
本文来自微信公众号:远川研究所 (ID:caijingyanjiu),作者:陈彬,题图来自:Microsoft News Center
ChatGPT背后的明星企业OpenAI,始于几个硅谷极客想要“拯救人类”的疯狂念头。
2014年,特斯拉正在为产能问题焦头烂额,来中国求援的马斯克顺便做客央视《对话》栏目,遭到杨元庆灵魂拷问:2013年联想一共卖出了1.15亿台设备,特斯拉卖了几辆车?
同一时期的美国,“AI取代人类”成为了硅谷new money的关键词,这让结过3次婚、生过10个孩子的马斯克深感不安。谷歌创始人拉里·佩奇就曾批评马斯克是一个“物种主义者”,不愿用“硅”创造新物种。
2015年夏天,马斯克找到了他的知音——萨姆·阿尔特曼。
这位名字也能翻译成“奥特曼”的帅哥,是创业孵化器Y Combinator的新任掌门,也是一个标准的科技狂,拥有两家核聚变企业和一家区块链公司。
2009年,YC创始人曾在博客上分享了过去30年最有趣的5位创始人,24岁的阿尔特曼与乔布斯、谷歌创始人、赛普拉斯半导体CEO和Gmail之父并列。
在一次私人聚会上,两位明星企业家宣布掏出10亿美元,筹备一家非盈利导向的AI实验室OpenAI,“让人类以更接近于安全的方式构建真正的AI”。
在ChatGPT横空出世之前,绝大多数人都不知道这家站在人类智商密度高地上的公司做了些什么,到底花掉了多少钱。
这是一段用美元堆出来的理想主义故事。
信仰:AGI神教
OpenAI诞生的那场聚会上,马斯克几乎没有招到人。现场所有人都在追问一个问题:此时谷歌、Facebook、百度早已把世界上最顶尖的AI学者搜刮殆尽,你碰什么瓷呢?
这群野心家不肯死心,向蒙特利尔大学一位教授要来了一份10人挖角名单,上面写着圈内最有前途的年轻AI研究员。这其中最为重要的挖角对象,是一个名叫伊利亚·萨特斯基弗的俄罗斯人。
小萨是AI研究宗师杰夫·辛顿的学生。2012年,辛顿带着27岁的小萨和另一个学生发明了一个AI模型,该模型识别图像的准确率高得吓人,在学术界引起了轰动,也直接奠定了小萨产业泰斗的历史地位。
这也让谷歌等企业迅速意识到:AI终于有搞头了,直接把小萨挖走了。
OpenAI给这10人挨个打电话,所有人都表示,除非别的人都答应才入伙。为了搞定小萨一行人,OpenAI将他们骗去了当地的一个葡萄酒之乡,好生伺候了一天。最终,9个人上了“贼船”。
可就在马斯克与阿尔特曼准备召开新闻发布会时,小萨却反悔了。
为了留住小萨,谷歌先给小萨的薪资翻了一番,数字是OpenAI的两到三倍,但对方不为所动。随后,谷歌采取了另一条策略:加更多的钱。
此时的OpenAI急得像热锅上的蚂蚁,但考虑到自身囊中羞涩,只能天天发短信求小萨谈理想。直到阿尔特曼召开新闻发布会的那一天,小萨才决定加入OpenAI,从谷歌的心腹变成了心腹大患。
小萨的决定其实出于一个有些难以启齿的“理想”:他想实现AGI(通用人工智能)。
