
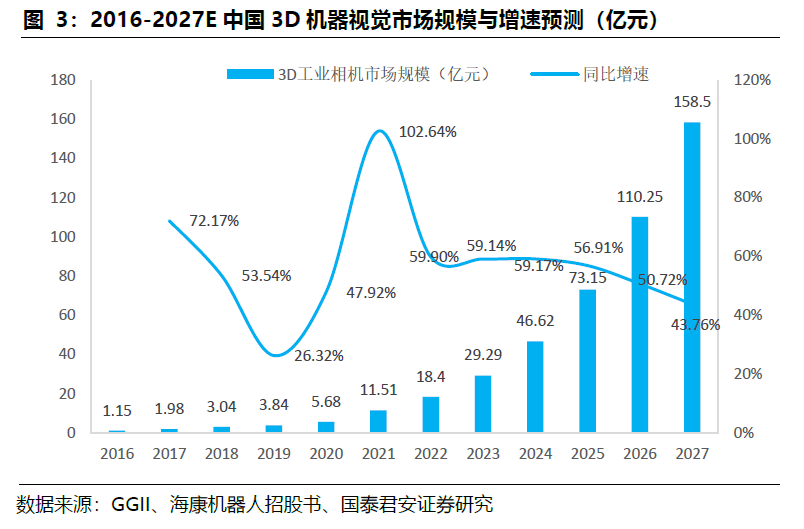
从2D视觉到3D视觉是一次技术的跃升。3D视觉针对工业自动化应用上的“痛点”,提升缺陷识别的精度和自动化产线在线检测的速度,加速在机器人引导和移动机器人环境感知场景落地。针对不同自动化领域的专业化定制是3D工业视觉的主要特征,视觉大模型赋能3D工业视觉,降低定制化开发的成本,提升定制化开发的效率,有效拓展应用场景。我们认为,3D视觉的渗透率有望快速提升,2022年中国3D工业相机市场规模18.4亿元/yoy+59.9%,预计2027年将接近160亿元,复合增速53.8%。
3D视觉技术满足工业领域更高精度、更高速度、更柔性化的需求,扩大工业自动化的场景。2D视觉技术基于物体平面轮廓,无法获得曲度、空间坐标等三维参数,检验精度低。激光三角测量、结构光、ToF、多目视觉等技术共同推动了3D视觉发展。高精度缺陷检测场景(如:半导体有图形晶圆检测)技术要求最高,主要采用激光三角测量、干涉和共聚焦技术;生产线在线检测和装配最难,需要复杂的解决方案来适应不同的生产场景,并在振动和环境光干扰下实现高速度和高精度,主要技术是激光三角测量和结构光。仓库自动化(尺寸测量、环境感知、手势识别、随机拣箱)主要采用结构光和立体视觉。
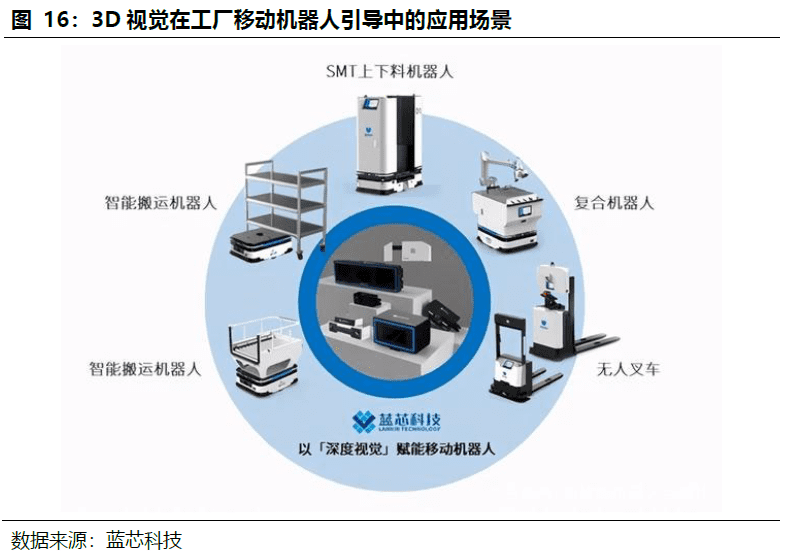
移动机器人视觉引导最具前景的场景,主要技术包括结构光、ToF、立体视觉。环境感知具备宽视场、高速度(用于实时视觉伺服)、高精度的要求,技术路径尚未确定。特斯拉Optimus的3D传感模块以多目视觉为主,全身搭载8个摄像头,自研SoC芯片FSD,纯视觉方案硬件成本低,对软件算法要求高。国内外其余厂商多采用3D相机+激光雷达方案,优必选WALKERX的视觉模块采用多目视觉,小米CyberOne的Mi-Sense采用iToF+RGB,追觅采用ToF+结构光,智元A1采用RGBD相机。
从深度学习到通用视觉大模型,AI助力机器视觉提升效率,拓展应用场景。过去工业机器视觉主要针对垂直场景的少量数据进行小模型训练,模型处理问题的复杂程度受限。23年4月Meta发布通用图像分割大模型SAM,视觉大模型赋能3D视觉,可以实现:a.大模型在广泛下游场景中具备优势,有望降低定制化开发成本,提升机器视觉产品毛利率,快速拓展应用场景。B.大模型在零样本或少量样本上表现优秀,机器视觉将在这些领域得以拓展,如从代码驱动变为视觉驱动的机器人、流程工业场景。
在精密检测及测量场景中,原2D视觉头部厂商优势较大;在机器人引导类场景中,内资初创型厂商以快速设计并落地方案的优势,处于领先地位。在精密检测及测量场景中,3D通常是与1D、2D技术融合使用,现有2D视觉领导厂商依靠成熟的供应链以及深厚的行业Know-How,依然会主导行业发展,领先的企业有:基恩士、奥普特、大恒图像、凌云光等。
国内3D工业视觉企业主要集中设备组装和集成环节,依靠性价比、深度定制以及服务能力赢得市场,但其主要核心零部件(机器人运动算法、应用工艺包,3D工业相机)主要为外购。在移动机器人引导应用中,内资初创型3D视觉厂商处于领先地位。目前大部分企业集中在机械臂进行分拣、上下料等场景,代表企业:梅卡曼德、图漾科技、熵智科技、迈德威视、知象光电、埃尔森、海康机器人、迁移科技、如本科技等。以视觉为主要导航方式的移动机器人在国内还较少,如海康机器人、灵动科技、马路创新、蓝芯科技等。
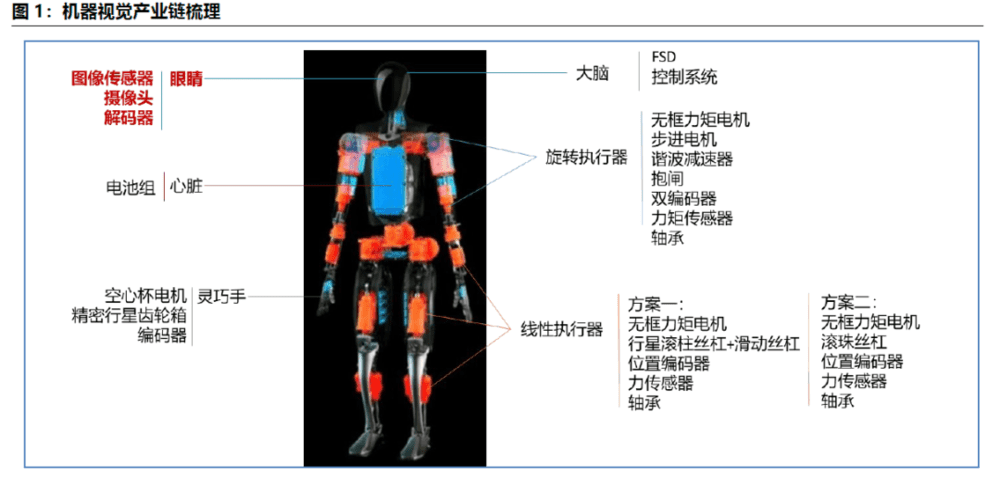
一、视觉:为机器人装上眼睛
1. 预计2022-2027年中国3D工业视觉CAGR=53.8%
预计2027年中国机器视觉市场规模为566亿元,CAGR为27%。根据MarketsandMarkets和高工产业研究院数据,2022-2027年全球机器视觉市场规模提升到172亿美元,年复合增速7.4%,中国市场规模预计从170.7亿人民币提升到565.6亿元,年复合增速27.1%,远高于全球水平。
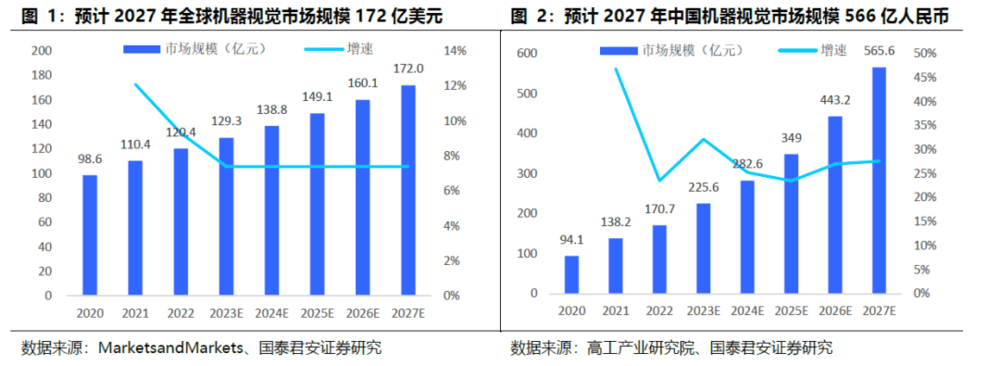
预计2027年中国3D工业相机市场规模为160亿元人民币,2022~2027年CAGR为53.8%。GGII数据显示,2022年中国3D工业相机市场规模为18.40亿元,同比增长59.90%,渗透率接近10%。随着制造业智能化深入,预计2027年3D工业相机市场规模将接近160亿元,2022~2027年CAGR为53.8%。
