
“我们需要更大的GPU。”
当地时间3月18日,黄仁勋在英伟达2024 GTC大会上,宣布了英伟达新一代加速计算平台NVIDIA Blackwell,以及基于Blackwell GPU架构的双芯片GPU B200和超级芯片GB200。
Blackwell架构单GPU AI性能达到 20 PFLOPS,性能比上一代提高了5倍,而成本和能耗下降降低25倍。黄仁勋以训练1.8万亿参数的GPT模型为例(可能GPT-4的参数量)。同样以90天为训练周期,上一代Hopper架构的GPU至少要用8000个,功耗15MW,而使用Blackwell架构的GPU,只需要2000颗,功耗约4 MW。
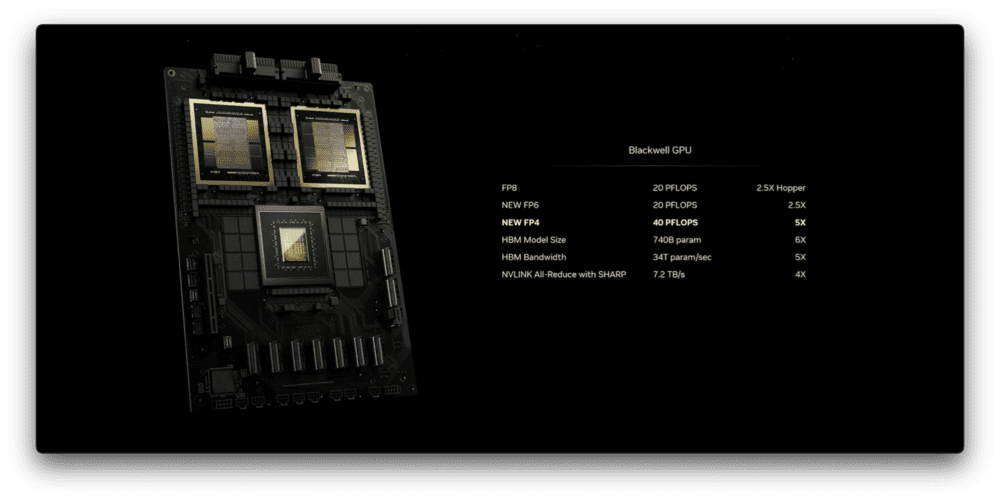
Blackwell
作为全球加速计算市场的“老大”,英伟达今天的一切成功都建立在GPU上。
不过,从黄仁勋在GTC大会上的主题演讲来看,英伟达似乎并不希望外界只看到他们的GPU。在黄仁勋2个小时的主题演讲中,虽然Blackwell平台的发布是绝对主角,但他也把超过一半的演讲时间放在了GPU“周围”的技术上,包括:芯片设计、生产技术,生成式AI模型训练,数字孪生,以及具身智能等。
一直以来,英伟达都在强调自己是“人工智能时代领先的计算公司”,而不只是一家芯片或是硬件公司。在GTC上宣布的软件技术、AI训练技术、机器人技术等,也无不透露着“源于GPU,高于GPU”的味道。
软件是GPU的护城河
加速计算市场上并不乏性能与英伟达接近的GPU产品,然而英伟达真正的护城河其实来自GPU软件开发工具。
在Blackwell之外,英伟达公布了一系列与AI、GPU、机器人相关的创新软件应用,包括:
AI 模型和工作流微服务产品NVIDIA NIM(NVIDIA AI Microservices);企业级的 AI 软件平台NVIDIA AI Enterprise 5.0;用于机器人开发的仿真环境NVIDIA Isaac Sim;GPU 加速、性能优化的轻量级应用NVIDIA Isaac Lab;用于计算编排服务的工具NVIDIA OSMO;用于药物研发的微服务NVIDIA BioNeMo;用于基因组学分析的软件套件NVIDIA Parabricks;用于视频分析和智能视频管理的软件平台NVIDIA Metropolis等。
其中,NVIDIA NIM(NVIDIA AI Microservices)最为突出。
NIM是一系列集成AI模型和工作流的微服务,专为企业和开发者提供在生物、化学、影像及医疗数据领域构建和部署AI应用的高效、灵活方式。NIM的关键优势是其符合行业标准的API,便于开发者创建云原生应用。
目前,NIM 微服务以及开始在医疗影像领域推广。通过利用 NVIDIA 的 AI 技术,NIM 微服务可以帮助医疗专业人员更快速、更准确地分析和解释医疗影像数据,从而提高诊断的质量和效率。此外,NIM 微服务还可以用于药物研发,通过生成式化学模型和蛋白质结构预测模型,加速新药的发现和开发过程。
