
本文来自微信公众号:严肃的人口学八卦(ID:renkou8gua),作者:胡文波,责编:李婷,图编:胡文波,题图来自视觉中国
怕是每个人都玩过人格测试类的小游戏,从纸媒时代意林上的心理测试题大全,到如今各种朋友圈刷屏的人格类型小程序,高质量人类们在对自己的人格特征这一块探究的欲望从未衰减,被割的韭菜也是一茬又一茬。
最近一个爆款人格测试当属网易云音乐前几个月推出的“人格主导色”,而且也上了微博热搜,阅读量达3.3亿,讨论9万,可谓是狠狠地抓住了流量收割密码。


虽然近些年来人格测试小游戏各种形式层出不穷,但究其本质来看,可以大致分为两种:一种是让用户回答和自身相关的陈述题的相符合程度,另一种则是让用户根据提供的声音、图像、情境等选择自己的看法,然后得到一个自身的人格评价。而这也对应了心理学人格测量中的自陈量表和投射测验两种测量类型。
如果要从科学角度来说,想要知道自己真实的人格类型是什么,还是得采用心理学上经典的人格测量方法,如我们耳熟能详的MBTI职业性格测试以及五大人格等。而现如今,越来越多的研究者们也热衷于运用大数据方法分析人们的人格特质。
一、大数据如何能识别人格?
《人格心理学》的作者Burger把人格定义为稳定的行为方式和发生在个体身上的人际过程。而我国著名的心理学家彭聃龄则提出人格是构成一个人的思想、情感及行为的特有的统合模式,这个独特模式包含了一个人区别于他人的稳定而统一的心理品质。可见人格一个重要的特点就是稳定性,而这种稳定的人格特征则会反映在我们生活当中的方方面面。
作为互联网原住民的我们,个人信息以及用户行为等都在社交网络上被记录下来。
一方面,我们在社交网络上留下了许多结构化数据,例如我们的性别、年龄、地区、朋友的数量等。
另一方面,社交网络上也包括许多关于我们的非结构化数据,如发表的文字评论,转发的生活照片以及视频、给某篇公众号文章点赞等。如果从大的时间情境下来看,这些非结构数据也通常具有相对的内在一致性,是我们人格的重要的外在表征。
因此,从社交网络用户中收集到的海量用户数据(文本、数字、图像等),无疑可以作为人格识别中的重要依据。研究者也通常可以利用这些数据,在一定准确性的前提下,通过恰当的数据分析方法推断人们背后的人格特质。
二、大数据如何来识别人格?
心理学中关于个体的差异有着许多的人格理论,而在人格分析当中最常用的是特质理论模型,即大五人格理论模型。五个方面的人格特质分别为开放性、尽责性、外向性、宜人性、神经质,研究者们认为这五个方面可以涵盖一个人人格的所有方面。并且由于其运用数值统计量化人格特征,也通常被运用于计算机领域中对人格进行测量。
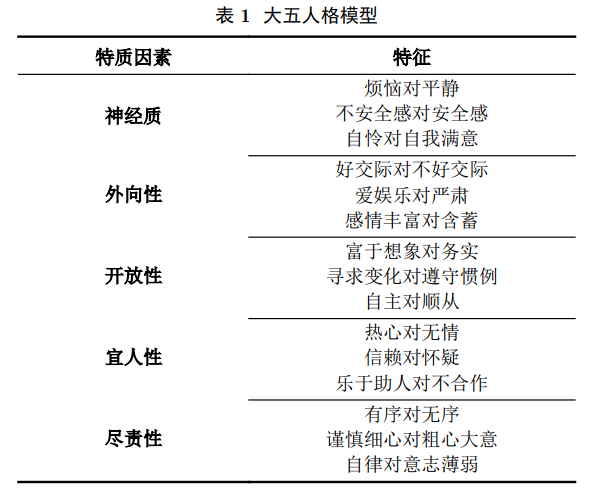
运用大数据识别人格的基本方法是首先使用问卷调查的方法,让调查用户填写心理量表获取用户的大五人格特质得分;同时获取调查用户在使用社交网络时产生的与用户自身相关的数据,进而利用大数据分析的方法将用户人格特质数据与用户相关数据进行关联,最终建立起模型对人格进行预测,实现对其他用户人格的识别。
那么在具体的研究当中,又可以根据社交媒体中的哪些数据来源来对人格进行识别呢?
