
这是城市数据团“职业生涯”系列推送的第一篇,这个系列的主题是打工人们的职业生涯发展,我们将会从现有的招聘数据出发,通过科学的数据处理手段,为读者呈现当下不同职业在不同城市的职业收入成长曲线,同时也结合近期的舆论热点,对AI可能产生的职业替代进行测算。
本文来自微信公众号:城市数据团(ID:metrodatateam),作者:chenqin,头图来自:视觉中国
与中国互联网同龄的招聘数据
如果要问,在各类互联网数据上,什么类型的数据既容易获得,又有非常大的信息量,回溯时间也比较长?我的回答就是——招聘数据。
时间回溯到20多年前。彼时大部分普通家庭都没有自己的电脑,遑论网络,而最吸引人的上网行为是什么呢?不是“上网冲浪”,也不是“聊天室聊天”。2000年9月13日,《科技日报》的一篇文章提到:
“随着我国经济的快速发展,网络逐渐为大众所接受。据调查统计,在目前上网的人群中,以求职为目的的上网者占上网人群的一半。”
2000年10月9日,《互联网周刊》的一篇文章《未来职业何处寻?招聘网站大比较》一文引用了CNNIC在2000年7月的调查,人们上网获取的信息中,招聘求职信息占26.11%。

1997年,中华英才网(chinahr)、智联招聘(zhaopin.com)成立;
1999年,前程无忧(51job)成立;
2005年,58同城、应届生求职网(yingjiesheng)成立;
2010年后的移动互联网时代,各类招聘网站和App如雨后春笋一般出现,猎聘、Boss直聘、拉勾……将招聘数据的维度再次扩张。
上至名校学子梦寐以求的高薪offer,下至家政服务、蓝领工人的短期零工,招聘数据沉淀的,不仅是一代代打工人的故事,更是中国经济这二十多年来的缩影。
招聘数据,从千禧年之初就与中国第一代互联网用户一起出现、成长,是一份与中国互联网几乎同龄的数据。
招聘数据:代表性问题与辛普森悖论
招聘数据也是非常难使用的数据。只通过简单的处理,难以呈现出口径一致、有代表性、有价值的信息。
代表性问题,一直是招聘数据的老大难。什么样的企业上网招聘,什么样的企业选择从其他渠道招聘?一直以来,互联网企业、外资企业等,使用招聘网站的频率都要远高于国有企业、制造业企业,这使得通过招聘数据汇总得到的总招聘量、总简历投递量以及平均工资等指标,都与真实的全国平均值有不小的偏误。不同招聘网站的招聘情况也有着极大差异。
例如下图是BOSS直聘的热招职位截图:
下图来自58同城的上海招聘热搜职位截图:

可以看到,两个网站的招聘信息类型、方向完全不同,当我们仅使用其中一个,或者几个招聘网站的信息时,难免挂一漏万,无法输出有效的结论。
除此之外,招聘数据的分类难度极高,也提高了它的使用门槛。当我们使用各类大数据时,常常需要将这份数据按照合适的分类标准和国家统计局的数据相匹配,得到类似口径的数据,方便我们验证数据的有效性。
但对于招聘数据来说,尽管在过去的八年中,我们通过数据合作伙伴从多个招聘网站来源,一共收录了5亿条招聘数据和12亿个招聘空缺,但如果只是将这些招聘岗位汇总,无论按照企业、行业还是地域进行划分,在与官方统计数据对比时都十分困难。
为什么海量的数据却并不能得到有效的结论?
