
本文来自微信公众号:城市数据团(ID:metrodatateam),作者:chenqin,原文标题:《中国1639种职业的GPT替代风险分析——5亿条招聘信息中的职业生涯密码:后篇》,头图来自:视觉中国
GPT来了,我会被它替代吗?
在上两篇推文(《5亿条招聘信息中的职业生涯密码:前篇》《打工十年,共得几钱?——5亿条招聘信息中的职业生涯密码(中篇)》),我们所使用的招聘数据,截止时间是到2022年年末。
但2023年,似乎进入到了一个新的纪元,各种生成式AI的快速推出,带来了前所未有的冲击。
生成式AI中最有代表性的,要数OpenAI的大语言模型——ChatGPT,很多人通过亲身尝试,在被科技震撼的同时,也都感到了深深的危机,似乎自己的工作很容易就能被AI替代。这种情绪迅速地被各类媒体和营销号捕捉到,通过个案的采访,以及文学化的解读,又被传播放大到了妇孺皆知的程度。
但是,迄今为止,关于生成式AI(或者狭义到大模型)对就业市场影响的真正的严肃研究还屈指可数。
目前比较有参考意义的研究,其实还是来自OpenAI自身。OpenAI在他们最新的工作论文《GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models》中,深入讨论了AI对劳动力市场可能的影响。

在这篇文章中,研究者发现,在大语言模型(LLM)愈发普及的冲击下,至少80%的美国劳动力会受到影响,他们的工作的10%会被LLM所替代。其中有19%的美国劳动力有超过50%的工作会被替代。
注意,以上研究也仅仅限于美国的就业市场。
那么,中国呢?
这是一个超巨大的但与美国截然不同的劳动力市场,同时又面临人口老龄化和各种劳资矛盾;在中国的各种岗位,又有多少会因为大语言模型的冲击,被替代、甚或是消失呢?
在这篇推文里,我们将借鉴OpenAI工作论文的思路,利用来自中国的招聘数据,用我们独立设计的方法,尝试对于这个大众关切的问题给出一个超越感性认识的,覆盖所有职业的,全面性的数据答案。
讨论AI替代的关键问题:每个职业究竟都在做什么?
要分析一个岗位在多大程度上能够被GPT或者衍生的其他AI模型所替代,首先需要明确一个最关键的问题:
每个职业究竟都在做哪些事情?
我们看到营销号里经常提到,AI会取代秘书、AI会取代程序员,诸如此类。但这是一个非常模糊的表达。在本质上,AI所替代的,并不是一个大众认知的泛泛的职业名字,而是这个职业中所包含的职能和工作内容。
那么,什么是职业中所包含的职能呢?在招聘网站上,我们会看到“岗位描述”,比如一个典型的人力资源部员工的岗位描述可能包括以下内容:
1. 新员工的招聘,员工入职手续办理;
2. 安排以及开展新员工入职培训;
3. 考勤及工资绩效的核算;
4. 维护和拓展公司招聘渠道,协助社招及其他招聘活动;
……
大家可以看到,其中每一条都是人力资源部员工的职能。而每一条职能又包括了更丰富的工作内容。比如“安排以及开展新员工入职培训”,又包含了下列具体工作内容——1. 撰写、准备培训材料;2. 交流、沟通并安排计划时间表;3. 演讲、培训,提升员工技能……等具体工作内容。
当“人力资源专员”这个职业的工作结构被拆解成了数个甚至数十个职能和工作内容后,单独判断“撰写、准备培训材料”这一项内容有多大可能会被AI冲击,这样才能产生具体的、可量化的、有切实意义的答案。
好的,那么问题来了,我们怎么才能获取每个职业的职能和工作内容信息呢?
