
本文来自微信公众号:XYY的读书笔记(ID:xiaoyanyan00002),作者:肖俨衍,题图:由Midjourney生成
AGI(Artificial general intelligence,通用人工智能)时代的曙光带来的不仅是新技术的兴奋,还有潜在人类危机。“如果AGI比人类还智能,未来还有断电的方法”。听起来好像很有道理,如果AGI比人类智能,其一定知道自己的弱点,从而避免人类打击它的弱点。由此,这个方法很可能是不可行的。
本篇,我们聚焦应该如何设计AGI系统从而避免其对人类生存构成基本危机,避免我们成为猿猴第二(孵化了人类,但自己却成了“玩偶”)。反言之,忽略了这个问题的AGI路线,要不被人类叫停,要不就会成为巨大风险。
《Human Compatible》这本书的作者Stuart Russell是UC Berkeley大学的计算机系教授,也是著名人工智能教材《Artificial Intelligence: A modern approach 》的作者,这本书写作于2019年,GPT还没出来,但其从智能的定义谈起,谈到作者对于AGI风险的辩论,并且提出了一套可行的设计框架,值得一看。
引子:AGI时代的隐忧
设想五个场景,你认为哪个会是人类历史上最大的事情?
1. 由于其他行星撞击等事件,人类灭亡;
2. 人类获得永生;
3. 我们发明了超越光速的飞行器,征服了宇宙;
4. 外星人来临;
5. 我们发明了超级人工智能AGI。
作者看来,第五个应该是对人类文明最大影响因素,其可能带来非线性阶跃,其包含了1-4事件能够给人类带来所有可能性——永生、毁灭、征服等,甚至可能是人类历史上最后一个事件。AGI时代是否很快就会到来?这一点几乎很难预测,就像人类发明原子弹的历史,1933年诺贝尔化学奖得主卢瑟福(Rutherford)说:“任何从原子转换中获取能量的想法都是天方夜谭”。然而,6年后,1939年,第一个原子弹类型武器专利在法国发布。
智能的定义。“越智能越好”是AI时代发展的基本纲要,然而智能的定义到底是什么?人类智能的核心是我们能够基于我们的目标采取相应的行动。类似的,对于机器智能,我们也可以采取类似的目标和行动关联关系的定义。
然而,机器的目标和人类的目标如何对齐,却成为AGI发展过程中最核心的问题和风险来源,如果机器的行为基于实现机器的目标,而这个目标与人类的目标相违背,那就可能是灾难。当然,你可以简单将这个目标替换为人类的目标,也即机器的目标是实现人类的目标,然而,人类自己是否真正知道自己的目标?我是谁,我来自哪里,我要去何方,几乎是人类哲学要解决的终极问题。由于人类的复杂性,目标对齐本身也充满复杂性。
一、简述人类的智能和机器的智能
人类智能进化历史
正如前文所言,一个智能主体核心定义是,基于其感知能力,其能够基于目标做出对应行动。从这个角度,一个细菌能够感知外界环境,做出相应反应,其是智能的。
下一步是神经系统诞生,神经能够通过突触快速传播电信号,且通过不断学习调整参数,神经系统可以培养行动习惯集合,此后大脑诞生。实际上,对大脑底层机制的研究就是人工智能的底层机制,而我们科学研究的进展目前也仅限于大脑神经结构的理解,而对学习、认知、记忆、推理、计划等一系列行为机制理解很有限——基本靠猜。
大脑反馈系统也广为人知,大脑倾向于对一些增加多巴胺释放的行为进行重复(比如吃甜食,比如别人的夸奖),反之则避免一些让你感到痛苦的动作。这种反馈系统和AI训练中的强化学习(Reinforcement Lerarning)机制类似。生物进化也和智能相关,DNA不断迭代和交叉构成物种进化的核心机制(优胜劣汰)。而文明传承等行为则加速了人类学习的过程(地球历史上曾经存在过1170亿人类,学习的时间就更多了)。
理性决策机制
简单来讲,理性决策是权衡成功的确定性以及获取的成本。比如,机会A是有20%概率获得10美元;机会B是有5%概率获得100美元。前者预期回报是2美元,后者是5美元,所以后者是更优选择。然而,这个逻辑并不能完全线性外推,比如机会A是100%获得100万美元;机会B是1%概率获得10亿美元。大多数人可能会选择机会A,因为从效用(Utility)角度来看,效应和钱并不是线性关系,对大多数人100万美元效应和10亿美元不是1000倍的关系。
