
本文来自微信公众号:集智俱乐部 (ID:swarma_org),作者:Neil Savage,翻译:毛迎荣,原文标题:《Nature:为什么人工智能需要理解因果?》,题图来自:《机械姬》
为什么药物只对某些人有效,而对另一些人无效?为什么 ChatGPT 会产生违背常识的答案?机器学习的发展似乎遇到了障碍,其中症结或许在于“相关性不等于因果性”。近日发表在 Nature 的一篇评论文章指出理解因果关系对于人工智能的重要性。因果推理让机器具备应对变化环境的能力,让机器可以像人类一样通过想象来学习。著名计算机科学家、“贝叶斯网络之父”Judea Pearl 在推特上转发了这篇文章并激动地评论道:Nature 杂志发现了因果!
Rohit Bhattacharya 开始攻读计算机科学博士学位时,他的目标是构建一种工具,帮助医生识别对免疫疗法反应良好的癌症患者。这种方式的治疗可以帮助人体的免疫系统对抗肿瘤,并且对可以和免疫细胞产生的蛋白质结合的恶性肿瘤效果最好。Bhattacharya 的想法是创建一个神经网络,可以同时描述肿瘤和人的免疫系统的基因,然后预测哪些人可能从治疗中获益。
但他发现他的算法不能胜任这项任务。他能够识别与免疫反应相关的基因模式,但这还不够[1]。他解释说: “我无法说这种特定的结合模式,或这种特定的基因表达,就是患者对免疫疗法反应的因果决定性因素。”
Bhattacharya 是被一个古老的格言所羁绊,即相关性不等于因果关系——这也是人工智能的一个基本障碍。计算机可以通过训练来发现数据中的模式,即使是那些非常微妙以至于人类可能会错过的模式。计算机还可以利用这些模式进行预测——例如,肺部X光片上的斑点表明有肿瘤[2]。但当涉及到因果关系时,机器通常就会不知所措。人们在生活中理解这个世界如何运转,而机器则缺乏这方面的常识。例如,原本用来训练发现肺部病灶的人工智能程序,有时会误入歧途,识别的却是图像中用来标记 X 光片右侧的符号。[3] 至少对人来说很明显的是,X光片上字母“R”的形状和位置与肺部疾病的迹象之间没有因果关系。但是如果没有这种理解,这些标记的绘制或者是定位方式的任何差异都可能将机器引上错误的方向。
印第安纳州普渡大学的电气工程师 Murat Kocaoglu 表示,要让计算机执行任何决策,它们需要理解因果。“任何超出预测的事情都需要某种因果关系的理解。如果你想计划一些事情,如果你想找到最好的政策,就需要某种因果推理模块。”
将因果模型整合到机器学习算法中,也可以帮助能够自主移动的机器做出如何在环境中游走的决定。“如果你是一个机器人,就会想知道当你以不同的角度迈步,或者推一个物体时,会产生什么后果。”Kocaoglu 说。
Bhattacharya 的案例中,可能是系统指出的某些基因让治疗效果更好。但由于缺乏对因果的理解,这意味着其他解释也可能成立,比如反过来,是治疗影响了基因表达,或者另一个隐藏的因素同时影响了基因表达和疗效。这个问题的潜在解决方案在于所谓的因果推理(causal inference)——即用数学的形式化方法来确定一个变量是否影响另一个变量。

长期以来,经济学家和流行病学家一直使用因果推理来检验他们关于因果关系的观点。2021年诺贝尔经济学奖授予了三位研究人员,他们利用因果推理提出了诸如提高最低工资是否会导致就业率下降,或者多上一年学会对未来收入产生什么影响等问题。如今,越来越多的计算机科学家致力于将因果与人工智能结合起来,赋予机器解决这些问题的能力,帮助它们做出更好的决策,更有效地学习,并适应变化,Bhattacharya 是其中之一。
