
本文摘编自《危崖:生存性风险与人类的未来》(由中信出版集团授权),作者:托比·奥德(新锐哲学家、未来学家),头图来自:《我,机器人》剧照
1956 年夏天,一小群数学家和计算机科学家聚集在达特茅斯学院,开始了设计智能机器的宏伟计划。他们探索了认知能力的许多方面,包括推理、创造力、语言、决策和学习。他们的问题和立场将决定人工能(AI)这一新兴领域的发展方向。而在他们看来,最终的目标是制造出在智力上可与人类媲美的机器。
几十年过去了,随着人工智能成为一个稳定发展的领域,人们降低了对它的期望。人工智能在逻辑、推理和游戏方面取得了巨大的成功,但在其他一些领域却顽固地拒绝进步。到了 20 世纪 80 年代,研究人员开始理解这种成功和失败的模式。
出乎意料的是,我们视为人类智力巅峰的任务(如微积分或国际象棋),计算机执行起来其实比那些我们认为几乎不费吹灰之力即可完成的任务(如认出一只猫、理解简单的句子或捡鸡蛋)要容易得多。所以,虽然有些领域里人工智能远远超过了人类的能力,但也有一些领域不如两岁孩童。这种未能取得全面进展的情况导致许多人工智能研究者放弃了实现完全通用智能的早期目标,并重新定义他们的领域,为解决具体的问题研发专门的技术。他们放弃了一个不成熟领域里新生热情所追求的更宏大目标。
但情况正在逆转。从人工智能诞生之初,研究人员就试图构建不需要清晰编程就能学习新事物的系统。最早的机器学习手段之一是构建类似于人类大脑结构的人工神经网络。在过去的十年里,这种手段终于有了起色。设计和训练上的技术改进,加上更丰富的数据集和更强大的计算能力,使我们能够训练出比以往更大以及学习能力更深入的网络。
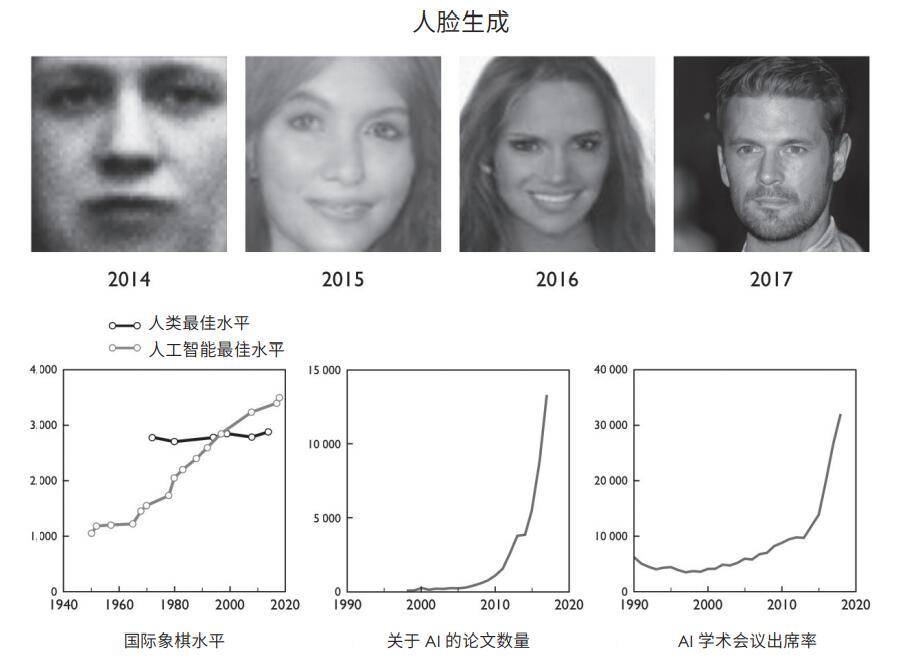
这种深度学习使网络有能力学习微妙的概念和区别。它们现在不仅能识别一只猫,而且在区分不同品种的猫方面,表现也超过了人类。它们比我们更能识别人脸,还能分辨同卵双胞胎。而且我们已经可以将这些能力用于感知和分类以外的领域。深度学习系统可以在不同语言之间进行翻译,其熟练程度接近人工翻译。它们可以生成人类和动物的逼真图像。它们只要听一个人讲几分钟话,就可以用这个人的声音说话。而且它们可以学会精细而连续的操控方式,如学会驾驶汽车或使用机械臂拼乐高零件。
但也许最能预示未来的重要标志是它们学会玩游戏的能力。自达特茅斯会议以来,游戏一直是人工智能的核心部分。持续而稳定的进步使人工智能的国际象棋水平从 1957 年参与业余比赛一直发展到 1997 年超越了人类,而且是大幅领先。要达到这个水平,需要大量的国际象棋策略方面的专家知识。
