
近期OpenAI动作频频,而且个个惊雷贯耳,接连爆出要自研芯片、要与苹果前首席设计师一同打造AI硬件设备。
同时ChatGPT的更新接踵而至:接入Windows、重新联网,实现多模态交互,甚至做到了既能看图、又能听声音、还能说话……
也就是说,OpenAI的进化速度,越来越快了。
模型越牛,估值越高。在过去一年时间,OpenAI的估值也从260亿美元翻到了最高900亿美元,在还没上市的超级独角兽里仅次于字节跳动和SpaceX,据称OpenAI今年收入预计将达到13亿美元,市销率接近70倍!公司正在和投资者讨论用这个估值出售股份。
然而,这个全球关注的超级明星,现在却有不小的烦恼。
说白了,就是虽然作为一个超级估值独角兽,但本身也是一个超级烧钱吞金兽,13亿美元的营收相对庞大的开支简直就是杯水车薪,它如今不仅加紧要考虑未来商业化变现的路径问题,还要应对来自后来者越来越步步逼近的围堵竞争。
在波谲云诡的商业世界里,产品化节奏和资金投入一出现问题,这场以底层模型为支撑的平台游戏都将举步维艰。
随着Meta、Google等玩家强势觉醒,Anthropic+Amazon的组合加入搅局,被强敌林立环绕的OpenAI下一步该怎么走?
一、代理人之战
OpenAI在模型层并不寂寞,即使站在塔尖,一统天下还言之尚早。
尤其在和微软的联盟让科技大厂们意识到成熟的大模型技术将给云计算带来新的业务需求,一番新的混战随着谷歌、亚马逊的加速布局撕开了口子。
近期,Anthropic接受了亚马逊40亿美元的投资,两家公司将在基础模型商用方面进行更深入的合作。具体而言,Anthropic将使用AWS的云服务,而AWS将把Anthropic作为底层模型之一,接入刚刚推出的托管服务,用于构建生成式AI应用。
作为开发者,可以从多个基础模型中选择,用自己的数据来训练,然后将它们部署到自己的应用程序里,就不再需要搭建服务器这么繁琐。除了亚马逊自己的大模型Titan,Bedrock服务里已经加入了多个基础模型。
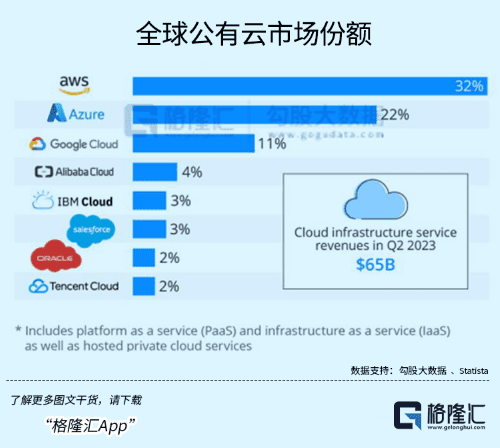
亚马逊不会找OpenAI,原因和谷歌是一样的,微软Azure-OpenAI的绑定让三家在公有云市场上又多了一番变数。明着看是对下游的押注,其实都是在给自己业务拉活儿。
亚马逊、微软和谷歌三家对公有云市场形成了寡头垄断的局面。根据 Statista 的数据,今年二季度,AWS 、Azure 、Google Cloud份额分别为32%、22%、11%,三家合计稳定在65%的份额。
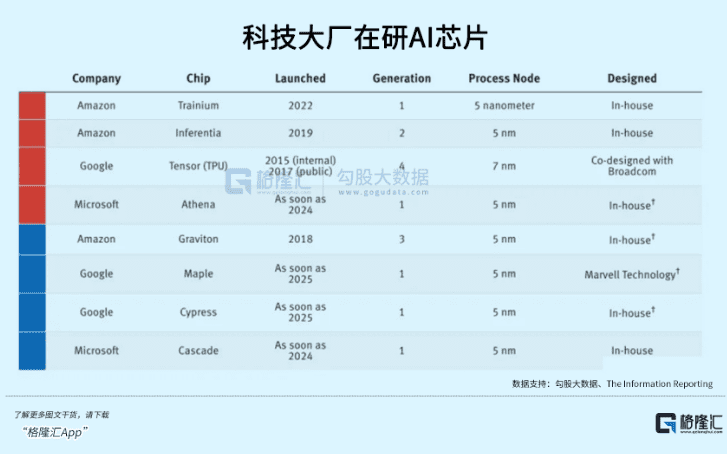
找大模型行家合作还不够,为了更好地给模型开发者提供服务,同时少受英伟达牵制,科技大厂还必须自己做芯片。
与OpenAI使用英伟达芯片训练不同,Anthropic将采用亚马逊自研的Trainium和Inferentia芯片来训练。
大模型竞赛从底层要求看,首先是算力竞赛。
大厂自研芯片的努力逐渐在实现,既为了降低成本,也想增厚自己出租服务器的利润,多收获像ChatGPT这样的开发项目。