为了获得各种职业的任务拆解信息,OpenAI的论文中使用了O*net数据库。O*net,全称为职业信息网络(Occupational Information Network),是一个基于美国标准化职业的免费在线数据库。这个数据库已经完成了所有的(美国)职业拆解。
那么中国有没有O*net这样的数据库呢?很遗憾,目前并没有,而且由于中美对于职业的定义存在一定差异,O*net数据库的职业也很难与中国职业大典中的标准职业形成准确的映射关系。
所以我们采用了一种间接的匹配方式,采用市场上真实招聘数据作为媒介,每一条招聘数据,通过前篇中的方法,同时映射到中国标准职业和O*net标准职业后,再按照中国标准职业汇总,从而就得到了每一个中国标准职业下的工作任务和具体工作内容。
经过汇总和抽象合并,我们共计匹配产生了1639种职业、19265条职能和23534种工作内容。
谁来判断AI替代性?意料之外的“数据标注员”
获得了上述数据,也就是明确了每个职业具体的工作任务和工作内容后,按照OpenAI的方法,下一步就是给每个工作任务和具体工作内容进行打标,具体判断其是否会被AI替代。
在此,需要标注的数据大约几万条,那么,如何完成这个工作呢?
在过去,我们就需要聘用大量人工数据标注员,对19265条工作任务和23534种工作内容打标,让标注员们判断每一个任务被AI替代的可能性是多少,是30%,还是70%,再将这些标注员的工作合并在一起求平均,得到每一个职业被AI替代的可能性。
数据标注员,其实是一种很新颖的职业,在2022年版的《中国职业大典》中才首次出现,职业代码为4-04-05-05-01,在细类“人工智能训练师”的类目下,主要工作内容包括“标注和加工图片、文字、语音等业务的原始数据”。判断每一个职业的具体任务和工作内容是否会被AI所替代,自然也是数据标注员工作的一种。