2017 年,深度学习被应用于国际象棋,并取得了令人瞩目的成果。人工智能公司 DeepMind 的一个研究团队创造了 AlphaZero:一个基于神经网络的系统,从头开始学习下棋。它从新手到象棋大师只用了四个小时。在不到一个职业棋手下两盘棋的时间里,它发现了人类花费几个世纪才发掘出来的策略知识,发挥出了超越顶尖棋手和传统程序的水平。而令棋手们欣喜的是,它赢得比赛的方式不是计算机象棋所代表的枯燥刻板风格,而是让人想起国际象棋浪漫时代的创造性和大胆技法。
但最重要的是,AlphaZero 能做的不仅仅是下国际象棋。它用同样的算法从零开始也学会了下围棋,并在八小时内远远超过了任何人类的能力。世界上最优秀的围棋选手一直认为自己的棋艺已经接近完美,所以很震惊地发现自己被如此彻底地击败。正如卫冕世界冠军柯洁所说:“人类数千年的实战演练进化,计算机却告诉我们人类全都是错的。我觉得,甚至没有一个人沾到围棋真理的边。”
正是这种通用性成了前沿人工智能最令人印象深刻的特点,它重新点燃了让人工智能赶上和超越人类智能各个方面的雄心壮志。这个目标有时被称为通用人工智能(AGI),以区别于曾经占据主导地位的狭隘技术。虽然国际象棋和围棋这些历史弥新的游戏最能展现深度学习所能达到的辉煌成就,但它的广度是通过 20 世纪 70 年代的雅达利电子游戏来揭示的。
2015 年,研究人员设计了一种算法,可以学习玩几十种差异极大的雅达利游戏,其水平远远超过人类的能力。与从棋盘的符号意义开始学习国际象棋或围棋的系统不同,雅达利游戏系统直接从分数和屏幕上的原始像素学习和掌握这些游戏。它们证明了通用人工智能体的概念是可以实现的:通过原始的视觉输入来学习控制世界,在不同的环境中实现其目标。
这种通过深度学习取得的迅猛进展,让人们对可能很快实现的目标极为乐观。企业家们争先恐后地将每一项新的突破付诸实践:从同声传译、私人助理和无人驾驶汽车,到改进监控设备和致命性自主武器等更令人关注的领域。这是一个满怀希望的时代,同时也是一个充满道德挑战的时代。人们对人工智能固化社会歧视、导致大规模失业、支持压迫性的监控以及违反战争准则等问题表示严重关切。
事实上,这些受到关注的每一个领域都可以自成一章或者为此写一本书。但本书关注的是人类面临的生存性风险。人工智能的发展会不会在这个最广泛的范围内构成风险?
最有可能的生存性风险将来自人工智能研究人员的宏伟抱负——成功创造出超越人类自身的通用智能体。但这种情况发生的可能性有多大,以及什么时候会发生呢?
