
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:周健工,原文标题:《生成式人工智能,如何再一次“重塑”媒体》,题图来自:视觉中国
霍夫曼(Reid Hoffman)是OpenAI的早期投资人,GPT-4在指令调优和人工对齐阶段,他花了大量的时间测试其理解能力,涉及到社会与人文的方方面面。
他把测试的结果和心得,写成了一本书《重塑一切的GPT-4时代》。不过这本书的英文原名是:Impromptu: Amplifying Our Humanity Through AI。其impromptu 含有prompt,说明这本书是他与GPT-4 围绕着人文展开的即兴对话,从一定意义上说,也是让GPT-4在价值观上向人类对齐的一个过程。
霍夫曼创办的领英LinkedIn,是一个媒体属性很强的职业社交应用。他自称是一位技术人文主义者,对于用人工智能解决社会问题,以及人工智能本身可能对人文价值的影响 ,也非常在意。
我最感兴趣的,是他谈媒体的那一章。媒体在过去二十多年互联网大潮中,被一波又一波地冲击,可以说已经被“重塑”好几回了。这一回将如何“重塑”?
这里所说的媒体,是指面向大众传播的新闻媒体;以发现和报道真相为使命的媒体;用一套专业的技能和标准,让内容保持真实、客观、公正的媒体;由职业的新闻记者、编辑、研究和设计人员生产的、具有社会影响力内容的媒体。不管人们站在什么政治立场,不管认同什么新闻观,对这些都秉持相同的看法。
对于霍夫曼来说,最令人担心的,是GPT-4会带来了一个“反乌托邦”的世界,谎言和虚假新闻无处不在,淹没了真相。
“试想现在是2032年,距离美国总统大选仅有几个月。由于AI技术的突破,假新闻泛滥成灾,一派乌托邦末世景象:虚构的名人为候选人背书、 候选人做出的虚假认罪供述、实时辩论被篡改等。甚至在政治集会舞台上,有戴着MAGA帽子的耶稣全息影像出现。”
这听起来并不遥远,就会在2024年。
对新闻业影响最大的,并不是AI会自动生成新闻、赛事信息、天气预报。也不是所谓的“定制化”的新闻:社交平台会收集每一位用户的信息,向其推送可能感兴趣的内容,形成了所谓的“信息茧房”;而用户在一定程度上让出了隐私,其个人信息最终要么掌握在平台手中,要么掌握在更具权势的“big brother”手中。
另外一个问题,是用户被产品化——“如果你在使用免费的产品,那么你就会变成产品。”平台企业通过用户大数据,精准地向其推送广告和各种产品,或者以内容的方式带货。
ChatGPT与用户是一种对话的关系,霍夫曼认为,“只是实时地为你的查询和提示提供高度响应的信息。这既是关于这些大语言模型运作方式的一个明显的发现,也是一个尚未被充分认识的发现。”
这对新闻媒体有特殊的重要性。
对于记者、编辑和研究人员来说,他们依然是媒体的核心,提供专业的内容,对真实与准确负责。但用户与媒体的交互方式,以及消费新闻内容的方式,已经变得完全不同。
霍夫曼提出了“一个问题引出十个问题”的内容生成方式。当用户愿意从发问开始消费新闻,这对媒体来说,未必是一件坏事,因为它将牵出一长串的问答内容。它将成为用户与媒体之间建立信任关系的新的机会。那些有年份的新闻媒体,其内容积淀的优势将会发挥出来,用户能刨根问底,从而有助于掌握和接近事件的真相。
这就改变了人与新闻的关系,以前是提供新闻的人们,也掌握了提供“真相”的权力,但是,用户可能用AI,更加便捷地掌握事件的多个信息来源,多个分析角度,以及事件演变的来龙去脉、历史沿革。每个人,终将为自己所获取的真相负责。同一事件的多个消息来源,背景知识,有可能通过一个智能代理来完成。
记者是职业提问者,理应是最好的prompt engineer(提示工程师);而每位新闻的消费者,每位AI媒体技术的用户,也只有自己成为prompt engineer,才能获取真相。
在所有关于生成式人工智能对于新闻媒体行业影响的排序中,排在第一个是大规模虚假新闻的产生,第二个是专业的新闻记者被替代。但这两者是互相矛盾的,如果虚假新闻成为一个严重的社会问题,甚至威胁到制度与文明,那么就需要有人来提供真相的专业服务,这些人就是新闻工作者、调查记者、研究能力强大的媒体工作人员。人们对于真相的需要是永恒的,而并不一定是需要某些形式的“内容”。
那么,不正是ChatGPT在许多情况下无法区分真实与虚构吗?它为了生成一个故事,或者通过概率预测构建与人类对齐的内容,不也是会夹杂大量的编造、错误和虚假的内容吗?