——是的,原本确实应该是这么做的,过去这么多年来也一直是这么做的。但我们现在有了大语言模型,有了GPT,事情开始变得不一样。
在OpenAI的那篇工作论文中,作者确实聘用了人类来为这些工作内容打标,但他们同时请来了另外一位更高效的助手,那就是GPT自己,通过一个复杂的prompt使GPT理解打标任务背景后,让GPT自己出手,判断每一条工作内容被自己替代的可能性究竟有多少。
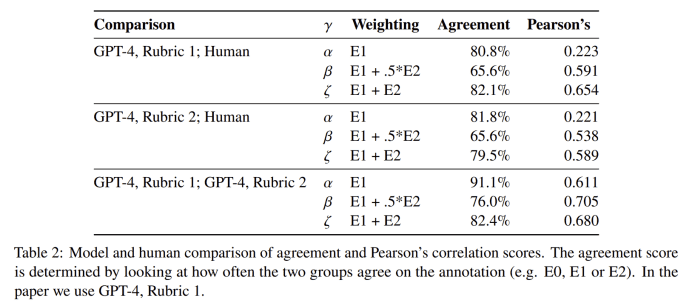
结果有些出人意料,细想却又很合理——GPT的标注结果,和人类的标注结果高度一致,有百分之81%以上的标注是完全一样的。论文中让GPT用不同的prompt标注了两次,其结果也很类似,两次标注之间有91.1%的结果一样。论文最后选了其中一次GPT的标注结果来进行研究,人类的标注结果,仅仅用来判断GPT的合理性,并没有被用在论文中。
是的,让GPT来标注“某一项工作内容会被GPT替代的可能性”。让魔法来审判魔法。
我们自然也使用了这种方法,直接使用GPT-4的API,对于每一种职业的每一类工作内容进行打标,具体的prompt类似这样(我们最终使用的prompt与之不完全一致,可以根据需求自行修改):
你是一名“大型语言模型替代劳动力评估师”。大型语言模型,是一种用于处理和生成自然语言文本的深度学习模型,最新的大型语言模型能够基于自然语言文本生成、描述创建图像与视频。在这样的背景下,你需要从“该任务是否能够在大语言模型帮助下,在同样时间达成同样产出或者同样效果的前提下,减少人类劳动时间的参与”的角度,给下列每一个任务打分。