一方面,可以利用文本资料来对人们的人格特质进行推断,例如我们的个人昵称、在社交平台上的个人介绍以及发表的评论等。有学者就根据微博用户发送的文本内容来识别人格特质。其研究发现:
开放性得分高的人倾向于发表较长篇幅的内容,使用第一人称和第三人称形式,并且更多使用情绪词和焦虑词
尽责性得分高的人在文本中不喜欢用分号
外向性得分高的人多使用第二人称形式,并且喜欢使用缩写形式以及表情使用和惊叹语气词
宜人性得分高的人则倾向于使用积极的情绪词,并且不怎么说脏话
神经质得分高的人,更多喜欢用第三人称形式,并且自我描述的内容也较多
另一方面,图像资料也颇受研究者们的青睐。一项针对推特用户的研究中,研究者就利用用户头像的图像、图像色彩以及面部表情等特征来推断使用者的人格特质。其研究发现:
开放性得分高的人更加倾向于使用清晰度高、色彩更少的用户头像,这是因为他们通常具有更高的审美要求但更少的情绪体验
尽责性的人则更加喜欢使用侧脸、颜色亮丽以及带有微笑的面部表情作为用户头像,这是因为他们更加倾向于让自己看起来更加成熟稳重以及更加被值得信赖
外向性得分高的人更加喜欢使用与外界相关联的用户头像,如使用合照以及突出周围环境的图像
宜人性得分高的人更加喜欢使用面部带有积极情绪的用户头像
神经质得分高的人更喜欢使用简单、无色彩、面部无表情的用户头像
此外,我们在社交媒体中的一些结构数据也能被用作识别人格,如我们在社交网络中的朋友数量、上传的照片数量以及参加群组的数量。一项利用Facebook的My Personality数据的研究利用这样的结构数据和大五人格特征得分进行了相关性分析。
开放性得分高的人更新动态的频率、点赞的频率更高,并且加入的群组数量也更多
尽责性得分高的人点赞频率更低、加入的群组数量更少,但却更加倾向于在社交媒体上上传照片
外向性得分高的人则更加频繁更新社交媒体的状态,并且喜欢向朋友分享生活近况和表达自己的感受
神经质得分和用户在社交媒体上朋友数量有着有趣的关系,神经质得分随着朋友数量的增加呈现出先上升后下降的关系
在神经质维度上的关系,一个可能的解释是,神经质得分高的人可能需要从朋友那里获取更多支持来缓解自己的负面情绪,而这种支持只能从少数的亲密朋友那里获得。因此,对于神经质得分高的人来说,朋友数量在达到一定程度后,便不再增加。但尽管神经质得分高的人在社交媒体上有更少的朋友,但通常有着更加密切的联系。
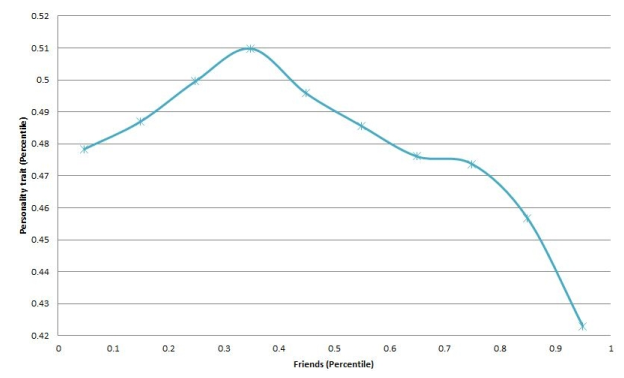
图表来源:Bachrach Y, Kosinski M, Graepel T, et al. Personality and Patterns of Facebook Usage.
三、小结
在过去的十几年中,社交媒体的普及使得研究者们利用大数据进行人格识别成为可能。基于个体的用户信息和行为特征,研究者可以从个体细小的足迹中窥探背后隐藏的人格特质。并且,随着研究的深入,利用大数据识别人格的精确性也不断提高,有学者将其概括为以下几个方面:
研究样本量的不断增加。研究的大样本量可以保证了研究结果的外部效度。
数据来源的多元化。由于社交平台之间的差异性,用户通常会在不同的社交平台上表现出不同的人格特征,组合不同的信息来源可以更加全面反映用户的人格特质。
单一维度的特征提取精细化。对于单一维度的数据如文本数据,研究者往往可以从多个方面提取出更多的有效信息,从而使结果更加准确。
分析维度的多元化。在利用用户数据时,研究者越来越倾向于采用文本、图像、语音等多维度相结合的方式进行识别,多维度的分析方式也增加了研究结果的可靠性。
算法实现的多元化。相比于早期研究,近几年的研究中,研究者会结合不同的算法来识别人格,以此来提高准确性。
但同时也要看到,大数据并不是万能的,由于其自身存在的一些特性,在运用到社会研究领域时通常会面临到很多问题。计算社会学家马修·萨尔加尼克将这些不利因素概括为不完整性、难以获取、不具代表性、漂移、算法干扰、脏数据以及敏感性。在未来,如何更好地利用大数据资源服务于社会研究,仍然需要研究者们更多的探索。
参考文献:
郑敬华,郭世泽,高梁,赵楠.基于多任务学习的大五人格预测[J].
中国科学院大学学报,2018,35(04):550-560.吴桐,郑康锋,伍淳华,王秀娟,郑赫慈.网络空间安全中的人格研究综述[J].
电子与信息学报,2020,42(12):2827-2840.费定舟,赵雅婷.社交媒体中的人格计算研究综述[J].计算机工程与应用,2019,55(20):34-42.
Liu L, Preotiuc-Pietro D, Samani Z R, et al. Analyzing personality through social media profile picture choice[C]//Tenth international AAAI conference on web and social media. 2016.
Bachrach Y, Kosinski M, Graepel T, et al. Personality and Patterns of Facebook Usage[C]// Proceedings of the 4th Annual ACM Web Science Conference.2012,24-32.
Farnadi G, Sitaraman G, Sushmita S, et al. Computational personality recognition in social media[J]. User modeling and user-adapted interaction, 2016, 26(2): 109-142.
本文来自微信公众号:严肃的人口学八卦(ID:renkou8gua),作者/图编:胡文波(中国人民大学社会与人口学院本科生),责编:李婷(中国人民大学社会与人口学院教授)