首先,这些数据的历年获取数量、来源、公司数量都有极大差异。从下图可以看到,招聘数量最高的2019年,全国所有的招聘广告的所有招聘岗位空缺总和共有3.4亿人,但2022年下降到3400万人,数量整整相差十倍。
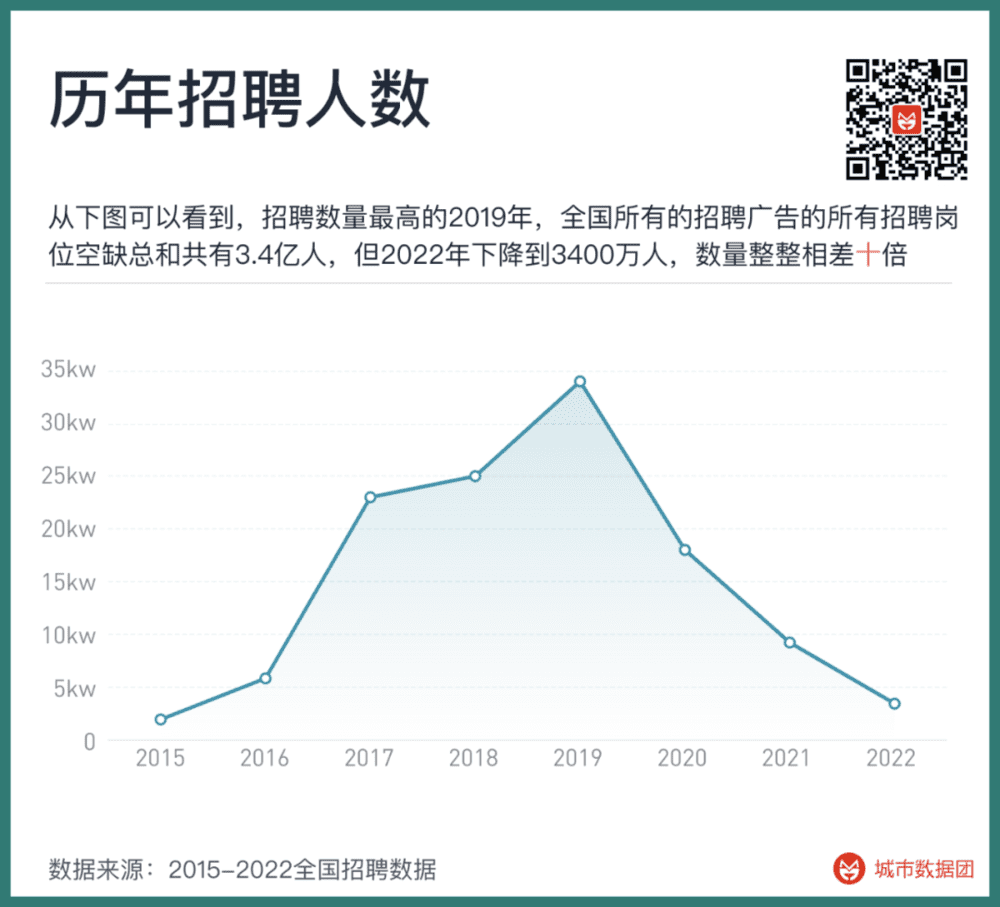
但招聘网站上的招聘数量的变化,其实并不能完全和企业对劳动力的需求一一对应起来。在经济景气时,员工流转更快,业务更多,企业对于未来的预期更好,甚至同一条招聘信息的多次调整重复,都会使得企业的招聘数量产生比真实劳动力需求更大的波动。
其次,招聘数据的工资也是一个混杂的变量。下图呈现了从2015年至2022年的分年度平均工资。可以看到,其中平均招聘工资最低的年份是2017年,约为4360元/月。2015年、2016到2017年,中国出现了招聘工资的连续两年下降,随后才重新回升。
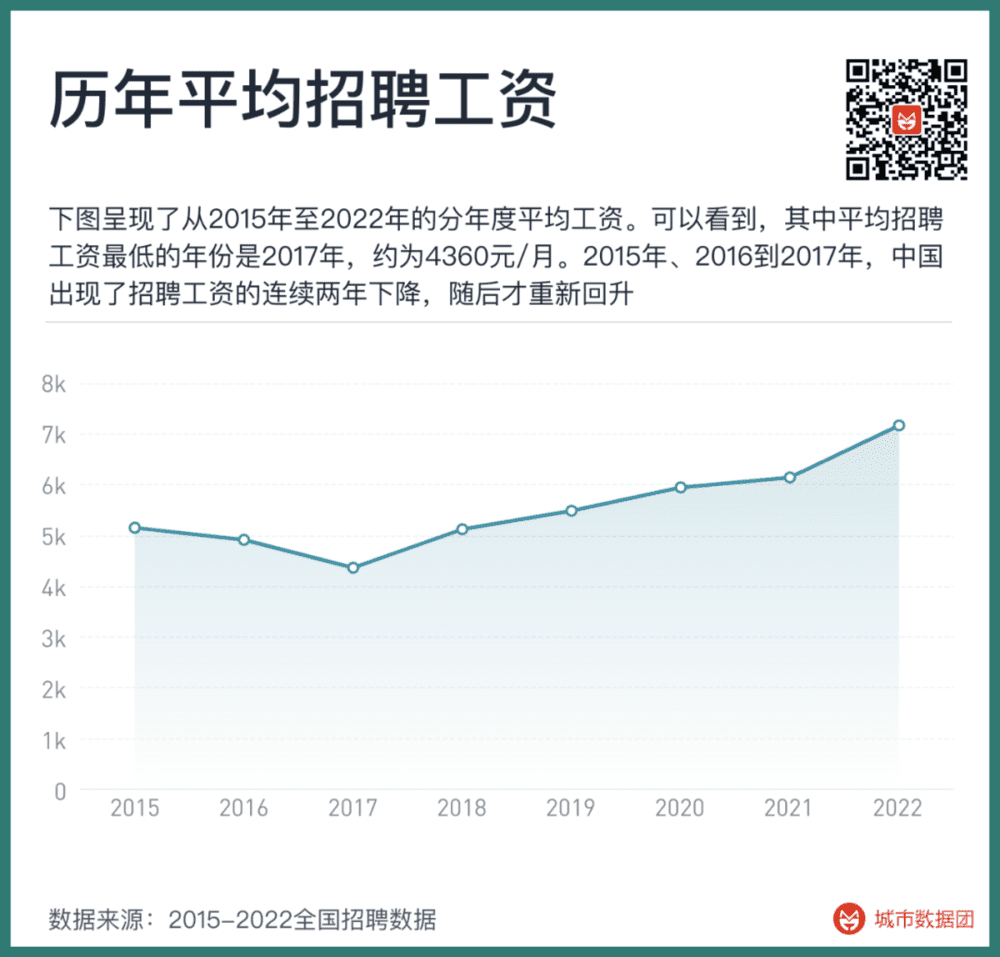