2. 识别、定位、测量、检测的视觉技术难度递增
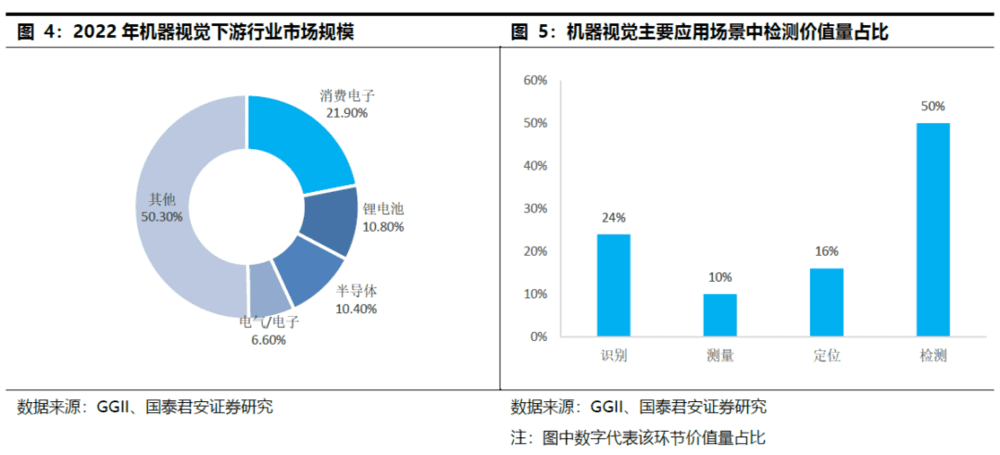
机器视觉下游应用行业,消费电子占21.9%,锂电、半导体各占10%,电气/电子占比6.6%。在国内,机器视觉在3C行业的需求量最大,应用覆盖电子元器件的生产、组装、检测、识别、分类以及读码追溯的全流程。近年来,国内新能源、半导体、汽车行业视觉渗透率快速提升。
从技术难度上来说,识别、定位、测量、检测的技术难度递增。在线检测需要在短时间内对大量的图像数据进行处理和分析,同时要保证检测的准确性和可靠性,不受环境因素的干扰。由于工业细分场景繁多,在线检测要适应不同的产品类型、规格、形状,能够自动识别和调整检测参数和策略,处理复杂的图像特征和背景干扰,实现自动学习和优化。
从消费电子、锂电池、半导体三个典型行业的具体场景,看机器视觉的应用:
a.消费电子领域,机器视觉主要用于过程检测、尺寸测量和尺寸全检。制程中检测包括准确的视觉检测、高效的尺寸测量、结合大数据快速定位发生源头。关键尺寸测量包括螺丝孔尺寸测量,关键轮廓的测量,信号和焊接尺寸测量。尺寸全检包括所有装配位置度的测量,孔径长宽尺寸测量,特征结构匹配测量不确定的漏失。
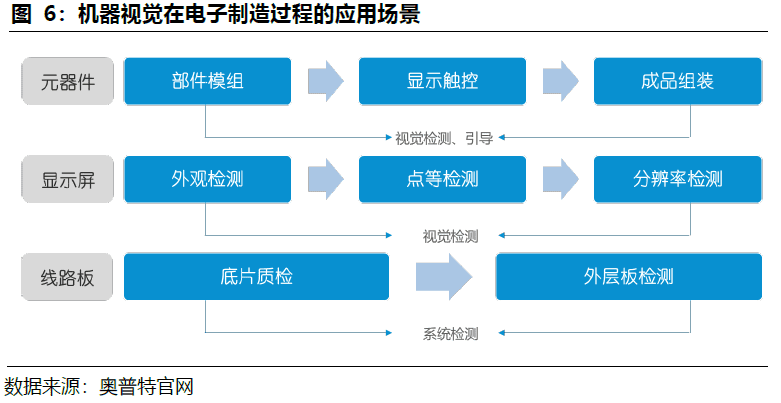
b.动力电池制造过程中,机器视觉应用于关键工艺的缺陷检测、尺寸测量和定位。电芯前段工序,在涂布、辊压等环节,锂电池容易产生露箔、暗斑、亮斑、划痕等缺陷,机器视觉主要用于涂布的涂覆纠偏、尺寸测量,极片的表面缺陷检测、尺寸测量、卷绕对齐度等环节。电新后段工序,主要应用于裸电芯极耳翻折、极耳裁切碎屑、入壳顶盖和密封钉焊接质量检测、电芯外观检测、尺寸测量、贴胶定位等;模组和PACK阶段,主要用于底部蓝胶、BUSBAR焊缝、侧焊缝、模组全尺寸和PACK检测等。
c.半导体领域,机器视觉主要应用于硅片检测分选、晶圆缺陷检测和成品外观检测,尤其是晶圆制造中的检测、定位、切割、封装全过程都需应用机器视觉技术。硅片检测分选使用3D测量系统,实现对硅片产品多种性能参数一站式自动检测,实现检测数据管理可视化分析统计,并对硅片质量等级自动分类。半导体工艺检测使用机器视觉实现制造工艺外观缺陷的3D、2D检测,晶圆表面缺陷、杂物、裂纹、切割削裂等检测。实现封装工艺、晶片不良、胶水不良、焊线不良、焊球不良以及杂物检测。成品外观检测主要包括划痕检测、电池检测、插卡槽检测。

3. 3D视觉最有前景的场景:机器人引导、高精度测量、缺陷识别
3D视觉技术在检测精度、光照环境等性能远超2D。2D视觉技术在工业自动化过程的应用已经超过30年时间,2D视觉基于物体平面轮廓驱动,解决部分二维层面的读条识别、边缘检测等问题,无法获得曲度、空间坐标等三维参数,完全可以满足外观检测、识别等应用,但检验精度低。
3D视觉技术在2014年前后开始兴起,利用立体摄像、激光雷达等技术准确地完成物体三维信息的采集,对于光照条件、物体对比度等客观因素适应能力更强,可以实现2D视觉无法实现或者不好实现的功能,例如检测产品的高度、平面度、体积等和三维建模等,更加适配半导体、汽车、3C等领域的高精度工业需求,检测要求精度达到<1μm。

3D工业视觉提升了检测和测量的精度和效率,扩大了质量控制在线检测的应用范围,在机器人引导(移动机器人+3D视觉、机械臂+3D视觉)场景应用前景广阔。

目前3D视觉最有前景的工业应用场景:高精度的测量及缺陷识别、高速高精度的在线检测、自动装配、视觉引导机器人等。
a.扩大质量控制在线检测的应用范围:2D视觉技术在低对比度、高反射或透明材料或带有阴影的特征等方面存在局限。由于这些限制,即使在最先进的制造商的工厂里,也只有30-40%的组件进行了在线检测。3D视觉可以很好地解决这些问题,扩大质量控制在线检测的范围。


b.协作机械臂柔性装配:总装是目前大多数行业自动化程度最低的环节之一,它涉及精确的校准,各种各样的工件,以及潜在的频繁变化。在汽车制造中,焊接过程的自动化程度约为90%,而组装的自动化程度不到5%。3D视觉是使用协作机器人和其他先进自动化设备的下一代柔性装配系统的使能技术。