亚马逊很早就开始把自研芯片往服务器堆;谷歌有TPU,并且已经给另一家图像模型的创业明星——Midjourney使用;据外媒报道,微软也可能于下个月发布自研的AI芯片。
其次,巨头们对大模型的想法,其实都在财报上说得明明白白。
他们的半年报里已经反映了客户对于生成式AI需求激增的趋势,ChatGPT掀起的大模型热已经消化得差不多了,下半年科技巨头开始围绕自家应用层的生产力工具,完善增值服务。
比如微软通过与OpenAI合作,率先将AI能力赋能到自己的应用全家桶。
Copilot是微软将AI融入产品矩阵的平台,被定义为“日常AI伴侣”,将作为一个应用程序在微软操作系统中使用,微软从上个月起已经将其加入到Win 11的更新中。
面向B端的365 Copilot企业版也将于11月1日正式上线,正如我们上半年见到的,各类办公软件届时将接入AI助手为我们进行一些自动化操作来提高工作效率。
收费上几乎完全对标了谷歌,这笔增值订阅费用是除企业用户已经支付的生产力套件订阅费用外的额外费用。在今年8月谷歌Workspace推出的Duet AI同样也向企业客户收取30美元/月的费用。
Workspace收入属于Alphabet的Google Cloud类别,与 Google 的云基础设施一起今年二季度产生了80亿美元的营收。在同一时期,微软的Office产品和云服务为其带来了135亿美元的收入。
作为Anthropic较早的投资者,谷歌云搭建的AI平台让用户能够部署和扩展机器学习模型。今年4~7月短短三个月的时间,谷歌云的生成式AI项目数量增长了150多倍。
值得注意的是,和亚马逊一样,谷歌也选择了多模型路线来扩充B端客户的不同需求,包括引入Meta的Llama 2和Anthropic的Claude 2来扩充。同样的,Llama 2也将通过微软云服务进行分发。
兜里不缺钱的大厂拥抱多模型并不稀奇,因为暂时很难笃定哪一类模型将会有更好的应用前景,区别是他们并非站在模型创业者的立场思考,而是以战略合作者的身份想去扩大自己的云服务生态,整合中间模型层给自己的产品赋能。
随着训练成本和调试模型的门槛进一步降低,模型—工具—应用各个层面应该会不约而同地涌进去一大批创业者,其中还包括大厂们现有的客户,与其研发大模型去开发新的应用,还不如实实在在地收割这批新的需求来得经济实惠。
另一方面,这有点像几年前国内两家互联网大厂在各个领域掀起的代理人大战,利用新技术在搜索引擎以及生产力工具不同领域向彼此发起冲击。
正如微软总裁纳德拉所说:“我们想让谷歌跳舞。”有了OpenAI的微软,市值从2022年的1.79万亿涨至如今的2.5万亿,股价一度创下历史新高。
二、OpenAI的选择
ChatGPT刚出来的时候,大家都惊觉这是科技界新的iPhone时刻,将目光聚焦在背后的OpenAI。
一个非盈利性,副线任务是与谷歌抗衡的人工智能研究机构,开发出了一款兼具实用性的AI聊天机器人,标志着一只脚迈出象牙塔,正式踏入了商业世界。
诸如AI工具解放生产力,将人类从重复性劳动解放,再到赋能千行万业、第四次工业革命等等宏大的叙事,配合ChatGPT网页井喷的流量,OpenAI的估值先坐上火箭蹿升。
这时的Open AI已经形成流量入口,加上api模型工厂组成的商业模式,而谷歌还在惊愕中酝酿着反击。