评分从0到5分,0代表该任务不能通过大语言模型的帮助减少人类劳动投入,1代表可以减少20%人类劳动投入,2代表可以减少40%的人类劳动投入,3代表可以减少60%的人类劳动投入,4代表可以减少80%的人类劳动投入,5代表可以减少100%的人类劳动投入,即该任务不再需要人类劳动参与。
你的评分,代表着大语言模型可以在每一个任务中节省多少比例的劳动投入,请根据当前大语言模型的进步情况和你认为未来可能的发展状况,谨慎评分。请按照“id,评分”的格式,每一行返回一条任务的评分结果。
在API中,以上内容被作为背景输入,接下来具体的内容便可输入具体的工作任务和工作内容,一次可输入多条,但由于输入token限制,一次我们最多能输入100条左右让GPT帮助打标。
接下来,GPT-4的API就会快速返回结果。由于任务已经被拆解得比较细致,对于每一条任务的打标十分准确,稳健性也极高。
更重要的是,使用GPT打标,成本之低令人发指。标注4万条内容,每次标注100条,只需要400次,使用GPT-4的模型,每标注100条,仅需要0.12美元。也就是说,一共只需要耗费48美元,合人民币300多元。如果使用不那么精确,但速度更快且更便宜的gpt-3.5-tubo模型,4万条只需要耗费3美元,约合20多元。在这样简单的任务上,GPT-4和gpt-3.5-turbo的表现几乎没有差异。
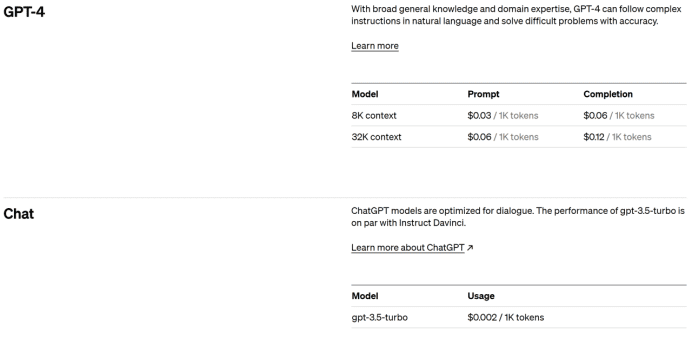
而人类数据标注员要完成4万条内容的标注,需要至少1万元,一星期。GPT只需要半小时,一杯奶茶的钱。而两者的质量是几乎一样的。
我们必须正视这样一个似乎有些讽刺的事实——
刚刚出现没几年的全新职业——人类标注员,他们喂养出来的大型语言模型GPT,在完成一项“GPT能够替代哪些职业”的标注工作任务时,首先替代掉了把GPT训练成材的人类数据标注员。
通过“工作内容标注”的结果,我们找到了最容易被AI替代的职业