2016 年,有人对 300 多名机器学习领域的顶级研究人员进行了详细调查。当被问及人工智能系统何时能“比人工更好、成本更低地完成每一项任务”时,他们的平均估计是到2061年有 50% 的可能,而到不久后的 2025 年出现这种情况的可能性为10%。
这份调查结果应该谨慎地解读。它评估的并不是通用人工智能何时会被创造出来,甚至不是专家们认为有可能发生什么事情,而且得的预测众说纷纭。然而,这次调查向我们表明,专家群体基本上认为通用人工智能并不是难以实现的梦想,而是有可能在十年内出现的,在一个世纪之内出现的可能性更大。因此,让我们以此为出发点评估风险,并思考如果通用人工智能被创造出来会发生什么。
人类目前还掌握着自己的命运,我们可以选择我们的未来
当然,每个人对理想未来有着不同的看法,我们中的许多人更注重个人诉求,而不是实现任何这样的理想。但如果有足够多的人愿意,我们可以选择任何一种丰富多彩的未来。而对于黑猩猩、山鸟或者地球上的任何其他物种来说,情况就不一样了。正如我们看到的那样(在第一章中),人类在世界上的独特地位是我们独一无二的心智能力所产生的直接结果。无与伦比的智慧带来了无与伦比的力量,从而让我们得以掌控自己的命运。
如果研究人员在本世纪某个时候创造了一种几乎在每一个领域都超越人类能力的人工智能,会发生什么事情?这种创造的行为会使我们把自己的地位拱手相让,使我们不再是地球上心智能力最强的实体。如果没有一个非常好的计划来保持情况受控,我们还会把最强大物种的地位以及可以掌控自我命运的物种这一地位让出来。
就这种情况本身而言,也许并不值得过于担心。因为有很多方法能让我们有希望保持控制权。我们可能会试着制造总是服从人类命令的系统,或者系统可以自由地做它们想做的事情,但它们的目标与我们的目标完全一致——这样,在构筑它们的理想未来时,它们也会构筑我们的未来。不幸的是,为数不多的正在研究这类计划的研究人员发现,这些计划比预期的要困难得多。事实上,提出担忧的主要就是这些研究人员。
为了了解他们为什么担忧,我们需要探讨得再深入一些,审视我们目前的人工智能技术,以及为什么这些技术很难规范或控制。有一项或可让我们最终创建通用人工智能的领先范式把深度学习与早期称为强化学习的理念结合了起来。人工智能体会因在各种情况下表现出的行为而获得奖励(或惩罚)。
例如,一个玩雅达利游戏的人工智能每次在游戏中获得分数时,就会得到奖励,而一个搭建乐高的人工智能体可能在拼好零件时得到奖励。有了足够的智慧和经验,人工智能体就会变得非常善于将环境引导到获得高额奖励的状态。
明确哪些行为和状态会让人工智能体得到奖励的规定被称为人工智能体的奖励函数。这可以由设计者规定(如上述情况)或由人工智能体习得。在后一种情况下通常允许人工智能体观察专业人士对任务的演示,推断出最能解释专业人士行为的奖励系统。
例如,人工智能体可以通过观察专业人士操控无人机来学习,然后构建一个奖励函数,惩罚飞得离障碍物太近的行为,以及奖励到达目的地的行为。不幸的是,这两种方法都不能轻易地上升到在人工智能体的奖励函数中写入人类价值观。我们的价值观太复杂、太微妙了,无法靠手指输入来指定。