c.仓库自动化,随机拣箱是应用难点。存储、检索、分类和码垛都需要3D视觉来确定包的尺寸。拣箱是实现工厂和仓库的基本功能。近年来生产和物流自动化的程度已经得到大幅提升,但随机拣箱(许多类型的物体重叠和堆积,而不是排列在一个平面上)的场景仍然没有实现无人化。3D视觉不仅可以识别物体,还可以让机器人辨别物体的位姿,并通过视觉伺服控制机器人进行工作。
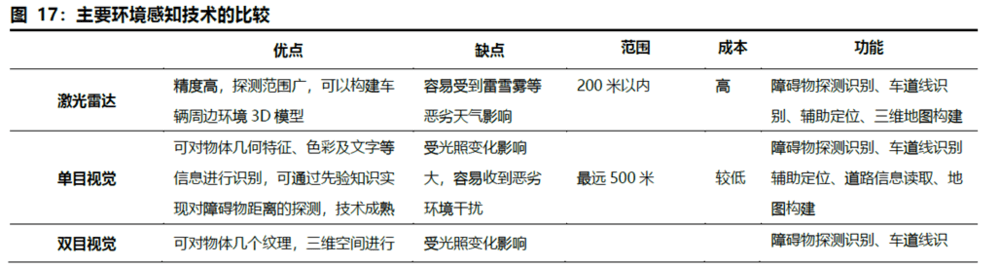
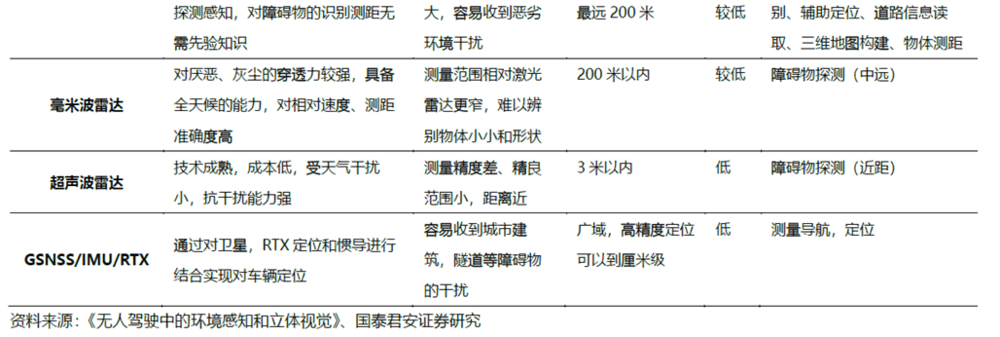
d.视觉引导机器人:引导定位分为移动机器人+机器视觉、机械臂+机器视觉两种路线。几类环境感知技术中,激光雷达和毫米波雷达都具有明显的优劣势,激光雷达精度高,探测范围比较广,可以构建机器人和周围环境的3D信息,但受天气的干扰较强;毫米波雷达对于烟雾、灰尘等环境的穿透性较强,所以在特殊环境下它的测距信息会比较好,但是测距精度要弱一些。视觉感知会有效弥补其他感知技术的缺点,对于可靠性要求高的场合,立体视觉加毫米波也是一个很好的组合,视觉感知的技术成本会比激光雷达更低。
二、从2D成像到3D视觉感知,是一次技术的跃迁
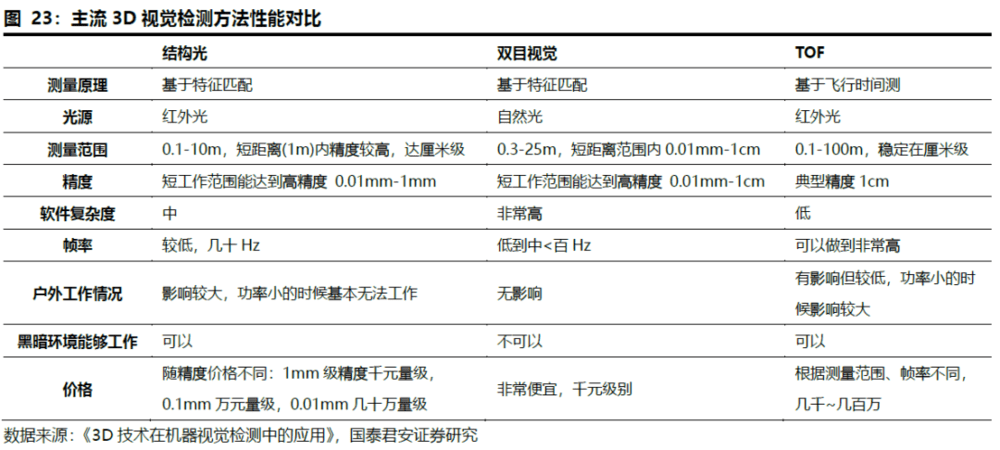
1. 激光三角测量、结构光、ToF、多目视觉等技术共同推动了3D视觉的发展
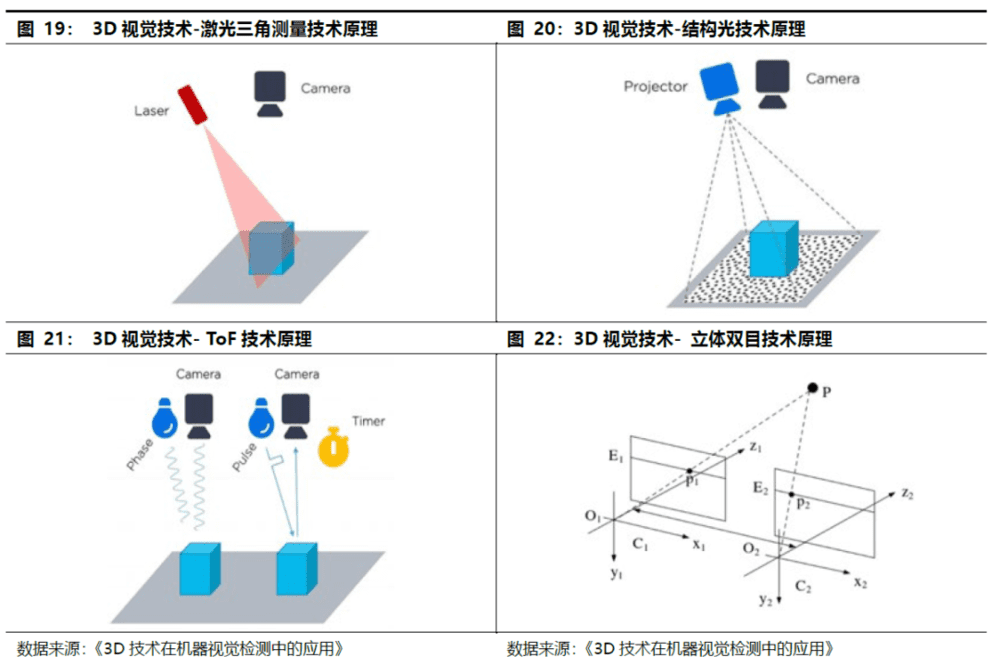
3D视觉常用四种技术:激光三角测量、结构光、飞行时间(ToF)、多目视觉。工作原理均为红外激光发射器发射出近红外光,经过人脸反射后,红外信息被红外光CMOS图像处理器接收,并将信息汇总至图像处理芯片,得到物体的三维数据,实现空间定位。不同之处在于:发射近红外光取得三维数据的方式,激光三角测量用激光线扫描物体表面,结构光发射的是散斑,ToF是发射面光源,而双目立体成像则是通过双目匹配,进行视差算法。
激光三角测量:也被称为“位移传感器”。该方法采用激光线扫描物体表面,并通过相机观察到的激光线变形分析、获得物体表面每个点的深度数据。特点:测量结果能够达到微米级,但扫描速度和工作范围有限。激光三角测量的高精度、动态测速性能促使在线检测发展迅速。
结构光:通过光学投射模块将具有编码信息的结构光投射到物体表面,在被测物表面形成光条图像。图像采集系统采集光条图像后,通过算法处理得出被测物表面的三维轮廓数据,以还原目标物体三维空间信息。结构光技术是一种主动的三维测量技术。特点:由于结构光是主动光,好处是昏暗环境和夜间可用。不需要根据场景的变化而有变化,降低了匹配的难度。但显然在强光环境中会受到干扰,室外基本不可用。
另外,由于主动结构光是带编码的,所以多个结构光相机同时使用也是有问题的。在实测中,结构光在角度比较小的侧面上反射比较严重,经常出现比较大的黑洞,当然黑色物体和玻璃是结构光的大BUG,一个吸光一个透光。
飞行时间(ToF):由发射和反射光信号之间的时间延迟来测量,给定固定的光速。为了精确地测量时延,经常使用短光脉冲。这种技术跟3D激光传感器原理基本类似,只不过3D激光传感器是逐点扫描,而ToF相机则是同时得到整幅图像的深度信息。特点:和结构光方式相比,ToF并不需要对光的图案做复杂解析,只需要反射回来即可,这大大的提高了鲁棒性,深度信息还原度比结构光好很多,点云的完整性更好。
主要表现在:深度图质量要高于结构光,抗强光的干扰能力也更强一些,精度也要更高一些。对于玻璃,是光技术的死穴,只能靠其他技术来弥补了。ToF速度高,但精度只有毫米级。ToF技术的难度较高,成本也较高。
立体视觉法:指从不同的视点获取两幅或多幅图像重构目标物体3D结构或深度信息,目前立体视觉3D可以通过单目、双目、多目实现。双目机器视觉是指使用两个RGB彩色相机采集图像,并通过后端的双目匹配和三角测量等算法,计算得到深度图的技术方法。双目技术使用的是物体本身的特征点,由于每一次双目匹配都面对不同的图像,都需要重新提取特征点,计算量非常大。双目是一种被动的三维测量技术。
特点:硬件复杂度较低,弱光或目标特征不明显时几乎不可用。同时,双目相机的运算复杂度也非常高,对硬件计算性能要求极高。因为计算能力要求高,双目相机极少在嵌入式系统设备中使用,双目相机在通用场景中表现也并不太好,像诸如slam导航等应用,但在工业自动化领域和x86系统中,双目相机应用广泛,因为工业自动化中,双目相机只要解决特定场景中的特定问题。

2. 移动机器人引导技术方案未定,高精度量测主要用激光三角法
3D视觉常用技术的重点应用场景和特征总结如下:
a.检测尤其是高精度的缺陷检测场景(典型代表:半导体有图形晶圆检测)是技术要求最高的,主要采用激光三角测量技术。
b.生产线在线检测是最难的,需要复杂的解决方案来适应不同的生产场景,并在振动和环境光干扰下实现高速度和高精度。主要应用的技术是激光三角测量技术和结构光技术,激光三角测量技术也可以用于生产线上的柔性装配领域。
c.仓库自动化:包括尺寸测量、环境感知、手势识别等功能,主要采用结构光技术和单目/双目视觉技术,随机拣箱主要采用结构光技术。这些功能也会在消费场景中得到应用,如手机的人脸识别、手势识别等。
d.机器人视觉引导是目前最具前景的场景。由于环境感知具备宽视场、高速度(用于实时视觉伺服)、高精度的要求,最终的技术路径尚未确定,目前主要用到的技术包括结构光、ToF、立体视觉。
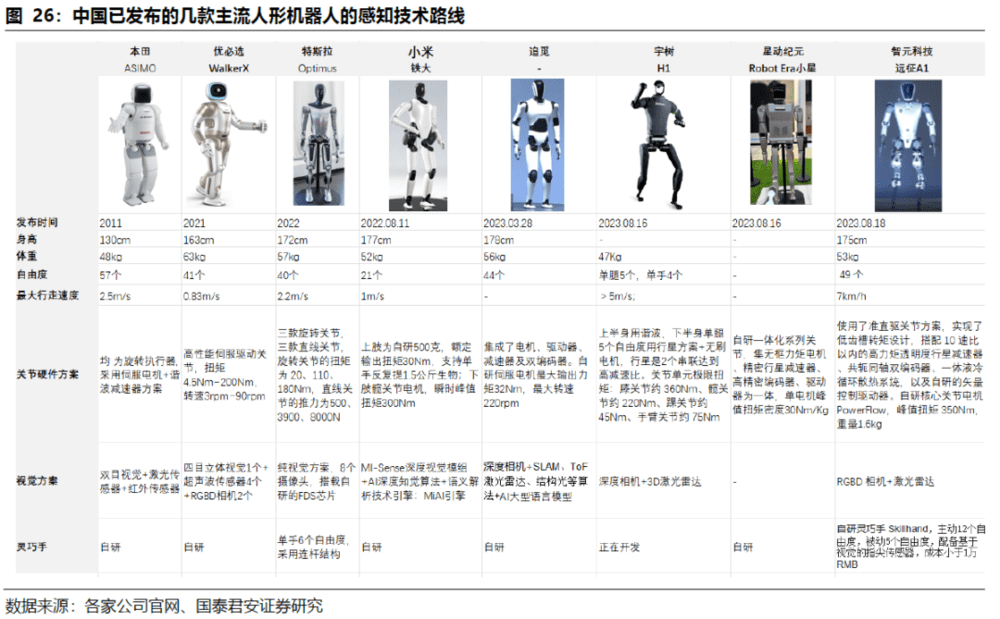
3. 人形机器人主要采用ToF、立体视觉
特斯拉采取纯视觉方案,其余大多数人形机器人厂商采用深度相机+激光/超声波雷达的方案。特斯拉Optimus机器人的3D传感模块以多目视觉为主,波士顿动力Atlas采用激光雷达+深度相机,优必选WALKERX采用基于多目视觉传感器的3D视觉定位,小米CyberOne机器人所搭载的Mi-Sense深度视觉模组是由小米设计,欧菲光协同开发完成,其机器视觉深度相机模块主要由iToF模组、RGB模组、可选的IMU模块组成。
特斯拉采取纯视觉方案,硬件成本低,对软件算法要求高。特斯拉人形机器人共搭载8个摄像头,搭载自研的FDS芯片,实现360°环绕的影像识别。FSD系统可以实现每1.5毫秒2500次搜索的超高效率,预测可能出现的各种情况,并在其中规划出最安全、最舒适、最快速的路径。
特斯拉自主研发了基于神经网络的训练方式,拥有一支1000人左右由世界各地人才组成的数据标注团队,每天对视频数据中的物体在“矢量空间”中进行标注,在善于把握细节的人工标注和效率更高的自动标注配合下,只需要标注一次,“矢量空间”就能自动标注所有摄像头的多帧画面。这为特斯拉带来了上百亿级的有效且多样化的原生数据,而这些数据都会用于神经网络培训。
多任务学习HydraNets神经网络架构可以将8个摄像头获取的画面拼接起来,并完美平衡视频画面的延迟和精准度。通过人工或自动标注环境和动静物体,系统会逐帧分析视频画面,了解物体的纵深、速度等信息,再将这些数据交给机器人学习,绘制3D鸟瞰视图,形成4D的空间和时间标签的“路网”以呈现道路等信息,帮助车辆/机器人把握驾驶环境,更精准的寻找最优路径。

国内外人形机器人厂商多采用激光雷达+深度视觉的方案。激光雷达的方案成本比纯视觉方案高,对软件算法的要求相对纯视觉方案低。优必选WALKERX的视觉模块采用多目视觉,小米CyberOne的Mi-Sense采用iToF+RGB,追觅采用ToF+结构光,智元A1采用RGBD相机。
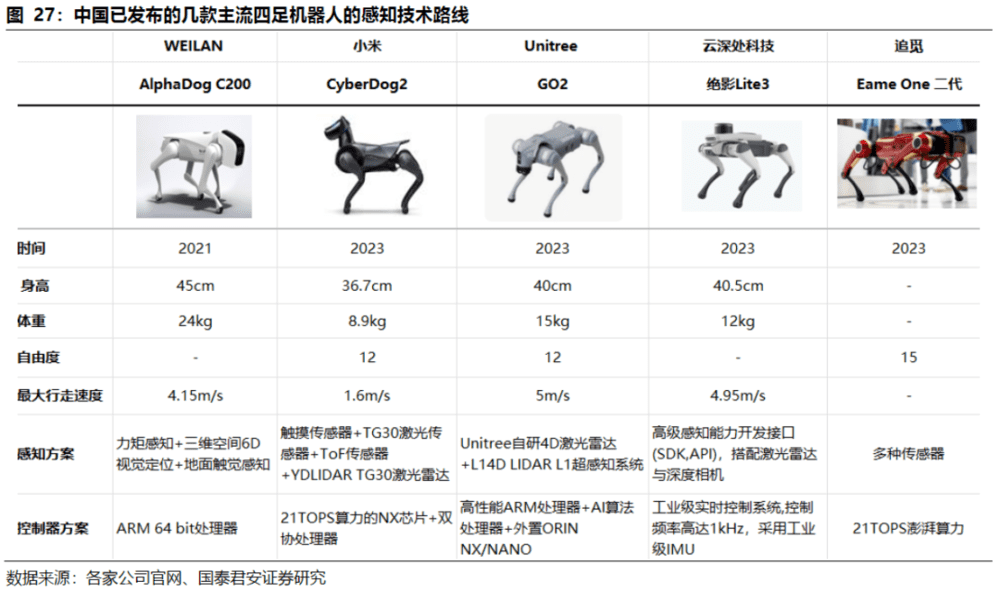
三、3D视觉行业格局
1. 专业化定制趋势明确
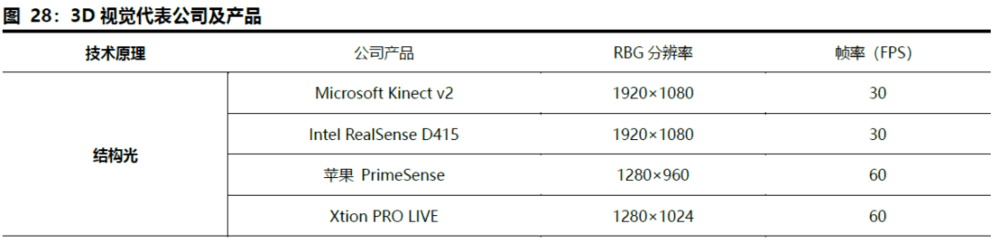
消费电子领域是目前3D视觉感知最大的应用领域,占比近40%。2017年苹果发布的 iPhone X搭载了前置3D结构光视觉传感器,标志着3D视觉感知技术在消费级领域开始规模化普及。3D视觉感知技术逐步在智能手机、移动支付、AIoT、刷脸支付、智能门锁、3D 看房等领域加速落地。代表公司:
1)结构光:苹果(Prime Sense),微软Kinect-1,英特尔RealSense,Mantis Vision,奥比中光等;
2)双目视觉:Leap Motion,ZED,大疆等,代表应用及产品:大疆创新搭载了双目视觉系统的无人机如Phantom Pro/Pro+、Mavic 2Pro/Zoom等;
3)光飞行时间:微软Kinect-2,PMD,SoftKinect,联想Phab等。代表应用及产品:2020年苹果推出搭载了基于dToF技术的Lidar扫描仪的iPad Pro及iPhone 12 Pro;华为、魅族等厂商相继推出搭载了基于 iToF 技术的后置3D视觉传感器的智能手机,基于不同技术路线的产品日益丰富;
4)激光雷达:谷歌旗下Waymo公司搭载激光雷达及多传感器的无人驾驶汽车。