事实上,软件应用生态除了在AI等开发端支撑英伟达的GPU业务,在未来也有可能为英伟达走出一条新的增长曲线。
SaaS行业是公认的毛利更高、赚钱快,且软件、应用研发资产轻,不会像硬件生产那样受到供应链的制约,也没有生产、库存压力。
虽然英伟达的GPU借着AI的东风也能赚得盆满钵满,但增长速度相比不如爆发增长的OpenAI。而且如果只做GPU和算力生意,未来的发展空间,也难免会受到制造业自身增长缓慢属性的影响。
已经垄断了GPU生意的英伟达,自然不希望像AMD、Intel、高通那样,“躬耕”于芯片行业卷生卷死。对于英伟达来说,基于AI大模型、软件等向上再迈一层,不仅能巩固自己当下的行业地位,也能拓宽未来的赛道。
算力怪兽的关注点在通信
专为AI而生的Blackwell可以处理万亿参数规模的大语言模型(LLM)。每块GPU拥有2080亿个晶体管,采用专门定制的双倍光刻极限尺寸4纳米TSMC工艺制造,通过 10 TB/s的片间互联,将GPU裸片连接成一块统一的GPU。
与Blackwell平台一同推出的还有采用双芯片设计的新一代GPU B200,单GPU AI性能达到20 PFLOPS。B200配备192GB内存。以及基于B200的超级芯片GB200 ,通过900GB/s超低功耗的片间互联,将两个 NVIDIA B200 Tensor Core GPU 与 NVIDIA Grace CPU 相连。
虽然Blackwell的性能提升巨大,但今天的超大规模AI模型多数都需要多GPU并联计算。由此,GPU的连接性能,才真正体现了GPU在AI大模型训练和应用过程中的价值。
第五代NVIDIA NVLink提供1.8TB/s 双向吞吐量,可以使576块GPU之间实现无缝高速通信,满足更为复杂的大语言模型训练需求。
在云端模型部署方面,英伟达还推出了NVIDIA Quantum-X800 InfiniBand 和 Spectrum-X800 以太网网络平台,提供了高达800Gb/s 的端到端吞吐量,大幅提高了AI和HPC分布式计算的可用性。
此外,英伟达还推出了6G研究云平台,以推动AI在无线接入网络 (RAN) 技术的应用。保证了端侧设备到云基础设施之间的链接,从而推动自动驾驶汽车、智能空间和沉浸式教育体验的发展。

英伟达全新网络交换机 - X800 系列。
与Blackwell架构一同宣布的,还有英伟达与主流服务器、云计算厂商的合作。AWS、戴尔、谷歌、Meta、微软、OpenAI、甲骨文、特斯拉和XAI等预计都会在未来将加速计算服务器更新到Blackwell架构。
促进落地是英伟达的当务之急
在GPU硬件方面,英伟达在全球GPU市场中持续保持领先。Blackwell的性能比2年前的Hopper架构提升了5倍,比8年前的Pascal架构提升了1000倍。