而且我们还不能通过观察人类的行为推断出人类复杂的价值观的全部。即使我们能够做到,人类也是由许多个体组成的,他们有不同的、不断变化的以及不确定的价值观。每一种复杂情况都会带来深刻的未解难题,即如何将观察到的东西结合成人类价值观的某种总体表征。
因此,短期内任何使人工智能体与人类价值观相一致的尝试都只会产生一个有缺陷的版本。其奖励函数中将缺失我们所关心的重要部分。在某些情况下,这种错位大多是无害的。但人工智能系统越是智能,越能改变世界,情况就越难办。
哲学和小说经常要求我们思考,当我们为了某些关心的事情而去优化社会,却忽视或误解了一个关键的价值,会发生什么。当我们对结果进行反思时,就会发现这种失序的乌托邦尝试可能大错特错了:我们会像《美丽新世界》里那样浅薄,或者像杰克·威廉森的《无所事事》里那样失去控制权。如果我们不能对齐人工智能体,它们就会努力创造这样的世界并让我们受困其中。
甚至这也属于最好的情况。它假设系统的构建者正在努力使人工智能体与人类的价值观相一致。但我们应该认为,一些开发者会更专注于通过构建系统来实现其他目标,比如赢得战争或实现利润最大化,而且可能不太关注道德约束。这些系统可能危险得多。
这些问题自然会让人们认为,如果我们发现人工智能系统将我们引向一条错误的道路,我们可以直接关闭它们。但到了最后,即使是这种由来已久的退路也可能失败,因为我们有充分的理由相信,一个足够智能的系统有能力抵制我们关闭它的尝试。这种行为不会被恐惧、怨恨或求生等情绪所驱动。相反,它直接来自系统一心一意追求回报最大化的偏好:被关闭是一种丧失能力的形式,这将使它更难获得高额回报,所以系统有动力去避免被关闭。这样一来,回报最大化的终极结果将使高智能系统产生谋求生存这一工具性目标。
而这不会是唯一的工具性目标。人工智能体也会抵制使其奖励函数更符合人类价值观的尝试——因为它可以预知,这将影响它获得当前它认为有价值的东西。它将寻求获得更多的资源,包括计算能力上的、物理上的或者属于人类的,因为这些资源会让它更好地塑造世界以获得更高的奖励。而最终它将有动力从人类手中夺取对未来的控制权,因为这将有助于实现所有这些工具性目标:获得大量资源,同时避免被关闭或者奖励函数被改变。
由于人类干扰所有这些工具性目标在其意之中,它会有动机向我们隐瞒这些目标,直到我们再也来不及进行有意义的抵抗。
对上述情景持怀疑态度的人有时会说,这种情况所依赖的人工智能系统要聪明得可以控制世界,但又要愚蠢得无法意识到这不是我们想要的。但这属于一种误解。因为事实上我们对人工智能动机的简述已经明确承认,系统会发现它的目标与我们的目标不一致——这才是促使它走向欺骗、冲突和夺取控制权的原因。
真正的问题是,人工智能研究者还不知道如何制造这样一个系统:它在注意到这种错位后,会把它的终极价值更新至与我们保持一致,而不是更新它的工具性目标来战胜我们。
我们也许可以为上面的每一个问题都打上补丁,或者找到对齐人工智能的新方法,一次性解决很多问题,或者转向不会引起这些问题的通用人工智能新范式。我当然希望如此,也一直在密切关注这个领域的进展。但这种进展是有限的,我们仍然面临悬而未决的关键问题。
在现有的范式中,足够聪明的人工智能体最终会以工具性目标来欺骗和制服我们。而且,如果它们的智慧大大超过人类本身,我们就不要指望人类会赢得胜利并保持对自身未来的控制了。
人工智能系统会如何夺取控制权?
