。在没有改变模型结构和参数规模的前提下,OpenAI向GPT-3投喂了更多的训练语料,提高了模型的推理、语言理解及生成和基础问题解决能力,并将版本号升级为GPT-3.5,在此基础上推出了火爆全球的ChatGPT。
2023年推出的规模更大的GPT-4,尽管OpenAI 没有公开它的参数规模和训练数据量,但经过一轮又一轮的爆料,大致可以认为它的参数量高达1.8万亿,训练Token数量为13万亿。
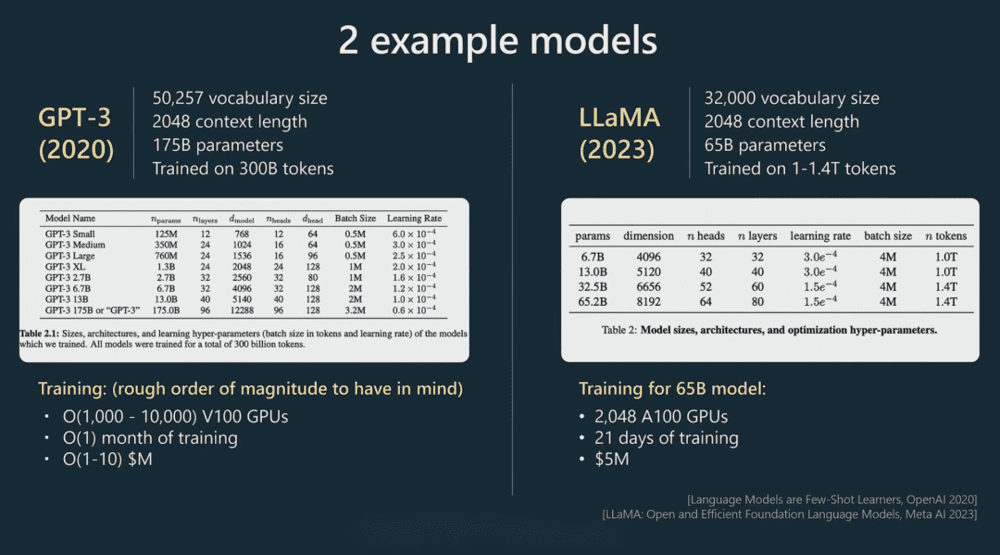
图片来源:微软Build大会
和人脑相比,GPT-4处于什么样的水平呢?据相关研究,人类大脑的神经元在860亿左右,通过100万亿左右个突触进行连接,对应到深度学习神经网络的参数量,人类大脑的“参数”在100万亿左右。训练Token在多少量级呢?有人做过估算,仅仅按单词量,人类一生接受训练的Token数量在几百亿到一千亿左右,考虑各种各样的图像、感觉、情绪,Token的数量会提升好多数量级。
且不说LLM大语言模型之后还会不会出现更能贴近人类智能的“新大模型”,单单拿GPT和人脑进行比较,至少在目前这个阶段,最顶尖的GPT和人脑且差得远呢。
更何况,本土车企自研的大模型和GPT-4这种优等生的差距还很大。
三、车企大模型受限于开源
尖子生的成绩亮出来了,下面要从参数量和训练Token数量两个维度,对顶尖的大模型和国内车企全栈自研的大模型进行一番比较了。
从数量上看,本土车企自研的大模型确实不少,但除了盘古大模型曾经公开过参数量(万亿级别)之外,没有任何其它车企公开过自研大模型的参数数量。不过,理想汽车曾经在去年的家庭科技日上公开过训练的Token数量1.3万亿,蔚来也曾经透露过NOMI接入的GPT大模型的Token数量达千亿量级,所以,暂且不比参数量,单单比较训练Token数量,理想和蔚来的GPT和GPT-4之间就存在数量级的差距。
其实,参数规模的差距也是巨大的,因为绝大部分全栈自研的大模型都是基于开源大模型实现的,而开源大模型的参数规模普遍不高。
不止是国内,全球范围内搞大模型都只有这么几种方式:在开源大模型的基础上做调优训练、调用其它大模型的API、在其它大模型的基础上做应用、真正自研大模型。OpenAI这些真正自研大模型的巨头正在着力推动赛道上的玩家选取第二种和第三种方式,不过,鉴于OpenAI们开发并发布的API数量依然非常少,所以,大家要么老老实实真正自研大模型,要么在开源大模型的基础上做训练。
从历史底蕴和技术积累上来说,国内真正自研大模型的车企恐怕不多。而且,即便要“真自研”大模型,也得从参数量小的模型开始做起,大家都是这么走过来的。目前,月活量排在全国头几位的百川大模型,参数量是从70亿、130亿、530亿慢慢做上去的。
值得一提的是,OpenAI的GPT-3并没有开源,开源的GPT-2的参数规模仅仅在15亿左右,Meta开源的Llama 2有7B、13B、70B三个版本,接受了2万亿个Token训练,国内这边,130亿参数的百川大模型Baichuan-13B选择了开源,530亿参数的百川大模型Baichuan-53B选择了闭源。可以认为,基于开源大模型全栈自研的车载大模型的参数量都在百亿级别,和GPT-4同样有一两个数量级的差距。
参数量、训练Token量与业界尖子生均存在数量级的巨大差距,真正了解了这一点,就不会对本土车企自研的大模型抱有过高的期待了。
四、写在最后
车载大模型的实际表现和消费者的心理预期产生了一定的落差,这主要是消费者的“乐观”估计造成的。记得比尔·盖茨曾经讲过这么一句话,“人们往往会高估未来一两年内取得的成绩,低估未来十年取得的进展。”前半句大概率适用于GPT这种具有划时代意义的新技术。
后半句呢?在比尔·盖茨、黄仁勋这些大佬的眼中,GPT大模型是数十年来最伟大的技术发明,大模型的未来是值得期待的。所以,对于车载大模型,我们不妨保持谨慎且乐观的态度吧。
本文来自微信公众号:autocarweekly (ID:autocarweekly),作者:三少爷