因果观念指导人类在世界中前行。计算机科学家 Yoshua Bengio 说,“拥有一个关于世界的因果模型,哪怕是不完美的,也能让我们的决策和预测更加有力,因为我们所拥有的就是不完美的世界模型。”Bengio 领导着加拿大蒙特利尔四所大学合作创办的米拉-魁北克人工智能研究所(Mila-Quebec AI Institute)。人类对因果关系的理解支持了想象、懊悔等属性;如果赋予计算机类似的能力,就可以将这些属性迁移给计算机。

攀登因果之梯
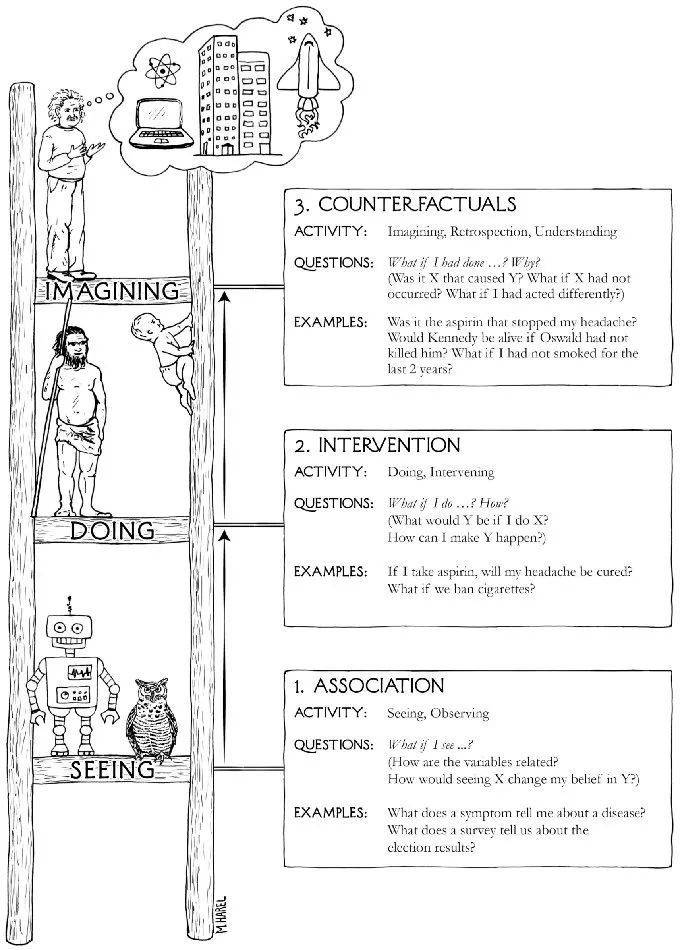
过去10年,人工智能取得的重大成功——比如在各种竞赛游戏中击败人类、识别图像内容,以及在过去几年中,根据书面提示生成文本和图片——都是由深度学习(deep learning)推动的。通过研究大量的数据,这类系统可以学习如何把一个事物与另一个事物相关联,随后这些习得的关联性就可以投入实际应用。但这只是登上了梯子的第一阶,而这把梯子通向更高目标。加州大学洛杉矶分校认知系统实验室主任、计算机科学家朱迪亚·珀尔(Judea Pearl)称这个更高目标为“深度理解”(deep understanding)。
2011年,Pearl 因为开发了一种概率和因果推理的算子,获得了图灵奖,这个奖项通常被称为计算机科学的诺贝尔奖。他描述了推理的三个层次[4]。最基本的层次是“见”,即通过观察在事物之间建立联系的能力。今天的人工智能系统在这方面非常擅长。Pearl 将下一个层次称为“做”——对某事做出改变,并关注后果。这就是因果发挥作用的地方。
计算机可以通过检查干预措施建立因果模型:一个变量的变化如何影响另一个变量。与当前人工智能中为变量之间的关系只创建一个统计模型不同,计算机创建了多个统计模型。在每一个模型中,保持变量之间的关系不变,但却改变了其中一个或几个变量的值,而这样的改变可能会导致新的结果,所有这些都可以用概率和统计学的数学方法来评估。Bhattacharya 说: “我认为,因果推理就是将人类如何做决定的过程数学化。”
Bengio 因其在深度学习方面的工作获得了2018年的图灵奖,以表彰他在深度学习方面的工作,他和他的学生已经在用训练神经网络的方式来生成因果图[5],这是一种描述因果关系的方式。简单来说,如果一个变量是另一个变量的原因,就用一个箭头从前一个变量指向后一个变量;如果因果关系反过来,那么箭头也是颠倒的;而如果两者没有关联,他们之间就不会有箭头。Bengio 的神经网络被设计为随机生成一个因果图,然后检查它与给定数据集的兼容性。如果一些图比其他图能更好地拟合数据,那么这些图大概率会更精准,于是神经网络学习生成更多类似的图,目的是找能最佳拟合数据的那个图。
这种方法类似于人解决问题的方式:人们生成可能的因果关系,并假设最符合观察结果的因果关系最接近事实。例如,当一个玻璃杯被扔到混凝土上时,看到它破碎,可能会导致一个人认为对坚硬表面的冲击导致玻璃杯破碎。把玻璃杯换成其他物品,或者把混凝土换成柔软的地毯,或者尝试从其他高度上跌落,都能让一个人改进关系模型,更好地预测一旦失手掉东西的后果。
因果推理让AI懂得应对变化
因果推理的一个关键好处在于,它可以让人工智能更有能力应对不断变化的环境。现有的人工智能系统只根据数据中的关联进行预测,因此极易受到这些变量相互关联方式产生的任何变化的影响。当学习关系的统计分布发生变化时——无论是由于时间推移、人类行为还是其他外部因素——人工智能将变得不那么准确。
