
2023年的8月,当朱同学乘坐飞机降落在异国他乡,看着四周陌生的文字,她一时弄不清该去哪里取行李,也不敢向形形色色的外国面孔寻求帮助。在过了很长一段时间以后,她终于下定决心开始行动。
于是,她打开小红书,敲下了“杜勒斯机场”和“杜勒斯机场 行李”两段关键词。

(图片由朱同学提供)
然而,在世界的另一头,当一位网友想要借助抖音找到自己关注很久的一位博主时,她点开搜索框,输入了不下20次脑海中能够想到的关键词。可在经历了一系列形容词、名词与动词的排列组合后,她还是无功而返。
直到某一天,她在浩如烟海的信息流中,再次和这个博主相遇。

(图源抖音一位用户评论)
九十年代以来,谷歌、雅虎、必应接连出现,搜索引擎借互联网之势一路风生水起。但在二十年后的今日,社交媒体正在强势分羹传统搜索引擎的市场。我们将生活中大大小小的疑问,一股脑地抛掷给纷杂的社交媒体。然而,我们与信息的距离是否变得更近?是否仍然如雾里看花、水中望月?
搜索迁移:因为实时、个性、差异化
从“被动看”到“主动搜”,不知从何时起,我们逐渐倾向于在社交媒体上搜索千奇百怪、五花八门的问题。在朗朗上口的“百度一下,你就知道”之外,“遇事不决小红书”开始流行。
为什么社交媒体能拿走传统搜索引擎的饭碗?
人们大多习惯了用传统搜索引擎求索更为久远、已然定型的静态信息:秦始皇何时建立秦朝、泰勒·斯威夫特第一张专辑是什么……然而,面对纷繁复杂、变化多端的现实世界,大到求职信息差如何收集,小到学信网如何验证在线学籍,社交媒体因其实时更新的个体经验,能反馈更加贴合的搜索结果。[1]
此外,出于对自身平台数据的保护,社交媒体一般会限制搜索引擎爬虫,这就导致互联网上的信息搜索结果成为一座座“孤岛”,也使各社交平台之间出现信息壁垒。[2]新增的互联网内容多数被“锁死”在各自的APP里。差异化内容便成为了社交媒体与传统搜索引擎间无声竞争的重要资本。
