
本文来自微信公众号:神经现实(ID:neureality),作者:Ananthaswamy,译者:叶卓扬、山鸡,审校:Yihan,头图来自:《超体》剧照
2011年的冬天,麻省理工学院计算神经科学博士后的丹尼尔·亚明思(Daniel Yamins),时不时会为他的机器视觉项目而忙至深夜。他在尝试设计一种能识别图像里的物体的系统。这种识别能力不会因物体的大小、位置或其他属性而改变——人类通常能轻易地这样识别物体。这个系统被称之为深度神经网络,这是一个被大脑神经的组织方式启发而来的计算工具。
“我仍然清晰地记得找到能真正处理那个问题的神经网络的时刻”,他说。那是凌晨两点,因为时间尚早,亚明思不敢叫醒他的导师詹姆斯·迪卡洛(James DiCarlo)或者其他同事,于是决定在剑桥市的冷风中散散步,缓解自己激动的心情。“我真的很兴奋”,他说道。
这个发现仅在人工智能领域就足以被看做一个亮眼的成就,它让神经网络在未来几年备受人工智能技术的青睐。但这并非亚明思和他同事的主要目标:对于他们和其他神经科学家而言,这是发展计算模型以研究大脑功能进程的一个重要转折点。
迪卡洛和在斯坦福大学拥有自己实验室的亚明思一样,属于一批同样使用深度神经网络来理解大脑组织结构的神经科学家。大脑分工处理任务的缘由令科学家们费解。他们不理解为何不同大脑区域负责处理不同的任务,以及为何这些区别可以如此具体:比如,为何大脑中存在一个识别物体的脑区,专门负责脸部识别?深度神经网络显示,区域分化或许是处理问题的最高效的办法。
目前就职于斯坦福大学的计算神经科学家丹尼尔·亚明思解释到,一个能像大脑一样分层处理场景图片特点的神经网络,识别物体的能力可以和人相媲美。
类似的,研究者也发现那些最擅长处理语音、音乐和模拟气味的深度神经网络有着类似于大脑听觉和嗅觉系统的结构。这样的相似性也存在于可以通过二维场景来推测三维物体属性的深度网络里。这也间接解释了生物认知的迅速和丰富。这些研究结果暗示着,生物神经系统的结构本身就承载着他们所负责的任务的最佳解法。
长久以来,神经科学家对大脑和深度神经网络的对比研究一直抱有质疑的态度,他们认为这类对比的意义难以捉摸。考虑到这些质疑,(对比研究的)成就更显得出乎意料。“说实话,以前我实验室里没有一个同事做和深度网络相关的研究”,MIT的神经科学家南希·坎维什尔(Nancy Kanwisher)说道,“现在,大部分同事都在定期训练深度网络。”
一、深度网络与视觉