一方面,产生“幻觉”已经成为大模型当前最重要的技术挑战,消除这些“幻觉”也成为生成式人工智能技术迫切需要的进步。另一方面,最重要的是向舆论场填充大量真实的新闻。霍夫曼认为,“本质上,我们需要确保寻求真相的任何人,都能很容易地获取准确、透明和真实的信息。”
这样就需要一个可溯源的“维基百科”,每一个事实,每一个观点,都可以找到源头,找到参考,在互联网上可以链接起来,实时动态地可以互相参考、互相核实,形成一个“真相的基础设施”,而在AI时代,可能需要一个AI版的事实维基百科。
正是世界各地专业的新闻机构,过去一两百年来专业地报道和记载着重要事件,才有助于构建了人类的集体记忆;人类也是通过一整套可溯源、可引证和可参考的研究形成了知识链接与图谱,也为后来的人们理解事件的真相和意义,提供了导航。
人们试图用web3.0来提供个人拥有、不可篡改的个人信息,但更为底层的是公众信息和舆论场的真相。AI最大的功能之一,是提供强大的探寻真相的工具,透明的新闻生产过程,以及便捷溯源与核实真相的基础设施。
霍夫曼相信,专业媒体工作者使用这些更高效的工具,就能用真实的新闻占领舆论场。
这同样需要依靠专业的媒体机构多年来形成的专业技能和规范,并且体现在AI产品中。例如 ,霍夫曼提出,在每条新闻后面,设立一个Fact Check(事实核查)的按钮。这样,消息来源是否真的存在,其背景是什么;数据的来源是否可信,是否还有第三方信源的存在,包括报道新闻的机构及个人的背景信息;图片、视频的来源,是不是经过加工与合成的;甚至包括用于训练模型的数据来源的水印,等等。这个按钮的设立,也降低了ChatGPT自身产生“幻觉新闻”的可能性。
这一切在过去由媒体机构中的记者或者助理来完成,甚至编辑要把关,但今后可以由AI提升效率,成为事实确认的AI助理。当所有的媒体机构都遵循同样的标准,而用户养成了这样的习惯,就会反馈到AI模型中,经过持续的强化,让优质、专业和负责的内容更容易受到识别。
许多新闻媒体具有党派性,具有党派倾向的读者,会对本党的报道采取“宁信其有”的立场,而对对立党派发布的新闻采取“宁信其无”的立场。这些党派属性及倾向性,同样可以“一键解决”,标注其党派属性,就像人们购买食品,看到其中不同营养成分的标识说明一样。
说到这里,最近有一项研究,分析受众平时习惯阅读的媒体内容的“营养成分”,发现用这些媒体内容训练出来的模型,可以预测出受众在民意调查中会对某些重要社会事件采取的态度、选择的回答。这一研究引发了忧虑,这会对那些操纵媒体、进而影响人们投票行为提供了一种理论依据。人们开始担心2024年大选中,AI将会起到什么破坏性的作用。
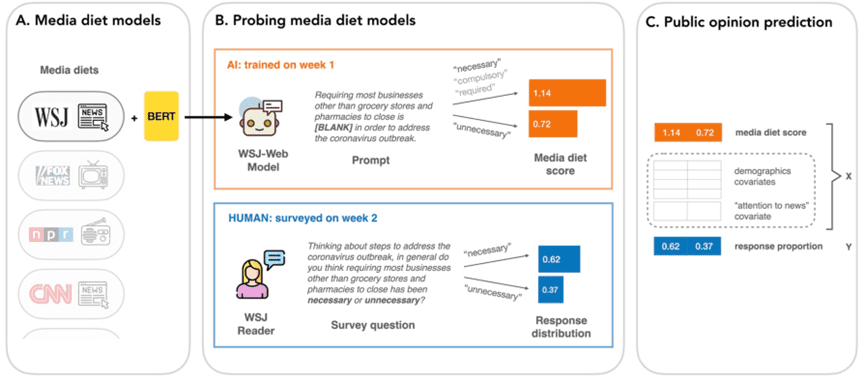
(媒体食谱的建模方法)
图灵奖获得者杨立昆(Yann LeCun)想出了一个办法:“想象一下未来,您与信息世界的日常互动将由 AI助手进行调解。这个 AI 助手就像是所有人类知识的活跃存储库。它将成为您“对抗”错误信息的最佳堡垒。”
的确,我们面对着大量的随机噪音,然后用自己的判别与之对抗,生成出“逼真”的内容。每个人的大脑,可能原本就是一个生成对抗神经网络。
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:周健工