点开传统搜索引擎必应,小林同学最近一次搜索记录是:温哥华冬奥会男子短道速滑1000米冠军是谁?而当她翻出小红书,搜索记录第一条是:洛阳旅游攻略。“我会在必应上搜概念性更强、有确切答案的东西;在社交媒体上肯定会搜互动性更强、需要得到别人经验的东西。”在日常生活中,小林对两类搜索渠道的使用,已经在无意识之间产生了分野。
社交媒体上,到底能搜到谁发的内容?搜到怎样的观点?
我们选取了抖音、B站、小红书、微博四类社交媒体,以近期4个平台共同的热点话题“南昌大风”与“台湾地震”为例,在4个平台进行搜索。通过分析发布者的身份发现,四类社交媒体的内容发布者大多都是普通自媒体与个人。社交媒体里,每个人都有可能被看到,社会事件下个人无意的俏皮话可能爆火,对事实真相阐述的努力也可能湮没在众人言语中。
同时各平台在“谁被看见”这一方面亦有不同侧重。微博内容发布者的类型最为均衡,既有官方通报,亦包含了有影响力的自媒体的分析。与此相反,普通个人的想法则占据了近95%的小红书推荐内容。而在B站中有影响力的自媒体占比22.5%,位列第二。
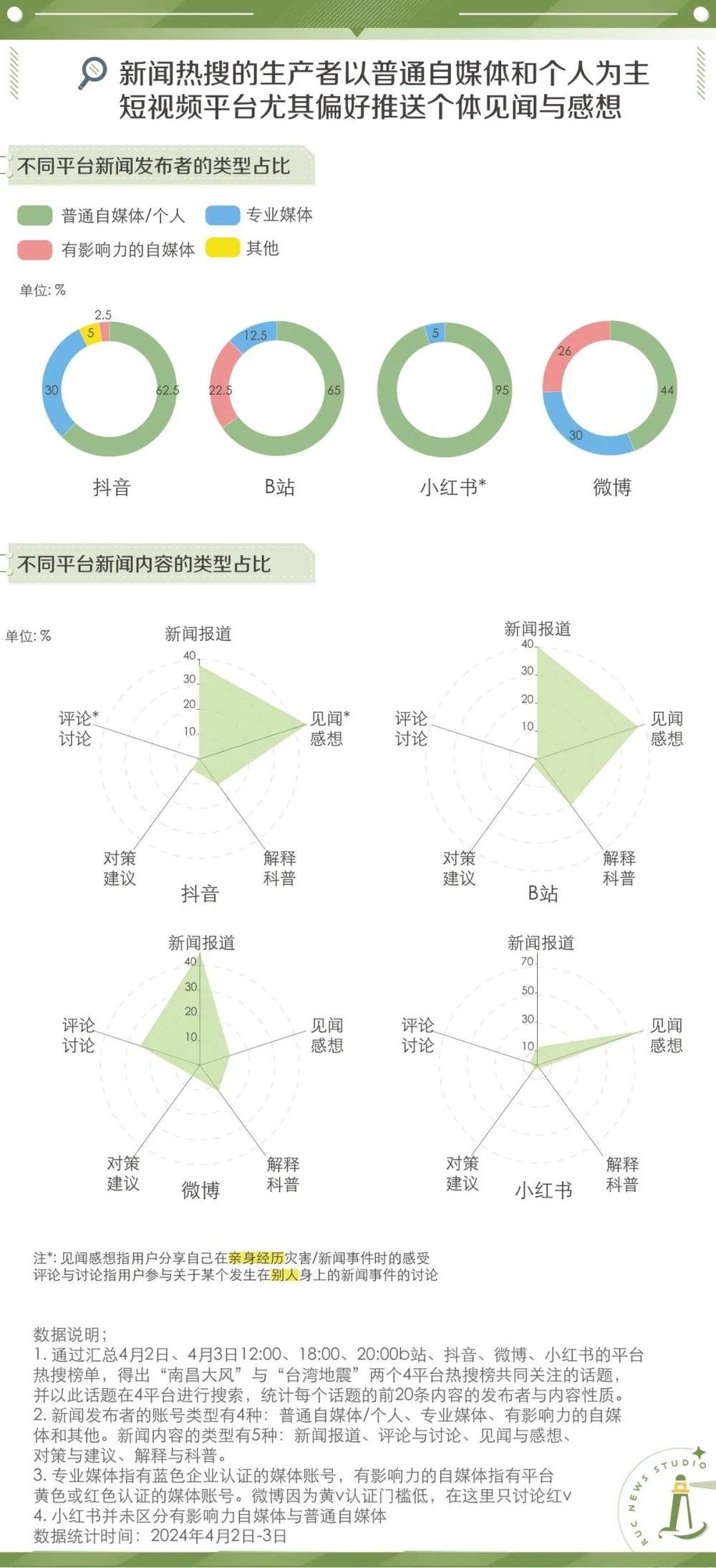
与“谁被看见”同样值得关注的便是“什么内容被看见”。为了解答这一疑问,我们进一步地分析抓取不同平台的信息,最后将其总结为:新闻报道、见闻与感想、解释与科普、对策与建议、评论与讨论五种类型。
数据显示,新闻内容在抖音、b站、微博三家平台的占比都达到了近40%。而在四类平台中,微博“见闻与感想”类内容占比最低,仅达到10%,相比之下,“评论与讨论”有着明显优势,占比25%。而小红书作为严重“偏科选手”,在其他类型的内容缺少时,见闻感想类内容则超过了70%。
实际上,内容类型分化极为明显的小红书在某种程度上将自身优势放大到了极致。无数普通人的生活经验宛若源头活水,你帮我“避坑”,我替你“攻略”,共同在互联网上完成一场低成本的信息交换。
在谈到最常用的搜索引擎时,张木子首先想到的就是小红书,“我现在关注的问题更多偏生活性,而这些问题在小红书上能够得到特别好的解答。”小林同学也认为,自己在小红书上更愿意去主动搜索,而在微博和抖音上更多去看大数据推荐的内容。
随波捕捉:搜索成本有多少?