但招聘工资真的在2015年~2017年出现了下降吗?并非如此。
造成招聘工资下降的第一个原因,是招聘结构中的社招、应届生招聘的比重发生了变化。当应届生招聘比例的网站数据量增加时,平均工资下降;对于有多年经验的社会招聘职位数据量增加时,平均工资又会上升。
第二个原因,是招聘网站向二线、三线城市的下沉,以及对于之前招聘较少的工种人群的渗透——例如对于蓝领工人、家政服务等工种,近年来越来越依靠网络招聘。而这部分工种的工资,要比之前主要通过网络招聘的程序员等工种的工资要低得多,从而拉低了总体平均工资。
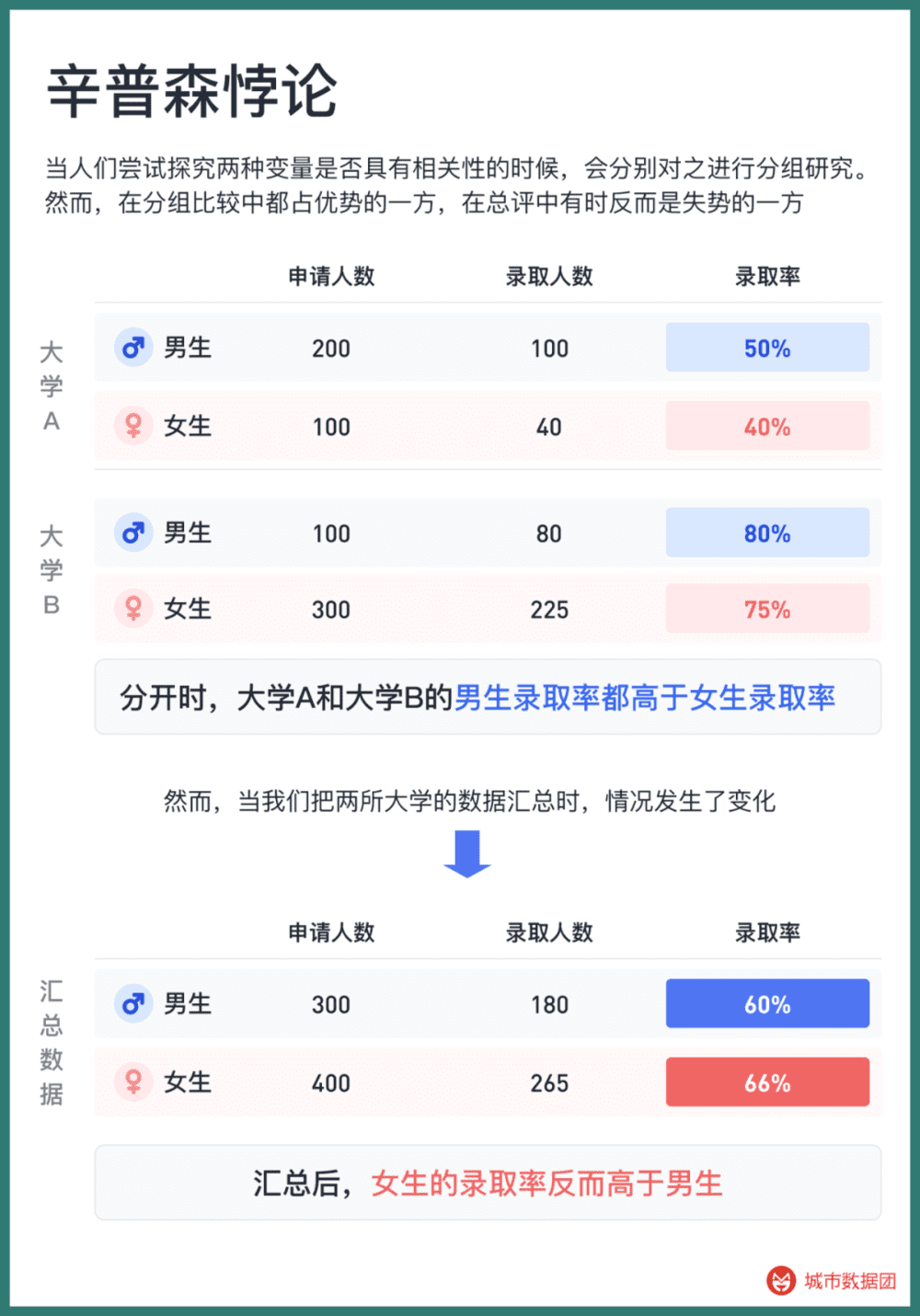
著名的辛普森悖论告诉我们一个结果:即便两组均值都在上升,其加总的均值却有可能下降。在下面的例子中,分开计算时大学A和大学B的男生录取率都高于女生,但在录取率较低的女性正在其录取率更高的那一组人数更多,导致汇总后,男生录取率却低于女生。
一些招聘网站使用自己的数据定期发布薪酬报告,也囿于其网站数据结构,与国家统计局的标准行业、职业结构也存在较大差异,难以与其他招聘网站对照,也难以与统计数据结合,得到一个可比较的口径。
因此,要从海量数据中识别出正确的趋势,真正把十多亿条招聘数据这一数据金矿用好、用足,关键在于我们能否对这组数据进行更正确、更标准化的分组,能否对每一条招聘数据,进行更细致的特征识别。
在过去的一个多月中,我们进行了一次尝试。
破解辛普森悖论:如何标准地分组职业
我们先用ChatGPT的GPT4模型生成下面这样一条典型的招聘广告:

可以看到,职位本身从事的职能,以及其需要的学历、经验,与这个职位的工资有着极大关系。学历与经验相对来说更容易从文本中分离出来,即“计算机相关专业、本科、3年以上”但我们如何对于这个职业进行分类呢?我们怎么把一个Python工程师,与其他类型的岗位分开,从而控制住这个岗位的内在能力需求呢?