人工神经网络(Artificial neural network)的搭建基于一种叫作感知器(perceptron)的组成部分。这些感知器互相关联,代表生物神经元的简化数字模型。神经网络至少有两层感受器,一层负责输入,一层负责输出。如同三明治一样,一层或多层隐藏层(hidden layer)夹在输入和输出之间,形成一个“深度”神经网络。这些隐藏层越多,网络就越为“深度”。
深度网络可以通过训练来寻找数据的规律,比如,我们可以训练网络寻找猫狗图像的规律。训练方法是,使用算法来定期地调整感知器之间关联的强度,网络可以学会将一个给定的输入(一个图像的像素)和一个正确的标签(猫或狗)对上号。一旦训练好了,深度网络理论上便能将一个没有见过的输入内容正确分类。
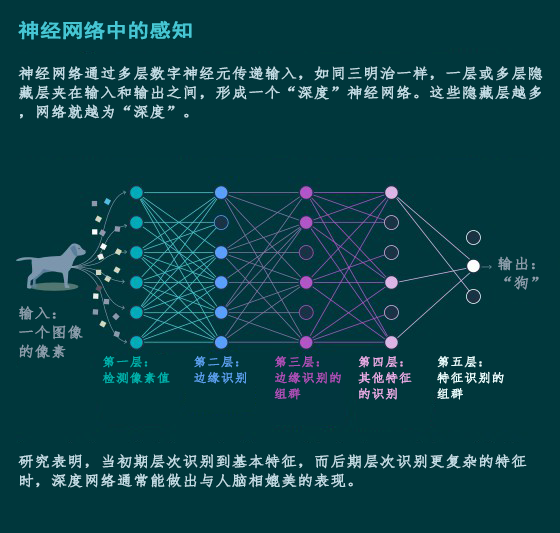
深度网络的一般结构和功能都旨在模仿大脑,而大脑中的神经元联结强度反映的就是习得的关联强度。神经科学家时常得指出这个对比中重要的局限:比如,神经元能比简单的感知器更全面地处理信息,以及深度网络常常依赖于感知器之间的一种叫反向传播*的联络,这种联络似乎并不存在于神经系统中。尽管如此,对于神经科学家来讲,深度网络有时却是模拟大脑结构最好的现有选择。
译者注:反向传播(Backpropagation,BP)是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。(Source: Wikipedia)
研究者开发的视觉计算模型受到灵长类视觉系统,尤其是腹侧通路的影响。该通路负责对人,场景和物体的识别(另一个独立的基本通路,背侧通路,处理物体的动态和位置信息)。在人脑中,腹侧通路加工始于眼睛。信息经过感官信息的中枢——丘脑的外侧膝状体核(LGN),直至初级视觉皮层(V1),随即流向V2和V4,最终引到达下颞叶皮层(非人灵长类大脑中有着相对应的结构)。
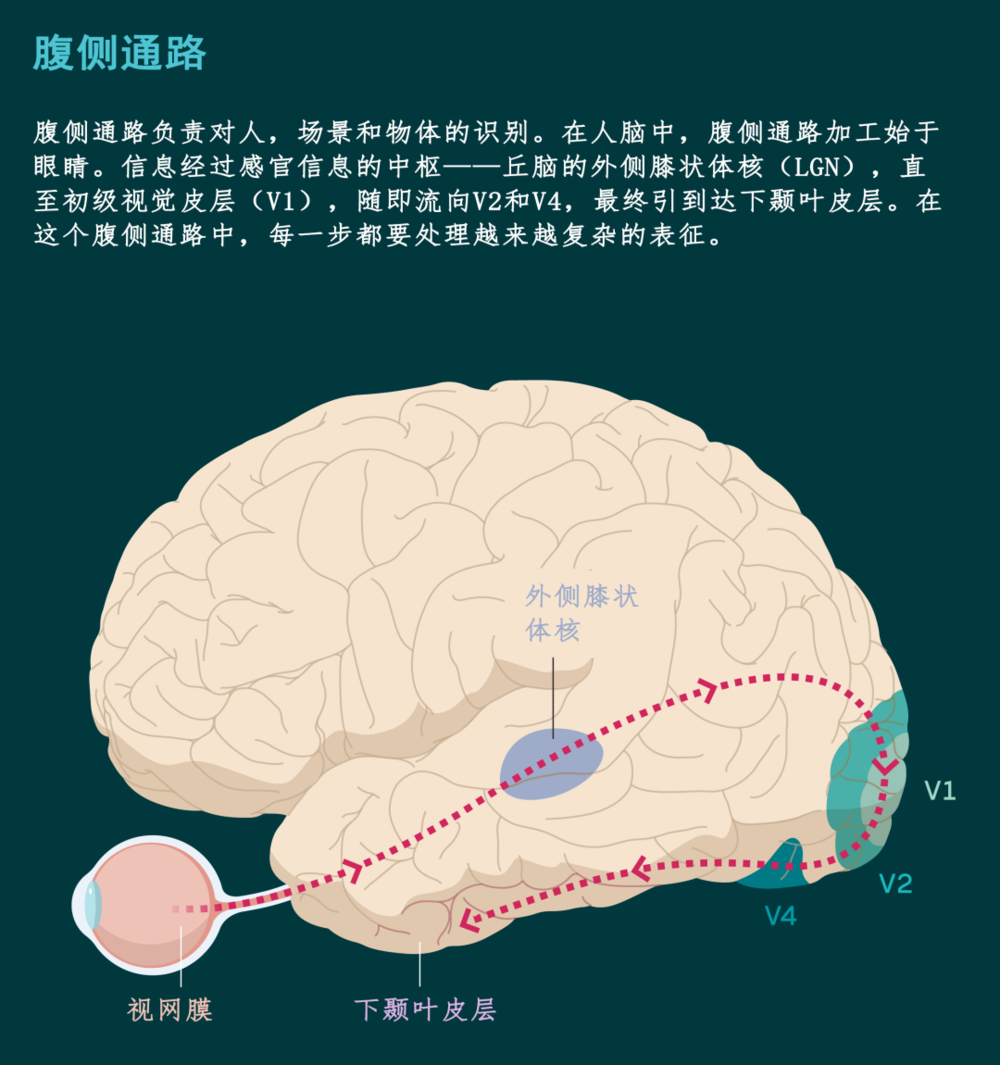
神经科学的关键发现在于,视觉信息处理不仅是分层级的,并且是阶段性的:前期阶段处理视野中初级视觉特征(比如边缘、轮廓、颜色和形状),而复杂的表征,诸如整个物体和面孔,则在随后的下颞叶皮层中进行加工。
这些发现指导了亚明思和同事们对深度网络的设计。他们的深度网络有隐藏层,其中的一部分能进行卷积(convolution)计算,遵循同样的规则对图像的各个部分进行过滤筛选。每个卷积处理不同的关键特征,如(图像)边缘。