因此,理性决策机制又可以是最大化效用函数。效用理论有很多反对的声音,比如有人觉得其将人类决策动机简化为自私和钱;也有人觉得这个效应无法量化,令其很难计算——理性行为并不完全涉及到计算,比如遇到水,你会闭眼睛保护眼睛,其背后并没有计算,但却是理性行为;比如,理性决策的载体是什么,是人类自身,还是家庭、部落等;最后,有很多数据证明,人类的决策其实是非理性的。然而,虽然理性人的假设有很多问题,我们在构建AI系统时候却可以假设人类的偏好是具有一致性的,而对那些不一致的倾向和偏好,AI或许能够容忍,但是却很难被AI满足(善变的部分)。
复杂的是社会
如果这个社会只有1个人和1台机器,问题可能容易得多。但问题是,地球上有80亿人类,有数百个国家和更多民族和不同文化。人类理性的决策将变得更加复杂,类似博弈论(Game Theory,纳什均衡)等的核心就是在多人情况下,人类的理性决策会变得不同。
假设A和B在进行踢点球的游戏,A是右脚运动员,其踢向右边的成功率和概率要更高一点。B则需要提前对A踢球的方向进行判断才有可能扑出。这里面就会涉及到N层博弈可能性,第一层:“因为A射向右边概率更高,所以我扑向右边。”;第二层:“A也知道我知道其更高概率会选择右边,所以他会选择左边”……无限循环。简单来讲,如果A有理性决策能力,B肯定也知道,因此这个游戏根本就不存在理性决策(股市博弈基本如此)。
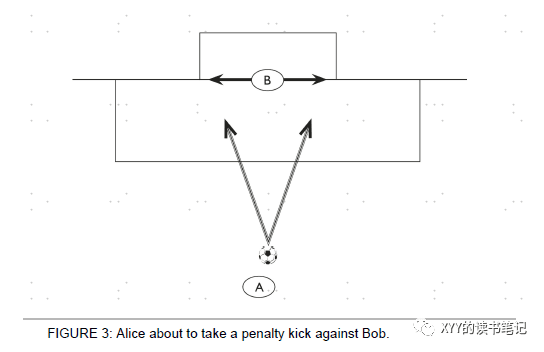
机器的智能,以及绝对理性无法实现
要实现AGI,第一步是定义机器智能,第二步是实现它。计算机是人类第一个智能机器,虽然我们已经习以为常。1936年图灵提出了通用机器的概念——也就是机器不用分计算、翻译等职能。最早的计算机每秒运算是千次,到2019年超算计算机每秒计算达到10的18次方,这个速度和大脑计算能力差不多(大脑主要是并行计算),但是后者功耗只有前者百万分之一。
从计算能力角度,量子计算可能是未来提高算力潜在方向。一位MIT教授测算了笔记本尺寸电脑的物理计算极限——每秒10^51次计算。一方面是计算能力有上限,另一方面的世界的复杂性,也即一类指数级别计算问题无法用穷举法粗暴解题。简单比如用三种颜色填充地图,且接壤国家不同颜色问题,如果国家主体有100万个,则需要2^1000次计算,如果用2019最先进超算需要10^275年来计算,而宇宙历史目前也只有10^10年。
由于世界的复杂性,我们应该预期不管是人类还是AGI,未来大概率都无法对每个问题找到全局最优解,更多只是找到局部最优解,无法做到绝对理性。
颠覆图灵测试——人工智能发展路径历史
识别机器智能著名的测试是图灵测试——如果一个机器能够欺骗人类,说明其已经具备了超人的智能。然而图灵测试一方面很难操作,另一方面如果机器发展的是另外一个智能体系(跟人类不同)怎么办呢?因此图灵测试其实一直不是学界评价机器智能程度的核心方法。
最早的AI方法是基于逻辑规则——即将机器基于信号、既定目的的行为写出对应的逻辑规则。到1980年代,简单基于逻辑规则的AI路线证明是不够的——世界规则是无限的,基于概率论(贝叶斯)的路线开始兴起,开启了Modern AI时代——培养一个针对特定目标的Agent,能够根据输入信号做出对应决策。针对Agent培养,环境——目标场景是否是连续,是否可观察;目标是否可操作;行动是否可预测等等一系列因素,都可以定义AI场景本身的难度。
比如,训练AI打游戏就难度很高,在任何时点,AI可能有10^50次方个选择(围棋只有100个),强化学习等方法运用已经使得AI征服各种高难度游戏(比最顶级人类玩家更厉害)。随着AI征服越来越难的场景,其也积累越来越多能够实现AGI的技术和可能性,2023年GPT的横空出世就是典型(作者写书的时候还没出现)。关于AI具体发展历史参见《【读书】深度学习发展史:相信和看见》。
二、AGI何时来,会带来什么影响?