社交媒体在搜索上虽有独到之处,但也难免有缺陷。由于页面显示的有限性,大量的内容并不会因为可被检索就一定可被见。在复杂的算法推荐机制和实时更新的“瀑布流”中,有时难以准确捕捉到某一块随波而去的“电子碎片”。
为了探究各类社交媒体搜索成本的差异,我们进行了一场小型的“你画我猜”实验。
在抖音、小红书、微博、B站这四类社交媒体上,37名实验对象向我们描述其看过119条印象最为深刻的博主、新闻和视频信息,我们通过搜索其描述的关键词来找寻原贴,并记录下从开始搜索到找到参与者心中所想的视频的过程中,需要按下多少次“搜索”。
我们试图通过这样的方式,还原用户搜索时模糊而辗转多次的场景,去探究不同平台是否会让用户有不同长度的搜索路径。
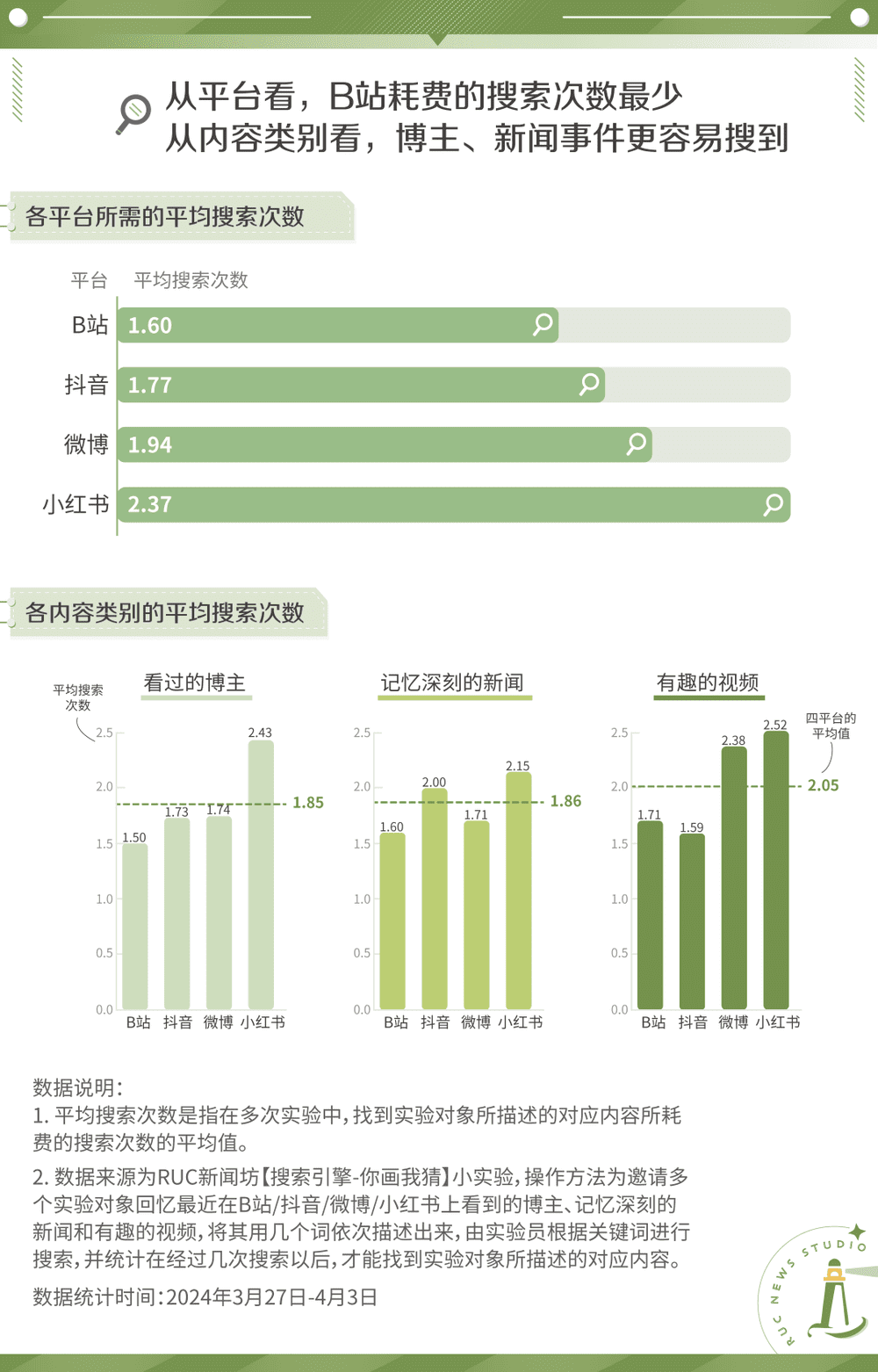
从实验结果上看,要想准确捕捉到原贴,小红书的搜索成本最高,无论是博主、新闻和视频,其平均搜索次数都处于首位。这或许和我们之前得出的结论相关:小红书拥有着过度庞杂而动态的UGC(用户生成内容)。越来越多的个体将自身对真实生活的触感展现在众人面前,但在流量的诱惑与算法的筛选下,互联网上激起了一片片相似的浪花。
当无数普通人的经验汇聚在同一个平台,如何准确找到某个人发布的特定内容,似乎成为一种“玄学”。