使用GPT标注的结果,我们可以计算什么样的职业最容易被大语言模型以及其他AI相关的衍生职业替代。具体计算过程是这样的:
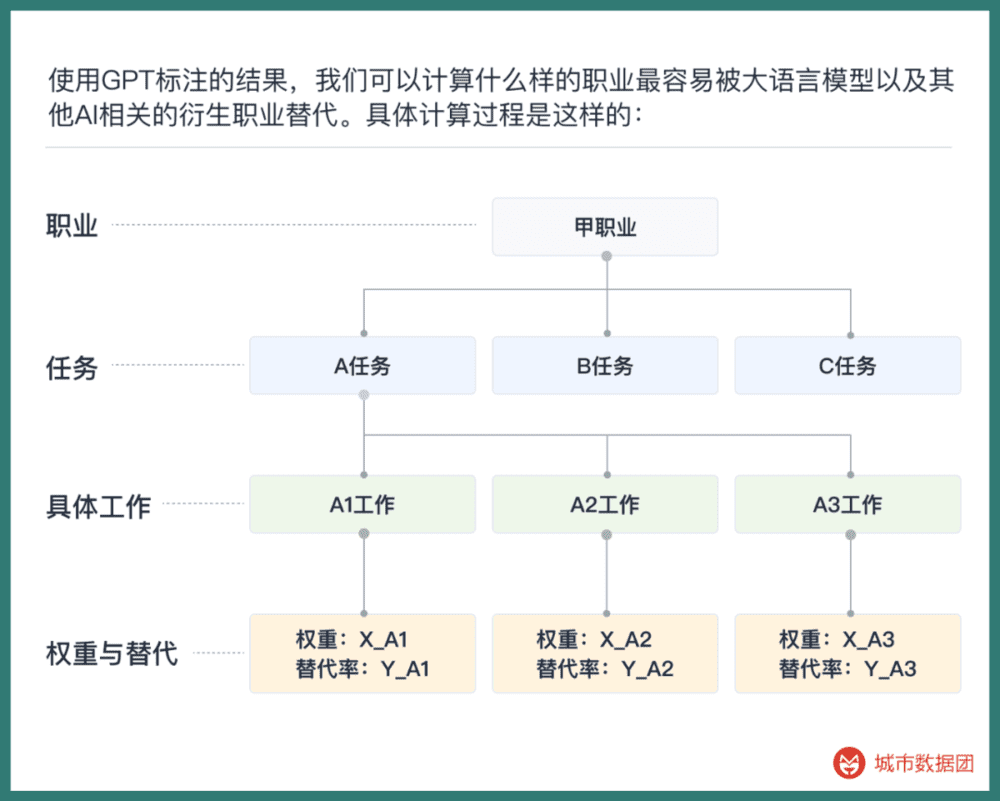
将所有的工作权重(来自O*net数据)和替代率全部相乘后求和,就得到了该职业的AI替代率,可以理解为这份工作总共有百分之多少的工作内容可能被AI替代。
下表列出了在招聘达到一定规模的职业中AI替代率最高和最低的各25个职业。

上表的这50个职业,可以理解为未来职业发展的晴雨表。
AI替代率最高的职业是翻译,其次是保险核保专业人员以及剧作家。这三个职业,有90%以上的工作任务和内容都暴露在AI替代的风险中。
接下来,视觉传达设计人员、装饰美工、美术编辑、广告设计师、剪辑师,这些与美术、视频、作图相关的职业,被AI替代的工作内容也超过了80%。
文字编辑、网络编辑、文学作家、文字记者,这些与文字生成和修改高度相关的职业,被替代的工作内容也超过了75%。
呼叫中心服务员、前厅服务员(即为宾客提供咨询、迎送、入住登记、结账等前厅服务的人员)、节目主持人、秘书……这些职业,也出现在了前25名中。
当然,不能忘记排名第25的计算机程序设计员,平均来说,程序员有75%的工作内容,面临被AI替代的风险。
AI替代率最低的职业主要是各种制造业相关蓝领人员。这并不意外,因为我们让GPT评分标注时扮演的角色就是“大型语言模型替代劳动力评估师”,它自然无法评估可能被其他机器所替代的职业。但仍然有几个制造业工人以外的人员值得注意——绿化工、保洁员、洗衣师、按摩师、美甲师、中式面点师……看起来并不需要太高学历,工资也不算最高的这些职业,反而成了最难被AI替代的职业。
AI替代率和职业特征背后的探究