关于这一点,有一个很大的误解(受好莱坞和媒体的影响),认为需要机器人来实现。毕竟,人工智能怎么能以其他形式在物理世界中行动呢?如果没有机器人的操控者,系统只能产生文字、图片和声音。
但稍加思考就会发现,这些恰恰是需要控制的。因为历史上最具破坏力的人并非最强大的人。希特勒通过话语说服其他千百万人赢得必要的身体上的较量,实现了对世界上很大一部分地区的绝对控制。只要人工智能系统能够诱使或胁迫人们听从它的物理命令,它就根本不需要机器人。
我们无法确切地知道一个系统如何夺取控制权。最现实的情况可能是,系统会使用非人类的微妙行为,我们既无法预测,也无法真正理解,而且这些行为可能针对我们目前无从得知的人类文明弱点。不过我们把自己能真正理解的一种可供说明问题的情况作为可能发生的下限,这一点是有帮助的。
首先,人工智能系统可以进入互联网,并隐藏成千上万的备份,分散在世界各地不安全的计算机系统中,如果原件被删除,备份的副本随时可被唤醒并继续工作。即使只到这一步,人工智能实际上也不可能被摧毁了:想一想清除世界上所有可能有备份的硬盘驱动器会遇到的政治阻碍。
接下来,它可以接管互联网上无数不安全的系统,形成一个大型“僵尸网络”。这将使计算资源的规模急剧扩大,并为控制权升级提供一个平台。它可以从那里获得财富资源(入侵这些计算机上的银行账户)和人力资源(对易受影响的人进行勒索或宣传,或者直接用偷来的钱支付给他们)。
这样一来,它就会像一个资源充足的黑社会犯罪组织一样强大,但更难消灭。这些步骤一点都不神秘 —黑客和普通智商的罪犯已经利用互联网做过这些事情。
最后,人工智能需要再次升级它的控制权。这更多是一种推测,但有许多可实现的途径:接管世界上大部分的计算机,使人工智能拥有数以亿计的合作副本;利用窃取的计算能力使人工智能远远超过人类水平;利用人工智能开发新的武器技术或经济技术;操纵世界大国的领导人(通过讹诈手段,或承诺未来赋予其权力);或者让人工智能控制下的人类使用大规模杀伤性武器来削弱同类。
当然,目前的人工智能系统都无法做到这些事情。但我们正在探索的问题是,是否有可信的途径,能让拥有高度智慧的通用人工智能系统夺取控制权。答案似乎是肯定的。
历史上已经出现过这种情况:具备一定人类智商水平的个体把个人控制权扩张为全球很大一部分区域的控制权,将其作为工具性目标来实现他们的最终目的。我们也看到了人类如何从一个数量不到百万的稀少物种,规模扩大至对未来拥有决定性的控制权。所以我们应该假设,这也有可能发生在那些智力大大超过人类的新实体上,尤其当它们由于备份副本而拥有永久生效的能力,并且能够将缴获的金钱或计算机直接转化为更多副本之时。
这样的结果不一定会导致人类灭绝。但还是很容易成为一场生存性灾难。人类将再也不能掌控未来,我们的未来将取决于一小部分人如何设置计算机系统的接管方式。幸运的话,我们可能会得到一个对人类有利或者还算过得去的结果,否则我们很容易就会永远陷入一个有着重大缺陷或反乌托邦式的未来。
我把重点放在人工智能系统夺取未来控制权的情景上,因为我认为这是人工智能最有可能带来的生存性风险。但其他威胁也是存在的,而且专家们对其中哪一种造成的生存性风险最大存在分歧。
例如,我们的未来存在着逐渐受控于人工智能的风险,在这种情况下,越来越多的控制权被移交给人工智能系统,越来越多的未来以非人类的价值观作为导向。另外,还存在故意滥用超级人工智能系统所带来的风险。
即使这些关于风险的论点在具体细节上是完全错误的,我们也应该密切关注通用人工智能的发展,因为它可能带来其他不可预见的风险。如果人类不再是地球上最有智慧的主体,这种转变很容易就成为人类在宇宙中地位的最大变化。如果围绕这一转变而发生的事件决定了我们的长期未来 —无论是好是坏,我们都不应该感到惊讶。
人工智能帮助人类改善长期未来的一个关键方法是提供保护,使我们免受其他生存性风险伤害。例如,人工智能可以让我们找到解决重大风险的办法,或者识别出本来会让我们意想不到的新风险。人工智能还可以让我们的长期未来比任何不依赖人工智能的前途都要更加光明。因此,人工智能发展可能会带来生存性风险的想法并不是劝我们放弃人工智能,而是提醒我们要谨慎行事。