如同灵长类动物的视觉系统,网络的早期处理更加初级的视觉特征,而后期处理更复杂的特征。一个像这样的卷积神经网络(convolutional neural network,CNN)进行图像分类训练时,最初过滤分析的初始值是随机的,在训练过程中,该网络能通过学习找到当下任务中的正确值。
这组科学家设计的四层级CNN能够从5760张三维实物图片中识别出八种类型的物体(动物,船只,汽车,座椅,面孔,水果,飞机和桌子)。在姿态、位置和规模上,这些图像中的物体千差万别。尽管如此,深度网络在物体存在差异的情况下仍能做出与人脑相媲美的表现。
亚明思没有想到的是,计算机视觉领域正在酝酿的一场变革,能为亚明思及其同事所采用的方式提供验证。搭建完他们的CNN之后不久,另一个叫做AlexNet的CNN在年度图像识别竞赛中崭露头角。AlexNet同样是基于分层处理搭建的结构,它能在初期识别到基本视觉特征,后期识别更复杂的特征。研究者使用120万张被标记成一千多个类别的图像对该网络进行训练。
在2012年的一次竞赛里,AlexNet打败了所有其他参赛算法:参照竞赛标准,AlexNet的错误率仅为15.3%;相比之下,竞争者中的最好成绩也仍然是26.2%。伴随着AlexNet的胜利,深度网络成为了AI和机器学习领域重要的角逐者。
然而,亚明思和迪卡洛团队的其他成员面临着一个神经科学领域的博弈。他们发问,如果他们的CNN模拟了视觉系统,它能否预测大脑对新颖图像的神经反应呢?为了寻找答案,他们首先将CNN中的人工神经元活动和两只恒河猴腹侧通路中的300处活动对应起来。
接着,他们通过CNN预测当猴子在看到训练中没有出现过的新图像时,大脑会如何反应。“我们不仅获得了不错的预测结果,而且还保证了解剖层面上的一致性。”亚明思接着说,早期、中期和后期的CNN网络层级分别预测了大脑初级、中级和高级三个水平的行为。这说明网络的形式结构和与功能吻合。
坎维什尔还记得看见这篇2014年发表的成果时她的震惊。“它无法证明深度网络中单个单元的行为与生理神经元相同”,她说,“然而,(这个结果说明)二者的功能对应却有惊人的准确性。”
二、量身定制的声音识别
在亚明思和迪卡洛的成果发表之后,科学家们转而寻找与大脑加工拟合程度更好的深度网络模型,尤其是能够拟合除灵长类视觉系统之外的大脑加工系统的模型。比如,“我们对听觉皮层,尤其是人脑的听觉皮层,仍没有较好的认识”,来自MIT的神经科学家乔什·麦德姆(Josh McDermott)说。深度学习可以让我们提出一个更好的假设,从而更深入地理解大脑对听觉刺激的加工吗?