例如,Bengio 可以在蒙特利尔当地的道路上训练一辆自动驾驶汽车,而人工智能有可能学会如何安全驾驶汽车。但如果将同样的系统转移到伦敦,它会立即失灵,原因很简单:加拿大的汽车是靠右行驶的,而英国的汽车是靠左行驶的,此前人工智能学到的一些关系可能需要反过来。他可以利用伦敦的数据从头再次训练人工智能,但这不仅需要时间,还意味着由于新模型取代了旧模型,该软件将不再适用于蒙特利尔。
另一方面,因果模型可以让系统学习许多可能的关系。Bengio说:“在可观察的全部事物之间不是只能学到一套关系,而是有无数个关系。你构建一个模型,就可以解释环境中任何一个变量发生变化时可能发生的情况。”
人类正是驾驭了因果模型才能快速适应变化。一个加拿大司机飞到伦敦,只需花几分钟调整一下,就可以左舵的路面上完美驾驶。在英国驾车右转时才需要处理路径交叉问题,这与加拿大情况不同,但它对驾驶员转动方向盘时的预期,或者轮胎如何与路面相互作用都没有影响。“我们对世界的了解基本上是一样的,”Bengio说。因果建模使系统基于当前对世界的理解就能确定干预的效果,而不必对任何事都需要从头开始,重新学习。
这种在不搅乱已有认知的情况下应对变化的能力也使人类能够理解一些非真实情况,比如奇幻电影。Bengio 解释道,“我们的大脑能够将自己投射到一个虚构的环境中,在这个环境中,一些事情发生了变化。物理定律不同了,或者出现了怪物,但其余的还都一样。”

反事实
想象的能力在 Pearl 的因果推理层次结构中处于最高层。Bhattacharya 说,关键是推测未采取行动的后果。
Bhattacharya 喜欢通过给学生们阅读 Robert Frost 的诗歌《未选择的道路》来解释反事实。在这首诗中,叙述者谈到必须在穿过树林的两条路之间做出选择,并表达了不知道另一条路通向哪里的遗憾。Bhattacharya 说: “他在想象,如果自己走上一条不同的道路,他的生活会是什么样子。”这就是计算机科学家想用因果推理机器去复刻的东西:提出“如果......会如何?”这样的假设问题的能力。
想象如果我们采取不同的行动,结果会是更好还是更糟,这是人类学习的一个重要方式。Bhattacharya 说,给人工智能注入类似的“反事实遗憾”能力是有用的。机器可以根据它没有做出的选择来运行场景,并量化它做出不同的选择是否会更好。一些科学家已经利用反事实遗憾来帮助计算机改进扑克游戏[6]。
想象不同情景的能力也可以帮助克服现有人工智能的一些局限性,例如难以应对罕见事件。Bengio 说,根据定义罕见事件在系统的训练数据中即便出现了,也会非常稀疏,以至于人工智能无法学到它们。一个开车的人可以想象从未见过的场景,比如一架小飞机降落在路上,然后基于他们对事情如何运作的理解,定制化设计潜在策略以应对这种特殊情况。然而,如果一个自动驾驶汽车没有因果推理的能力,那么它最多只能对路上的物体做出一般性的响应。通过使用反事实来学习事物如何运作的规则,汽车可以更好地为罕见事件做准备。从因果规则出发,而不是一长串过去发生过的案例列表,最终使系统更加通用。
利用因果关系将想象力编程到计算机甚至可能创造出自动化科学家。在微软研究院主办的2021年在线峰会上,Pearl 认为,这样的系统能够生成假设,能够挑选用于检验这个假设的最佳观测数据,以及能够决定如何设计实验以产生这样的数据。
将因果纳入人工智能
