
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:未尽研究,原文标题:《刚刚,炮轰GPT模式活不过5年之后,杨立昆推出了“世界模型”,I-JPEA》,题图来自:视觉中国
刚刚在北京举办的智源“AI春晚”大会上,杨立昆在开幕演讲中,对以GPT为代表的大模型发起了严厉的批评:单纯根据概率生成自回归的大语言模型,根本解决不了幻觉、错误的问题。在输入文本增大的时候,错误的几率也会成指数增加。他预言GPT模型活不过5年。
这位Meta AI的首席人工智能科学家认为,他的架构将有助于模型学习得更快,计划完成更复杂的任务,并且能够真正学到人类的智能——迅速适应陌生的环境。
杨立昆一直批评现有生成式人工智能学习方式,他又一直忙于开发能学习运作世界模型的新型机器学习架构。
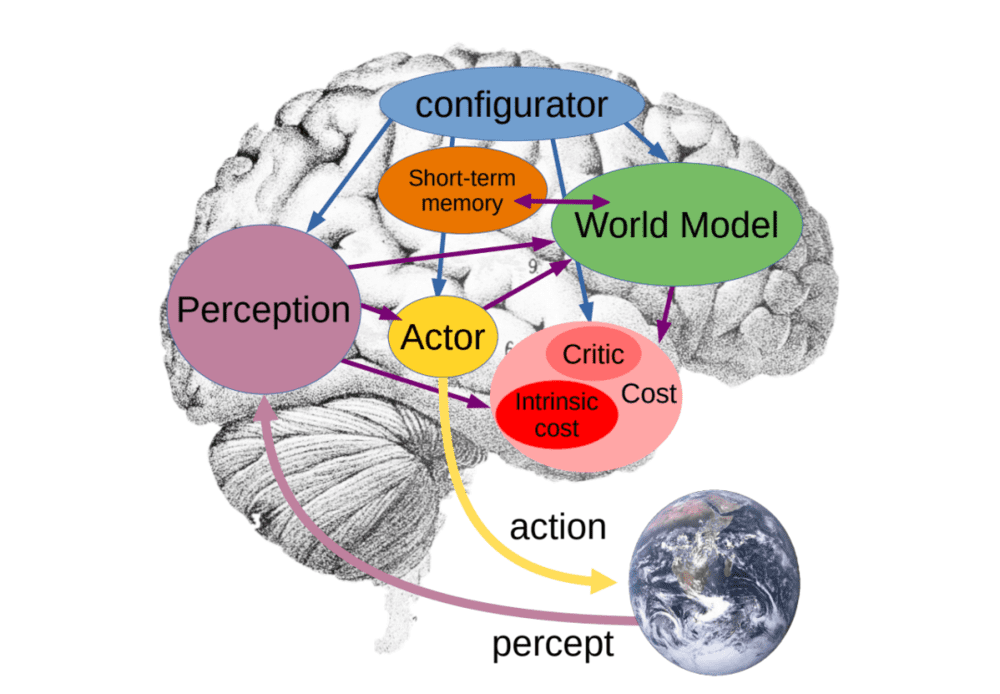
杨立昆提出的世界模型架构,由 6 个独立的模块组成:配置器(Configurator)模块;感知模块(Perception module);世界模型(World model);成本模块(Cost module);actor 模块;短期记忆模块(Short-term memory module)
他指导的Meta AI团队正在推出这样一个模型。可以用类似人类大脑的方式,分析并预测未完成的图像 ,而且比现有的模型都准确。
该模型名为图像联合嵌入预测架构(Image Joint Embedding Predictive Architecture,简称I-JEPA),它能够比较图片的抽象表示,而不是比较像素本身,通过创建外部世界的内部模型来进行学习。这意味着它的学习方式更接近人类学习新概念的方式。
I-JEPA的基本理念是,人类在被动观察世界时学习了大量关于世界的背景信息。大体来说,I-JEPA试图通过捕捉这个世界的常识的背景知识,并将其编码为以后可以访问的数字表示,从而模仿这种学习方式。挑战在于,这样的系统必须以自监督的方式学习这些表示,使用未标记的数据,如图像和声音,而不是标记的数据集。
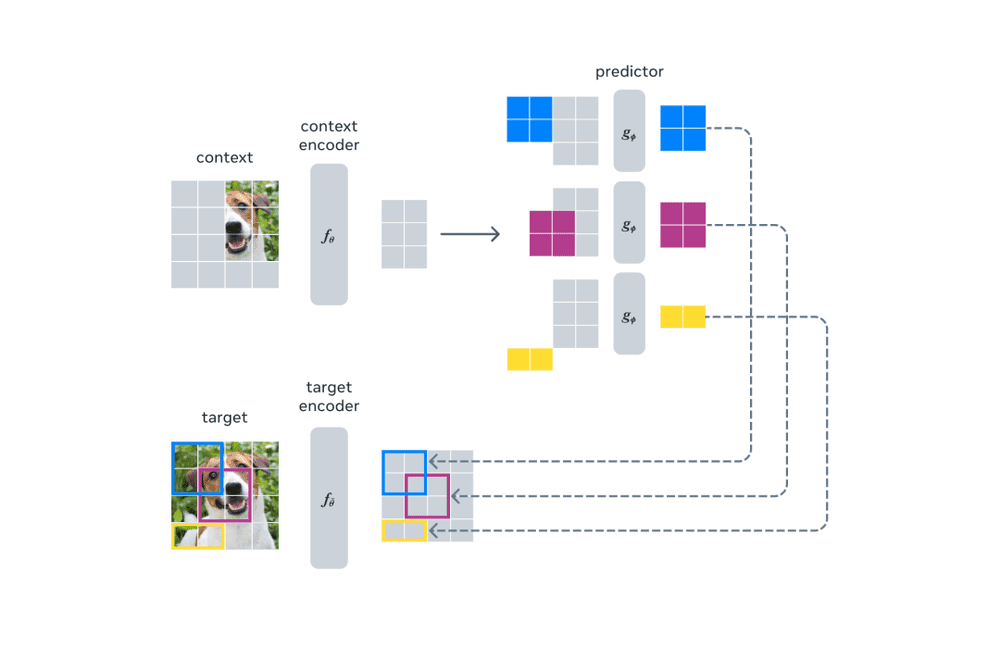
在更高的层次上,I-JEPA可以使用输入的部分表示,预测同一输入的其他部分表示,比如图像或文本的一部分。这与新型生成式人工智能模型不同,后者通过移除或扭曲输入的部分,例如擦除图像的一部分或隐藏段落中的一些单词,然后尝试预测缺失的输入。