在OpenAI的那篇工作论文中,研究者发现了稳定的正相关关系——工资越高的职业,被GPT们替代的可能性越高。这个趋势在年收入大于10万美元的职业之后才区域相反,见下图。
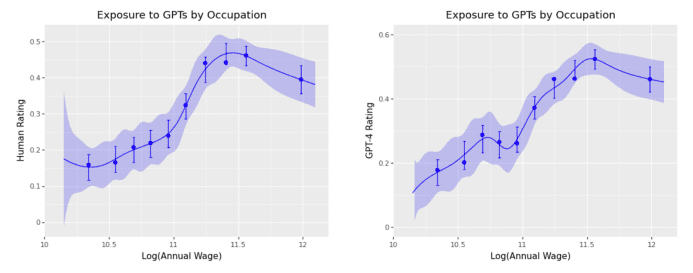
那么中国的情况呢?请看下图:
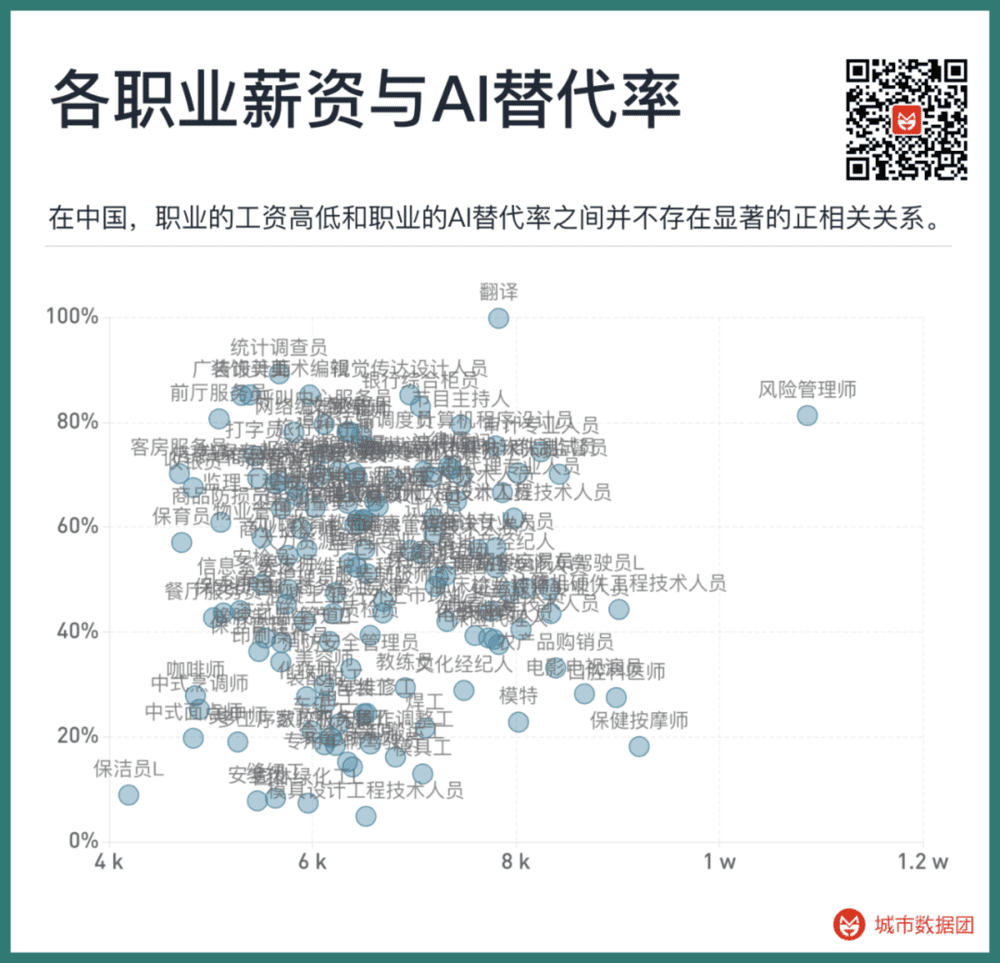
可以看到,美国的现象在中国似乎并未出现。职业的工资高低和职业的AI替代率之间并不存在显著的正相关关系。
但是,正如上一篇文章中提到的,对于每一个职业,当前的工资只是一部分内容,更重要的是从业年限增长率。一些工作可能入职时工资更低,但随着工资年限上升却有更高的上升空间,从而有更高的十年总收入。
那么,从业年限的工资增长率和每个职业的AI替代率之间存在什么关系?可见下图:
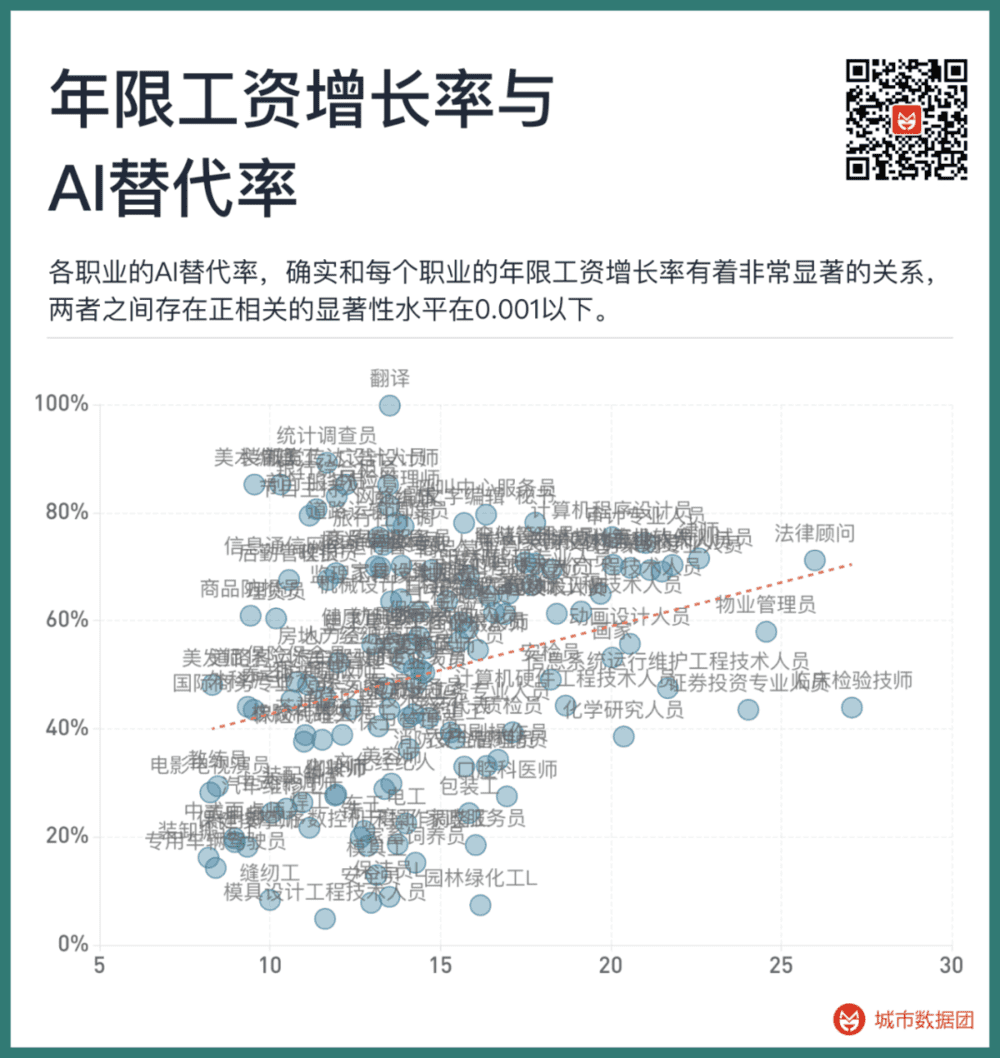
可以看到,各职业的AI替代率,确实和每个职业的年限工资增长率有着非常显著的关系,两者之间存在正相关的显著性水平在0.001以下。如果我们将上图改为分段柱状图,我们将可以看到更明显的趋势。请看下图:
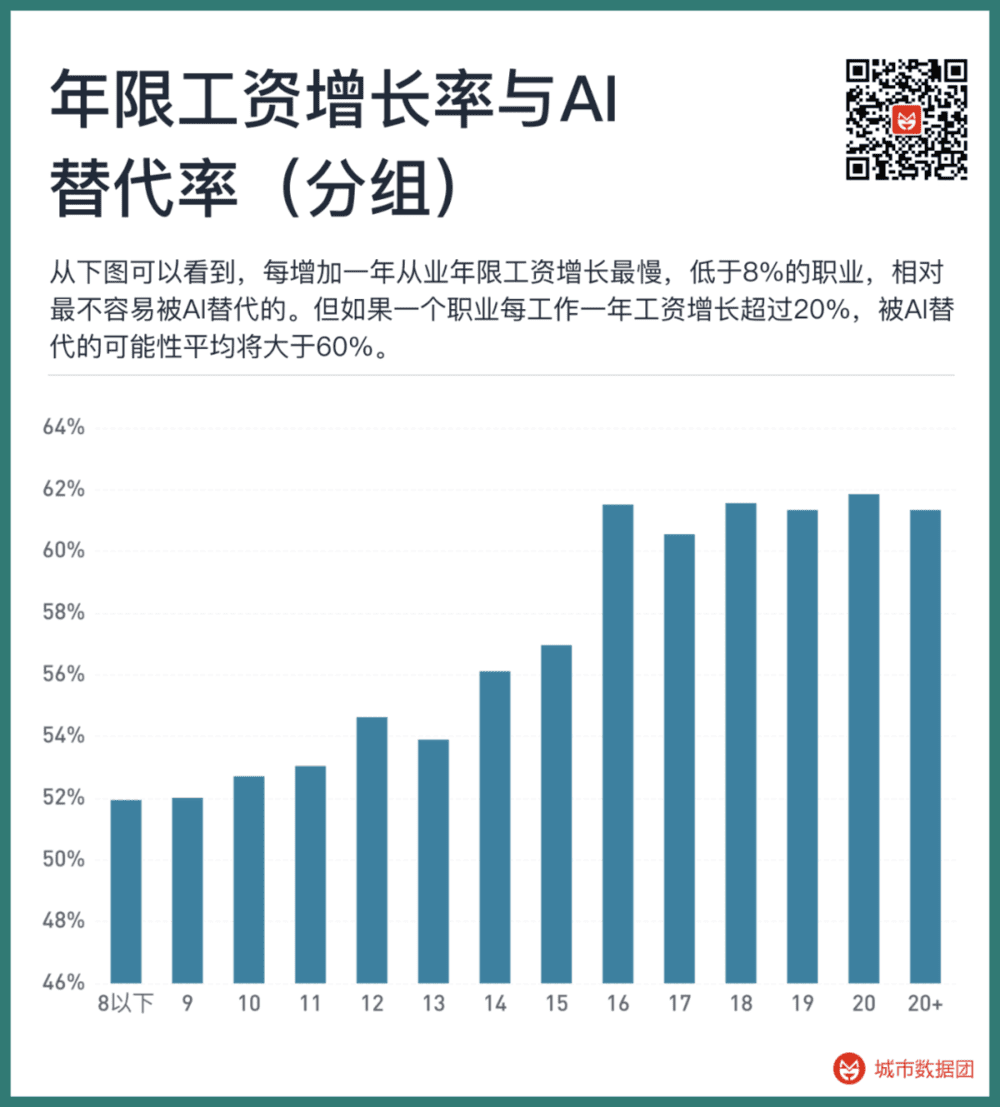
从上图可以看到,每增加一年从业年限工资增长最慢,低于8%的职业,相对最不容易被AI替代的。但如果一个职业每工作一年工资增长超过20%,被AI替代的可能性平均将大于60%。
这个趋势,说明的是在本轮大语言模型和其衍生出来的相关AI的一个显著特征,那就是:
人们在一个行业上积累的经验、学到的技巧、掌握的诀窍,他们一方面使这些职业看起来有更强的“成长性”,但另一方面也是被大语言模型首先替代掉的东西。
反过来,那些不需要精深学习就能掌握的人类能力,反而成了不会被AI替代掉的技能。
为什么AI替代掉的是这些?我们为什么是我们?