在工业领域,3D视觉根据不同应用场景进行专业化定制。机器视觉需要与其他自动化解决方案相互适配,在行业垂直领域的生产过程中,零件类型(材料、形状、尺寸、位置和呈现)、精度公差、生产效率和工作范围都是不同的,导致了视觉产品的定制化要求。在现实世界中,即使是同一行业的相同流程,两个工厂也会有不同的生产环境(照明、振动、几何配置等),需要不同的视觉产品和配置,因此3D视觉的AI模型难以做到规范通用,针对不同自动化生产领域的专业化定制成为3D视觉的发展趋势。
3D工业视觉主流玩家有两类:原2D视觉领域内外资头部厂商、内资初创型厂商。由于定制化程度高,内外资品牌应用场景有明显区分:原2D视觉领域内外资头部厂商在工业高精度高效率量测和识别领域占据优势,国内3D视觉厂商在机器人视觉引导领域领先。同样由于工业场景定制化程度高,以及高精度、高效率的方案要求,工业级3D视觉的产品定价更高,盈利能力更强。
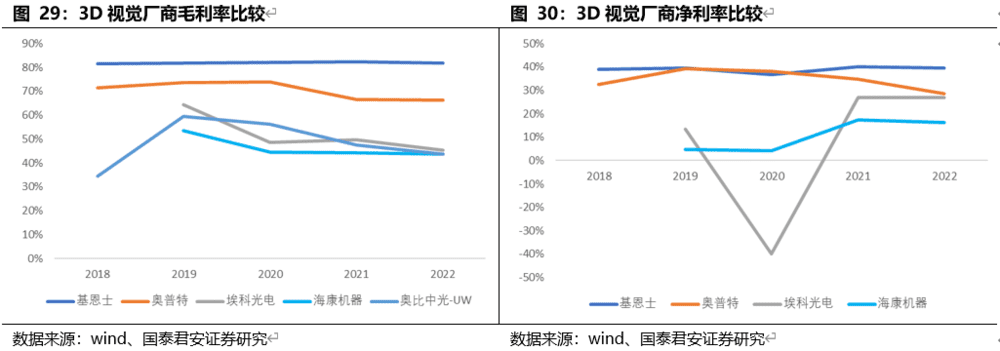
2. 原2D视觉厂商加深护城河
原2D视觉领域的内外资头部厂商,依靠强大的供应链及项目实施经验,3D技术的升级将进一步加深其护城河。在工业领域,3D通常是与1D、2D技术融合使用,领先的工业机器视觉厂商纷纷将技术从2D延申至3D,基于深厚的行业Know-How积累,原2D视觉头部厂商的竞争优势将得到进一步强化。3D相机端,得益于镜头与CMOS传感器的技术领先,基恩士、康耐视的检测间隔可达0.6秒,基恩士、康耐视相机的检验重复精度可达±0.5μm,对比海康±0.06mm相机优势较大;基恩士算法搭载AI芯片,拥有自动特征抽出算法、机器学习算法、预处理功能,康耐视VisionProDeep Learning软件基于AI神经网络模型运算,两者3D定位精度2.5μm,海康算法3D定位精度6μm。
在精密检测及测量应用中,原2D视觉头部厂商优势较大:机器视觉领先厂商主要应用于汽车、3C、锂电池、半导体晶圆检测、芯片检测等中高端领域,产品价值量相对本土产品更高,借助在工业2D视觉中较强的技术和客户积累,头部厂商如基恩士、海康威视、奥普特等在此场景中取得较大出货。
大多数3D视觉国产品牌更多专注于物流、工程机械、金属加工、3C电子等毛利率较低、对产品精度要求相对较低的中低端场景中。如:梅卡曼德、埃尔森等企业专注于机器人引导类型相机;图漾科技、海康机器人产品主要应用于视觉定位;深视智能产品主要应用于精密测量与检测;盛相科技专注于检测场景等。部分领先的国内企业,通过提升核心零部件能力,拓展产品线,应用场景持续往高端领域渗透,代表厂商有奥普特、凌云光、大恒图像、海康机器人等。
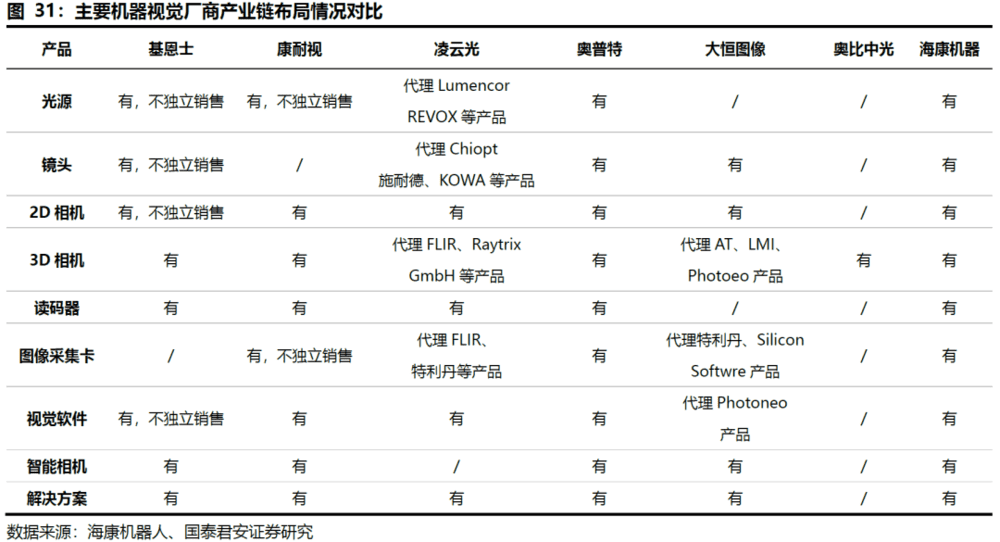
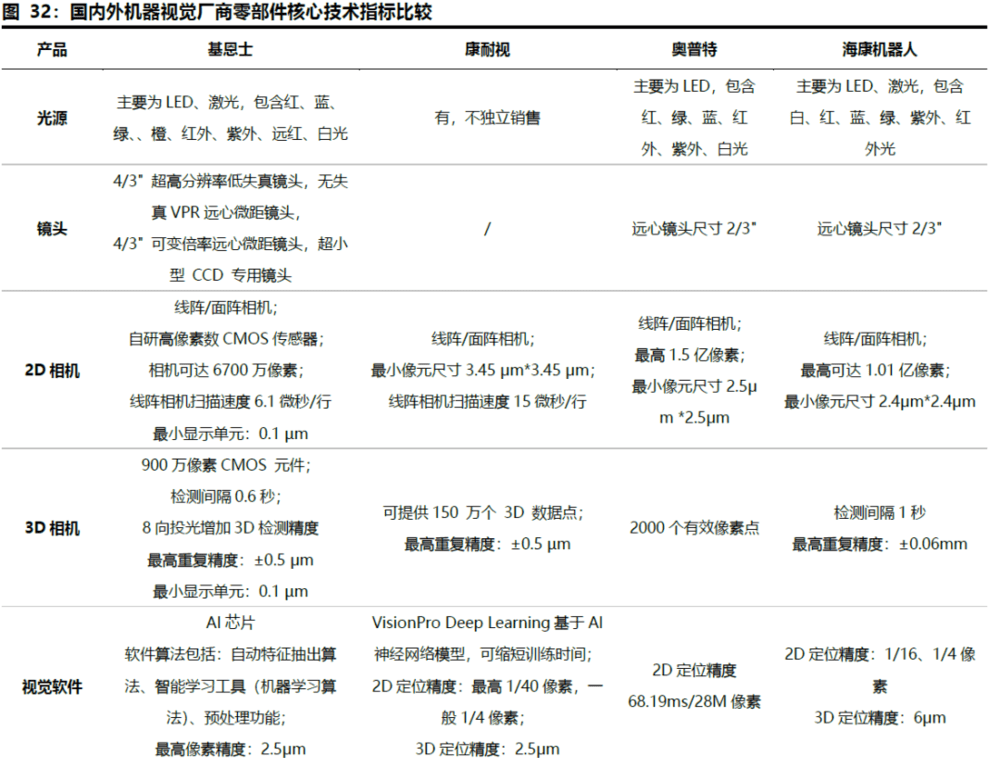

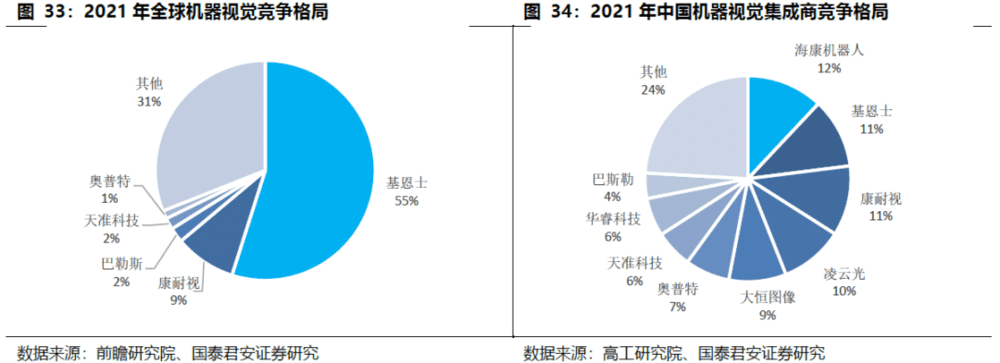
3. 内资初创厂商深耕机器人引导场景,优势明显
国内3D工业视觉市场处于发展早期阶段,产业链不成熟,尚未形成稳定的市场格局。国内3D视觉企业多为初创企业,国内3D视觉企业主要集中在下游设备组装和集成环节,凭借方案的性价比、以深度定制以及服务能力获得客户,但其主要核心零部件(机器人运动算法、应用工艺包,核心3D相机)主要为外购。
在引导类应用中,内资初创型厂商以此为主场快速设计方案并落地,占据优势。引导定位分为移动机器人+机器视觉、机械臂+机器视觉两种路线,大部分3D视觉厂家集中在配合机械臂进行分拣、上下料等作业上,代表企业有:梅卡曼德、图漾科技、熵智科技、迈德威视、知象光电、埃尔森、海康机器人、迁移科技、如本科技等,产品主要应用于机器人视觉定位。以视觉为主要导航方式的移动机器人目前在国内还较少,主要厂商有:海康机器人、灵动科技、马路创新、蓝芯科技等。GGII调研数据显示,2022年中国3D工业相机销量超过5万台,其中机器人引导类3D相机出货量超过8500台。
部分优秀企业已经在基于自身核心技术突破的条件下,向其他应用场景拓展。2022年,梅卡曼德推出面向检测/测量场景的微米级精度工业3D相机Mech-EyeUHP-140,应用于汽车零部件生产和组装等工艺中位置度、间隙、面差等检测/量测类应用;2023年,海康机器人发布光伏组件汇流带视觉检测解决方案,可满足串EL外观检、排版定位、接线盒焊后检测等需求;同年,图漾科技推出面向无序分拣和测量检测等多种场景工业相机PS800-E1。


四、3D视觉核心部件:需努力实现自主可控