黄仁勋在演讲中自豪地说:“摩尔定律是每10年提升100倍性能,过去8年里,我们提升了1000倍,我们还少用了2年。”
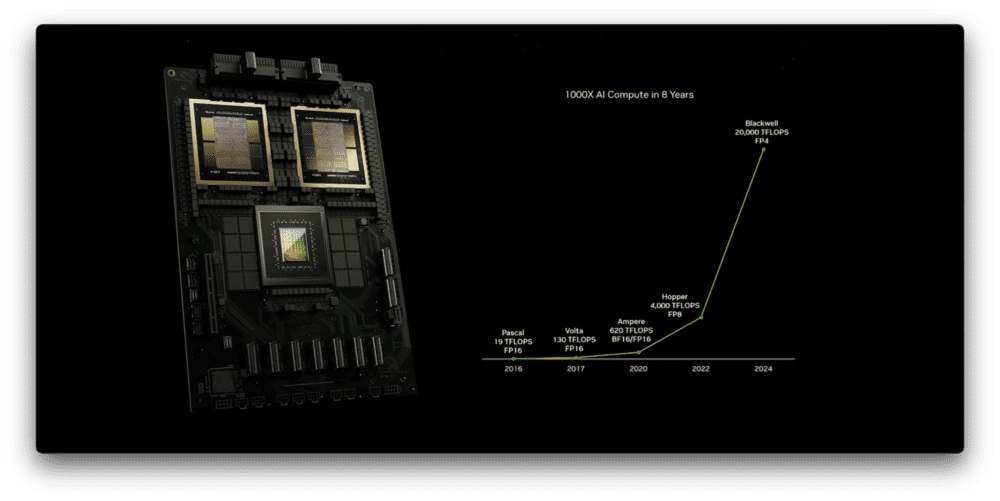
英伟达GPU性能八年提升1000倍
Blackwell一出,业界一片欢腾,很多人直呼:新摩尔定律诞生了。
相对于英伟达的用户,华尔街对英伟达的看法相对冷静。
刚刚过去的3月前几周,英伟达遭市场逼空,3月8日股价下跌5.55%。虽然华尔街对英伟达本届GTC表现乐观,市场普遍预测此次大会将帮助英伟达股票结束近期震荡走势。但是黄仁勋的主题演讲结束后,英伟达夜盘表现不佳,次日开盘股价亦未见起色。
这主要是因为GTC上公布重磅新品,对于市场来说基本都在预期之内。其实对于英伟达来说,不管是8年前的Pascal还是今天的Blackwell。1-2年一次的GPU架构的升级早已经是顺理成章的技术迭代,时至2024年,推出Blackwell在英伟达来说是一个“渐进式创新”的必然结果。
另一方面,对于如今的市场来说,随着GPU技术的迭代,算力快速增长很可能会大幅压缩英伟达的增长空间。
方舟投资首席执行官、知名投资人“木头姐”凯西·伍德(Cathie Wood)在3月7日致股东的一封信中对英伟达未来可能面临的竞争压力发出警告,并将其与思科在1997至2000年期间股价经历的“抛物线”进行比较。
伍德认为,如果AI公司、软件公司在应用层面一直见不到收益的话,很可能会停止增加在GPU建设方面的投入。
只是循序渐进地提升GPU性能,显然不能保证英伟达业务的长期增长。英伟达需要给客户提供更多围绕GPU构建业务能力的工具。英伟达大概也早就认识到了这一点。
在传统的GPU图形渲染方面,英伟达重点向客户推广工业数字孪生应用和工作流创建平台Omniverse。本次GTC,也宣布了最新的NVIDIA Omniverse Cloud API,用以帮助开发者将 Omniverse 技术集成到他们的设计和仿真工具中。
英伟达还宣布了与西门子、达索系统、Ansys、楷登软件、新思科技等主流工业软件厂商的进一步合作。
在AI方面,本次GTC上英伟达公布了一款人形机器人基础模型NVIDIA Project GR00T。可以支持通过语言、视频和人类演示来学习动作和技能,为机器人技术的 AI 应用提供了新的可能。Project GR00T与前段时间Figure推出的使用OpenAI大脑控制的机器人有些异曲同工。Project GR00T是一个多模态的人形机器人通用基础模型,可以使机器人通过观察人类行为来模仿动作,从而快速学习协调、灵活性等技能。
除此之外,英伟达一直着力打造的机器人开发和仿真环境Isaac平台此次也升级加入了生成式 AI 基础模型和仿真工具,以及针对机器人学习和操作的优化工具。