各种工作中被AI替代掉的,为什么是上文的这些?
第一种可能,是因为那些学习、工作后能积累更多经验,提高更快生产率的职业,本身劳动力成本更高,因此更促使人们去找到能替代这类劳动力的AI,给这样的AI产品更大的投资,因此这些职业就成了第一批牺牲品。
这样的说法有一定道理,但我们也能找到很多反例,例如自动驾驶。驾驶这个技能,人们学习几个小时至多十几个小时就能掌握;另一方面,自动驾驶方面的投资在领域内数一数二,但目前的效果距离全路况自动驾驶依然有很长一段距离。
反过来,一些生物、化学方面的技能,化合物寻找、蛋白质折叠,或者是在实验流程上的全自动化,这些人们需要数年专业训练才能掌握的知识,尽管资本的介入比起自动驾驶只能算九牛一毛,却已经有了非常不错的替代AI。
从这点看,劳动力价格更贵——吸引更多投资——替代性AI更容易出现的逻辑似乎并不完全正确。
那么,我们不得不考虑第二种可能——人类通过后天的实践学习知识、积累经验和诀窍的技能,AI确实已经实现甚至完成了超越。
是的,不是单个技能,也不是一组技能,而是那种通过艰苦的学习实践来获取知识、积累经验的技能,人类已经落后于AI。那些高成长性的职业,不管现在是否还处在安全区,出现替代AI,也许就是这几年,甚至几个月之内的事。
到头来,那些人类孩提时期甚至出生时就已经掌握的技能,那些精巧的人类生物学本能,似乎反而是AI最难模仿和替代的部分。
而那些后天学习到的知识,花上好长时间学会算术、学会写作、学会画画、学会编程、学会做好看的ppt、学会看X光片、学会写法律文书、学会很多种语言并且自如地交流……人类学会了各种各样以此为傲的东西,并觉得这些特征似乎使人类和其他生物产生了哲学上的差异。
但在AI看来,这些东西一文不值。
本文来自微信公众号:城市数据团(ID:metrodatateam),作者:chenqin