3D视觉成像方案是在2D相机基础上进行的结构及软件重构,相机多作为零部件进行外购。3D相机由四部分组成:红外光发射器(IR LD或Vcsel)、红外光摄像头(IR CIS或者其他光电二极管)、可见光摄像头(Vis CIS)、图像处理芯片。红外光发射器发射红外光到物体表面,红外光传感器采集物体的深度图像(Z轴信息),可见光传感器采集物体平面图像(X、Y轴信息),经过图像处理芯片得到三维位置信息。红外摄像头需要特制的窄带滤色片,结构光方案还需要在发射端添加光学棱镜与光栅,双目立体成像多一颗红外光摄像头。
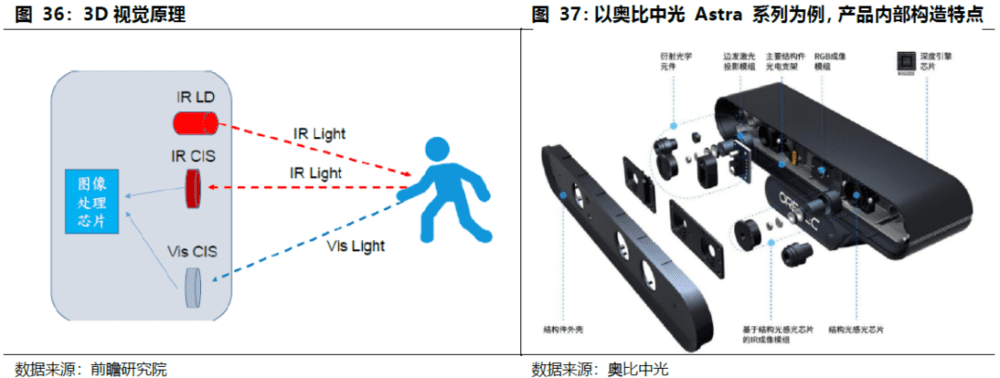
1. 3D光源:红外激光发射器
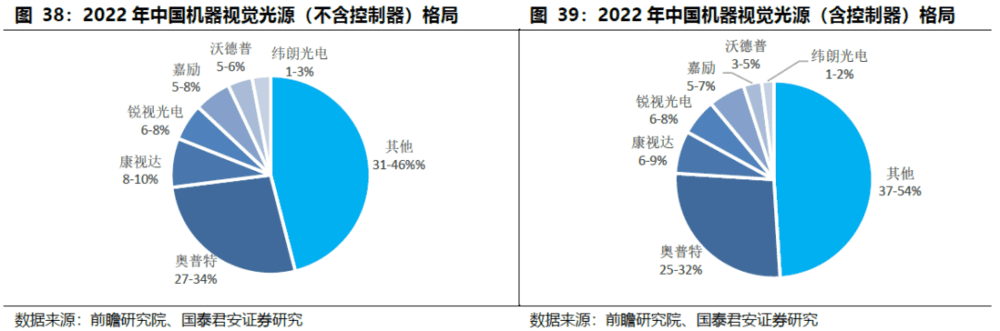
2D光源:竞争激烈,奥普特是国内光源环节最具竞争力的公司之一。机器视觉光源在照度、均匀性和稳定性三个核心指标上有较高的要求,按照类别区分,光源可分为 LED光源、卤素灯、高频荧光灯、激光光源。
全球市场份额大于5%的企业有日本CCS和奥普特,CCS全球市场份10%以上。第二梯队场份额位于1%-5%之间,代表企业包括美国 Advanced Illumination, Inc、中国锐视光电、中国康视达、中国嘉励等。第三梯队市场份额不足1%,代表企业包括日本 Moritex、中国沃德普、中国纬朗光电等。奥普特光源产品覆盖了常见的可见光和不可见光,不可见光产品覆盖波长从280nm~405nm的紫外光及850nm~1500nm的红外光,共有38个系列,近1000款标准化产品,光源控制器包括模拟控制器和数字控制器两类,后者可通过PC远程控制。目前CCS标准光源尺寸厚度最小为3mm,奥普特各型号光源厚度在10mm~20mm之间。
在3D相机中,光源是红外激光发射器,其发射图像的质量对整个识别效果至关重要,VCSEL是近红外光源最佳方案。红外线的主要波长是700nm~2500nm。目前的摄像头图像传感器对900nm以上的红外光感应差,需要更强的光才能感测到,这就要求红外发射器有更大的电流,更多的功耗。
而800nm以下的波长,太靠近可见光,极其容易受到太阳光的干扰,所以一般红外的波长选择在800nm~900nm。可以提供800-1000nm波段的近红外光源主要有三种:红外LED、红外LD-EEL(边发射激光二极管)和VCSEL(垂直腔面发射激光器)。早期3D传感系统一般都使用LED作为红外光源,但由于LED不具有谐振器,导致光束更加发散,在耦合性方面也不如VCSEL,因此演变成了从LED向VCSEL的转变。
VCSEL厂商布局众多。全球主要的VCSEL供应商包括Finsar、Lumentum、Princeton Optronics、ⅡⅥ、ams和Osram等,它们在移动端VCSEL处于前沿的研发角色。国内厂商:武汉光迅、山东太平洋、深圳源国、国星光电、华工科技、光迅科技、三安光电、乾照光电、华灿光电以及睿熙科技等具备中低端VCSEL的设计和生产能力,长春光机所在VCSEL技术研发方面有一定竞争力。结构光需要采用pattern图像进行空间标识,因此需要定制DOE衍射光学元件(苹果、奇景光电、福晶科技、驭光科技等)和WLO晶圆级光学原件(AMS、奇景光电、采钰、晶方科技等)。
红外传感器是距离传感器的高配版,主要由AMS/Heptagon和意法半导体两大厂商主导,国内暂没有企业切入。Heptagon一直致力于小型化TOF传感器开发,2016年被AMS收购。TI和infineon也在这一领域有所布局。
2. 3D红外光摄像头
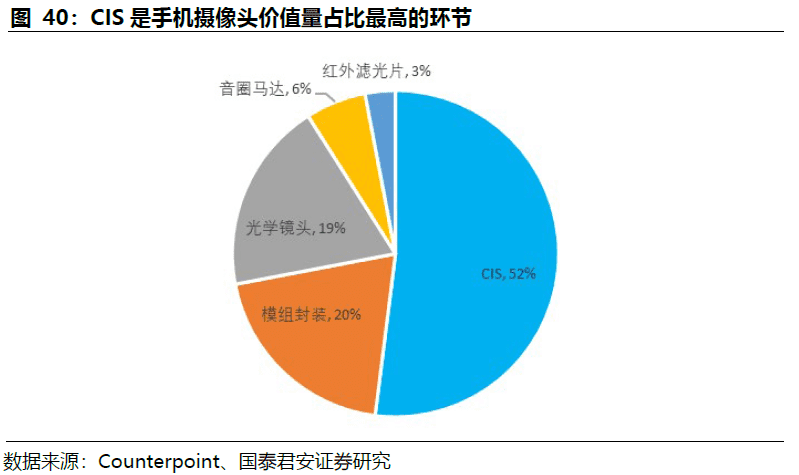
红外光摄像头主要包括:光学镜头、红外窄带干涉滤色片、红外CMOS传感器。以手机摄像头成本构成做参考,CIS是价值量占比最大的部分,模组封装占比20%,光学镜头占比19%。
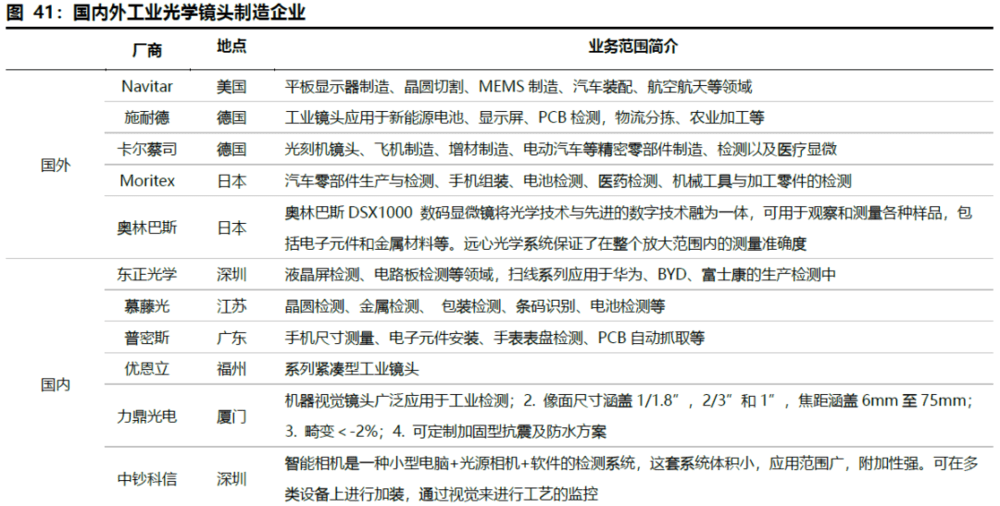
海外品牌垄断工业镜头高端市场,国内厂商开设涉足高端领域。红外摄像头对光学镜头的要求不如可见光摄像头的要求高,对光线的通光量、畸变矫正等指标容忍度高,多采用成熟的普通镜头。可见光摄像头,采用普通镜头模组,用于2D彩色图片拍摄。厂商主要有德国施耐德、卡尔蔡司、美国Navitar、日本KOWA、CBC Computar、Moritex、意大利Opto等,基本垄断国内高端市场领域。