Meta AI的论文认为,生成式人工智能模型采用的方法的一个缺点是:它们试图填补每一个缺失的信息,但世界的本质上是不可预测的。因此,生成式方法常常会犯下人类永远不会犯的错误,因为它们过于关注无关紧要的细节。例如,生成式人工智能模型经常无法生成准确的人手,会添加额外的数字或出现其他错误。
I-JEPA通过更类似人类的方式预测缺失的信息,用抽象的预测目标来消除不必要的像素级细节。通过这种方式,I-JEPA的预测器可以基于部分可观察的上下文,在静态图像中为空间不确定性建立模型,帮助预测关于图像中未见区域的更高层次的信息,而不是像素级细节。
Meta表示,I-JEPA在多个计算机视觉基准测试中表现出非常强大的性能,显示出比其他类型的计算机视觉模型更高的计算效率。它学到的表示也可以用于其他应用,而无需进行大量的微调。在ImageNet-1K线性探测和半监督评估中,它还优于像素和标记重建方法。
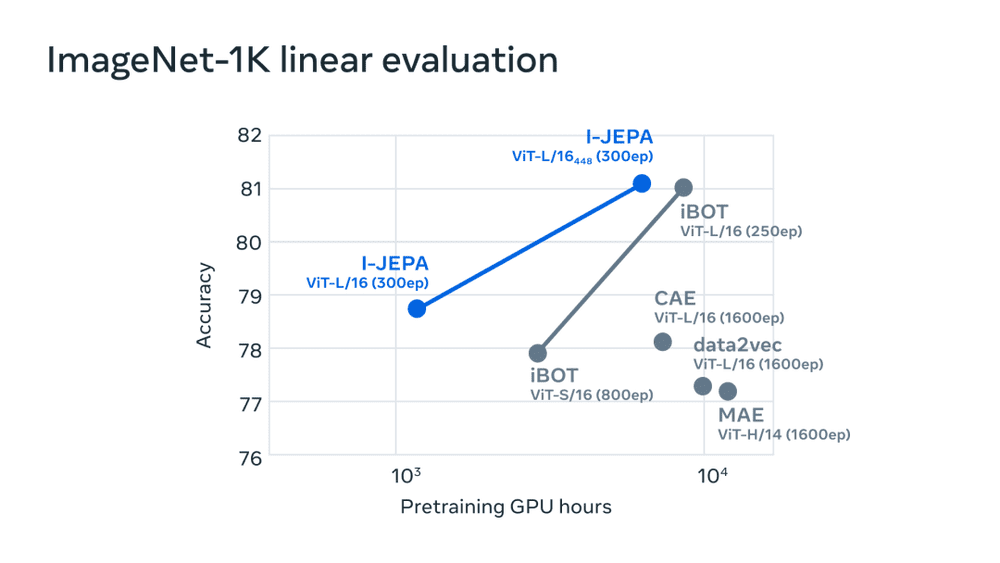
Meta的AI团队使用16个A100 GPU在不到72小时的时间内,就训练出了一个6.32亿参数的视觉变换器模型,并在ImageNet的低样本分类上取得了最先进的性能,每个类别只有12个标记示例。其他方法通常需要高达2倍到10倍的GPU小时数,并在使用相同数量的数据进行训练时达到更差的错误率。
Meta AI认为,I-JEPA证明了存在许多有潜力的架构,可以学习到强大的即插即用的表示,而无需在手工制作的图像变换中编码额外的知识。Meta AI将开源I-JEPA的训练代码和模型检查点,并且下一步将扩展该方法到其他领域,例如图像-文本配对数据和视频数据。
“未来的I-JEPA模型在视频理解等任务中可能具有令人兴奋的应用。”Meta AI表示,“我们相信这是应用和扩展自监督方法来学习世界知识的通用模型的重要一步。”
相比以OpenAI为代表的日益封闭的大模型,Meta AI坚持大模型开源。一些机构批评开源大模型不安全,容易遭到滥用,但Meta AI从来没有参与过任何监管人工智能的签名活动。Meta创始人CEO扎克伯格认为,开源的大模型,有助于加快人工智能技术的创新和普及。
这篇论文,将在下周举办的人工智能顶级盛会CVPR 2023上宣读讨论。
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:未尽研究