但是现在,还有很长的路要走。因果推理的理论和基础数学已经确立,但人工智能实现干预和反事实的方法仍处于初级阶段。Bengio说:“这仍然是非常基础的研究。我们正处于以非常基础的方式弄清楚算法的阶段。”等到研究人员掌握了这些基本原理,还需要继续对算法进行优化,以便能高效运行算法。目前还不确定这一切需要多长时间。Bengio说:“从我的感觉上看,既然已经拥有了全部概念工具,解决剩下的可能只是几年的问题。不过通常实际需要的时间要比预期长,甚至可能还要数十年之久。”
Bhattacharya 认为,研究人员应该借鉴机器学习。机器学习的迅速发展,在一定程度上是因为程序员开发了开源软件,让其他人能够使用编写算法的基本工具。同样道理,因果推理的工具化也会产生类似的效果。Bhattacharya说,“包括一些来自科技巨头微软和卡内基·梅隆大学的开源软件包,最近几年有很多进展令人兴奋。”他和同事们也开发了一个开源的因果模块,称为“Ananke”。目前这些软件包仍在持续开发中。
Bhattacharya 还希望在计算机教育的早期阶段引入因果推理的概念。他说,目前这一主题主要在研究生阶段教授,而机器学习在本科生培训中很常见。他说:“因果推理是非常基础的,我希望看到它以某种简化的形式也被引入高中阶段。”
如果研究人员能够成功地将因果纳入计算,那么人工智能的灵活度将会达到一个全新的水平。机器人可以更容易地为自己导航。自动驾驶汽车可能会变得更加可靠。评估基因活性的计划可能产生对生物机制新的理解,进而转化为更新、更好药物的开发。“这会改变医学。” Bengio 说。
即使是像 ChatGPT 这样流行的自然语言生成器,能让生成的文本读起来就像是人写的一样,也可以通过纳入因果从中获益。现在的算法会自我背叛,它会写出自相矛盾的文字,或者其表述违背了我们所知世界的真相。纳入因果的 ChatGPT 可以为它试图表达的内容构建一个连贯的计划,并确保它与我们所知道的事实一致。
当被问及这是否会让作家失业时, Bengio 表示这可能需要一段时间。他说:“如果你在十年后失去了工作,但是却被治好了癌症和阿尔茨海默氏症呢?这也是一笔不错的买卖。”
参考文献
[1] Shao, X. M. et al. Cancer Immunol. Res. 8, 396–408 (2020).
[2] Chiu, H.-Y., Chao, H.-S. & Chen, Y.-M. Cancers 14, 1370 (2022).
[3] DeGrave, A. J., Janizek, J. D. & Lee, S.-I. Nature Mach. Intell. 3, 610–619 (2021).
[4] Pearl, J. Commun. ACM 62, 54–60 (2019).
[5] Deleu, T. et al. Preprint at https://arxiv.org/abs/2202.13903 (2022).
[6] Brown, N., Lerer, A., Gross, S. & Sandholm, T. Preprint at https://arxiv.org/abs/1811.00164 (2019).
原文题目:Why artificial intelligence needs to understand consequences
原文链接:https://www.nature.com/articles/d41586-023-00577-1
本文来自微信公众号:集智俱乐部 (ID:swarma_org),作者:Neil Savage,翻译:毛迎荣