这就是麦德姆的目标。他的团队,包括亚历山大·凯尔(Alexander Kell)和亚明思,开始设计能将言语和音乐两种听觉刺激分类的深度网络。耳蜗是内耳中的声音传导器官,我们对它的了解也比较透彻。
因此,团队通过硬编码(hard-code)首先得出一个耳蜗(cochlea)模型,随后用模型来处理音频,将声音分类出不同的频率,并把它们作为CNN的输入内容。CNN被训练识别语音音频里的词语,以及夹杂噪声的音乐片段所属的流派。这个团队希望找到一种能在不需要太多资源的前提下精准执行这类任务的深度网络构架。
他们找到了三种看似可行的结构:深度网络处理的两个任务要么依赖共同的输入层级,随后分离到两个不同的加工网络;相反的情况也可行,即初期任务能共享加工网络,而仅在输出层级被分离开;或者是介于两种情况之间的混合型网络,一部分网络层被共享,另一些分离。
不出所料,在输入层之后分离的网络比共享加工网络效率更高。然而,一个混合型网络(输入层之后有7个共享层和两个分离的5层级网络)几乎和输入层后分离的网络一样高效。麦德姆和同事们选择了这个耗费计算资源最少的混合型网络。
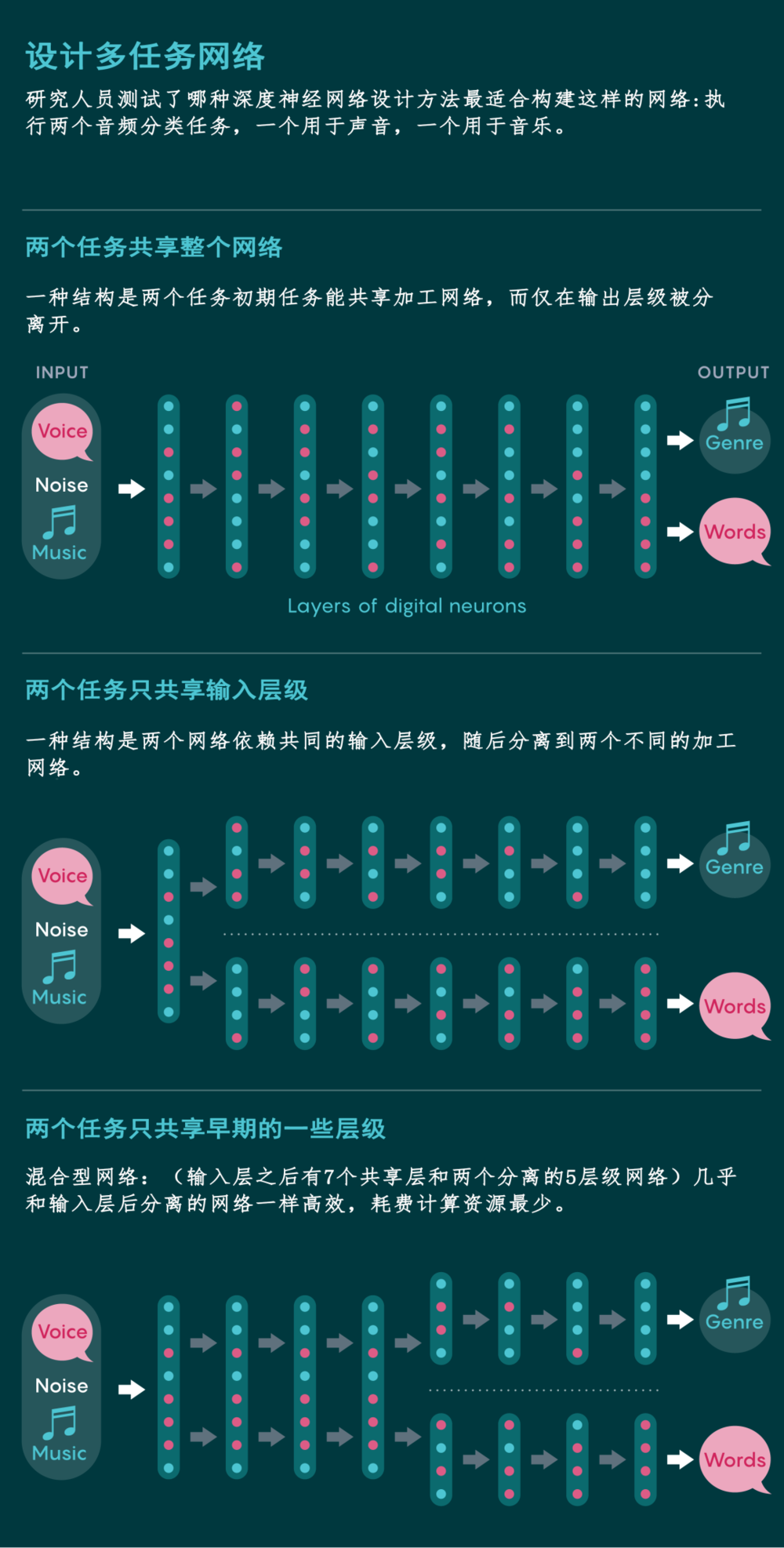
当他们比较混合型网络与人类在任务中的表现时,网络的表现超出了他们的预期。该结果验证了此前一系列研究作出的结论:
非初级听觉皮层中,针对音乐和语言有独立的处理区域。在一份发表于2018年的测试中,这个模型预测了人类被试的大脑活动:这个模型的中层级预测了初级听觉皮层的反应,而深层级预测到了更高级的听觉皮层活动。这些预测结果远比那些不基于深度学习的模型更准确。
“科学的目标就是为了更好地预测系统将如何反应。”麦德姆说道,“这些人工神经网络让我们离神经科学的目标更近一步。”
起初,坎维什尔对深度学习的效果抱有质疑态度,但她在麦德姆的模型里看到了希望。坎维什尔最有名的成就,是她在90年代中后期对一个处在下颞叶皮层的区域的发现。这个区域叫做梭状回面孔区(fusiform face area;FFA),它专门负责于对脸部的识别。相比看着其他物体(比如房子)的图像时,当人们盯着脸部的图像时,FFA就变得非常活跃。为什么人脑要将对面孔的识别从对其他物体的识别中分离开来呢?
传统上而言,让神经科学来回答“为什么”并不容易。因此,坎维什尔和她的博士后凯瑟琳·道布斯(Katharina Dobs)以及同事转向深度网络中寻找答案。他们使用了AlexNet的继任者,一个名为VGG的更加“深度”的卷积网络。他们分别使用面孔识别和物体识别两个任务训练了两个深度网络。
他们的团队发现,被训练去识别面孔的深度网络不能很好地识别物体,反之亦然。这表明,这些网络分别擅长面孔和物体识别。接着,这个团队同时用两种任务训练深度网络。他们发现这个网络在后期阶段中,分化出两个分别处理面孔和物体的结构。“VGG自发地在后期将它们分开”,坎维什尔说道,“任务分离并不一定在初期就要进行。”