第一种方式是,使用招聘网站本身的职位分类。
以下的三张截图,分别来自BOSS直聘、智联招聘和58同城,其类别都包括了“人事/行政”。可以看到,两者的职业分类存在不少交叉和差异。BOSS直聘的“薪酬绩效”,在智联招聘被划分为“薪资福利”与“绩效考核”,在58同城中,不仅薪酬、绩效是合并为一类的,“员工关系”也被包括在其中。


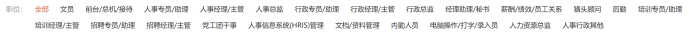
而当我们点击进某一类职业时,某一个岗位又往往“身兼数职”,或者只存在着资历的差别,并没有职能的差异。不同招聘数据的划分差异,使招聘数据的使用更为困难。
为了进行统一口径的比较,自然需要更权威、更标准的职业划分。我们使用了《中国职业大典》作为职业划分的依据。
《中国职业大典》是国家统计局、人力资源和社会保障部等在统计各类职业时使用的职业划分类目。
历次中国人口普查、人口动态抽样调查等,都使用《中国职业大典》作为每个被调查劳动者的职业划分依据。最新的2022版本《中职业大典》包括了大类8个、中类79个、小类449个、细类(职业)1639个,是对于中国职业最完整、权威的划分。
例如我们要从中找到“程序员”的分类,就可以通过下表这样的层级来查找:
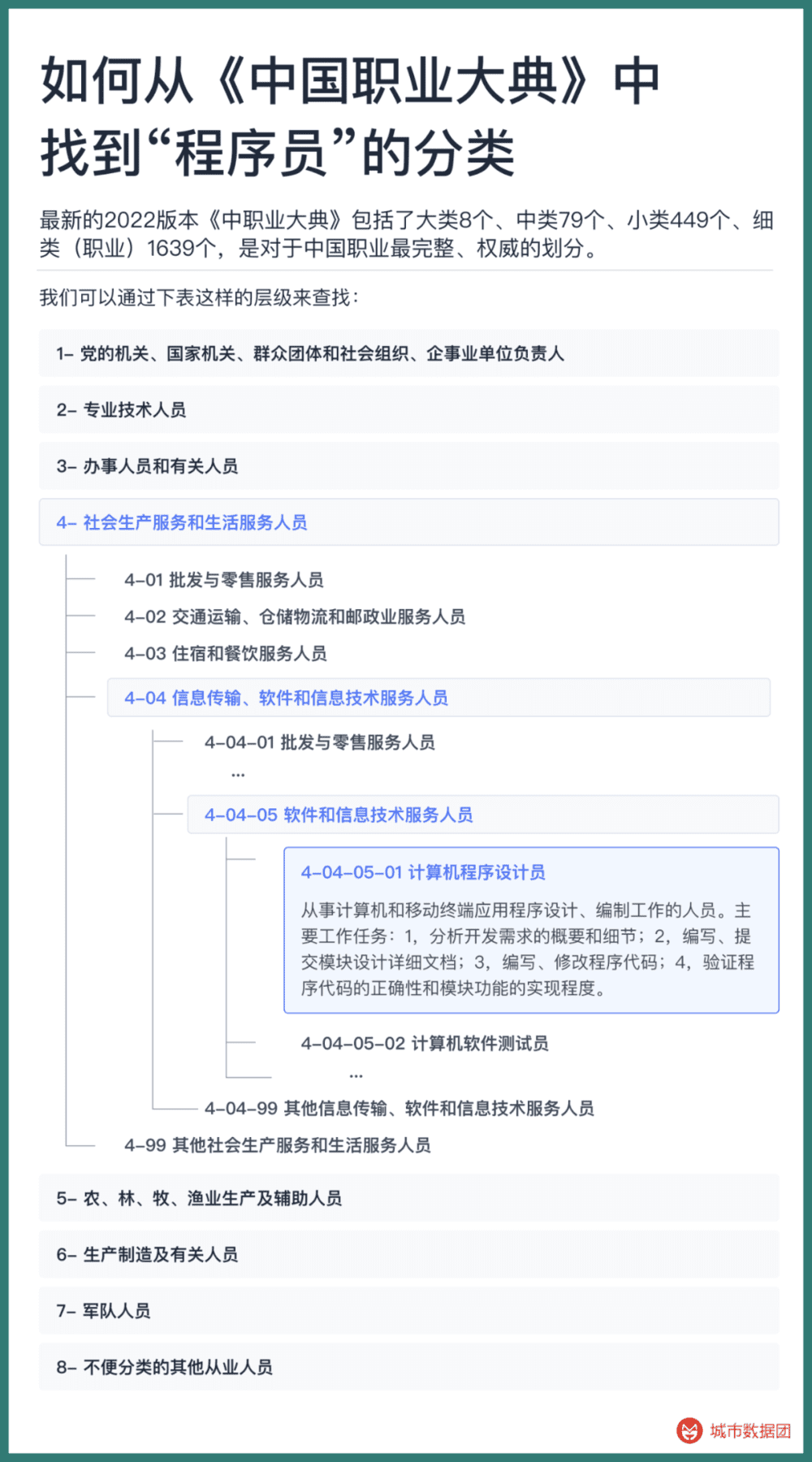
这样的职业划分,在最大程度上保证了职业之间的交集最少,而并集最大。我们将尝试把所有的招聘数据映射到这1639个职业中。
但是,如何划分和映射呢?光是“计算机程序设计员”这一个职位,在招聘网站上的职业名称就可能包括JAVA、Python、Ruby、Golang、Node.js、C++……等一系列关键词。这还是笔者相对熟悉的职业,我们可能还可以通过关键词映射的方式来遍历这一类职业。但一些相对不熟悉的职业,比如“课程顾问月入过万上升空间大”,你还能够将他准确地分类到标准职业代码的“营销员”的类别上吗?