卡尔蔡司与ASML紧密合作,以光刻镜头技术领先半导体制造,施耐德、Navitar等主流厂商的工业镜头广泛应用于晶圆切割、精密零部件检测、航空航天、医疗显微等诸多领域。国内工业镜头部分企业已经能够提供全系列的工业镜头,开始涉足高端市场,如:茂莱光学的产品可以满足不同情况下半导体测试的要求,深圳的东正光学的扫线系列应用于华为、BYD、富士康的生产检测中。

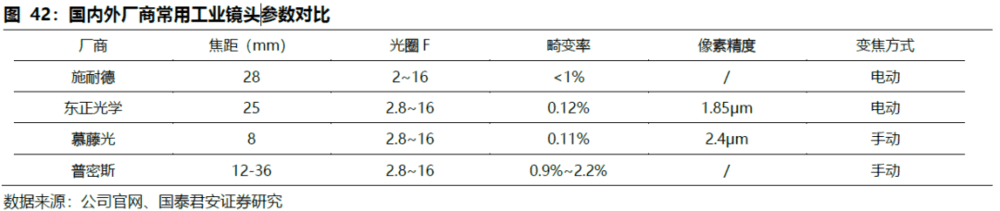
3. 窄带滤光片
滤光片在近红外识别系统中以窄带滤光片为主。对于3D视觉而言,IR红外摄像头与RGB可见光摄像头在滤色片方面存在较大的差异。传统的RGB可见光摄像头,需要采用高通红外滤色片,将不必要的低频近红外光过滤掉,以免红外光线对可见光部分造成影响,产生伪色或波纹,同时可以提高有效分辨率和彩色还原性。
但是红外摄像头,为了不受到环境光线的干扰,需要使用窄带滤色片,只允许特定波段的近红外光通过,目前近红外窄带滤色片主要采用干涉原理,需要几十层光学镀膜构成,相比于RGB 吸收型滤色片具有更高的技术难度和产品价格。
全球范围内窄带滤光片主要厂商:美国的Viavi、水晶光电。其他厂商还有布勒莱宝光学(Buhler)、美题隆精密光学(Materion)、波长科技(Wavelength)等。
4. CMOS图像传感器
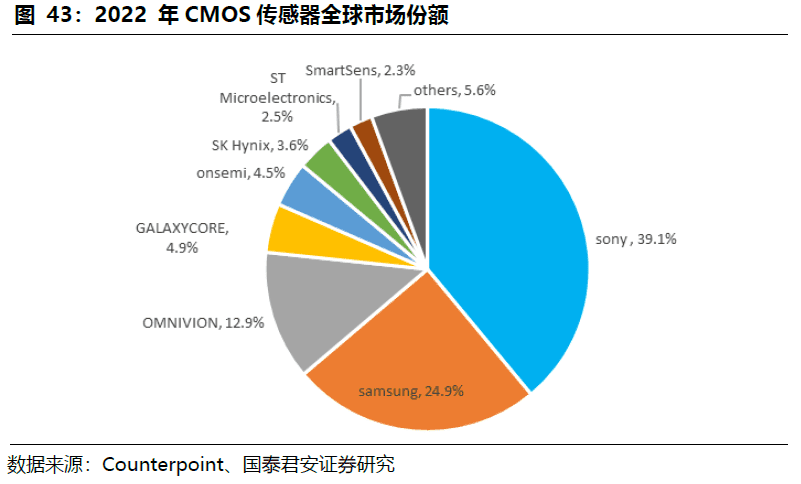
CMOS图像传感器,索尼三星销售额占全球市场55%,格科微全球出货量第一。从硬件构成来看,2D工业相机主要由图像传感器、驱动器、时序发生器以及传输接口组成。长期以来,智能手机保持CMOS需求量的第一位,而随着智能驾驶技术的不断升级,汽车成为增速最快需求端应用。
索尼以自主开发的堆栈式CMOS传感器等技术领先于全球厂商,下游覆盖手机、汽车、智能制造、安防物流等多应用领域;三星在3C电子、汽车领域紧跟其后,国内格科微、豪威等厂商主要布局手机等领域的中低端产品。索尼、三星在全球市场份额占比长期领先全行业,2022年总和达到全球55%。
国产厂商格科微CMOS出货量已经超过索尼,2021年出货22亿颗,连续三年位列全球第一,其产品更多聚焦于低端领域,因此销售额距索尼仍有较大差距。韦尔股份因收购豪威,销售额排在全球前列,国内厂商还有、比亚迪微电子、锐芯微、思比科微、长光辰芯等。
3D图像处理芯片技术壁垒高,目前全球范围内少数几家芯片巨头可以提供该类产品,包括意法半导体、德州仪器、英飞凌等。3D图像处理芯片需要将红外光CIS采集的位置信息与可见光CIS采集的物体平面信息处理成单像素含有深度信息的三维图像,完成3D建模,数据处理和计算复杂度高于一半ISP图像处理芯片,壁垒较高。

五、AI赋能机器视觉,提升具体场景分析能力,拓宽应用场景
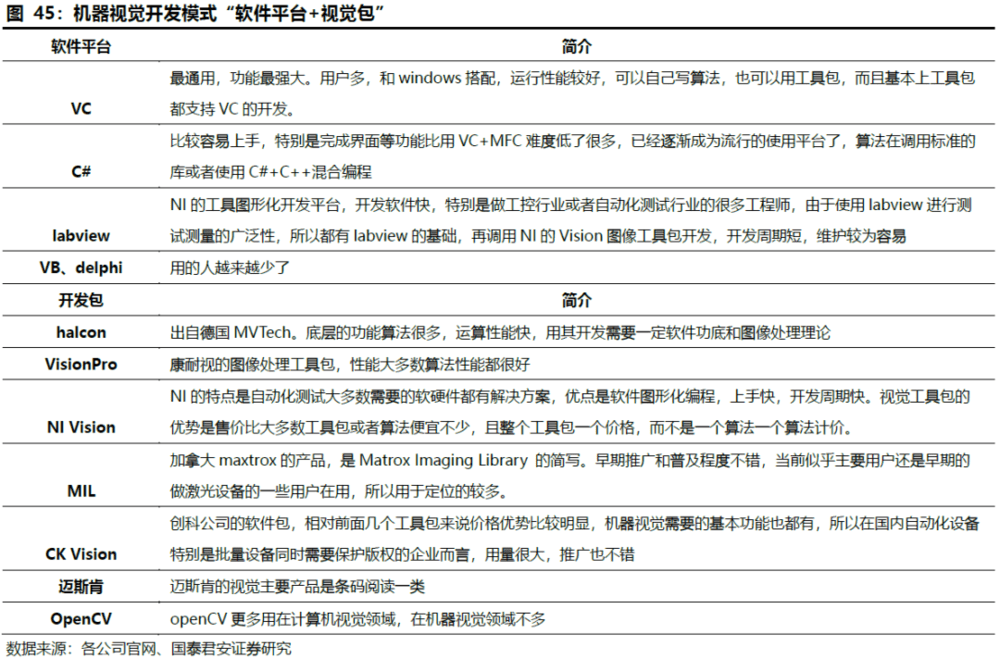
1. 视觉软件开发模式:软件平台+视觉包
机器视觉软件和的开发模式为软件平台+视觉包的模式,针对不同的工艺场景,持续开发迭代工艺包。机器视觉软件的具体衡量指标主要包括定位算法模块数量、算法性能、软件灵活性和易用性。
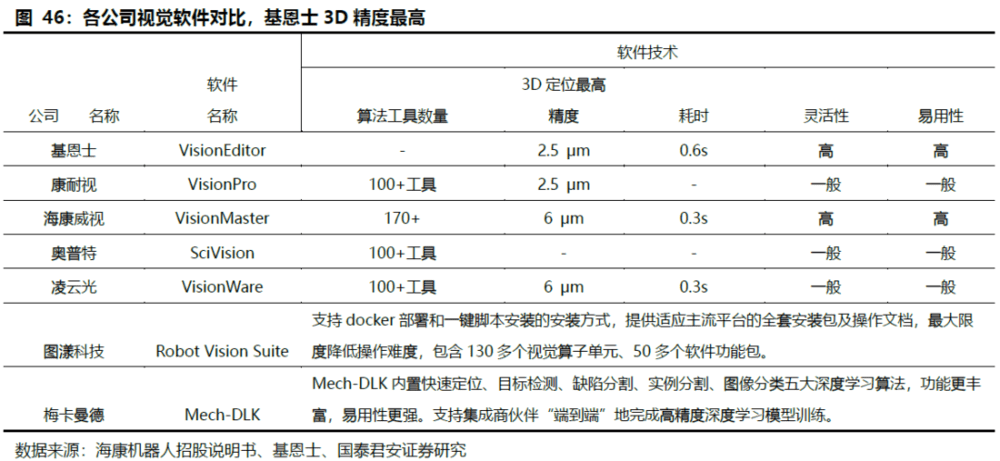
基恩士视觉软件XG-X VisionEditor算法精度与操作xing2领先,支持的3D精度最高可达2.5μm。国内软件算法正在努力追赶,积累众多垂直领域算法,海康自研视觉软件VisionMaster 算法工具包超过170个,奥普特、凌云光机器视觉算法平台VisonWARE,已包含100+算法工具包,支持的3D精度为6μm。
2. 3D视觉和AI技术的应用,提升对具体场景分析的能力
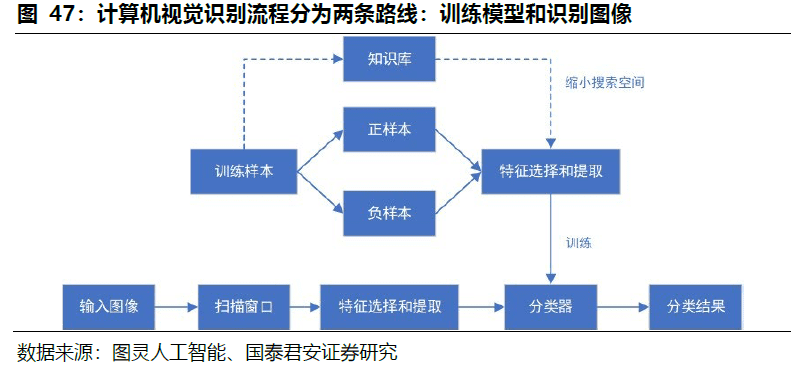
视觉识别流程分为两条路线:训练模型和识别图像。
a.训练模型:样本数据包括正样本(包含待检目标的样本)和负样本(不包含目标的样本),视觉系统利用算法对原始样本进行特征的选择和提取训练出分类器(模型);此外因为样本数据成千上万、提取出来的特征更是翻番,所以一般为了缩短训练的过程,会人为加入知识库(提前告诉计算机一些规则),或者引入限制条件来缩小搜索空间。
b.识别图像:先对图像进行信号变换、降噪等预处理,再来利用分类器对输入图像进行目标检测。一般检测过程为用一个扫描子窗口在待检测的图像中不断的移位滑动,子窗口每到一个位置就会计算出该区域的特征,然后用训练好的分类器对该特征进行筛选,判断该区域是否为目标。