这与人类视觉系统的组织方式不谋而合:腹侧视觉流在早期阶段共享,后期分化(外侧膝状体核和V1以及V2)。“我们发现,脸部和物体识别的功能分化在训练了两种任务的网络里自发出现,正如人脑中一样”,目前任职于德国吉森大学(Justus Liebig University)的道布斯说道。
“最让我兴奋的是,我认为我们现在有办法能够回答为什么大脑表现出这样的结构了”,坎维什尔说。
三、气味的分层
在对嗅觉感知的研究中,科学家们发现了更多类似的线索。例如,神经科学家们已经非常熟悉果蝇的嗅觉系统。在2019年,哥伦比亚大学的计算神经科学家罗伯特·扬(Robert Yang)等人设计了一个深度神经网络,试图模拟果蝇的嗅觉系统。
气味处理网络的第一层模拟了嗅觉神经元(olfactory sensory neuron)。每一个嗅觉神经元只表达50种气味受体(odor receptors)中的一种,每一类嗅觉神经元约有10个,嗅觉神经元的种类与下一层的不同神经节一一对应。
因此在第二层中,大脑每侧共有50个这样的神经节。这些神经节和叫做凯尼恩层(Kenyon layer)的下一层里的神经元有着许多随机连接。凯尼恩层中有大约2500个神经元,每一个接收约7个输入信号。
人们认为,凯尼恩层在气味的高级表征中极为重要。气味处理网络的最后一层则有大约20个神经元,在网络中充当输出的角色,而果蝇则利用这种输出信号来引导活动。要注意的是,杨表示,我们还不知道气味处理网络的输出是否称得上是“对气味的分类”。
为了知道设计这样一个计算模型是否现实,扬等人首先创建了一个数据库来模拟气味。气味激活神经元的方式和图像不同。如果你一比一地叠加两张猫的图片,结果可能跟猫的样子相差甚远。然而,如果你混合两只苹果的气味,它闻起来仍会像苹果。“这是我们在设计嗅觉任务时要考虑的关键信息。”扬表示。
他们搭建了一个四层的深度网络,其中三层对应果蝇的处理层,另外一层则是输出层。当扬等人用这个网络来分类数据库中的模拟气味时,他们发现这个网络产生了许多和果蝇大脑相同的连接:一层与二层之间有一对一的映射,二层与三层之间则有一个稀疏(sparse)的随机7比1映射。
这样的相似也就意味着,演化和深度网络都找到了嗅觉分类任务的最佳解决方案。但扬对他们的结果仍持保留意见。“也许我们只是好运罢了。也许(我们的结果)不具有普适性。”
下一步的测试则是演化出能预测其他(还未被研究过的)动物嗅觉系统中神经元连接方式的深层网络。这些网络产生的结果能由其他神经科学家通过实验验证。“这将给我们的理论提供更严格的考验。”扬说。他将于2021年迁至MIT工作。
四、大脑不只是一个黑匣子
深度网络的短版之一是泛化能力的不足。倘若用作训练的数据库与用于检测的数据差异过大,深度网络将无法作出合理的表现。短板之二是有名的黑匣子理论。仅仅是检测塑造深度网络百万级别的参数,我们无法解释这个网络是如何作出决策的。那么,用深度网络来研究大脑是用一个黑匣子来替换另一个吗?