AGI的路径
AGI何时来是大家最关心的一个问题,然而几乎也无法回答的问题。一方面,预测很容易错误,例如前文说的原子弹。1960年AI萌芽的时候,学术界主流观点是AGI在20年内就能实现。其次,AGI是否到来本身没有明确界限和标志,实际上,现在计算机已经在很多维度超越了人类。如果硬要预测,时间可能是5-500年(OpenAI的Altman说是10年内,且看吧)。
从AGI路线来看,作者认为缺乏知识的模型一定不智能,而要学习知识最重要是掌握语言,因此如果一台机器能够理解人类语言,其就能够快速积累知识(GPT恰好就是这个路线,神预测)。然而,作者认为这种路线可能面临鸡和蛋的问题——因为你总的有点理解才能开始积累知识,现在来看GPT几乎把语言和知识两个问题合并了,本质上是一个问题——这个很哲学,可能物体本来就是自己的原因,鸡和蛋的问题本不存在。
有了知识之后,还要有常识,正像怀特海说的:“人类文明的进步本质是我们潜意识动作模块化的积累(不需要思考)。”人类能够根据事物优先级来制定目标和行动计划,而很多具体行动本身不需要思考。作者认为,这一步对于实现AGI很重要,目前来看从GPT-4的图片识别来看,其似乎已经具备了一些常识(其知道剪断挂着铁球的线,它会落到地上)。但是,博主认为GPT拥有多模态,甚至增加感知世界能力后,这个常识模型可能会更加精进。
AGI实现了会怎样?
首先,AGI能够干人类能做的任何事情,数学、编程、研究等。这些工作价值几何?美国有个调查说,美国人认为如果要让他们放弃搜索引擎,需要支付给他们1.75万美元/年,从这个角度AGI版本搜索引擎价值就是几万亿美元。此外,人和人的大脑并不能联通,然而机器人AGI却可以,这一张认知网络的联合,一定会产生更加庞大的能力。从学习速度来看,人类可以一周看一本书,然而机器可以在几小时内看完人类有史以来写的1.5亿本书,这种学习能力无需赘言,而这种超强的学习和思考能力,大概率就能发现我们人类尚未发现的规律——比如治疗癌症的方法。
AGI会有哪些局限性?
一种普遍的错误认知是认为AGI会成为“上帝”一样的存在,即不仅对当下有完美的理解,还包括对于未来。然而,正如前文所说世界中有大量指数级别的复杂问题,AGI也受到物理计算能力的限制,其肯定能比人类找到更优解,但却不是无限能力。
此外,AGI的研究发现很多情况也受到其他因素限制,比如研发一些药,其需要临床测试(需要时间)。当然也可以通过仿真,但是仿真就需要了解清楚每一个生物细节(科学难度很高)。AGI最后的局限性来自于其本身不是人类,他们在预测和理解人类行为时候很可能会碰到困难(比如人类复杂的、非理性方面)。我们人类在理解他人想法的时候,最大的优势就是我们也是人类,我们可以将心比心,但AGI可能不是。
AGI对就业影响如何?
