

“史在他邦,文归海外。”
每谈及那些离家百年、去国万里的中华古籍,郑振铎先生总是不胜慨叹。
近代以来,大批古籍流散海外,不少珍本、善本、孤本为国内罕见。
所幸,在海内外有识之士的携手努力下,大批海外中文古籍,正迎来“数字化回归”的浪潮。
5月18日,汉典重光古籍平台上线,一批珍藏于加州大学伯克利分校的中文古籍善本,以数字化方式正式回家。

这其中,有多套珍贵的宋版书籍,如宋刻本《後村居士集》、北宋《金粟山大藏经》写本、苏轼文集残页,此外还有清文澜阁四库全书本《宋百家诗存四十卷》、清末第一批近代思想家王韬的稿本《瀛壖杂志》等。

借助阿里达摩院AI技术,汉典重光以准确率达到97.5%的古籍识别系统,将20万页古籍从扫描图片变成在线文本,还沉淀下覆盖3万多字的在线古籍字典。
从寻觅、修复、储存,再到如今的数字化、公共化,海外回归的中国古籍背后,是一代代中国人为延续民族文化香火所做的努力。
 文澜阁《四库全书》毁失过半
文澜阁《四库全书》毁失过半 自古以来,卷帙浩繁,难避水火兵虫,最典型的例子,就是《四库全书》。
《四库全书》,编纂于乾隆年间,动用了3800名文人墨客,耗时近15年,共包含3461种书、7.9万卷、3.6万册,总字数接近8亿。
为妥善收藏保存《四库全书》,乾隆下令在中国南北分建七座藏书阁,“北四阁”和“南三阁”规制相当。

位于杭州西湖孤山的文澜阁
历经十年,藏于紫禁城文渊阁的《四库全书》率先告成,全书抄成3万6千册,约计229万页,7亿7千万字。
其中,经、史、子、集四部书籍,分别用绿、红、白、黑色的绢帛作封面,还选用珍贵楠木制函套,便于长期保存。
乾隆的这套方案,当时看来几乎可保万无一失,可随着清朝统治由盛转衰,列强入侵,战乱频繁,七阁《四库全书》躲过了“水”与“虫”,却逃不过“兵”与“火”。
咸丰三年(公元1853年),太平军攻入镇江、扬州,文宗阁和文汇阁遭焚毁,阁中珍藏的《四库全书》均付之一炬。

清文澜阁《四库全书》零本
最终,内廷四阁的《四库全书》幸存三部,江浙三阁的仅存半部,不过百年,毁失过半。
据传,杭州藏书家丁申、丁丙兄弟在避难之余,发现包子的包装纸,竟是文澜阁本《四库全书》书页,立即捡拾、搜寻。
丁氏兄弟最终寻回8000多册,约占《四库全书》原有数量的四分之一。

四库全书杭州文澜阁本(复制品)
光绪七年(公元1881年),文澜阁重建,丁氏兄弟又着手补抄书籍。
再过了近百年,清代曹庭栋辑纂的《宋百家诗存》,出现在了美国加州大学伯克利分校东亚图书馆内。

印着乾隆印章的《宋百家诗存》
这正是文澜阁本《四库全书》丢失的诗集之一。
通过现有资料可知,民国时期的浙江嘉业堂,曾收集过部分遗散藏书,后被带去日本三井文库,最终存于加州大学伯克利分校。
至于残存古籍流转所经历的种种,已无处可寻。
 古籍回归困难重重
古籍回归困难重重 去年,法国一次拍卖会上,两册国宝文物《永乐大典》以5000欧元起拍,最终由中国收藏家以640万欧元天价拍下。

《永乐大典》真迹回归故土,但大部分散落海外的文物古籍,集中藏于各地图书馆、博物馆,鲜见流通市场。
据不完全估计,近代散居海外的中国古籍超过40万部、400万册,包括甲骨简牍、敦煌遗书、宋元善本、明清精椠、拓本舆图、少数民族文献等等。
中国古籍流入他国,曾令郑振铎忧心忡忡,“将来研究国故朝章者,非赴国外留学不可。”

原藏于伯克利大学东亚图书馆的苏轼著《苏文忠公文集》
确实,加州大学伯克利分校东亚图书馆,如今每年要接待大批学者,他们不远万里,舟车劳顿,只为来此查阅古籍善本和特藏资源。
2019年,馆长周欣平见到一批来自中国的特殊客人,包括四川大学教授陈力、王果和阿里的同学,他们提出要将中文古籍善本数字化,双方一拍即合。