随波逐流,相遇且看缘分。形成这缘分的要素十分复杂,根据实验过程,我们捕捉到至少三个影响视频“捕捞”次数与体验的因素:视频热度、内容同质化程度、关键词与标题的重合度。一位粉丝量过百万的博主,在社交媒体中的可见性远大于普通网友;高度重合的话题与攻略,将用户想要寻找的帖子藏匿在茫茫贴海深处;包含很多关键字的标题,在社交媒体中进行关键词查找时,会更容易被配对成功。
在搜索次数以外,很多次搜索也折戟于无数次滑动切换屏幕中。有研究表明,在必应上,97%用户只关注搜索结果的第一页。[3]因此,在计算搜索成本时,我们将“在页面浏览多久才能定位需要的信息”也纳入其中。
移动端一屏可容纳的信息量和应用软件的界面设计,影响了用户定位检索结果的难易程度。与搜索引擎不同,社交媒体更多地采取沉浸式下拉而非翻页式的刷新方式。为了了解不同社交媒体平台间的差异,我们在四个平台上搜索关键词“春天”,并计算“综合”栏中可显示的最多内容的平均值。最后发现,B站一屏可显示的搜索结果最多,达到4.38条,而以竖屏短视频为主的抖音一屏最多可显示1.25条,不到B站的三分之一。
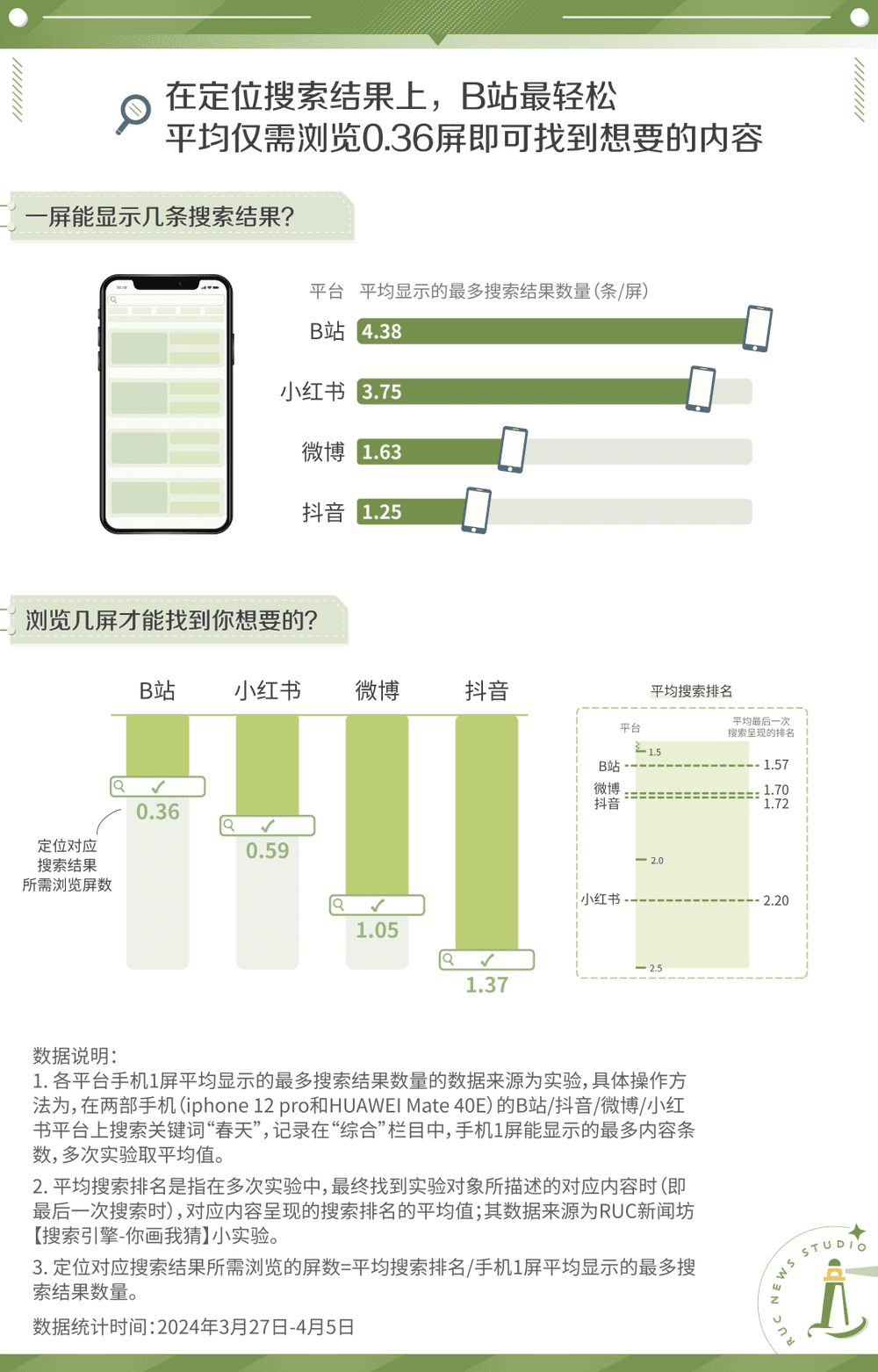
当一屏的信息量足够大时,用户为了找到信息而需要浏览屏幕的次数也随之减少。以最后一次搜索为例,B站因其一屏可显示更多的信息,所以无需下拉,甚至只需看前半屏的内容,即可定位信息,而抖音则要平均浏览1.37屏。在定位搜索结果上,横屏比竖屏优势更大。
因此,放大的图片、满屏的视频、夺人眼球的长文,在无形之中增加了我们浏览屏幕的次数,放大了我们翻找到所求信息的路径成本,成为搜索成功路上的一道道拦路虎。
回溯信息:海底捞针还是囊中取物?