因此,我们使用了一种文本学习的方法,首先让计算机学习每一种职业的具体工作,再通过每一个职位的职位描述进行匹配,见下图:
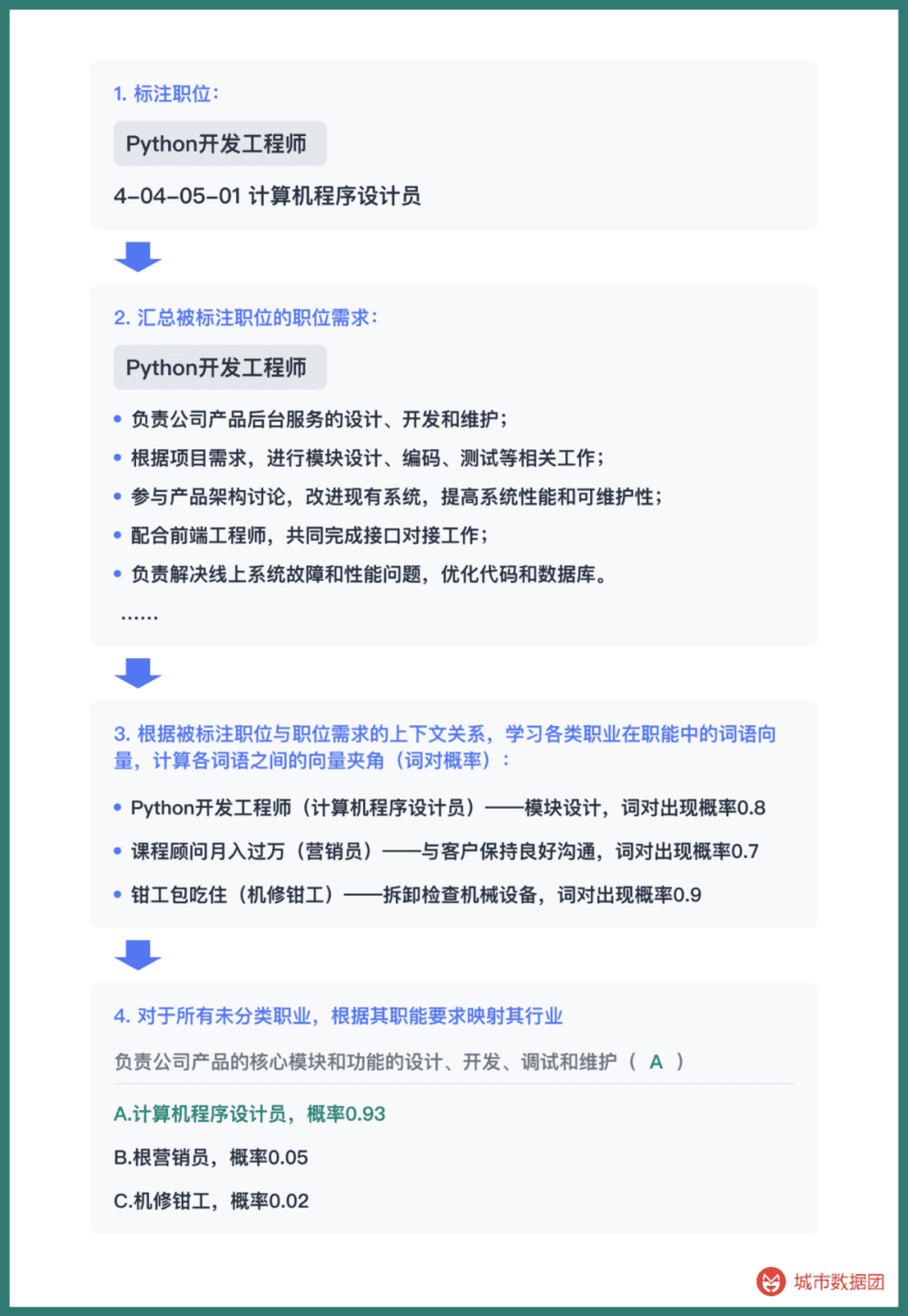
通过前期标注,将每一个职业的具体工作与该职业名称结合,计算职业-职能的高频率词对。再从招聘广告描述的工作职能出发,使用贝叶斯概率计算对应的可能是哪一种具体职业,像完形填空一样计算每一个职业的具体分类。
这样的方法具有极高的准确性,下面是我们分类到“计算机程序设计员”的一组例子,可以看到,即便在职位的标题中没有“程序员”的关键词,我们可能也无法遍历各种程序相关的关键词,也可以通过其岗位职能,准确地对这个岗位进行分类。
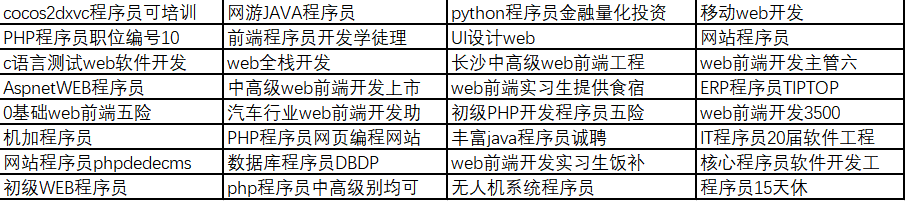
通过这样的方法,我们将从各类招聘网站获取到5亿条、包含12亿个招聘人次的招聘数据,高达1800万种职业,分配到了1500余种标准职业中,形成了一个从2015年到2022年全国各城市的标准职业数据库。
