
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:未尽研究,原文标题:《都在卷长文本,原来谷歌魔改了Transformer,推出了“无限注意力” | 笔记》,题图来自:视觉中国
最近都在卷长文本。
谷歌的大模型Gemini 1.5首先玩了一个百万token,中国的月之暗面一个月后推出Kimi智能助手,支持200万字超长无损上下文,在中国的大模型应用中异军突起。
行业内的大厂们坐不住了,阿里巴巴的通义千问项目开放了1000万字的长文本处理能力;360公司的智脑开始内测500万字的长文本处理功能,并计划将其整合至360 AI浏览器中。百度也宣布推出200万至500万字的长文本处理能力。但它们都没有说明在技术上是如何实现的。
谷歌发了一篇论文,介绍它是如何玩转长文本的。
它们对Transformer的常规注意力机制进行“魔改”,发明了一种新的注意力技术,称为无限注意力 (Infini-attention)。

无限注意力(Infini-attention)具有额外压缩内存,并使用线性注意力处理无限长的上下文。{KV}s−1 和 {KV}s 分别是当前和先前输入段的注意力键和值,而Qs是注意力查询,PE表示位置嵌入。
记忆是智能的基础,在一段特定的上下文中,记忆让计算更有效率。谷歌的研究人员,引入了压缩记忆,保存了完整的上下文记录。
常规的注意力机制,是把注意力计算中所有的键值(KV)和查询状态丢弃;而经过改进的注意力机制,将注意力的旧KV状态存储在压缩内存中,用于长期记忆中的巩固和检索。
在处理后续序列时,注意力查询可以从压缩内存中检索值,在最终的上下文输出中,Infini-attention会聚合从长期记忆检索的值和局部注意力上下文。
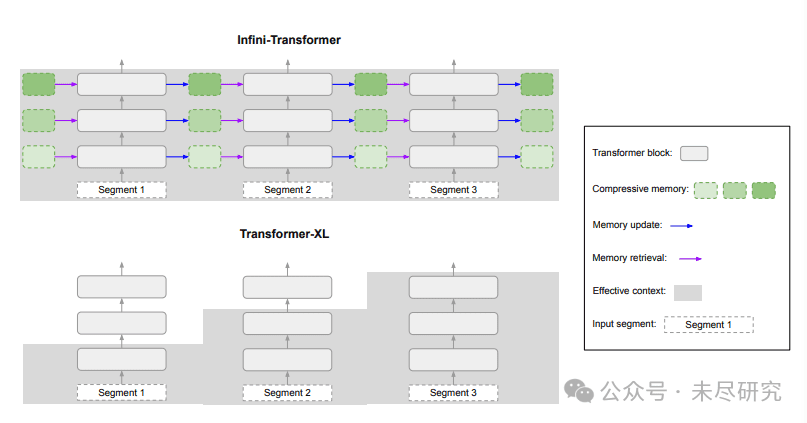
Infini-Transformer(上)拥有完整上下文历史记录;而 Transformer-XL(下)则丢弃旧上下文,仅缓存最后一个段的 KV 状态。
Infini-attention让基于Transformer的模型,能够在有限的内存占用和计算量下高效处理无限长的输入序列,它把压缩内存集成到标准的注意力机制中,并在单个Transformer块内构建了掩码局部注意力和长期线性注意力机制。
修改之后,对现有的模型能进行持续的预训练和微调,上下文可以自然扩展到无限长。
结果证明,在内存不变的前提下,具有Infini-attention的10亿参数大模型自然扩展到100万上下文。持续预训练和任务微调后,具有Infini-attention的80亿参数模型,在50万长度书籍摘要任务上达到了SOTA。
长上下文模型已成为前沿人工智能实验室研究的重要领域,也是其竞争焦点之一。Anthropic的 Claude 3支持最多20万token,而OpenAI的GPT-4的上下文窗口为12.8万个token,直到Gemini 1.5达到百万token。
模型具备了无限上下文,就能够创建定制应用程序。目前,为特定应用程序定制模型需要采用微调或检索增强生成(RAG)等技术。虽然这些技术非常有用,但需要复杂的工程。
理论上,一个具有无限上下文的大模型可以将所有文档插入到提示中,让模型为每个查询挑选最相关的内容部分。它还可以通过提供一长串示例来定制模型,以提高其在特定任务上的表现,而无需进行微调。
然而,这并不意味着无限上下文将取代其他技术,如RAG。它将降低进入应用程序的门槛,使开发者和组织能够快速创建工作原型,而无需花费巨大的工程成本。最终,无限上下文让企业和机构优化其模型管道,以降低成本并提高速度和准确性。
而支持百万上下文的模型,很快将可以装到笔记本电脑里了。
论文链接:https://arxiv.org/abs/2404.07143
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:未尽研究