
出品|虎嗅科技组
作者|齐健
编辑|陈伊凡
头图|英伟达
“切勿错过AI的决定性时刻!”这是英伟达2023年GTC大会的广告语。不知英伟达所说的“决定性时刻”是指黄仁勋在GTC大会主题演讲中三次强调的“AI的iPhone时刻”,还是说本届GTC大会就是AI的“决定性”时刻。
当然,今时今日可能确实是AI的决定性时刻。
从上周三到现在,一系列或惊艳,或不那么惊艳的最前沿AI技术接二连三地刷爆科技新闻版面。从OpenAI发布GPT-4,到百度发布文心一言,再到微软发布Office的AI助手Microsoft 365 Copilot,以及Midjourney发布能“画手指”的V5版本,甚至几个小时前,谷歌也上线了Bard聊天机器人接受排队测试。
在这样的AI关键时刻,手握GPU算力技术的英伟达自然不会缺席,毕竟在大模型军备竞赛中,作为“军火商”的英伟达,已经赢麻了。
北京时间3月21日晚11点,2023春季GTC大会正式上线,在大会的主题演讲中,黄仁勋围绕AI、量子计算、芯片等前沿科技,发布了一系列前沿技术和产品。

ChatGPT专用GPU可提速10倍
围绕AI的发布自然少不了GPU的提速,在黄仁勋的主题演讲中发布了全新的GPU推理平台,该平台包括4种不同配置,针对不同工作负载进行优化,分别对应了AI视频加速、图像生成加速、大型语言模型(LLM)加速和推荐系统和LLM数据库。包括:L4 Tensor Core GPU、L40 GPU、H100 NVL GPU和Grace Hopper超级芯片。