扬不认同这样的观点。他表示:“(即便深度网络非常复杂)研究它还是要比大脑来的简单。”
迪卡洛的研究团队在去年针对深度网络的不可窥探性及泛化性短板发表了一篇研究。在这篇研究中,该团队使用了一类AlexNet网络来模拟恒河猴的腹侧视觉通路,进而探究人工单位神经元与恒河猴V4脑区中神经位点之间的关联。随后,研究团队通过计算模型合成了一张可能在恒河猴神经元中激发高水平神经活动的图像。
在实验中,这些“非自然”图片在恒河猴68%的神经位点中激发了高于自然水平的神经活动;此外,这些图片在提升某个神经元活动水平的同时,抑制了其周边神经元的活动水平。以上两个结果都与神经网络模型的预测相同。
研究团队认为,这些结果显示,深度网络能够基于大脑表现出泛化能力,此外,它们并不是完全无法研究的黑匣子。该团队也表示:“然而,我们认为……在这些模型还需进一步体现它们的价值,我们还需从其他角度探究他们的‘可研究性’。”
深度网络与大脑在结构上和表现上的相似,并不能证明他们的工作机制是完全相同的,许多研究验证了这些差异。但深度网络与大脑或许已经足够相似,这使得它们能够遵循同样的基本原理进行工作。
五、模型的局限
麦德姆在研究中看出了深度学习网络的治疗潜力。患者们的病理受损往往源自耳部的改变。大脑中的听觉系统需要应对受损的输入信息。“因此,一个能完美预测大脑听力系统工作机制的神经网络,能让我们帮助失聪患者调节听力。”
即便如此,麦德姆对于深度网络的作用仍持保留态度。“我们付出了非常多的努力去了解神经网络作为预测模型的局限性。”
詹妮尔·费瑟(Jenelle Feather)是在麦德姆实验室工作的一名研究生。她设计了不同的同声异波(metamers)刺激组来比较神经网络表现与人类听觉表现之间的差别。
她负责的一项实验表现出了神经网络的局限。在这个实验中,詹妮尔·费瑟与麦德姆实验室的同事们利用两个物理性质不同但在系统中的表征相同的刺激对进行实验。举个例子,两个同声异波刺激是具有不同声波波形的刺激对,这两个刺激在人类被试的耳中听起来相同。
通过声学系统的深度网络模型,这个团队设计出了自然声音信号的同声异波刺激;这些同声异波刺激在神经网络不同层级上的激活表现与对应自然音频信号相同。如果神经网络能够精确模拟人类的听觉系统,那么这一系列深度网络模型认为相似的刺激对在人类被试的耳中也应相同。
但实验结果否定了这个预测。基于神经网络早期阶段(初等层级)激活情况设计的同声异波刺激,在人类被试听来与对应自然声音相同。然而,由神经网络深度层级设计的刺激在人类被试耳中与噪音无异。麦德姆表示:“因此,即便深度神经网络在一些特定情况下能很好地模拟人类行为,它们的设计还存在着许多问题。”
