
2024年,优化训练和部署大模型仍然非常重要,大模型的生态加速形成,应用开始在一些领域大规模展开,主要表现在如下十个领域:
1. 智能体作为任务助理进入更多应用场景和业务流程
智能体能有一定的主动性,能帮助完成任务,而不仅仅是问答。在感知环境后,通过其大脑(大型语言模型),调动其他的程序、应用、知识,甚至自己编程,规划和执行更复杂的任务。有了智能体,许多人可以用经验和专业知识,通过自然语言而不限于编程代码去写软件。
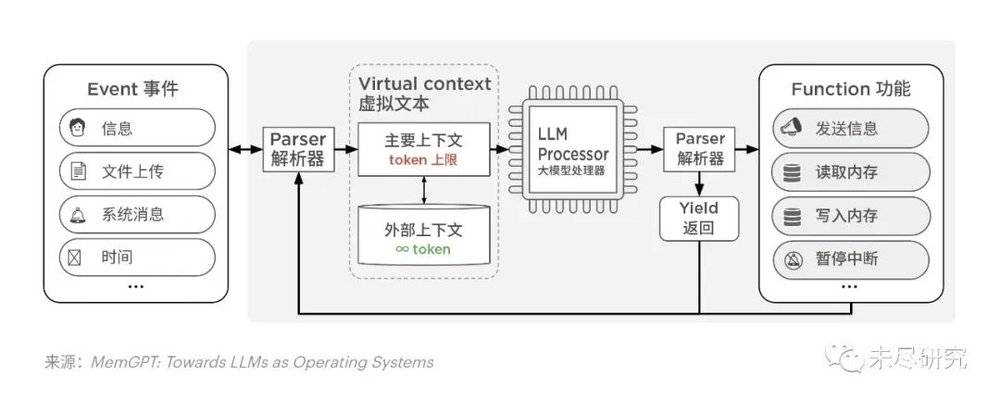
2. 操作系统集成下一代大模型,成为下一代操作系统
大型语言模型日益操作系统化,AI芯片为它设计,PC和手机的操作系统为它升级,AI应用成为它的下游,上下文管理类似于操作系统的内存。微软将推出Windows 12操作系统,在PC上与下一代大模型、Copilot深度集成。在移动设备上部署的模型,也与iOS、Android操作系统紧密结合,实现AI功能和建立AI应用商店。
3. 生成式AI制作的影视剧大量出现,冲击影视行业
图像和视频是生成式AI迭代最快的领域之一,GPT-4V等多模态大模型的推出,基于扩散模型的Dall-E 3、Midjourney和Stable Diffusion的功能不断增强,LCM-LoRA等技术达到了实时生成图像和视频的效果,对影视、音乐、游戏等内容娱乐行业的影响是颠覆性的。这方面的应用也是巨头目前还染指不多的领域。2024年将大量出现由生成式AI产生的影视剧,创作者、用户以及角色之间将会出现崭新的交互方式。
4. 人形机器人开始量产,自学习与环境互动能力进一步强化
在已有的机器人技术之上,多模态和具身智能的大模型,不断展示出惊艳的效果。大型语言模型的推理和规划能力,与视觉模型结合,可以通过获取周围环境数据,学习人类用手脚完成任务。2024年人形机器人开始量产,开始在工作场景中进化迭代人类的灵活性。
5. 终端设备加载AI模型,推动换代升级
小型化的大模型可以加载到笔记本电脑和手机等终端设备上,用户不仅可以更快捷地生成内容,而且可以利用自己本地的数据和知识进行检索生成,建立起定制化的智能体,更快捷地进行推理,也保护了数据安全和个人隐私。AI设备的主流硬件规格将包括内置7-10B LLM模型、40-50 TOPS AI算力、10-20 token/s以上推理速度、8-16GB以上DRAM等。
6. 下一代闭源大模型推出,出现胜任人类水平的AGI“火花”,但规模边际效应递减
OpenAI与微软将推出GPT-5,谷歌将推出Gemini Ultra,亚马逊也在训练数万亿参数的大模型。下一代大模型将是多模态的、使用更多合成数据的、混合专家系统的,会消除一些幻觉、增加上下文长度、信息更加准确和及时、基础数学水平有所提升等等。