其中,H100 NVL是专门为LLM设计的GPU,采用了Transformer加速解决方案,可用于处理ChatGPT。相比于英伟达HGX A100,一台搭载四对H100和双NVLINK的标准服务器速度能快10倍,可以将大语言模型的处理成本降低一个数量级。此外,H100 NVL配备94GB HBM3显存的PCIe H100 GPU,采用双GPU NVLink,支持商用PCIe服务器轻松扩展。
L4是针对AI生成视频的通用GPU,用于加速AI视频,可以提供比CPU高120倍的性能,能效提升约99%。可以优化视频解码与转码、视频内容审核、视频通话等性能,一台8-GPU L4服务器可以取代100多台用于处理AI视频的双插槽CPU服务器。目前,英伟达GPU在AI视频生产技术供应商Runway的产品中已经提供了相应的技术支持。
L40则是用于图像生成,针对2D、3D图像生成进行优化,并可以结合Omniverse,直接生成3D内容,甚至是元宇宙内容。该平台推理性能是英伟达的云推理GPU T4的10倍。
此外,Grace Hopper超级芯片是为推荐系统和大型语言模型AI数据库设计的。可用于图推荐模型、向量数据库和图神经网络。它可以通过900GB/s的高速一致性芯片到芯片接口连接英伟达Grace CPU和Hopper GPU。
计算光刻技术提速40倍
黄仁勋带来的另一项革命性技术,也关乎英伟达自身的产品研发,是一项聚焦先进芯片设计制造的技术——NVIDIA cuLitho的计算光刻库。
NVIDIA cuLitho计算光刻库可以通过计算技术大幅优化芯片制造流程,利用GPU技术实现计算光刻,可以使传统光刻技术提速40倍以上,为2nm及更先进芯片的生产提供助力。
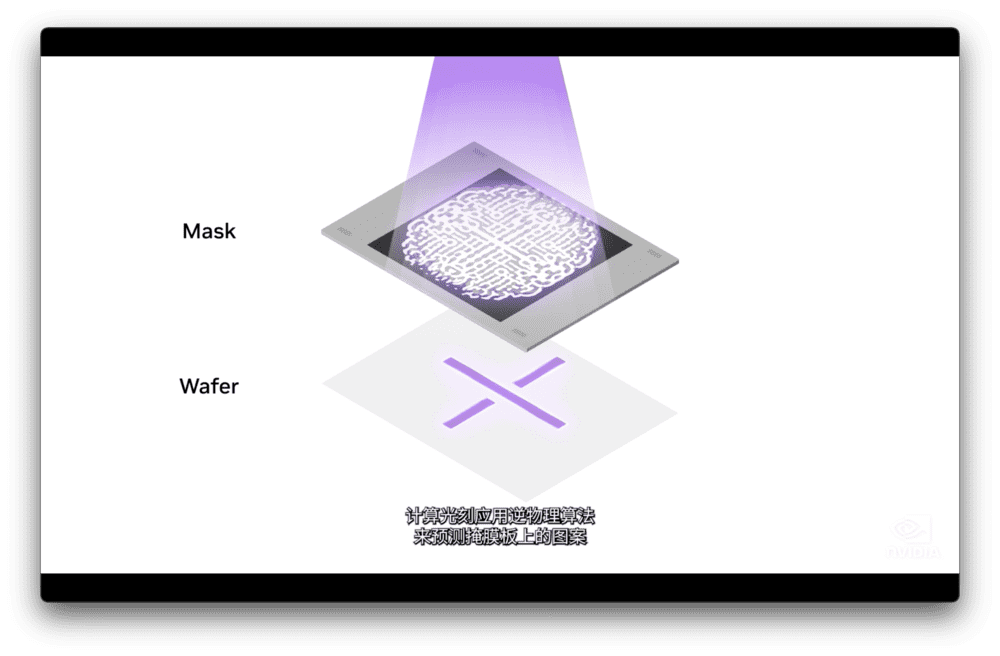
事实上,英伟达的计算光刻库在研发过程中,已经与3家全球顶尖的芯片制造厂商开展了长达4年的合作。包括晶圆制造巨头台积电、光刻机制造商阿斯麦,以及EDA巨头新思科技,目前3家厂商均已开始将该技术引入芯片设计和制造流程。
“计算光刻是芯片设计和制造领域中最大的计算工作负载,每年消耗数百亿CPU小时。”黄仁勋介绍说,大型数据中心24x7全天候运行,以便创建用于光刻系统的掩膜板。这些数据中心是芯片制造商每年投资近2000亿美元的资本支出的一部分。
NVIDIA H100需要89块掩膜板,在CPU上运算时,处理单个掩膜板,当前需要2周时间。如果在GPU上运行cuLitho则只需8小时即可处理完一个掩膜板。黄仁勋说:“台积电可以通过在500个DGX H100系统上使用cuLitho加速,将功率从35MW降至5MW,替代用于计算光刻的40000台CPU服务器。”
GPU&量子计算
除了AI和芯片以外,英伟达还在研究另一项前沿科技——量子计算。
本次GTC上宣布的第一个全新产品就是与Quantum Machines合作的NVIDIA DGX Quantum。该产品结合了通用量子控制系统Quantum Machines OPX+和NVIDIA Grace Hopper超级芯片,这个平台可以为高性能和低延迟量子经典计算的研究人员提供了一种革命性的新架构。

据黄仁勋介绍,NVIDIA DGX Quantum是全球首个GPU加速的量子计算系统,可以实现GPU和量子处理单元(QPU)之间的亚微秒级延迟。这种组合使研究人员能够建立强大的应用,实现校准、控制、量子纠错和混合算法,将量子计算与最先进的经典计算相结合。
DGX Quantum还为开发人员配备了统一软件栈,混合GPU-Quantum编程模型NVIDIA CUDA Quantum,能够在同一系统中整合和编程 QPU、GPU 和 CPU,是一个混合型量子经典计算平台。目前,CUDA Quantum 已经开放了源代码,为开发者提供了更多的支持。
AI超级计算上云
本次GTC的另一个重头戏是云。
英伟达发布的DGX Cloud云服务,提供了专用的NVIDIA DGX AI超级计算集群,搭配NVIDIA AI软件,使每个企业都可以使用简单的网络浏览器访问AI超算,消除了获取、部署和管理本地基础设施的复杂性。
该服务目前已经与Microsoft Azure、Google GCP和Oracle OCI开展合作。每个DGX Cloud实例都具有八个H100或A100 80GB Tensor Core GPU,每个节点共有640GB GPU内存。