我们搜索信息,也会回溯信息。与信息的相遇并非仅图当下一乐,那些未能及时觉察的意义,可能会在未来的某一刻突然明晰。
对张木子而言,在社交媒体上回溯信息是每日的常规操作,“很多视频需要有‘反刍’,在现实生活中产生互动以后,我才觉得它们特别有趣”。另一位受访者小舒则聊到:“有时候和朋友聊天,我会突然想到某个之前看过的搞笑视频,想要拿出来分享,但是后面怎么找都没有找到。”
怎样可以回溯过往所见?我们翻阅了不同平台的历史浏览记录呈现模式,旨在了解当用户想要重新打捞起那些曾经“擦肩而过”的内容时,平台如何为他们搭建“记忆博物馆”。

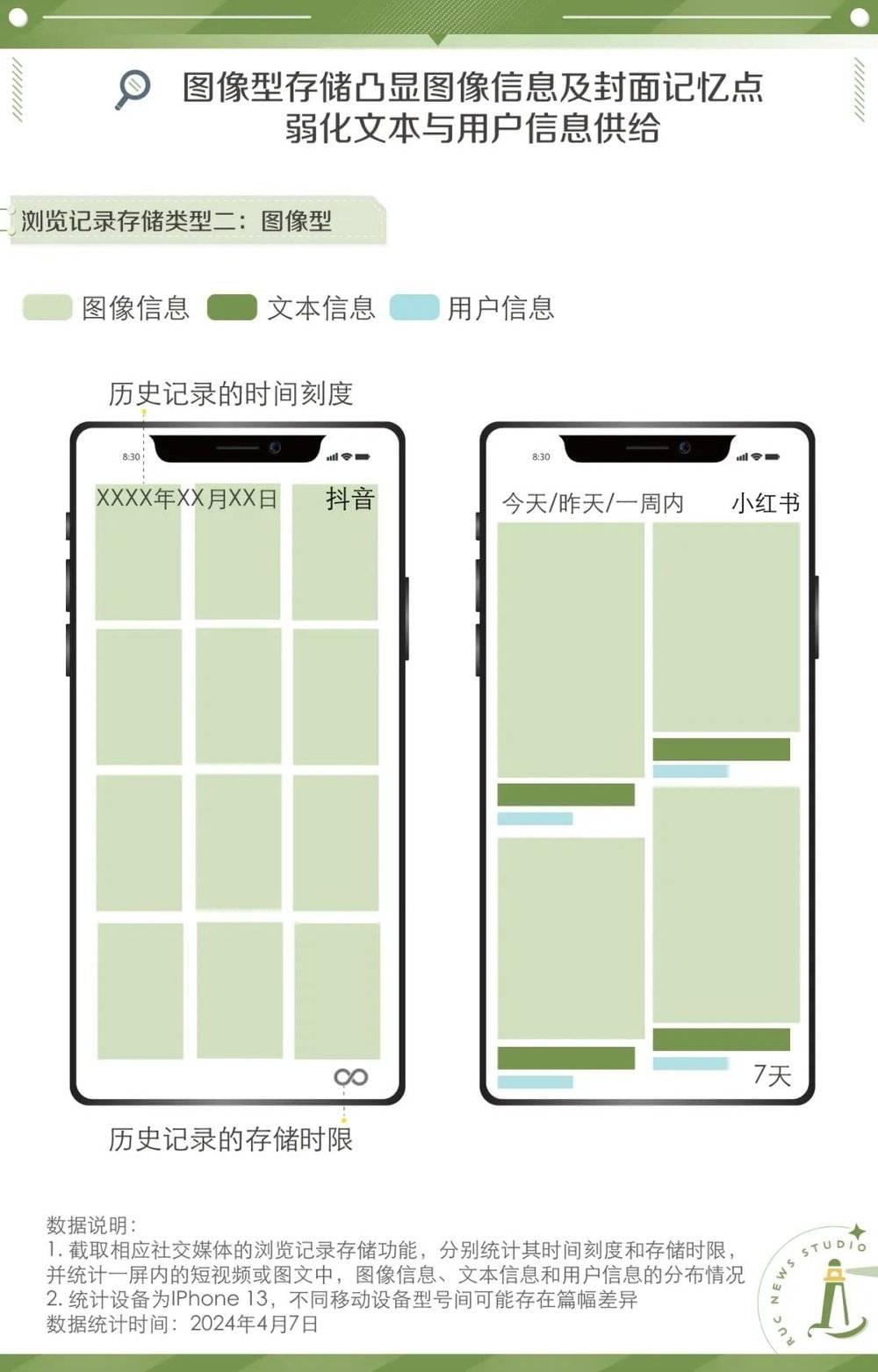
在基于各个平台的界面设计可视化的基础上,根据图文占比的差异,我们将四类社交媒体的浏览记录存储类型,划分为综合型与图像型。B站和微博属于综合型,图像信息、文本信息、用户信息有着较为均匀且醒目的标识;抖音和小红书则属于图像型,浏览记录以图片为主。
如果存在大量的同质化封面图,抑或是用户对封面图记忆不深刻,那么用户和文本信息则可作为回溯信息的重要抓手。
历史记录的时间刻度和存储时限也会影响着回溯信息的效率。张木子对此感触颇深,因为抖音浏览记录可以精确到某一天,而B站观看历史只划分为“今天/昨天/更早”,这导致他在B站上找视频的难度比抖音大得多。想要从浏览记录里面找到以往的冲浪踪迹,首先要从混乱的时间线里挣脱出来。