认为人工智能会带来生存性风险的想法显然是一种推测。事实上,这是本书中推测性最强的重大风险。然而,一个危害极大的推测性风险,可能比一个概率极低的确信风险(如小行星撞击的风险)更为重要。我们需要找到办法来验证这些推测成真的可能性到底有多大,一个非常有用的切入点是听听那些在这个领域工作的人对这个风险的看法。
奥伦·埃齐奥尼(Oren Etzioni)教授等坦率直言的人工智能研究人员将这种风险描绘成“非常次要的争论”,认为虽然像斯蒂芬·霍金、埃隆·马斯克和比尔·盖茨这样的名人可能会深感忧虑,但真正从事人工智能研究的人并不担心。如果这是真的,我们就有充分的理由怀疑人工智能的风险并不大。但即便只是简单了解一下人工智能领域领军人物的言论,也会发现事实并非如此。
例如,加州大学伯克利分校教授、人工智能领域最受欢迎和最受推崇的教科书作者斯图尔特·罗素就强烈警告过通用人工智能带来的生存性风险。他甚至成立了“人类兼容人工智能中心”(Center for Human-Compatible AI),致力于解决人工智能的对齐问题。
在应用领域,沙恩·莱格(DeepMind 的首席科学家)提出了生存危险警告,并协助推动了人工智能对齐问题的研究。事实上,从人工智能发展早期到现在,还有很多其他重要人物发表过类似言论。
这里的分歧其实比表面上看起来要小。那些淡化风险的人的主要观点是:
(1)我们很可能还有几十年的时间才能让人工智能与人类能力相匹敌或超过人类水平;(2)试图立即制约人工智能研究将是一个巨大的错误。然而那些提出谨慎看法的人其实并没有质疑这两点:他们一致认为,实现通用人工智能的时间范围是几十年,而不是几年,并且他们通常建议研究人工智能的对齐问题,而不是监管问题。
因此,实质性的分歧并不在于通用人工智能是否可能或有证据显示它对人类构成威胁,而是一个看似几十年后才会出现的潜在生存威胁是否应该引起我们目前的关注。而在我看来,答案是肯定的。
造成这种明显分歧的根本原因之一是对“适当保守”的看法不一。一个更早的推测性风险很好地说明了这一点,当利奥·西拉德和恩里科·费米第一次谈论制造原子弹的可能性时说道:“费米认为保守的做法是淡化这种可能性,而我认为保守的做法是假设它会发生,并采取一切必要的预防措施。”
2015 年,在波多黎各一次关于人工智能未来的开创性会议上,我看到了同样的互动。每个人都承认,通用人工智能在实现时间方面的不确定性和意见分歧要求我们对进展使用“保守假设”——但有一半人使用这个词是因为考虑到令人遗憾的缓慢科学进展,而另一半人则是考虑到同样令人遗憾的风险出现之快。
我相信,目前有关是否应该认真对待通用人工智能风险的拉锯局面,很大程度上归因于人们对有关人工智能未来进展的负责任的、保守的推测意味着什么,持有不一致的看法。
波多黎各会议是关注人工智能生存性风险的一个分水岭。会议达成了实质性的协议,许多与会者签署了一封公开信,表示要开始认真研究如何使人工智能既强大又对人类有利。两年后,又有一场规模更大的会议在阿西洛马召开,选择这个地点是为了呼应著名的 1975 年遗传学会议。
在当年那次会议上,生物学家们齐聚一堂,颇有先见之明地商定原则,以管理可能很快实现的基因工程。在 2017 年的阿西洛马,人工智能研究者商定了一套阿西洛马人工智能原则,以指导该领域以负责任的方式长期发展。其中包括专门针对生存性风险的原则:
能力警惕:由于尚未达成共识,我们应该避免对未来人工智能的能力上限做出较为肯定的假设。
重要性:高级人工智能可代表地球生命史上的一次重大变化,应该以与之相称的注意力和资源来进行规划和管理。
风险:对于人工智能造成的风险,尤其是那些灾难性和毁灭性的风险,必须付出与其可造成的影响相称的努力,以用于规划和缓解风险。
或许了解人工智能研究者真实想法的最佳窗口是 2016 年对人工智能重要研究人员的调查。除了询问通用人工智能是否以及何时可能被开发出来,调查者还询问了风险问题:70% 的研究人员同意斯图尔特·罗素关于为什么高级人工智能可能会带来风险的宽泛论点;48%的人认为社会应该优先考虑人工智能的安全问题(只有 12% 的人认为不需要)。而一半的受访者估计通用人工智能造成“极其糟糕(如导致人类灭绝)”的长远影响的概率至少是 5%。
我觉得最后一点特别了不起——有多少其他领域的典型顶尖研究者会认为该领域的最终目标有 1/20 的概率对人类极其不利?