目前世界上图像识别最大的数据库是斯坦福大学人工智能实验室提供的ImageNet,针对诸如医疗等细分领域也需要收集相应的训练数据;谷歌、微软面向市场提供开源算法框架,为初创视觉识别公司提供初级算法。
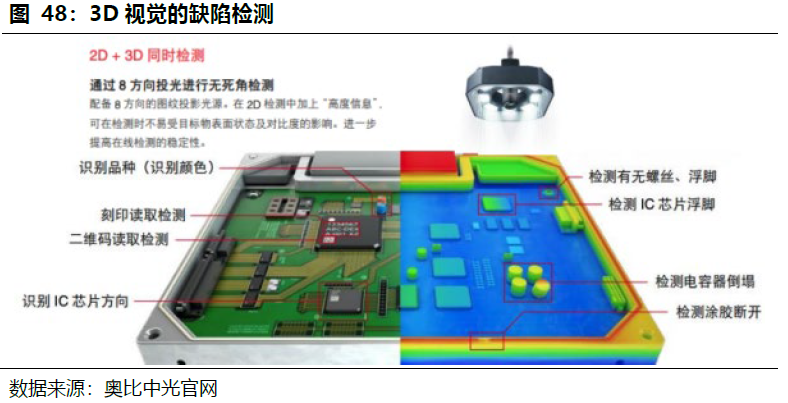
目前工业机器视觉系统主要采用的是基于规则学习的思路。以缺陷检测为例,首先需要人去总结缺陷的类型,提取出判断各类缺陷的特征,再通过大量的含特征的样本训练使得计算机能够区分这些特征从而判断是否存在缺陷。但在检测场景变得复杂时,基于规则学习的思路便无法较好满足要求。基于深度学习的机器视觉,不但可以判断缺陷,还可以理解缺陷的共同特征,预测新的缺陷类型,从而实现对于更复杂场景的更优分析。深度学习技术的应用会对计算能力和储存能力提出更高要求。
3. 结合大模型实现降本增效,推动更广泛的商业化落地
视觉大模型技术突破,赋能机器视觉的革新与突破。过去的工业机器视觉系统主要针对垂直场景的少量数据进行小模型的训练。由干模型参教量有限,因此模型能够处理的问题的复杂程度受到限制。在这一训练模式下,想要针对新的场景进行工业机器视觉的应用,需要更大量的相关场景数据以及对模型进行重新训练,带来了更高的应用推广成本,不利于广泛的商业化落地。
视觉大模型赋能机器视觉产业变革主要体现在两方面:
a.数据成本、训练成本高的场景将有望实现降本增效。大模型在广泛下游场景中具备优异能力,因而有望大幅降低定制化开发产品的成本,带来机器视觉产品毛利率的提升和应用场景拓展的加速。
b.因样本数量不足而机器视觉难以应用的场景将得以拓展。受益于大模型在零样本或者少量样本上的优秀表现,机器视觉将在这些领域得以拓展,比如从代码驱动变为视觉驱动的机器人领域、流程工业场景等。
从卷积神经网络到SAM、SegGPT通用视觉大模型,AI助力机器视觉提升效率。2012年Alex等人提出AlexNet卷积神经网络后,业界不断改进卷积神经网络算法来处理计算机视觉任务,广泛应用在边缘检测(Sobel)、特征提取(SIFT)、图像分割等领域,解决了传统2D算法误差率高(15%以上)、难以叠包分拣、分拣速度低等问题,但仍然存在训练数据量过大、无法处理时序数据、容易过度拟合等影响计算精度的问题。
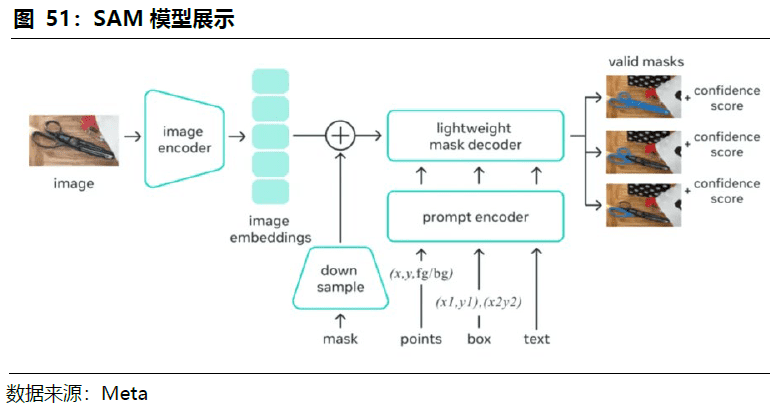
产业界逐渐提出全卷积神经网络算法、基于编码器-解码器概念(Encoder-Decoder)的Transformer、VIT等模型,从像素分割层提升算法精度。2023年4月Meta和智源分别发布通用图像分割模型Segment Anything Model(SAM)和SegGPT,增加交互性和示例的自动推理学习,大大提升监督模型的效果。
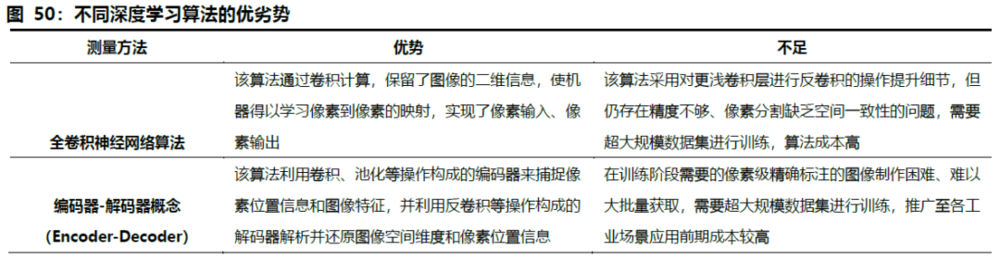
产业内提出弱监督学习算法降低成本。全卷积神经网络算法、编码器-解码器概念两种深度学习算法都为全监督模型,在训练阶段需要的像素级精确标注的图像制作困难、难以大批量获取,推广至各工业场景应用前期成本较高。对此,将简单的标注作为监督信息加入到原有模型进行计算,将结果与标注进行对比,并将以上环节重复迭代直到准确率收敛。弱监督算法主要基于边框级、涂鸦级、图像级标注这三类弱标注素材进行训练,弱标注将大大降低前期训练成本。

SAM和SegGPT大模型助力图像分割精确度提升。2023年4月Meta和智源分别发布通用图像分割模型Segment Anything Model和SegGPT,两种整体架构采用的是编码器-解码器结构。SegGPT基于ViT架构,将不同分割任务统一到通用的上下文学习框架中进行训练,只需提供示例即可自动推理、完成分割任务。
SAM将提示(prompt)引入到模型中,增加了用户的交互性,在接受数百万张图像和超过10亿个掩码的训练后,可根据交互提示返回有效的分割掩码。SAM大模型在切割任务的不同具体场景中展现出了强大的泛化能力,在零样本和少量样本的基础上就能非常优秀的完成不同的切割任务;SAM模型还具备高精度自动标注能力,降低数据标注成本。SAM 在广泛的图像处理应用中的巨大潜力,例如医疗成像、视频、数据注释、3D重建、机器人、视频文本定位、图像字幕、多模态视觉和开放词汇交互分割等。
本文来自微信公众号:国君产业研究(ID:industryRCofG),作者:肖群稀、鲍雁辛