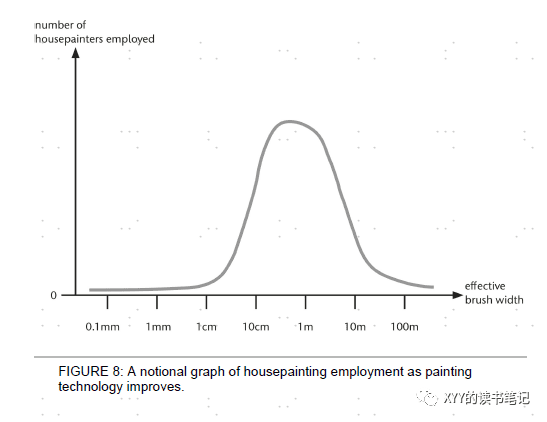
除了终极的颠覆人类文明外,常见的负面影响包括更没有隐私,包括致命武器威胁,包括虚假内容误导人类等。更重要可能对职业的影响,早在亚里士多德的时候,其就指出只要雇主发现一种通过机械实现目标的方法,人们的就业就会受到影响。乐观派的观点则认为技术的进步往往会带来新的就业,比如工业革命。作者给出一个上下半场的解释,即在技术发展的上半场,其让很多场景和功能变得可能,其可以增加就业。但是下半场则效率提升到一定幅度后,其肯定对就业有负向影响。用刷墙的毛刷的宽度可以做类比,当毛刷宽度只有头发丝宽度时候,用其刷墙是不可能的任务,因此就业是0。随着毛刷宽度不断增加,到10cm时候,就业规模达到一个高点。此后机械毛刷宽度越来越大,其对就业产生了负向影响(机械刷墙代替)。
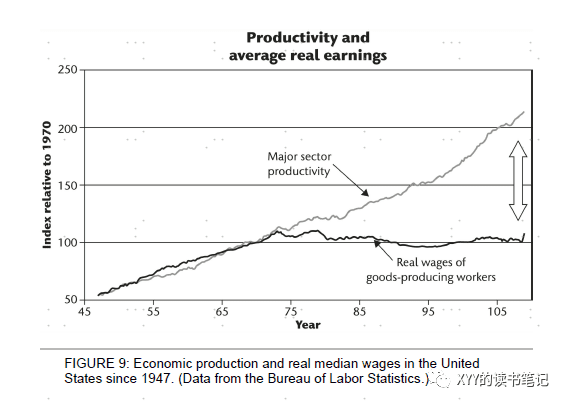
当然,需要指出的是,当人们雇佣刷墙工人的花费因为机器人介入减少后,这部分花费可能会花在其他领域,这样会增加其他领域的就业。另外,技术进步整体增加了生产力,从而能够让我们基于同样的工作享受更多物品和服务。还有一点,技术进步往往利好资本,也就是投资技术形成资产的阶层,下面第二张图显示1960年代以来技术确实带来生产效率提升,但是1973年后平均工资却基本没变。AGI时代,哪些职业可能比较危险,简单来说,类似人机互动的职业(比如司机)可能都会被替代,包括白领岗位(操作计算机),外包的职业也是(因为所有外包部分几乎都是可以模块化,自动化的)。
最终来说,可能还有价值部分可能就是我们是人类,对人类能够提供一些人性化的服务。对于人类来说,虽然技术可以提供一切服务,但我们对某些场景,我们还是希望有人类给我们服务,比如教育,虽然AI可以提供很强的个性化教育能力,但是我们可能还是希望有个老师来教我们。对社会而言,UBI(统一最低工资)可能是一种解决方案,可以让绝大多数人共同享受技术进步红利(而不是少数人)。如果你需要更高工资,可以去通过给人提供服务来增加收入。
三、机器人会威胁到人类文明吗?
猿猴怎么看待人类的出现?
