
作者| 宇多田
出品| 虎嗅科技组
封面来自视觉中国
如果能给人工智能与科学计算产业设一个热搜榜,那么从昨晚到今天,榜单只有两个热词:
英伟达停货,AMD停货。
作为全球顶级计算芯片企业,两家的公告几乎一夜之间刷遍算法工程师的朋友圈:英伟达的云端加速器系列A100与H100,以及AMD的数据中心级GPU MI100与MI200,都将暂停向中国客户发货,等待下一步通知。

虎嗅第一时间联系了英伟达与AMD官方联系渠道,得到的回答均为“不予回复”。但这个消息,已经得到了国内产业相关采购人士的证实。
昨日,一份由英伟达在8月26日提交给美国证券交易委员会(SEC)的报告里明确显示,出口英伟达的服务器GPU A100与H100系列,需要向政府申请新许可证。
“未来峰值性能与芯片I/O性能等于或大于A100的任何英伟达产品,以及包含这些电路的任何系统,都需要遵照新的许可要求。” 文件里特意标注出受限的产品型号。
换句话说,代际在A100之后的高端AI加速卡系列(包括A100、H100以及与这些硬件产品密切相关的DGX系统),都将在中国市场受到更加严苛的销售限制。
英伟达接受美国媒体采访时承认,自己正在与中国客户做替代产品相关的交涉。虽然在申请新的许可证以延续中国出口项目,但并不清楚政府能否给予豁免。
从中国市场规模来看,英伟达遭受的打击不小。
据英伟达自己估算,2022年第三季度,他们在中国的潜在销售额会减少4亿美元,而此前的预估收入为59亿美元。消息一出,其股价在周三的盘后交易中跌幅达6.5%。

毋庸置疑,英伟达各系列GPU产品一直都是产业焦点。特别是数据中心级加速卡,基本代表着全球图形处理器软硬件的最高水准。
而A100,是在V100发布4年后,于2020年才推出的新一代数据中心级云端加速芯片。
如果说2019年前后,国内华为等中国企业陆续发布了可对标V100系列的产品(很明显,参数上的超越不代表实际应用的超越),那么A100无论从制程(7nm)、架构(Ampere)还是“运算与浮点性能”,都对市面上的其他产品进行了全方位碾压。
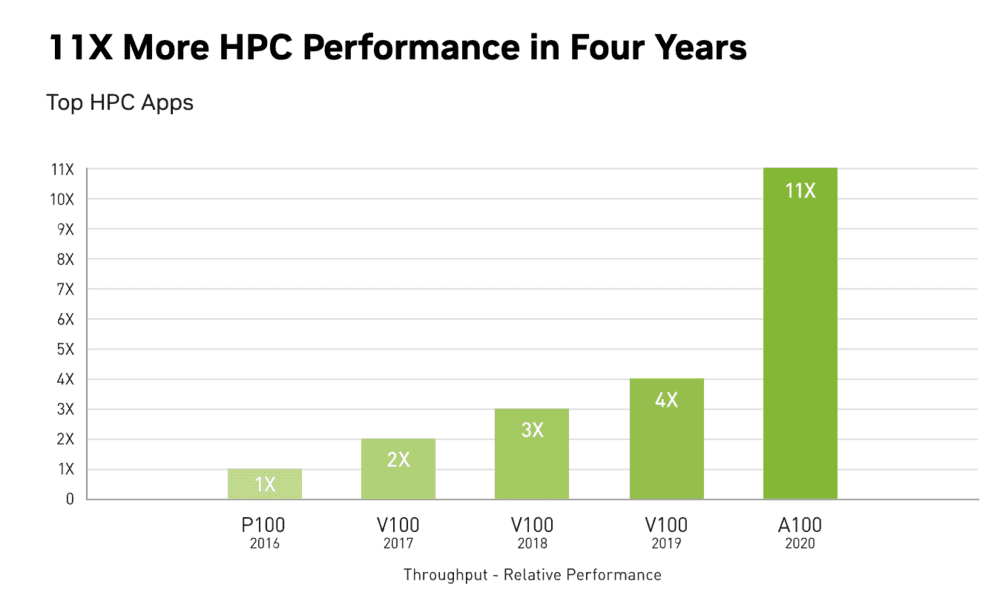
“A100比V100强太多,这不单单是绝对性能的问题,而是在于‘怎么用’。” 一位虎嗅芯片分析师表示,A100在应用层面有很大的想象力,而其配套的算法组件、算法库方面都是顶级的,在软件层面建立的全壁垒优势太难打破。
