
本文来自微信公众号:集智俱乐部(ID:swarma_org),作者:David Lazer等,翻译:陈孟园,审校:张洪,编辑:李沛欣,题图来自:视觉中国
在自然科学领域已经广泛应用大数据、分布式计算等方式提高研究质量的今天,社会科学领域涉及到的核心数据仍然被少数机构所拥有并创造着巨大的价值。而与此同时,数据隐私、制度规范等问题也纷至沓来。
社会计算(social computing)概念于1994年被首次提出,社会科学与计算机科学的交融既是长期的学术热点,也深刻地影响着社会发展。2009年2月6日,15名来自社会科学、计算机科学和物理学的重要学者联名在Science发表文章,计算社会科学(computational social science)被推上前台。

原文题目:Computational Social Science
论文地址:https://science.sciencemag.org/content/323/5915/721
计算社会科学的诞生
一场信息革命,一次技术飞跃,一门新兴学科诞生,2009年2月6日,是计算社会科学界值得纪念的日子。15名来自社会科学、计算机科学和物理学的重要科学家联名在Science上发表该篇文章《Computer Social Science》,宣告计算社会科学的诞生。
21世纪,我们生活在网络之中,脸书、微信、电话和邮件一秒钟沟通起了你我他,一封封往来的信件在互联网中留下印记;信用卡、公交卡记录了你我的地域轨迹和消费支出;在车头我们安装摄像机记录行车状况,而政府在公共场所各处装上监控记录犯罪证据。
我们虽生活在真实的生活当中,但却在虚拟的世界留下种种数字印记,这些印记改变了我们的生活,改变了我们对社会的理解,改变了科学研究的进程。
搜集和分析大数据的能力已经彻底改变了自然科学,比如生物学和物理学。然而,数据驱动的计算社会科学发展却极为缓慢,在经济学、社会学以及政治学的重要期刊上都很少有计算社会科学的相关文章。但不容忽视的是,在一些知名的互联网公司Google、Yahoo和政府部门比如美国安全局中,正在开展计算社会科学的研究。
计算社会科学也许会仅仅集中在私人公司和政府部门内部。又或者,某些拥有特权的学术研究者将使用这些独一无二的“秘密”数据,从而发表无法被别人评价和复制的论文。从长远来看,以上这两种情况都不利于知识的积累、验证与传播。让我们试想,如果在一个开放的学术环境下,计算社会科学将会如何增强我们对个人和集体行为的理解?
计算社会科学关心的内容
至今,关于人类互动的研究还主要依赖于某一特定时段个人填答的调查数据。而技术发展带来的海量数据[1],能够极大的改善这一现象。例如,往来的电子邮件数据中展示了不同的时间段里人们之间互动关系的结构和内容,据此我们可以研究人们之间的关系如何随时间而变化,帮助我们思考一系列人类互动行为的问题:一个团体内部之间的关系究竟是怎么样的,是已经达到了稳态很少出现变化,还是他们之间的关系一直发生着剧烈的波动[2]?优秀的团队和个人具备怎样的互动模式[3]?
同样,我们还能够考察宏观的社会网络[4],观察它如何随着时间演变。移动电话公司,大型互联网公司Google、Yahoo拥有大量的用户交流信息数据,这些数据能不能描绘出一张社会通信模式的复杂图景,而这张图景又如何影响经济生产力和公共健康?手机使得追踪人类活动变得方便快捷[5,6],同时人类活动数据可以帮助我们研究流行病如何通过个体传播等重要问题。