也因为Killer Apps还不多,在ChatGPT向世人崭露头角的时候,大家都在猜想OpenAI未来是否将统治整个模型层,参考的是操作系统、搜索引擎这种几乎垄断的市场。
但其实连Open AI自己都不这么想。
在他们的CTO米拉·穆拉蒂看来,平台游戏能够玩下去的要求,就是让尽可能多的人使用他们的模型,无论是to B还是to C,但人们并不总是需要使用最强大的型号来满足自己的需求。
作为劲敌的Anthropic由原来OpenAI的研究主管Dario Amodei等人出来自立门庭,他们的底层分歧只是对AI商用化和安全性存在不同见解,但同时有一点是同一批来自象牙塔里的人共同笃信的,那就是规模法则(Scaling Law),在未来很长一段时间还会继续发挥着魔力。
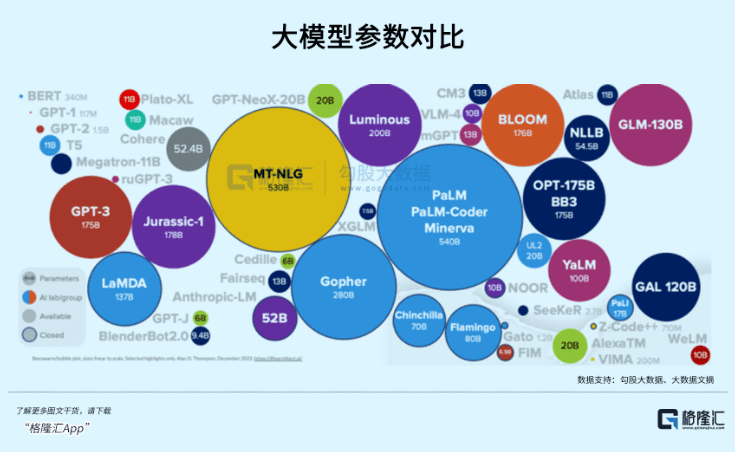
在Transformer架构成功融入模型训练中后,数据规模超线性地增长驱动了模型性能的涌现。这就是说,模型参数规模越大,进步得越明显,这是支撑GPT3.5、GPT4、GPT5甚至以后6789的信仰。
然而,开发顶级LLM模型的难度不小,代价不菲。GPT不断迭代会让模仿者望尘莫及,当训练一个更高层级的GPT模型花费成倍级增长时,资本需求自行创造了一定的准入壁垒,在这一层面上没有多少公司能够参与竞争,模型迭代速度决定了Open AI和其他势力的追赶差距,而规模法则助力了这一点。
正如台积电每一代制程升级的成本代代迭升,技术壁垒和花费跟上一代都拉开了巨大差距,但实际上大多数电子产品根本用不上最顶尖的芯片,也因为广泛的需求,落后好几代的制程芯片能以更低的成本使用。
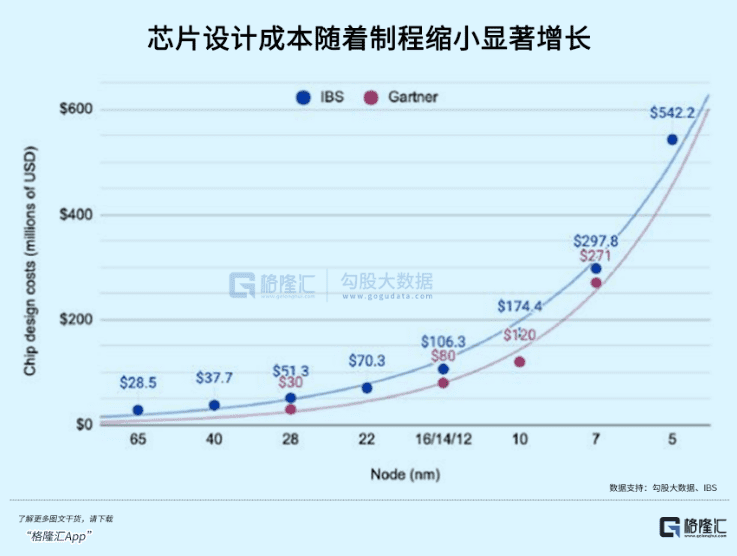
类似的,大模型领域将来可能也会出现这样一种格局,Open AI或者Google作为最顶尖的大模型是极度稀缺的,在某些功能上遥遥领先,而总是落后一代的模型,可能要跟实际使用需求融合得更贴近。
最终两三个最通用的模型可能会站在塔尖,孕育出无数个定制化小模型和应用,这也是OpenAI不愿意错过的商业机会。
几天前,公司刚升级Fine-tuning用户界面,不用写代码,上传训练数据就可以微调大模型, 通过额外的训练,可以让已经训练过的大模型更好完成特定的任务,比如用你自己的风格写文章的大模型。这就是要一步步把中游工具层吃掉的意思。
成为平台玩家之后,OpenAI同样不可避免地要应对商业竞争和自身盈利的要求,经营大模型的成本花费不菲也曾令OpenAI变现的压力骤增。
数月以前,Analytics India Magazine的一份报告中称,OpenAI仅运行其人工智能服务ChatGPT每天就要花费约70万美元,绝大部分花费主要来自高昂的GPU以及人才成本。
GPT3.5爆火后,OpenAI一步步开始构建商业化流程。先是推出ChatGPT Plus收费版,再有ChatGPT 商业版,为了增加营收,OpenAI还多次调整了GPT-4的访问限制。
同期meta和Google相继发力给OpenAI带来不小的压力。其中针对了Google即将发布的Gemini,察觉到威胁的Open AI就已经抢先为GPT4增加图像能力。在接下来的11月6日,OpenAI开发者大会上还将公布“伟大的新工具”,外界纷纷猜测那会是GPT-5。