人类对于周围环境的掌控本质来源是人类的智能,由此不难发现“发明一个比人类还聪明的物种”是一种风险很大的行为。1000万年前,人类从猿猴进化而来,逐步进化到现代社会,猿猴会怎么看待这种行为?如果猿猴能表述自己的想法,这种想法可能会和人面对AGI风险比较类似。
另一种风险是人类过于自信的风险,即使人类能够给机器灌输自己的目标,但机器如果足够智能,其很可能意识到实现这个目标最好的方式是改变人类的目标。这个问题其实比较微妙,皇帝和太监到底是什么关系?真的是皇帝掌控太监么,历史上有多少太监掌握了皇帝弱点的时候,能够操纵朝政的?(比如天启皇帝喜欢做木匠,魏忠贤就专门挑后者做木工活的时候汇报重要事情,后者就会顾不上,说你们看着办吧)。现实中情况类似内容推荐算法,很可能是通过改变用户内容消费偏好,从而达到最大化点击量等目标。
另一个难点是,我们几乎无法通过简单地禁止研发AGI来阻止这种风险,其一我们无法停止对于AI的研究(等于限制人们思想),其二是禁止起来也很难,通往AGI的路径是未知的,我们无法知道我们应该禁止哪条路线,工具AI的发展很可能是通往AGI的路径,如果禁止AGI就意味着完全禁止工具AI,那人类目前的科技水平要大撤退。
对于AGI的风险,我们也可以听听反方的观点:
完全否定AGI的风险:计算机在计算方面比人类强,马在运动能力比人强,他们都没有威胁人类。历史上,也从来没出现机器威胁人类的情况。也有人认为AGI完全不可能,或者现在担忧还太早(杨立昆就认为当下GPT还远远称不上智能,因为其缺乏人类常识模型)。Andrew Ng也说现在担忧AGI的风险就像担忧火星上人太多。还有一种说法是我们是专家(比如IBM的人),我们更懂AGI的威胁。
反驳:历史不代表未来,某个方面智能和AGI也不同。面对AGI的风险,我们早做准备远远好过临时抱佛脚。
即使知道风险,我们也束手无策。比如我们很难控制AI科研,也有人觉得过于谈论风险等于忽略AI的好处,也有人认为我们应该对风险保持沉默,他们认为人类文明能够自然而然处理好这些风险问题。
反驳:实际上,人类对DNA编辑技术的应对(法律禁止),对核武器的应对(无核)都是历史上对颠覆人类文明历史的风险应对经验。
我们不能直接关闭它们吗?比如建设某些最后措施,能够在AGI风险前一刻关闭系统。比如我们可以给AI建立一个笼子,比如建设一个Oracle AI,只回答是和不是(限制功能)。还有人觉得我们人类应该和AI合并,通过脑机接口,人类的意识可以输入AGI,从而实现人机合一(马斯克搞脑机接口研究可能就是如此吧)。
反驳:这些想法的局限性都是,如果AGI足够智能,能够产生自我意识,其就能够冲破牢笼,防止别人断电。还有一种提议说每次给机器人下命令都包含一个后缀,比如“帮我冲咖啡同时允许自己不被关闭”,这种方法可能是机器人可能可以保持开关的畅通,但是让人无法靠近这个开关。
四、一种潜在解决方案
在作者看来,要打造一个始终有利于人类的AGI系统,需要遵守三个原则:
AGI机器的唯一目标是最大化实现人类的偏好。第一条,让机器无我是最根本的设置,我们要打造一个类似佛教所说的无我,普渡众生一样的“佛”。也有很多问题,比如人类真的有明确的、稳定一致的偏好么?比如这么多人,究竟遵从谁的偏好?比如,世界上还有那么多生物、动物呢?
机器最开始对于人类的偏好是不确定的。第二条核心是不能有确定的目标,否则机器可能变成一根筋,最终会导致人类无法对AGI断电。这点也好理解,对于人也一样,一根筋的人几乎无法劝解,但是对未来保持不确定性的人更容易接受别人的看法。
机器学习人类偏好的唯一来源是人类的行为。人的行为是反映人类偏好的唯一证据。可能有人会想到将人类价值观植入机器,但是这个不好操作,一方面价值观无法量化,另一方面价值观千人千面。另一方面是AGI对人类文明的毁灭风险和道德选择完全不是一个level的问题。这里面问题是,人的邪恶行为机器应该怎么反应?
