
本文来自微信公众号:孤独大脑 (ID:lonelybrain),作者:老喻,题图来自:《黑客帝国:矩阵重启》
一
和人最大的不同之处是,AI永远不会说不。
这不只是说,当你给ChatGPT派任务时,它永远会给你一个答案,哪怕是一本正经地胡说八道。
还因为,AI模型的工作方法很大程度上是基于概率:“它们估计所有选项的概率,即使所有选项的正确概率都极低,它们仍然只会选择概率最高的路径。”
有人会说,这不是人之常情吗?
面对两个苹果,傻子也会选大的呀。 然而,两个苹果是确定性的,是眼见为实的。 一旦变成概率,大多数人就不会了。
“什么是概率?一件事情发生了就是百分之百,没发生就是零,哪里有什么30%啊,60%啊,根本不存在。”
更别说,还是两个正确率都很低的概率。这时,即使是概率信徒,也会失去了选择的力气。
比方说,一个相信概率的人,可能会在70%和80%之间选后者。
但如果一个数值是3%,一个数值是5%,还有啥可选的?
如果希望仅为3%或5%,那就相当于毫无希望,根本没有选的心情了。
我想将其称为“决策厌恶症”:绝大多数人处在仅有“小概率可能”的环境里,就会放弃思考,失去向前选择的动力,只想躺平。
想想看,当你遇见事情一团糟,或者做事条件不充分,未来毫无头绪,哪里还有心情在一堆坏事里面,去找那件相对不那么坏的事情?
与人不一样,AI永远会行动,即使所有选项的正确概率都极低。
AI永远会给你答案,哪怕一切模糊不清,“仍然只会选择概率最高的路径”。
而一旦以上动作可以迭代循环往复,就会产生惊人的智能。
只有特别厉害的人才会如AI一样:哪怕选项再糟糕,也会冷静地选择概率相对较大的那一项,然后全力以赴做好。
二
棋手卡帕布兰卡说:“我只向前看一步,但总是正确的一步。”
这看起来有点儿奇怪,作为一名棋手,难道不应该向前计算很多步,高瞻远瞩,运筹帷幄,为什么只向前看一步呢?”
的确,所有伟大的棋手,以及决策高手,都会比对手计算得更深远,并且以终局胜利作为评价当下一手的价值标准。
然而,即使如此,你也只用为接下来要走的那一步操心。
以围棋AI为例,它会计算几个主要落子点的终局胜率,然后从中选择胜率最高的那一手。
这是一个典型的马尔可夫决策过程。
马尔可夫性质(或称马尔可夫性)是指一个随机过程的未来状态只依赖于当前状态,而与过去的历史状态无关。简单来说,这就是“无记忆性”。
在马尔可夫链的每一步,系统根据概率分布,可以从一个状态变到另一个状态,也可以保持当前状态。状态的改变叫做转移,与不同的状态改变相关的概率叫做转移概率。
下棋具有马尔可夫性质。在这些游戏中,下一步的决策只需要考虑当前的棋局状态,而无需考虑达到这个状态之前的所有步骤。
换句话说,棋盘的当前状态(即每个棋子的位置)包含了决定游戏未来走向的所有必要信息。
所以,可以说下棋游戏符合马尔可夫性质,因为你不需要知道游戏是如何进行到当前这一步的。
只要知道当前棋盘上各个棋子的位置,就足以决定你的下一步棋应该怎么走。
1. 面对未来,以终局为目标,但只操心下一步;
2. 回望过去,压缩可用价值,忘掉得失和情绪。
这才是活在当下的真义。
三
大神Stephen Wolfram谈及,ChatGPT尝试写一篇文章时,基本上只是在猜:下一个单词应该是什么?