职业密码初窥,招聘数据“矿井”建成
有了标准职业数据库,我们就可以控制住每一个岗位的招聘时间、地点、经验要求、教育要求以及职位类型等信息了。当我们再使用这些数据时,已经不会再出现辛普森悖论类似的偏差问题。
举个例子,在此基础上当我们再次计算每一年的招聘工资时,便可得到下图:
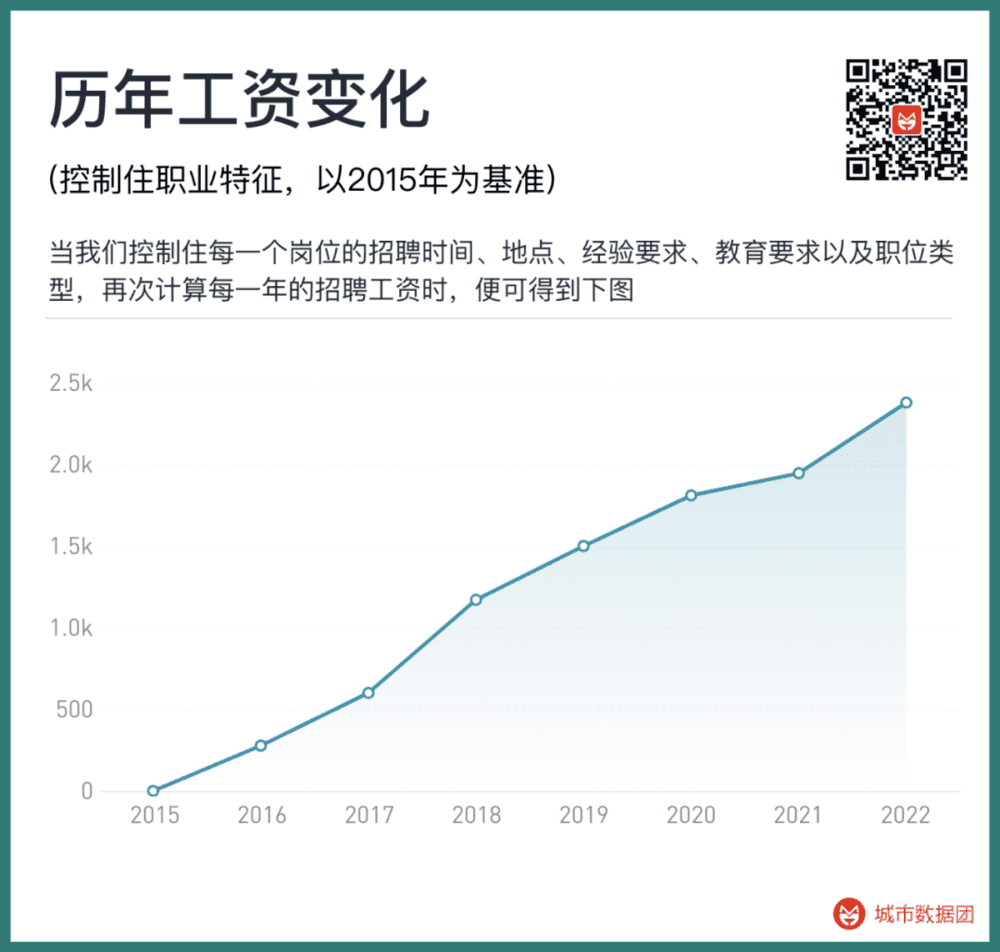
此时,我们便能看到一条稳定向上的工资增长曲线,并未出现突然的下降。同样招聘时间、地点、经验要求、教育要求以及职位类型的一份工作,2022年的招聘工资比2015年要高出2385元。
这也意味着,这个包含着数十亿招聘数据的“金矿”,终于不再是一片混乱的露天野矿,而已经被建成为一个品质稳定可控的工业级矿井了。
接下来需要做的,就是从中挖掘冶炼出各种宝贵的足金信息了。
本文来自微信公众号:城市数据团(ID:metrodatateam),作者:chenqin