在斯坦福大学,亚明思仍在探索这些模型无法模拟哪些大脑功能。比方说,训练深度学习网络需要用到庞大的标签数据库,但在特殊情况下,大脑甚至只需要一个例子就能完成学习。如今研究者正在开发效率更高的无监督学习深度网络——通过反向传播算法进行学习的深度网络。
大部分神经科学家们认为,这种连接形式是无法在真实的神经组织中实现的。“近来,在另外一些应用了生物学上更加可靠的学习规则的网络也取得了不小的进展。”亚明思说道。
美国麻省理工学院的认知神经科学家乔西·特南鲍姆(Josh Tenenbaum)表示:尽管所有的深度网络模型都是“真正的科学进展,”但他们完成的不过是简单的分类任务。而人类大脑完成的任务要比这复杂得多。“我的视觉系统不仅能够分清平面图像中的几何信息与立体情境中的三维结构,还能分析这些场景中的因果因素——比方说,当一辆车经过时,我们知道背景中的树木突然消失是因为它们被车挡住了。”
为了理解大脑是如何做到这一点的,曾就职于麻省理工学院,如今在耶鲁大学工作的伊尔凯尔·伊尔迪里姆(Ilker Yildirim)与特南鲍姆等人一同开发出了逆向图形模型。研究者在这个模型中规定变量,从而在背景中渲染出一张脸。这些变量规定了图片的形状、纹理、光的方向以及头的姿势等。
随后,他们利用一个叫做生成模型的计算机画图软件根据这些变量创造出一张三维图景;通过数个阶段的处理,这个模型能生成从不同角度观测该三维图景的二维图像。通过生成模型产生的三维与二维图像库,研究者利用AlexNet训练出了一个能从陌生二维图像中模拟三维图景变量的模型。“这个系统学会了将根据结果推导成因,即从二维图像预测原三维图景。”特南鲍姆说道。
该团队通过恒河猴的腹侧颞叶皮层表现检测了该模型的预测水平。他们向这些恒河猴呈现了25个人摆出7种姿态的图片,共175张。然后记录它们大脑中“面部识别区”的神经活动。面部识别区是专门负责面部识别的视觉处理系统。同时,该团队还对他们的深度学习网络呈现这些图像。
在网络中,第一层级人工神经元的激活水平与二维图像相关,而最后一层级人工神经元的激活水平代表着三维参数。“在这两个层级之间,信息经过了从二维至三维的数次转换。”特南鲍姆表示。团队发现,该网络的最后三个层级与恒河猴面部识别网络的最后三个层级表现出了惊人的一致性。
这样的结果可能表示,通过结合生成模型与识别模型,大脑不仅能够识别并表征物品,还能从中推导出图景中的因果关系,这种推导能在瞬间完成。不过,特南鲍姆表示,他们的模型无法证明大脑确实是这样工作的。“但这个发现确实为研究者打开了一扇探究大脑加工机制的大门”,他表示。“这项发现应该激励我们进一步探讨更加精细的大脑加工机制。”
本文来自微信公众号:神经现实(ID:neureality),作者:Anil Ananthaswamy,译者:叶卓扬、山鸡,校对:Yihan,编辑:阿莫東森,原文:https://www.quantamagazine.org/deep-neural-networks-help-to-explain-living-brains-20201028/