总之,互联网提供了一个全新的途径来理解人们之间的连接[7]。仔细思考一下,在刚刚过去的政治选举时期,如果能够追踪被火热传播的论点、谣言、政治立场或者博客圈中的一些谈论[8]以及网络上的“冲浪”行为[9],每一个选民最关心的问题将会变得显而易见。
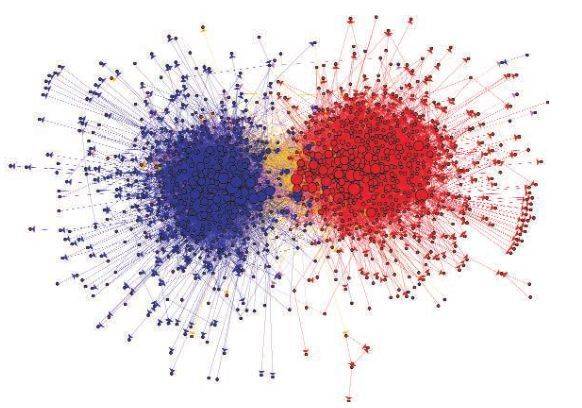
来自博客圈的数据。显示的是一个政治博客社区内的链接结构(从2004年开始),其中红色节点表示保守派的博客,蓝色节点为自由主义博客、橙色线代表从自由主义连接到保守主义,紫色线代表从保守主义连接到自由主义。每个博客的大小反映了其他博客链接到它的数量。转载自参考文献[7]
互联网所营造的虚拟世界,自然而又轻松地捕获了个体行为的完整记录,这为原本不可能实现的研究提供了丰富的数据基础[10]。例如,这些完整的个人记录帮助我们了解一个人在社交网络中的位置是如何影响他们的喜好、心情、甚至是身心健康[11]。自然语言处理技术的发展(NLP)也大大提高了我们分析大量文本数据的能力[12]。
未来,我们希望,对社会的认知不再通过手动记录面对面交流者的信息来实现,而是通过各种各样的电子设备自动生成和记录社交信息。总而言之,计算社会科学正在以前所未有的广度、深度以及规模搜集与分析数据,但与此同时,计算社会科学的兴起与发展却遭遇着重重阻碍。
计算社会科学研究障碍
在研究范式上,现有的解释人类行为的理论和范式是在无法获取和处理几千万兆的人类交互信息数据的时候发展和建立起来的。比如说,基于几十个人某一时刻的数据而建构的社会网络理论如何能解释上百万人之间的相互关系呢?关于人们如何互动的大量新兴数据可以为研究人类的集体行为提供新的视角,但我们目前社会科学的研究范式并不一定会接受。
推进计算社会科学还存在着很多制度性障碍。计算社会科学与物理和生物学的研究问题不同,在观察与干预研究对象过程中也存在着不同的挑战。在物理学和生物学实验中,夸克和细胞不像人类一样,会因为别人的观察而不自觉或者刻意掩盖自己的行为,它们乖乖地听从人类的干预而不会反抗。
就基础条件而言,从社会科学到计算社会科学所要解决的困难要比从生物学到计算生物学之间克服的困难大得多,究竟为什么会这样呢?主要是从社会科学到计算社会科学的发展需要解决分布式监控、数据使用许可权获取和加密等问题,在社会科学领域中这些资源都较为缺乏。
也许最令人头疼的问题还是数据的获取和保护,目前很多研究所需数据都涉及到个人隐私。以美国AOL公司事件为例[13],在2006年8月,AOL公司公布了2006年3月1号到5月31号这3个月用户的真实搜索记录,包括1900万搜索,1080多万不一样的搜索词,还有65万8000个用户ID(美国AOL公司是一家在线信息服务公司,可提供电子邮件、新闻组、教育和娱乐服务,并支持对因特网访问,2015年被威瑞森通信Verizon Communications收购)。
虽然用户的ID是匿名的,但如果你足够细心认真的话,还是可能从这8000多个用户中发现足够多的信息。有一位记者就从搜索的地址和姓名中快速找到了一位62岁的老太太,并且老太太证实了那些罗列出来的搜索词确实是她的。
你还可以从搜索词中看到这样一些关键词(来源:https://www.seozac.com/other-se/aol-data/):
怎样炸掉一栋楼;
怎样给别人下药;
怎样制造炮弹;
怎样攻入别人的电脑;
怎样杀死太太;
怎样杀人能够不留痕迹;
.......