我们假设已有文本为“人工智能最擅长的一点是......”然后想象一下扫描数十亿个人类编写的文本(例如网络内容和数字化书籍),找到所有这些文本的实例,看看下一个单词出现的频率是多少。这里概率最高的下一个英文单词是学习(learn)。
如何计算这些概率呢?Wolfram介绍说:
大的想法就是制作一个模型,好的模型是与人类看法相一致的函数结果,这里就涉及到了神经网络,它可以被认为是对大脑是如何工作的简单理想化表达。
ChatGPT的神经网络基于有数十亿个权重的数学函数,根据它所看到的训练内容,查看数十亿页的文本,“合理地”去猜下一个单词。
所以,AI的“只看下一步”,不止是胸怀全局,还是一个强化学习的过程。
在强化学习中,代理(agent)通过与环境交互,进行一系列的动作,从而尝试最大化累积奖励。
每个动作都会导致环境状态的改变,每种状态都有一个与之相关的奖励。代理的目标是学习一种策略,该策略能够根据当前的状态确定应采取的最佳动作。
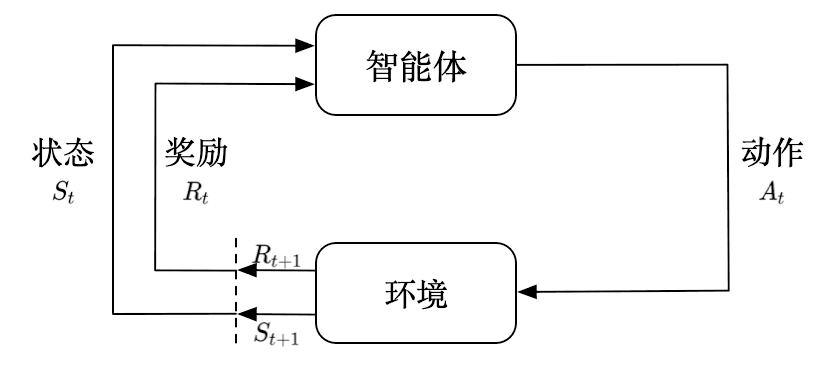
机器学习的训练,令AI的预测越来越准。在与环境的交互过程中,智能体持续自我改进,不断进化,进而实现了整体的更大回报。
从这个角度,更能理解胡先生说的,科学家明知真理无穷、知识无穷,但他们仍然有他们的满足:进一寸有一寸的愉快,进一尺有一尺的满足。
四
选择最接近的,而非追逐完美。
如笛卡尔所说:当追随真理超出了我们的能力时,我们应该追随最可能是真理的东西。
笛卡尔的这句话,和AI的逻辑有些像。
我们总是生存在混乱、不完备的状况之中,如果我们总是纠结于要想明白,要条件充分,要明明白白,要大概率,那就寸步难行。
在已知条件下,找到对你的全局利益相对而言比较优的一手。
马斯克提过类似的工作方法,他说,你应该设好大目标,别太担心现在和目标之间的山高水长和种种残缺,每次想好朝着目标的最优下一步即可。
大处坚定,小处灵活。 辛顿也是这一类人,不然神经网络这种当初被骂惨的路线很难坚持下来。 这和偏执之间的差别是什么呢?也许是大处去“赌”,具体执行则极端理性,极其柔韧,极致务实。
哪怕那一手的获胜概率极低,也理性选择,认真走好。
一手棋的胜率是6%,一手棋是3%,虽然都一塌糊涂,但还是冷静地选6%那一手。 而不是说,反正都很烂,选哪个不是一回事?然后破罐子破摔。 其实,这个时候才是真正考验高手的时刻。
反过来说,不管一个人的处境多么困难,永远会有相对较好的下一步。
这就是本文鸡汤标题的并不鸡汤之处。
这时候,与其哀怨,不如坚定地走出概率最优的一步。
五
我们不仅要有“永远都有最好的下一步”的乐观,还需要评估当下可选项的理性,并选择相对优的下一步。
AI不仅教会我们机器似的理性决策,还通过模仿人类大脑的方式,反过来提示我们,智能体如何通过强化学习越变越聪明。
想想看,那正是我们小时候的样子:大胆试错,跌跌撞撞。
童年,是我们学习速度最惊人的岁月。
那当然也是我们最快乐的岁月。
童年的我们,有一种“相信可能性”的勇敢。就像《爱丽丝梦游仙境》里的女孩,她有时候在早餐前会相信六件不可能的事情。
对可能性的信仰和智慧,正是本文想要表达的某种生命中最重要的品质:基于小概率的100%的勇敢。
这绝不是孤注一掷,一切依然需要基于整体的正期望值。
当所有选项的正确概率都极低,仍然只选择概率最高的路径。
本文来自微信公众号:孤独大脑 (ID:lonelybrain),作者:老喻