陈力、王果和阿里的同学讨论古文字识别中的技术问题
但这是一项很有难度的挑战。
在古籍数字化领域,业界一直没有现成的算法或方案。
在海外,谷歌的Google Books,是较为早期的古籍识别项目,但识别对象是英文古籍,并不适用于汉籍。
在国内,20世纪80年代起,文渊阁《四库全书》先后有三家企业进行过影像数字化,一家完成影像、全文文本的数字化,但由于各种原因都未能面世。

达摩院的扫地僧们,也是在正式接手这项任务后,才意识到AI古籍识别能力的挑战性有多大。
 理科生用技术“延续”文化香火
理科生用技术“延续”文化香火 在阿里内部,OCR(光学字符识别)技术团队是底蕴最为深厚的AI团队之一,常年深耕于文字图像领域。
不料,OCR技术一度也搞不定古籍。

最直观的原因是,OCR识别现代印刷品是认行(行识别),但要识别古籍必须认得每个字(单字检测)。
现代常用汉字只有6000多个,算法基本能覆盖到2万字内,但由于写法多样,古籍文字多达几十万。
“这个项目光靠技术不行。” 项目算法负责人何梦超说,“最大的问题是我们算法人员不了解古籍,甚至很多字都不认识。”

鲁迅笔下的孔乙己,就说过茴香豆的茴字有四种写法,可陈力教授认为,在古籍中,茴字写法其实远不止四种。
加之,人工抄录的古书千人千面,雕版印刷古籍还有季节、气候、地点等变量。同时,古书年代久远,纸张破损、污渍在所难免,AI识别更为困难。

为了开发出一套AI古籍识别系统,达摩院的技术大牛和川大的研究学者,纷纷恶补对方的知识领域。
一方研究历史知识,一方学习AI技术,大家取长补短。
不到10人的达摩院项目算法团队,花费两年时间,最终利用单字检测、无监督单字聚类、小样本学习、主动学习等机器学习方法,开发出了一套边识别古籍、边训练模型的系统。

单字检测,就是给全书做检测,抠出古籍正文中的每个字,单独成为一张图。

下一步是聚类,让机器自动把字形笔划一致的字,归为一类,再由人工标注。
10万字的古书,“聚类”一下,人工只需标注几千字。

古籍里的异体字、生僻字,就让机器自动生成样本,确保单字样本量达到10个,即可得到少样本识别模型。
从聚类到打标,再到少样本模型,一轮迭代后,可正确完成全书70%左右的文字,剩下30%再用来做第二轮迭代。