而基于Hooper架构的H100,则是2022年2月发布可取代A100的新一代异步计算巨兽。
除了比A100多出至少250亿个晶体管,它也在FP16、FP32和FP64计算上比A100快三倍。英伟达曾特别指出,它非常适用于当下流行且训练难度高的“大模型”。
“国内还没有能与这两代加速器相对标的硬件产品与系统能力。” 尽管国内优秀团队与创业公司看起来很多,但一位分析师指出,研发周期跨度至少有3年。
商用影响不大
与强悍性能相对应的,则是昂贵的价格。
以英伟达A100为例,单台 DGX A100 服务器的售价高达19.9万美元,大部分学术机构负担不起,取而代之的是V与T系列的广泛应用。
另一方面,从人工智能覆盖的多产业(人脸、摄像头、金融、客服等等)与自动驾驶的企业级商用市场反馈来看,英伟达与AMD的顶配线一直不在他们的考虑范围内。
“性能虽强大,但对于城市道路级别的感知和规划,就过于大材小用了。自动驾驶对精度的要求,英伟达RTX(游戏)系列与Tesla系列的显卡足以应对。” 多位自动驾驶从业者表示,“性价比”是绝对的第一考量因素。
而近年来,在逐步往汽车市场下沉的过程中,过去不计成本追求高端算力芯片与高端工控机的L4自动驾驶公司,最终在车规级与高性能之间找到了平衡。
譬如在2021年,自动驾驶公司最喜欢做的事情,就是晒“与英伟达车规级Orin芯片的合作证书”。这是一款英伟达专门面向车规级自动驾驶市场开发的“可调节”计算芯片。

而英伟达数据中心云端加速器产品的绝对大客户——服务器厂商与云计算厂商们,或许会喜忧参半。
一方面,2021年规模达到53.9亿美元的中国加速器市场还在不断壮大,GPU服务器占绝对主导。其中,加速卡的采购型号主要集中在英伟达的T4、V100、V100S以及A100系列上,外加少量的AMD与英特尔。
2021年,中国加速卡数量出货超过80万片,其中英伟达占据超过80%市场份额(数据来自IDC)。
“A100的采购量没有那么多,主要还是T4与V100。” 一位云计算产业人士告诉虎嗅,从2021年下半年后,包括云计算和服务器厂商在内,为了应对不断变化的市场环境,在主动降低这类GPU的采购需求。
但另一方面,A100在更多复杂模型训练上的吸引力仍然极大。云巨头和一些有财力的科技公司加起来的购买量至少有万台规模。譬如,国内某家人工智能独角兽企业,采购了上千块A100。