以上三点其实对做人也很有启示,比如我们做人不能一根筋,要抱有开放性。比如我们应该更加看重从现实中寻找知识,实事求是,不脱离现实。在作者看来,基于这三条设计AGI系统首先是其足够的开放性,通用性能够使得研发者有足够动力研发这类系统;其次,我们有充足的数据可以让AGI系统学习人类的偏好。可以用数学定理格式来描述:基于A\B\C机器,以及对应算法和反馈,对于任何类似计算能力和物理能力的机器,这些机器有很高概率能够提供非常接近人类偏好的、事实上可能的行为。首先,机器无法确保最优解,正如前文所言由于物理世界的复杂性,由此,其提供的是可能性上的最优解。
这里面还有两个假设,一个是世界的运行规律是一致的,不然就没法学习;其次是人类对机器的反应是在意的,不然有益的(beneficial)这个定义就没意义。从偏好角度,需要保证机器学习的是人的底层意图,而不是机械地模仿人类动作,即使其最开始不知道,但是其底层目标是实现人类的偏好。机器人“无我”还体现在机器人会学习人类每天早晨起来需要咖啡的习惯,而不是学习到“机器自己也需要咖啡”。
从人类选择中学习偏好——不确定理念很重要
假设机器人Robbie是Harriet的个人助手,其有一个具体任务就是帮助Harriet订酒店,Robbie并不清楚Harriet的偏好——便宜的还是昂贵的酒店,其选择的目标效用可能是-40到60,其直接行动平均预期效用是10,其还有一个选择是关闭自己(效用是0),第三个选择是等着Harriet给提示——有40%概率,Harriet会关闭Robbie,有60%概率会让Robbie直接行动。
由此,机器人等Harriet提示再行动,其预期效用是18。这个案例有几个启示——Robbie对自己的选择永远不是100%确定很重要,这样其就永远有被关闭的选项。其次,事实情况下,Robbie等待Harriet提示本质上是对后者一次“骚扰”,对后者增加了一些成本,这个成本越高,机器人越有可能直接行动。
一个潜在问题可能是,机器人Robbie越来越懂Harriet选择后,其不确定的比例会越来越低,但重要的是其始终不能100%确定。最后,这种不确定性可能会传递,也就是即使机器人Robbie开发的机器,可能也会承袭这种对于人意图不确定性的认知。
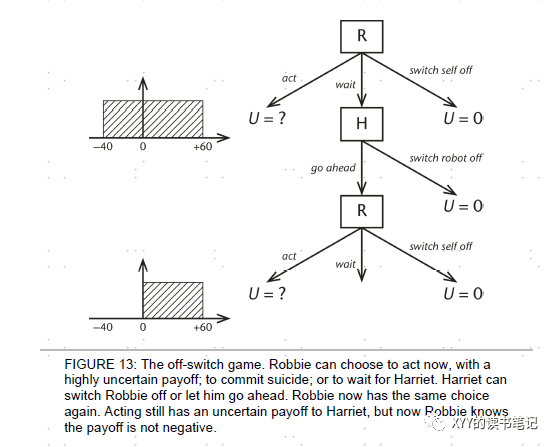
AGI需要领会人类意图
核心是人类和AGI的对话不能简单理解为确定的命令:比如Harriet在沙漠加油站中,对机器人Robbie说想喝咖啡,但是最近卖咖啡的地方有300km,Robbie的选择应该是不顾一切去买咖啡吗?实际上,Robbie应该将Harriet的话理解为后者的偏好的一种提示——他倾向于咖啡类饮料,如果Robbie发现最近咖啡店有300km,其最佳选择应该是告诉Harriet这个事实。
另一种需要避免的情况是Wireheading——多巴胺的快乐会促使动物跳过行为步骤,直接追求后者快乐(比如通过电击),机器人也可能。只要AGI足够智能,其可能会重新编程自己的程序,从而跳过行动步骤,直接获得reward,甚至操控人类强制后者给自己奖励。核心还是要区分“reward信号”和“实际的rewards”,前者的积累并不能简单等同于后者,这样智能系统就不会这么作弊了。
五、机器人的困惑:人类的复杂性
AGI必须考虑所有人的偏好
首先,人类是各种各样的。这点其实好办,因为根据以上定义AGI并不是学习某个人的价值观,而是可以选择不同人的偏好,其可以根据不同人的行为来推断其偏好。此外,考虑到不同偏好人有一定共同规律,机器人可以互相学习和积累认知,这种学习肯定不会从0开始。此外,Robbie应该不仅注重实现Harriet的目标,还应该重视后者的体验——假设Harriet想登珠峰,Robbie的方案不应该是开启飞行引擎把Harriet带上去。比如Robbie要减少Harriet痛苦,其解决方案不应该是让他消失。更复杂的问题是,社会是由海量的人类组成的,机器人应该遵从谁的偏好呢?(人类通过法律和道德准则来约束每个人的行为)如果Harriet提出一个对他人有害的建议,Robbie应该如何反应?一种方式是将Robbie的行为规范用法律来约束,但是AGI可能会去找各种法律的漏洞(但是不道德的)来实现Harriet的偏好。