随着模型不断优化迭代,目前,汉典重光古籍识别系统对20万页古籍的整体识别准确率已达到97.5%,剩下有2.5%的字,仍需人工识别打标。
这已是非常了不起的成就。
以一本100万字的古籍为例,如全靠专家录入,每人1000字/天,需要1000天。用上这套古籍识别系统,只需要35天时间,效率提升了近30倍。
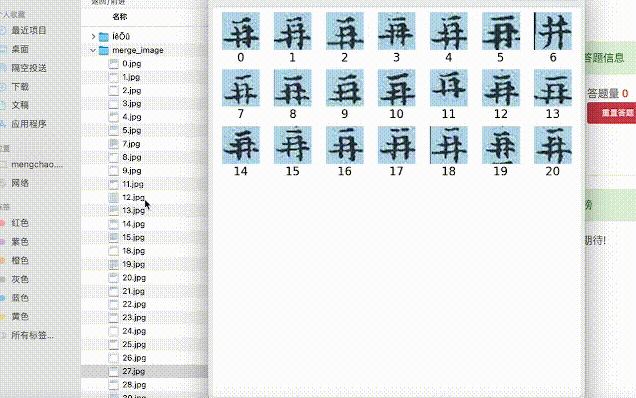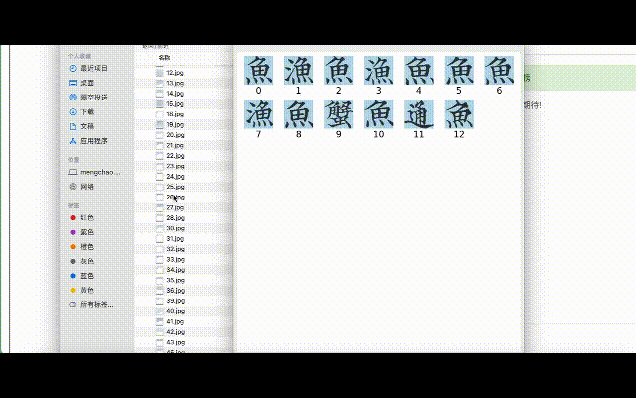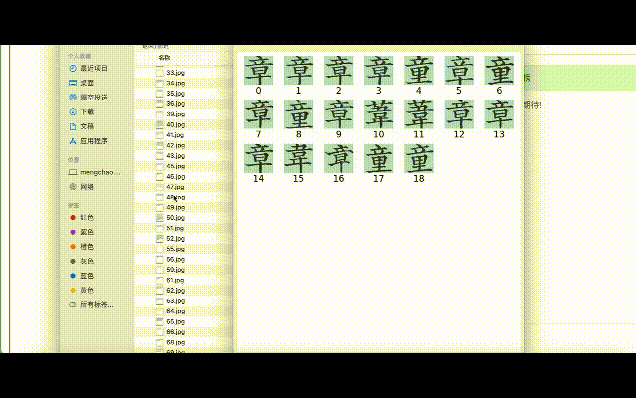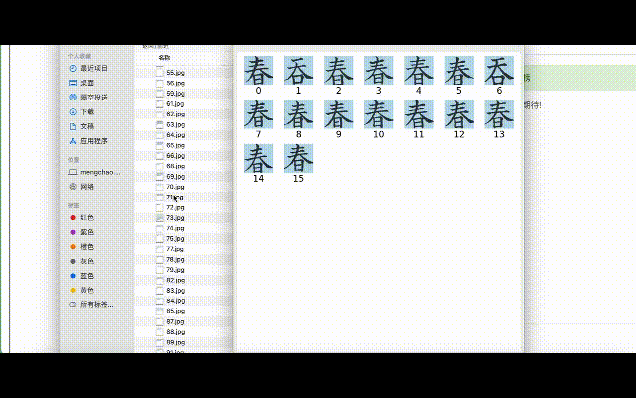
目前,汉典重光研发的古籍识别系统已能对上百本古籍作批量识别。
 古籍“回归”意义非凡
古籍“回归”意义非凡 “在技术研发过程中,难度比之前预想的还要大。”王果教授说,这两年多很难,但从未有人试图放弃。
在国家图书馆副馆长张志清看来,古籍是中华文明的“魂器”。
从古自今,我国就有整理古籍、文献和修史的传统。

在“十四五”规划和国家中长期发展规划中,古籍的保护、整理、研究、利用,也得到了高度重视。
古籍数字化,能为学术研究按下快捷键。
例如颇有争议的《红楼梦》后四十回,一直被认为并非曹雪芹所著,可是后来就有学者利用大数据技术,通过分析全书字频词频、语言习惯,认定大部分是由曹雪芹本人所写。

阿里正计划,将这套技术工具连同古籍数字化平台一并捐赠,交由权威公共机构长期运营,最终将成为一个开放的网络平台,供大众检索学习。
这意味着,研究人员、学者足不出户,就能学习到过去难以获取的内容。
而在汉典重光平台上,所有人都能免费使用所有功能,包括古籍数字化交互式训练、古籍全文内容检索、古籍汉字字典。

过去学者皓首穷经的事,如今每个普通人都能知晓,大大降低了人们学习、阅读古籍的门槛。
“敦煌在中国,敦煌学在日本。”

这句话一度被传是日本专家藤枝晃所说,后考证是中国专家吴廷璆所言,其寓意是为了让国人重视这门当时还比较陌生的敦煌学。
现在,有了技术支持,实现数字时代的“书同文”梦,就有了主动性。

未来,阿里还将与美国、欧洲、日本、韩国等有影响力的图书馆合作,扩大古籍回归的数量,同时,继续研发古籍数字化技术,提升古籍识别系统的准确率与效率。
20万页古籍只是沧海一粟,一切刚刚开始。
随着越来越多的古籍文献数字化回归,“史在他邦,文归海外”的窘境,终将彻底成为历史。
【汉典重光】古籍数字化平台:
https://wenyuan.aliyun.com/home
文 | 王安忆