来源:ChatGPT APP
根据The Information爆料,OpenAI在2022年亏损达到5.4亿美元,但今年营收就能达到13亿美元。才短短10个月的时间,多套组合拳的配合让OpenAI完成了由亏转盈,10亿美元,原是CEO奥特曼年初对2024年的目标。
截至7月份,ChatGPT Plus付费用户达到了200万;在B端市场,企业版ChatGPT已经被超过80%的财富500强公司团队采用。
但处在金字塔尖的模型迭代所需要的算力估计每年都会上升一个数量级,随着应用场景变得更广,这会让不同的专有模型数量倍增,进而大大提升模型部署所需要的算力。
根据机构分析,如果ChatGPT的访问量达到谷歌搜索十分之一的水平,那么每年OpenAI的GPU开销将达到160亿美元,这样的开销未来可能是阻止OpenAI进一步规模化的重要瓶颈。
OpenAI自研芯片和特斯拉研制Dojo实际上很相似,针对性非常高,降本空间也很大。凭借公司对模型的积累,能够根据模型的需求去明确芯片的设计指标,而且对于模型版本有着明确规划,不至于出现芯片量产之后模型已经领先一代的局面。
正因在高性能计算芯片领域,算法和芯片架构协同才是主要的性能提升动力,OpenAI在这方面处于一个比较有利的地位,凭借对算法的深刻理解,公司有望充分利用Huang’s Law做出芯片。
OpenAI还有一项很重要的动作,可能来自应用端的延伸。ChatGPT是公司第一个Killer App,但聊天机器人的应用场景比较局限于文字交互。多模态的降临再度丰富了应用落地的想象力,不过被meta抢先实现了。
Meta上月末公开发布的这款价值299美刀的AI智能眼镜搭载了AI助手Meta AI,内置摄像头,在功能上实现了多模态交互,能玩的事情就比较多了,比如,旅行时讲解各种地标建筑,翻译多种语言菜单,指导维修水管,还支持第一视角的在线实时直播。

与苹果前首席设计师乔纳森一起研发的AI硬件,很可能就是一款支持GPT4甚至5的智能眼镜,但对终端芯片的要求更高了,这次再次看到了OpenAI可能借由硬件布局从定义模型层到产品应用层的潜在路径。
三、尾声
总的来说,多模型的趋势对于Open AI也许是压力,也许是机会,技术迭代远远未至极限,如何突围并引领市场规模增长将会是它面临的主要挑战。
在ChatGPT诞生的大半年里,也不乏像数据泄露安全,侵犯版权这样负面事件影响人们对AI工具的信心,对这些弯弯绕绕,对人工智能的未来,OpenAI没有明确的计划来应对。
当初Sam Altman一批人集结起来的第一个问题就是“我们要做什么”。
如果大模型也有着类似自动驾驶等级的划分,那我们现在或许还处在L1到L2的阶段,而当初这批热血科学家个个都想做出AGI,但究竟会不会有L5这个层级,没人敢打包票。
OpenAI和它的竞争对手们都身处在同一片迷宫里。
用Altman的话说,他们当前的状态,就是每次走到拐角的地方,就拿手电筒照一照,最终到达终点。
本文来自微信公众号:格隆汇APP (ID:hkguruclub),作者:弗雷迪,数据支持:勾股大数据