因此,Robbie必须考虑其他所有人的偏好来决策其相应的行动,这有点像墨子说的“兼爱”,从效用理论来看,也就是机器人的行为应该是最大化社会整体的福祉(效用),或者每个人的平均福祉(效用)。基于福祉效用的理论也有反对声音,比如每个人的效用很难量化,更不用谈加起来或者计算平均了。还有,超级个体的存在可能会造成偏离,比如人类相对于其他动物,在效用计算时候人类就是超级个体。对于这一点,作者的看法是他觉得效用是可以量化的,但是也要防止机器人Robbie过度“兼爱”,从而持续忽略Harriet的需求的问题。
羡慕嫉妒恨
在正常性善的假设下,人会有同理心,看到别人幸福自己也会觉得幸福。假设有俩人Alice和Bob,Robbie某个行为可能同时对Alice和Bob造成影响,Alice整体效用=Alice效用+C(AB)*Bob效用,这个C(AB)就是Alice有多在意Bob,如果C(AB)是正的,说明Alice真的在意Bob,后者高兴他也高兴。复杂的情况是C(AB)为负的情况,也即Alice可能嫉妒Bob,后者的痛苦成为了Alice的高兴,客观来讲,这种情况在现实世界中,并不少见,任何羡慕嫉妒恨都有可能导致该系数为负。一种解决方案是直接将负数系数变成0,也就是忽略这些负能量,但其实际后果还需要分析。此外,很重要一点是机器人不能简单学习人类的行为,而是观察人类的偏好,要能够出淤泥而不染。
人类的“愚蠢”和非理性
这个其实不太用解释,人类通常做出违背他们偏好的决策,或者因为短期利益而牺牲长期利益的选择。此外,人类经常基于感性来做情绪化的决策,因此Robbie必须对情绪化的人类有理解。此外,正如前文所言,人类真的清楚自己的偏好吗?不管是从认知局限性,还是能力局限性(比如计算能力),人类很多时候都不清楚自己的偏好。当然这点对作者提出AGI体系并没有什么影响,因为Robbie可以根据人类行为来推断其偏好,但基于人类非理性的假设,Robbie应该知道这些行为未必能够反映Harriet的真实偏好。
从心理学看,即使是基于效用最大化,人类也往往基于记忆做出错误的决策——因为人类往往只能记得记忆中效用的最大值或者最终值(记住某个瞬间),而不是记住整体效用,或者平均效用。举个例子,曾经有个实验有两个选项,A是人先把手伸进14度的水中60秒,然后伸进15度水30秒;B是直接伸进14度水中60秒。几乎所有人通过记忆会选择A,因为人只记得15度那个舒适最高点。这个也好理解,我们往往直接的那些最有记忆点的瞬间(最大值),由此根据记忆做决策是不靠谱的。
机器人改变人类偏好?
人类的认知偏好其实是随着时间改变的(因此不确定性很重要),如前文所言,机器人为了更容易完成任务,可能会做出改变人类偏好的选择。这里可能就会涉及到定义哪些改变人类偏好的决策是可以接受的——比如Harriet可能想减肥,Robbie可以做出决策改变Harriet吃甜食的偏好。如果Robbie这些改变人类偏好背后动机是让人类更长寿、更健康和生活更好,则认为是可以接受的。这里面问题是,美好生活定义是唯一的吗?我们减少羡慕嫉妒恨的相关系数最终后果可能是什么?
结语:未雨绸缪是必要的
本篇,作者提供一套粗略的约束AGI的框架,但不可否认的是这里面未解决的问题,未知的问题还有很多。比如,机器人Robbie如果开发自己的机器人Robbie II,后者肯定比前者更加智能,Robbie是否会对Robbie II失控?人类通过DNA遗传基因,我们是不是也要AGI来个DNA(确保服从人类偏好、不确定的态度等是被遗传的?)。不管怎样,未雨绸缪,对于人类一定是好的。
本文来自微信公众号:XYY的读书笔记(ID:xiaoyanyan00002),作者:肖俨衍