AOL公司做出的这件蠢事给社会带来了一场大混乱,虽然该网页几个小时之后就被撤下,但数据却被网友们在互联网上广泛传播,这也为私人公司擅自分享私人数据敲了警钟。
设想现在,如果谷歌、百度、天猫、腾讯、京东等互联网巨头突然公布了所有人的搜索记录、聊天记录、购物记录等,更不幸的是,如果你浏览器的登录昵称是你的真实名字,同时你多次在浏览器中搜索你家附近的加油站、超市等信息,并且在天猫购物平台中多次输入你的地址,那么你可能很快就被定位。
根据你的搜索记录,你将被贴上各种各样的标签,“房奴”“彩妆迷”以及“二次元”等。更可怕的是,你的电话可能会被各种销售公司打爆,生活将变得一塌糊涂。
因此,为了保护个人的数据隐私和企业的利益,为了能让这些数据发挥作用从而促进科学研究的进步,企业和科学家之间建立起合作共赢的数据分享模式是非常有必要的。总体来说,妥当地处理隐私问题是非常必要的。最近美国国家研究委员会有关地理信息系统的报告就特别指出,即使是非常仔细地匿名化数据,还是有可能重新分析出个体的隐私数据[14]。
去年,美国国家健康局和惠康信托基金会突然停止了一些基因数据库的在线获取功能[15]。尽管这些数据只是非常简单地报告了某些特定的遗传标记的总频率,根本没有包含个人信息,一些研究者仍然认为,基于数据库中每个个体的大量数据,依照现有的统计技术,依旧能够重新定位到个体[16]。
因为一次偶然的违背个人隐私事故的发生,就可能使得社会对信息共享深恶痛绝,甚至会颁布一些扼杀计算社会科学发展的法律条文。此时我们迫切需要制定合理的规章制度,既能够降低信息泄露风险,又可以保留数据的研究价值。
作为学术界自我管理的核心制度,美国机构审查委员会(IRB)需要加强他们的科技知识以了解新技术对于个体的潜在侵权和伤害,因为他们目前的规定中有关伤害的定义已经难以评估这些新型的伤害。IRB的审查员们现有的技术也很难判断数据有没有“真正的匿名化”。除了上述问题外,IRB可能有必要建立起一个处理数据安全问题的部门。
目前,已经有很多私人企业手中握有大量的数据,但却没有一个统一的标准来保护数据安全。如果科学家们要用这些数据做研究,就需要考虑到数据的隐私问题,开发技术保护个人数据的隐私,这些技术将会反过来帮助政府和公司保护数据安全和客户的隐私[17]。
结语
与其他新兴交叉学科一样(如:可持续发展科学),若要发展新兴的计算社会科学,就需要建立新的范式培养新的学者。大学中终身教职评定委员会和各个期刊的编辑部需要积极地鼓励新兴学者在跨学科建设方面做出的努力。
最开始,计算社会科学的发展需要社会科学和计算机科学的学者组成团队一起努力,但来自不同学科的学者努力是远远不够的,计算社会科学的发展最终还是取决于学术界愿不愿意培养计算社会科学家、具有计算相关知识的社会科学家或者是具有社会科学知识的计算机科学家团队。
好在认知科学的出现为计算社会科学的发展提供了一个很好的范例。认知科学的研究涉及从神经生物学到哲学到计算机科学等各个领域。它吸引了大量资源投入来创建一个共同领域,并在上一代为公共事业创造了巨大的进步。我们认为计算社会科学具有类似的潜力,值得进行类似的投入。
参考文献:
[1] D. Roy et al., “The Human Speech Project,” Proceedings of the 28th Annual Conference of Cognitive Science Society, Vancouver, BC, Canada, 26 to 29 July 2009.
[2] J. P. Eckmann et al. Proc. Natl. Acad. Sci. U.S.A. 101, 14333 (2004).
[3] S. Aral, M. Van Alstyne, “Network Structure & Information Advantage,” Proceedings of the Academy of Management Conference, Philadelphia, PA, 3 to 8 August 2007.
[4] J.-P. Onnela et al., Proc. Natl. Acad. Sci. U.S.A. 104,7332 (2007).
[5] T. Jebara, Y. Song, K. Thadani, “Spectral Clustering and Embedding with Hidden Markov Models,” Poceedings of the European Conference on Machine Learning, Philadelphia, PA, 3 to 6 December 2007.
[6] M. C. González et al., Nature 453, 779 (2008).
[7] D. Watts, Nature 445, 489 (2007).
[8] L. Adamic, N. Glance, in Proceedings of the 3rd International Workshop on Link Discovery (LINKDD 2005), pp.36–43;
http://doi.acm.org/10.1145/1134271.1134277.
[9] J. Teevan, ACM Trans. Inform. Syst. 26, 1 (2008).
[10] W. S. Bainbridge, Science 317, 472 (2007).
[11] K. Lewis et al., Social Networks 30, 330 (2008).
[12] C. Cardie, J. Wilkerson, J. Inf. Technol. Polit. 5, 1 (2008).
[13] M. Barbarao, T. Zeller Jr., “A face is exposed for AOL searcher No. 4417749,” New York Times, 9 August 2006, p. A1.
[14] National Research Council, Putting People on the Map: Protecting Confidentiality with Linked Social-Spatial Data, M. P. Gutmann, P. Stern, Eds. (National Academy Press, Washington, DC, 2007).
[15] J. Felch. “DNA databases blocked from the public,” Los Angeles Times, 29 August 2008, p. A31.
[16] N. Homer, S. Szelinger, M. Redman, D. Duggan, W. Tembe, PLoS Genet. 4, e1000167 (2008).
[17] M.V.A. has applied for a patent on an algorithm for protecting privacy of communication content.
本文来自微信公众号:集智俱乐部(ID:swarma_org),作者:David Lazer等,论文下载地址:http://www.davidlazer.com/sites/default/files/publications/12_DL_Science_Feb_09_%26_Supporting.pdf