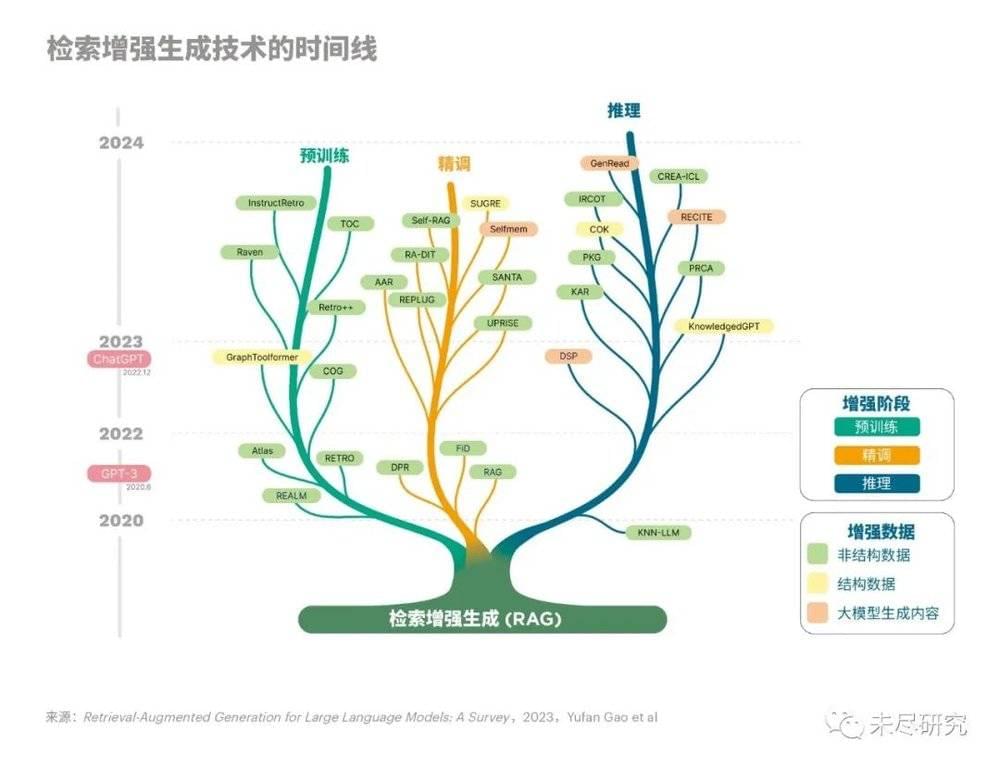
更多更好的数据、更强的算力、更顺的搜索,依然是产生智能的根本因素。加上RAG(检索增强生成)补充非参数化的知识,闭源大模型会应用于更多的场景。
7. 数据来源的深度和广度进一步开拓、进一步规范,更多合成数据与自然数据结合用于大模型训练
数据决定了泛化的边界。自然语言数据,以及直接从现实世界事件或对象中收集得到的数据,已经无法满足下一代大模型的训练的胃口。在专业领域和垂直场景,非公开的数据将会发挥更大的价值,并且与大模型服务商建立新型商业合作关系。
大模型训练、自动驾驶、机器人、图像生成、模拟仿真等,都在大量使用合成数据的同时生成新的数据。越来越多的数据标注也由AI来完成。但是,只使用合成数据可能会造成数据多样性不足和自循环训练的问题。2024年将会看到AI企业寻求合法获取更多非公开数据,以及使用更多的混合数据。
8. 苹果真正入局,力争复现AI“iPhone时刻”
2023年被称为大模型之年,苹果表面上在作壁上观,但实际上在芯片及软硬件方面的研发一直在加大力度,只做不说。2024年苹果将把Vison Pro推向市场;PC和手机加载大模型,苹果是其中最重要的玩家;为了建立AI应用生态,操作系统封闭的苹果拥抱开源模型。苹果被广泛期待能给消费市场带来更好的AI产品体验。
9. 一些开源模型及AI应用,因为无法建立起商业模式将面临生存危机
绝大多数初创企业的开源模型,目前还无法在提供推理服务、授权、训练和部署模型方面建立起用户基础;消费类模型+应用的初创企业,在激烈的竞争中多数将遭淘汰;纯应用类的初创企业,许多将遭到巨头碾压或者很快在更新的开源技术迅速推广中出局。快速获取用户并且在反馈中建立起数据飞轮的企业将赢得生存。而能结合起应用场景、行业深度和垂直数据来源的企业,将能保护好自己。
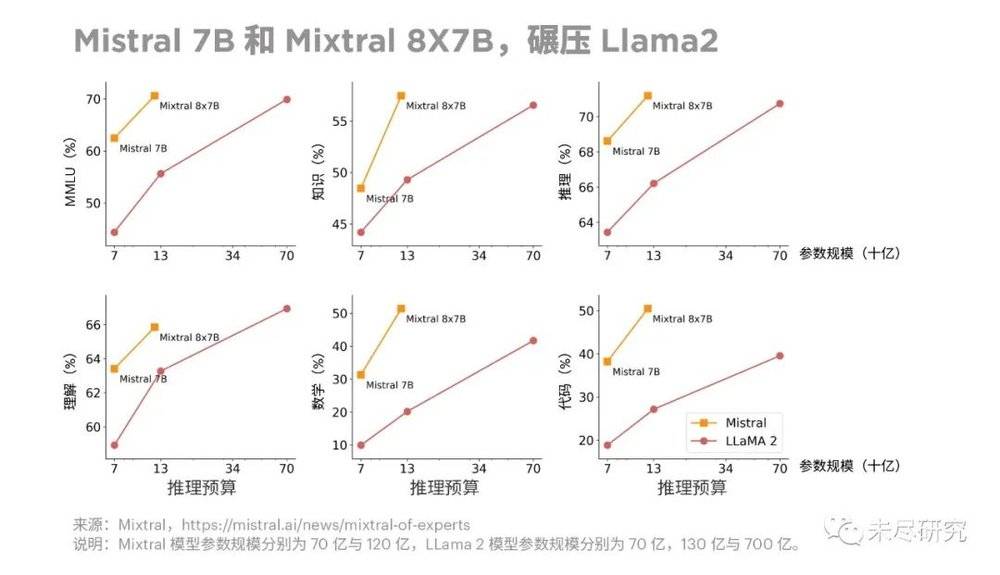
10. 小模型结合软硬件应用,新物种涌现
2023年是大模型之年,2024年也将是“小”模型之年。更多几十亿到上百亿参数的小模型,通过模型架构、算法、训练和精调的创新,以及结合外部检索,性能可以叫板百亿参数大模型,甚至追平GPT-3.5(1750亿参数)。
许多开源模型来自中国、欧洲、韩国、甚至中东等地,以更快的速度推广到各行各业。小模型尤其适合下载到设备上,在许多功能上可以替代从云上提供的大模型服务。小模型+终端设备是2024年的重要看点。
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:未尽研究