
随着媒体狂炒Sora,OpenAI的介绍材料中称Sora是“世界模型”(world simulator),世界模型这个词又进入视野,但很少有文章来介绍世界模型。这里回顾一下什么是世界模型,以及讨论Sora是不是“世界模型”。
什么是“世界模型”?
当AI领域中讲到 世界/world、环境/environment 这个词的时候,通常是为了与 智能体/agent 加以区分。研究智能体最多的领域,一个是强化学习,一个是机器人领域。因此可以看到,world models、world modeling 最早也最常出现在机器人领域的论文中。而今天world models这个词影响最大的,可能是Jurgen 2018年放到arxiv的这篇以“world models”命名的文章,该文章最终以 “Recurrent World Models Facilitate Policy Evolution”的title发表在NeurIPS‘18。

论文题目:Recurrent World Models Facilitate Policy Evolution
论文地址:https://worldmodels.github.io/
该论文中并没有定义什么是World models,而是类比了认知科学中人脑的mental model,引用了1971年的文献。

mental model是人脑对周边世界的镜像
Wikipedia中介绍的mental model,很明确指出其可能参与认知、推理、决策过程。并且说到 mental model主要包含mental representations和mental simulation两部分。
an internal representation of external reality, hypothesized to play a major role in cognition, reasoning and decision-making. The term was coined by Kenneth Craik in 1943 who suggested that the mind constructs "small-scale models" of reality that it uses to anticipate events.
到这里还是说得云雾缭绕,那么论文中的结构图说明了什么是一个“世界模型”:
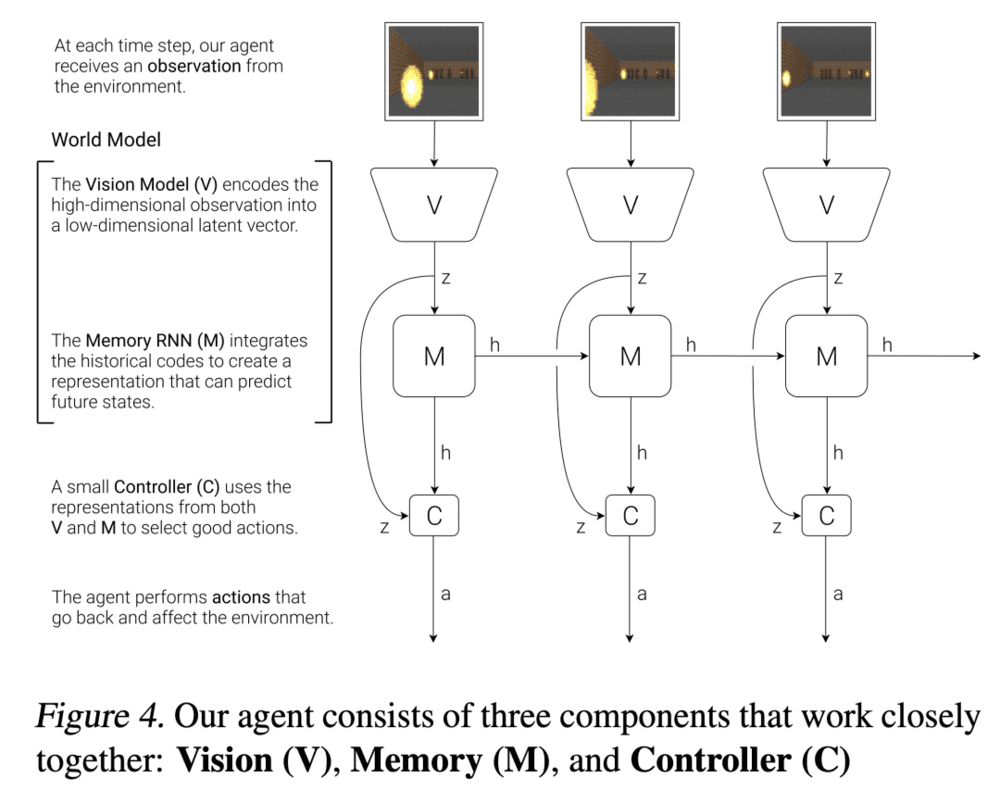
图中纵向V->z是观测的低维表征,用VAE实现,水平的M->h->M->h是序列的预测下一个时刻的表征,用RNN实现,这两部分加起来就是World Model。
也就是说,“世界模型”主要包含状态表征和转移模型,这也正好对应mental representations和mental simulation。
看到上面这张图可能会想,这不是所有的序列预测都是“世界模型”了?其实熟悉强化学习的同学能一眼看出来,这张图的结构是错误(不完整)的,而真正的结构是下面这张图,RNN的输入不仅是z,还有动作action,这就不是通常的序列预测了(加一个动作会很不一样吗?是的,加入动作可以让数据分布自由变化,带来巨大的挑战)。
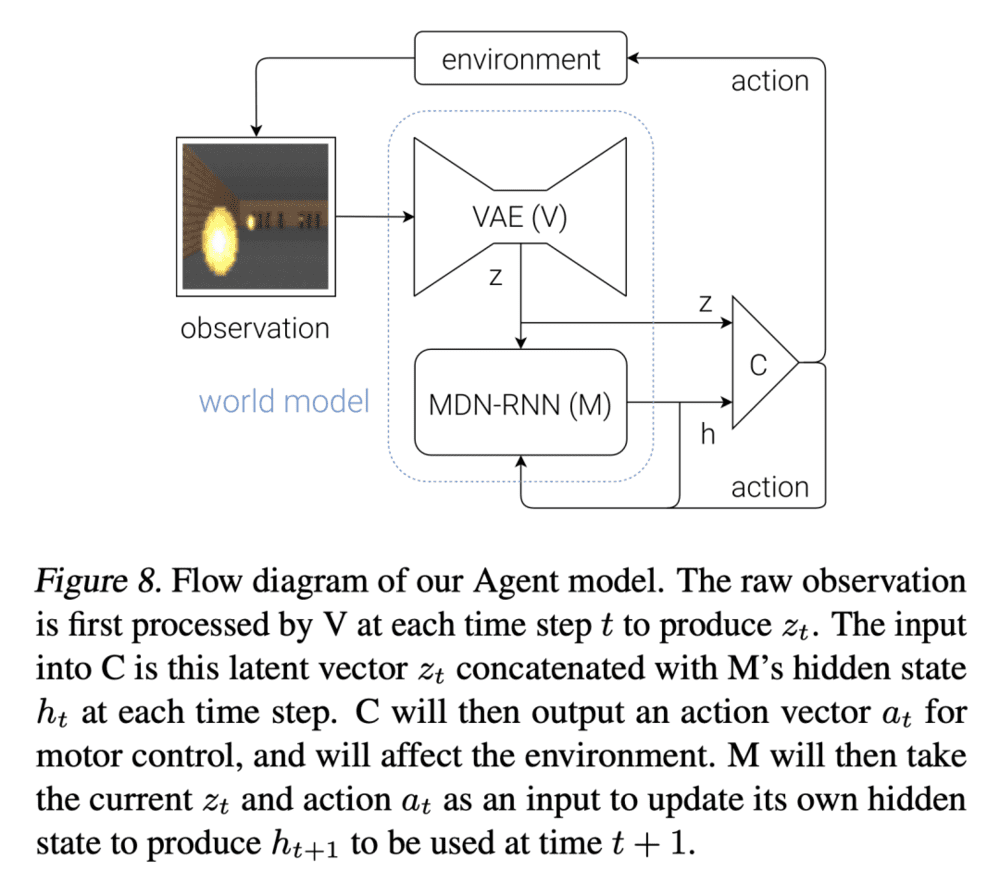
Jurgen的这篇论文属于强化学习领域。那么,强化学习里不是有很多model-based RL吗,其中的model跟world model有什么区别?答案是没有区别,就是同一个东西。Jurgen先说了一段:

基本意思就是,不管有多少model-based RL工作,我是RNN先驱,RNN来做model是我发明的,我就是要搞。
在Jurgen文章的早期版本中,还说到很多 model-based RL,虽然学了model,但并没有完全在model中训练RL。

没有完全在model中训练RL,实际上并不是model-based RL的model有什么区别,而是model-based RL这个方向长久以来的无奈:model不够准确,完全在model里训练的RL效果很差。这一问题直到近几年才得到解决。
编注:强化学习算法可以分为无模型(model-free)强化学习与有模型(model-based)强化学习,后者中的模型也被称为“世界模型”。在基于世界模型的强化学习方法中,智能体首先学习一个关于环境的内嵌的模型,在内嵌的模型中学习行为决策,从而提高在真实环境中的表现。
聪明的Sutton在很久以前就意识到model不够准确的问题。在1990年提出Dyna框架的论文 Integrated Architectures for Learning, Planning and Reacting based on Dynamic Programming(发表在第一次从workshop变成conference的ICML上),管这个model叫action model,强调预测action执行的结果。RL一边从真实数据中学习(第3行),一边从model中学习(第5行),以防model不准确造成策略学不好。


论文题目:Integrated Architectures for Learning, Planning and Reacting based on Dynamic Programming
论文地址:https://dl.acm.org/doi/10.1145/122344.122377
可以看到,“世界模型”对于决策十分重要。如果能获得准确的“世界模型”,那就可以通过在“世界模型”中反复试错,找到现实最优决策。
这就是“世界模型”的核心作用:反事实推理/Counterfactual reasoning, 也就是说,即便对于数据中没有见过的决策,在“世界模型”中都能推理出决策的结果。
了解因果推理的同学会很熟悉反事实推理这个词,在图灵奖得主Judea Pearl的科普读物The book of why中绘制了一副因果阶梯:
最下层是“关联”,也就是今天大部分预测模型主要在做的事;
中间层是“干预”,强化学习中的探索就是典型的干预;
最上层是“反事实”,通过想象回答 what if 问题。
Judea为反事实推理绘制的示意图,是科学家在大脑中想象,这与Jurgen在论文中用的示意图异曲同工。

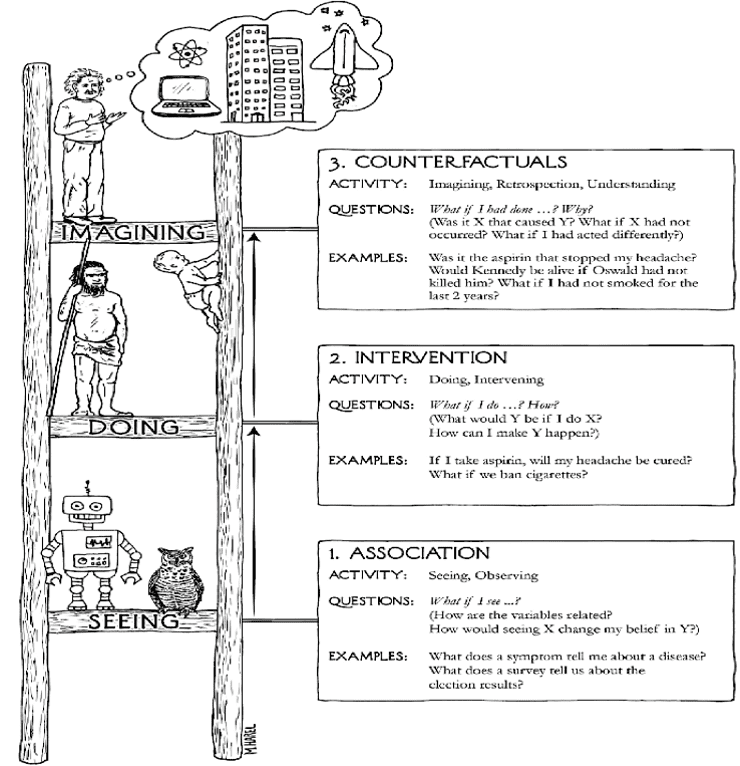
上:Jurgen论文中的世界模型示意图。下:Judea书中的因果阶梯。
到这里我们可以总结,AI研究人员对“世界模型”的追求,是试图超越数据,进行反事实推理,回答what if问题能力的追求。这是一种人类天然具备,而当前的AI还做得很差的能力。一旦产生突破,AI决策能力会大幅提升,实现全自动驾驶等场景应用。
Sora是不是“世界模型”?
simulator这个词更多出现在工程领域,其作用与“世界模型”一样,尝试那些难以在现实世界实施的高成本高风险试错。OpenAI似乎希望重新组成一个词组,但意思不变。
Sora生成的视频,仅能通过模糊的提示词引导,而难以进行准确的操控。因此它更多的是视频工具,而难以作为反事实推理的工具去准确的回答what if问题。
甚至难以评价Sora的生成能力有多强,因为完全不清楚demo的视频与训练数据的差异有多大。
更让人失望的是,这些demo呈现出Sora并没有准确地学到物理规律。已经看到有人指出了Sora生成视频中不符合物理规律之处。
我猜测OpenAI放出这些demo,应该基于非常充足的训练数据,甚至包括CG生成的数据。然而即便如此那些用几个变量的方程就能描述的物理规律还是没有掌握。OpenAI认为Sora证明了一条通往simulators of the physical world的路线,但看起来简单的堆砌数据并不是通向更高级智能技术的道路。
本文首发于作者知乎:https://zhuanlan.zhihu.com/p/661768957,经作者授权转载。
本文来自微信公众号:集智俱乐部 (ID:swarma_org),作者:俞扬