不过值得注意,他们购买A100的理由并非只为商用,而是与“超算”“高性能运算”等领域有密切关系。
“顶配”的科学贡献
就像上面那位虎嗅分析师所说,享用A100与H100这类高端线的机构也需要拥有更多“想象力”。或者说,使用者也需要具备与之相匹配的系统级实力。
2022年5月30日,第59届的全球超算TOP500榜单上,美国橡树岭国家实验室开发的超级计算机Frontier以绝对优势称霸。值得注意,Frontier 有9408个节点,每个节点配置了1个 AMD Epyc CPU 和 4个AMD MI250X GPU。
而橡树岭另一台超算 Summit 排名第四,有4356 个节点,每个节点配置了2个 IBM Power9 CPU和 6个英伟达 V100;而美国能源研究科学计算中心发布的AI超级计算机 Perlmutter 则排名第7,GPU 采用了英伟达的A100。
有趣的是,全球排名第8的超级计算机由英伟达公司自己开发,其每个节点由AMD Epyc CPU与A100组成。
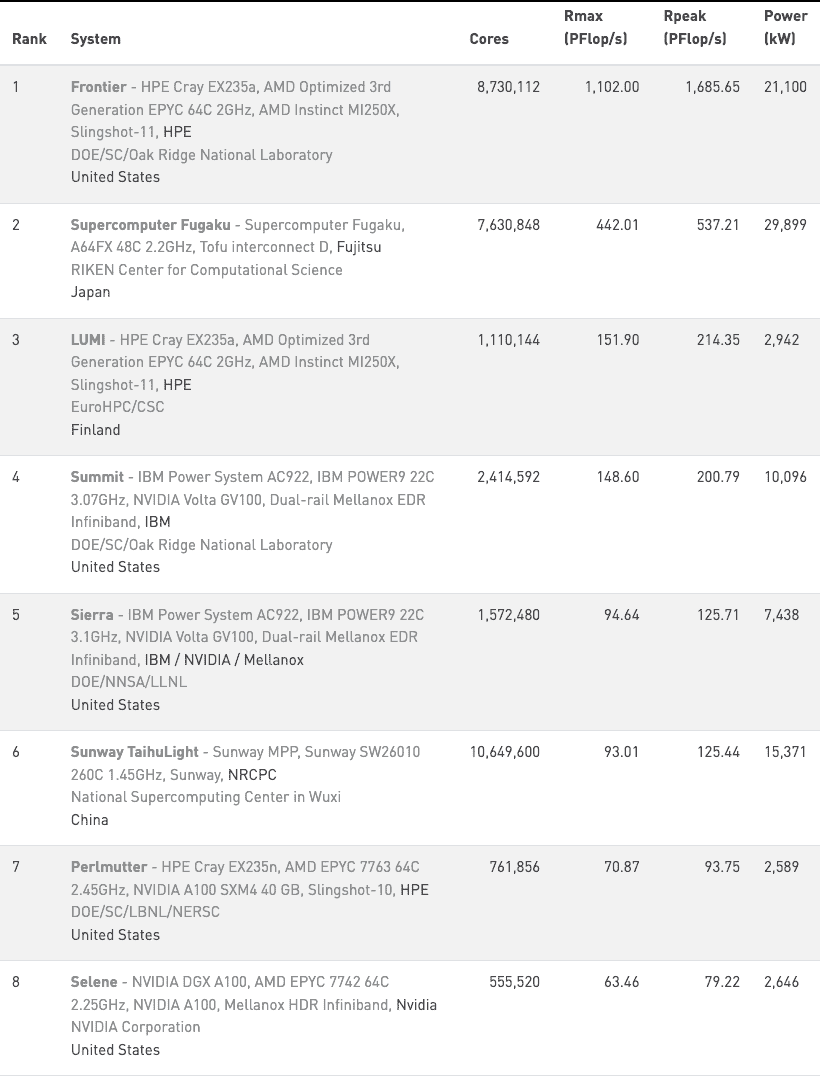
“毋庸置疑,英伟达的高端加速器对大规模科学运算的研究有重大影响力。” 一位国内专攻芯片性能调优的技术大佬指出,在这个市场,英伟达和AMD暂时还没有对手。
而有趣的是,越来越多的商业巨头也开始参与到“高性能运算”领域的技术竞演中。
就在2022年初,转型元宇宙的Meta公开承认,自己正在秘密建设一台名叫“AI研究超星团”(RSC)的AI超级计算机。
虽然Meta建造这台机器的理由,主要集中在“避免受到芯片与零部件供应链的太多牵连”。但实际上,他们早在2017年就建立了一个由2.2万片V100组成的超级计算集群,每天执行3.5万个算法训练任务。
而这次,RSC的任务范围也相应扩大——除了训练与自然语言处理与计算机视觉相关的大模型,也会探索更多未知的科学任务。
“大规模并行运算的研究覆盖面非常广泛,绝不仅仅是人工智能方面的应用。或者说,通过人工智能,可以‘解密’更多自然科学层面的研究。”
一位产业人士表示,“并行计算”也是仿真学、空气动力学、磁学等学科不可或缺的研究工具。譬如,高端工业仿真软件,便需要高性能计算架构的强有力支撑。
“因此,投入和发展这类底层并行计算产品,对我们极为重要。”
我是虎嗅科技组主笔傅博,关注半导体与自动驾驶,欢迎爆料与交流。(微信:fudabo001,请务必备注身份)