
本文内容节选自《拆穿数据胡扯》(由中信出版集团授权),作者:卡尔·伯格斯特龙、杰文·韦斯特,译者:胡小锐,头图来自:《人类灭亡报告书》剧照
当你想到尖端的信息技术时,你可能不会想到美国邮政服务。但事实上,很少有行业如此依赖机器学习的进步。
美国邮政系统每天要处理5亿封邮件,这是一个惊人的数字。如果地球上70亿人每人寄一封信或者一个包裹,美国邮政可以在两周内处理完。尽管每个邮件上的地址都需要正确解读,他们也能按时完成。对于打印的地址,将这项任务委托给机器相当容易。手写地址处理起来难度较大,但美国邮政已经开发出一种优秀的手写识别系统,解读地址的正确率高达98%。这些邮件包括你的医生手写的节日贺卡,你奶奶写给当地国会议员的信,还有你6岁女儿写给动物园要求对刚出生的长颈鹿宝宝进行视频直播的信。
还有2%的邮件机器无法读取地址,该怎么处理呢?它们会被送到盐湖城的一个大型邮政综合大楼。在那里,地址专家分33个班次,每天24个小时,每周7天,解读这些难以辨认的地址。最快的员工每个小时可以处理1800多个地址,也就是说,2秒钟处理一封邮件!速度之快,令人叹为观止。
在完成一些需要做出判断和斟酌选择的开放式任务时,人类干预无可替代。就目前而言,在辨别假新闻、识别讽刺、制造幽默等方面,机器还比不上人类。不过,读取地址对计算机来说还是比较简单的。数字分类问题(例如,判断打印出来的数字是1、2还是3)是机器学习的一个经典应用。
计算机是如何做到这一点的呢?就像我们在猫和狗的例子中描述的那样。首先,收集一组训练数据。我们收集大量被人标记为0,1,2,…,9的手写数字(成千上万的图像)。很多时候,对计算机学习能力的唯一限制是能否找到高质量的标签用于训练机器。幸运的是,美国邮政服务在多年前就创建了一组合适的带标签的手写数字。它被称为MNIST,即改进版美国国家标准与技术研究院手写数字数据库,其中包括7万张类似于下图的带标签手写数字图片。

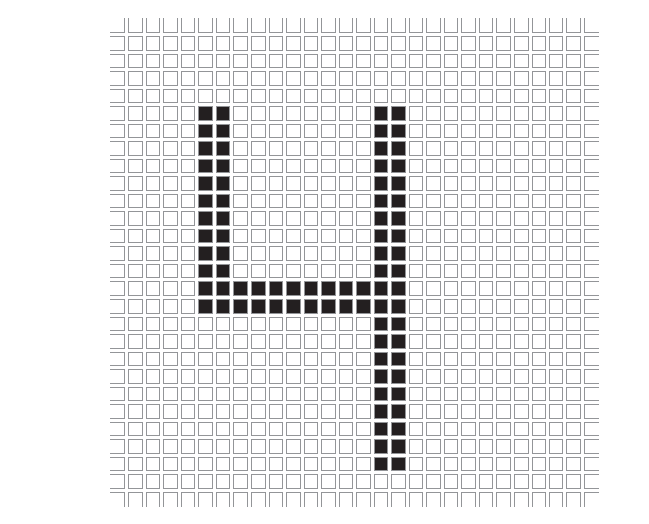
上面这个28行、28列的图像表示数字4。它一共有784个方格,每个方格都用0或1填充。计算机通过这些矩阵“看到”图像。看到数字4意味着计算机识别出了与手写的4相对应的矩阵所具有的独特属性,然后比较类似图像的矩阵。
带有“4”的已知图像是机器学习的训练数据。有了足够的训练数据和惩罚错误的定量方法,就可以教会计算机始终如一地对手写的“4”进行分类。为了评估机器的学习情况,我们向它提供测试数据——它从未见过的数据。处理测试数据是机器学习的关键环节。
通过记忆所有数据点及其所有属性这个基本手段,算法通常可以完美地分类所有的训练数据。对于手写数字,机器可能会记住每个像素的值及其确切位置。从训练数据中选取一幅图像输入机器,它就能很肯定地猜出数字。
但这还不够好。来自现实世界的训练数据总是一团糟,有时是个人的书写风格导致的,有时是扫描图像的质量过差导致的,有时则是因为图像的标签有错误,或者是因为图像直接取自错误的数据集。因为要记住这些噪声,所以当计算机被要求对不属于训练数据集的新图像添加标签时,就会导致问题。如果把训练数据变成测试数据后,计算机添加的标签的准确性显著降低,就说明模型可能出现了过拟合的问题。所谓过拟合,就是在预测时将噪声归为相关信息,这是机器学习的一个难题。
科学家在建立模型预测行星位置时,并不是把每颗行星在每个可能时间的每个位置都分类,而是确定可以预测未来位置的关键物理定律。机器学习的难点是开发能够泛化的算法,也就是说,开发出来的算法可以运用所学到的知识,识别从未见过的模式。
为了更好地理解机器是如何识别模式和进行预测的,让我们看一个只包含深色点和浅色点的示例。但你可以把它看作一个基于各种健康指标判断病人是否患有糖尿病的数据集。假设我们希望提出一个规则,预测一个新的点(不属于该数据集)是浅色还是深色。已有的100个点是我们的训练数据。深色点大多在顶部,浅色点大多在底部,所以我们可能会尝试画一条将深色点与浅色点分开的分界线。



这个更简单的模型并没有为了正确分类所有的点而让分界线变弯曲,也就是说,它没有过拟合训练数据。因此,它在测试数据上的表现与在训练数据上的表现差不多。在测试数据上,该模型错分了6个深色点和5个浅色点。

这只是一个随意设计的小例子,但大多数机器学习应用程序也会遇到同样的问题。复杂的模型可以完美地拟合训练数据,但是简单的模型在测试数据上的表现通常优于那些复杂的模型。诀窍就在于要把握好简单的程度。如果选择的模型过于简单,就会忽视一些有用的信息。
本文内容节选自《拆穿数据胡扯》(由中信出版集团授权),作者:卡尔·伯格斯特龙、杰文·韦斯特,译者:胡小锐