当人们从传统搜索引擎迁徙到社交媒体,他们被个体发布的信息吸引,将无数普通人的经验作为“他山之石”。然而,在实时的、庞杂的个人信息中搜索需要成本。一个习惯性的下拉刷新,你可能就和“一见钟情”的信息失之交臂。即使换上几轮关键词,划过比“燕国地图”还长的屏幕,可能也是无功而返,需要重新“搜索一下”。当他们在某个下午想要再次回味以往的信息,却又在有限浏览记录中望而却步。
更好的社交媒体搜索功能,可能需要“既要又要”:既提供鲜活、丰富的用户视角信息,又能给予清晰、有序、密集的搜索结果陈列。或许2030年,社交媒体,又长成了传统搜索引擎的样子。
(文中受访者皆为化名)
参考资料
[1] 半佛仙人. 小红书正在拿走搜索引擎的饭碗. 凤凰网. https://i.ifeng.com/c/8LxS9fMwCh1
[2]柴知道.搜索引擎怎么搜不到信息了?因为互联网正在孤岛化. 网易公开课.https://open.163.com/newview/movie/free?pid=UGB2HIUCG&mid=HGB2HIUD2
[3]Golebiewski, M., & Boyd, D. (2019). Data Voids: Where Missing Data Can Easily Be Exploited (2018).
本文来自微信公众号:RUC新闻坊 (ID:rendaxinwenxi),数据收集与分析:汪瀚、江雪、邱童、禹琳、杜天舒,可视化:邱童、汪瀚,文案:禹琳、江雪、杜天舒,美编:杜天舒,统筹:杜天舒、汪瀚