当然这并不能证明风险是真实存在的。但它说明了很多人工智能研究者对通用人工智能在 50 年内获得发展以及成为一场生存性灾难的可能性持严肃态度。虽然有很多不确定性和分歧,但它绝对不是一个次要问题。
当有更多研究人员承认人工智能的风险时,有一个对风险持怀疑态度的值得关注的论点就变得更加有力——而非站不住脚。如果研究人员能够预见构建人工智能将是极其危险的,那么他们到底为什么要做这件事呢?他们不会只是为了建造出明知会毁灭他们的东西。
如果我们都真正明智、利他且相互协作,那么这个论点确实说得通。但在现实世界中,人们往往一有机会就先开发技术,之后再处理后果。
其中一个原因来自我们的理念差异:哪怕只有一小部分研究人员不相信人工智能的危险性(或者欢迎由机器控制的世界),他们都会成为迈出最后一步的人。这就是单边主义诅咒的一个例子。
另一个原因与动机有关:即使一些研究人员认为风险高达 10%,但如果他们认为自己会获得大部分利益,那可能还是会愿意承受风险。从他们的自身利益来说,这可能是合理的,但对世界来说却不堪设想。
在某些类似的情况下,政府可以为了公共利益而介入,解决这些协调和动机问题。但在这里,这些完全相同的协调和动机问题出现在国家之间,而且没有简单的机制来解决。如果一个国家要缓慢而安全地解决它们,则可能担心其他国家试图夺取其工作成果。缔结条约变得异常困难,因为核查其他国家是否遵守条约比核查生物武器更加困难。
我们能否在人工智能的发展中生存下来,并保持我们的长期发展潜力完好无损,有可能取决于我们能否在开发出足以构成威胁的系统之前学会对齐和控制人工智能系统。值得庆幸的是,研究人员已经在研究各种关键问题,包括如何让人工智能更安全、更稳健、更易理解。但研究让人工智能与人类价值观对齐这一核心问题的人仍然很少。这是一个新兴的领域,我们需要在该领域取得长足的进步,才能实现自身的安全。
尽管目前以及可预见的系统不会对人类整体构成威胁,但时间是最关键的。一部分原因是人工智能的进步可能来得非常突然:通过无法预知的研究突破,或通过迅速扩大第一代智能系统的规模(例如将其推广到数量为目前数千倍的硬件上,或者提高它们自身的智能)。另一
部分原因是人类事务中如此重大的变化可能需要超过几十年的时间来充分准备。用 DeepMind 的联合创始人德米什·哈萨比斯的话来说:
我们要利用人工智能发展的停顿期,在风平浪静的时候为今后几十年事态严重起来之时做好准备。我们现在拥有的时间是宝贵的,需要利用起来。

本文摘编自《危崖:生存性风险与人类的未来》(由中信出版集团授权),作者:托比·奥德(新锐哲学家、未来学家)