使用NVIDIA Networking构建的高性能、低延迟结构,可以确保工作负载跨互连系统集群扩展,允许多个实例充当一个巨大的GPU,以满足高级AI训练的性能要求。
目前,英伟达开放的首个NVIDIA DGX Cloud,是与Oracle Cloud Infrastructure(OCI)合作的云服务。用户可以租用DGX Cloud的月租为36999美元起。
AI工厂,制造智能
除了算力以外,英伟达还想要通过云服务,把制造大模型的能力交给更多的用户。
黄仁勋带来的另一项关于云的重磅发布是NVIDIA AI Foundations,旨在为用户提供定制化的LLM和生成式AI解决方案。该服务包括语言模型NEMO、视觉模型PICASSO和生物学模型BIONEMO。

其中,NEMO是用于自然语言文本的生成式模型,可以提供80亿、430亿、5300亿参数的模型,且会定期更新额外的训练数据,可以帮助企业为客服、企业搜索、聊天机器人、市场分析等场景定制生产生成式AI模型。
PICASSO则用于制作视觉模型,可以用于训练包括图像、视频和3D应用的生成式AI模型。PICASSO可以通过高文本提示和元数据用DGX Cloud上的模型创造AI模型。目前英伟达已经与Shutterstock合作,开发了Edify-3D生成式AI模型。
本次GTC英伟达还着重关注生物制药领域。BIONEMO是专门为用户提供创建、微调、提供自定义模型的平台,包括AlphaFold、ESMFold、OpenFold等蛋白质预测模型。生物圈的热门方向是利用生成式AI发现疾病靶因、设计新分子或蛋白类药物等。
此外,英伟达还与Adobe合作,将生成式AI融入营销人员和创意人士的日常工作流,并开展了对于艺术家版权保护的工作。
写在最后
有人将GPU在深度学习方面的成功比作是中了技术的彩票,但黄仁勋并不这么认为。他曾多次表示自己在10年前就已经看到了AI行业的发展潜力,以及GPU对AI的决定性作用。英伟达正是看好这点,才孤注一掷地投入力量开发更适合AI的GPU产品。
OpenAI在2018年推出的GPT-1,只有1.2亿参数量,而最后一个公布了参数量的GPT-3则有1750亿,虽然有一些专家认为ChatGPT和GPT-4的参数量有可能更小,但业界多数的声音认为,更强大的模型就以为这更大的参数规模,且要消耗更多的算力。
OpenAI已公布的信息显示,在训练上一代的GPT-3时,使用了数千个NVIDIA V100 GPU。
调研机构TrendForce在一份报告中提到,GPT-3训练时大概用到了20000个NVIDIA A100 GPU左右的算力,而ChatGPT商业化后所需的GPU数量将达到30000个以上。
某AI芯片专家告诉虎嗅,目前OpenAI公布的技术细节不多,前期的训练又都是在英伟达的显卡上做的。“这给了英伟达更多针对Transformer的GPU实验数据,从一定程度上造成了英伟达对ChatGPT和GPT-4的技术垄断,从市场竞争的角度说来说,对其他AI芯片很不利。”
事实上,谷歌此前曾推出过针对TenserFlow的TPU产品,然而,英伟达此次发布的GPU推理平台针对时下火热的GPT大模型,进行了Transformer架构优化,则似乎又领先了谷歌一步。