所谓AGI,即“超级智能”,接近科幻电影中万能的人工智能;与之形成对比的是人脸识别、翻译、下围棋等只能完成单一任务的人工智能。
即便2012年,杰夫·辛顿和小萨的论文让AGI的可行性跨出了一大步,但以当代的科研基础,谈论AGI,依旧就像谈论如何长生不老一样民科。
科学家all in AGI,赌赢,可以在教科书里与比肩牛顿;赌输,成为美版知乎Quaro的民科代表。
但企业all in AGI,大概只有一个结局——成为先烈。庞大的资本支出,让无论是相信“专家算法”的IBM,还是“深度学习”神教的谷歌、百度,无论信奉何种AI路线,巨头们的一切AI研究,都为产业化服务。
愿意成为这个冤大头的,只有OpenAI一家。
阿尔特曼将OpenAI打造成了一个象牙塔:在实验室成立的前15个月,OpenAI都没一个明确的研究目标。平日里,马斯克便带着这群梦想家一起脑暴,探讨AGI将如何实现。
2016年5月,时任谷歌首席AI研究员曾参观过OpenAI,对其工作方式相当困惑。他询问OpenAI的目标是什么,没想到难倒了OpenAI,“我们现在的目标,就是......做点好事[3]。”
然而在数月之后,这位研究员却毅然辞职加入了OpenAI——一起做点好事。
毕竟在当时的硅谷,“放肆做梦”是个极其稀缺的特质。哪怕是AGI曾经的布道者DeepMind,在被谷歌收购后也更实际了些。产业界与学术界的差异,促使了大批科学家的“叛逃”:从2017年开始,吴恩达、李飞飞等著名AI学者先后回归大学校园。
此般大环境下,高举理想主义大旗的OpenAI,成功抄到了历史的大底,拉拢了不少顶尖人才。
2017年3月,随着团队越来越庞大,阿尔特曼决定给OpenAI设立一个更具体的目标,这时,等待他们的是一个好消息与一个坏消息。
接盘:读作理想,写作美元
2017年是OpenAI命运的分水岭。
好消息是,谷歌帮OpenAI解决了没有具体目标的困扰。2017年,谷歌在一篇论文中开源了“Transformer神经网络架构”。它的革命性在于可以让AI“听懂人话”,而这很可能会是通往AGI的关键钥匙。
一直在做好事的OpenAI,瞬间有了攻坚的方向。
坏消息则是,没钱攻坚了。
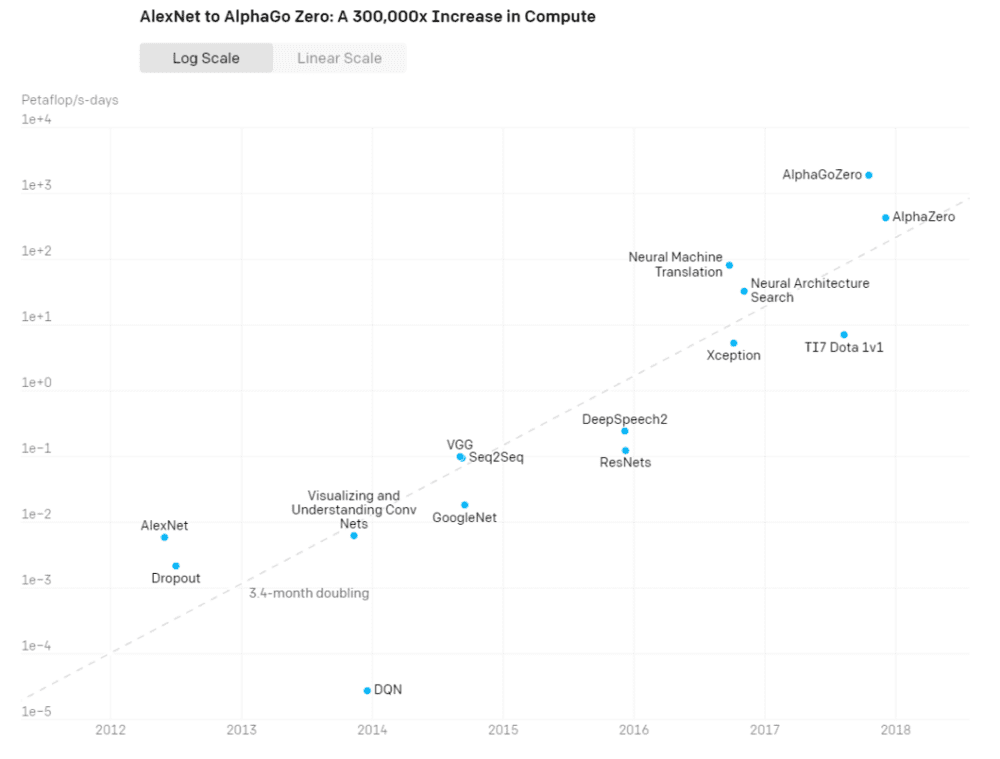
一个热知识是,如果没一个出手阔绰的靠山,根本没资格搞AI。光算力,也就是芯片的开销,就是一笔巨额成本。从2012年的AlexNet模型到2017年的AlphaGoZero,算力消耗足足翻了30万倍。同期英伟达股价翻了整整15倍,黄仁勋做梦笑醒好几回。
早些年,一大批科学家纷纷跳槽去硅谷巨头,就是为了找靠山。2010年,还在斯坦福的吴恩达研究出一套新算法,却发现大学的算力条件远远不够。他从美国东海岸找到西海岸,发现只有谷歌符合条件。
2017年,Transformer横空出世后,AI进入大模型阶段。所谓大模型,背后支撑的是大算力、大数据以及大算法,而这也意味着烧大钱。
以OpenAI的GPT-3模型为例,有机构做过测算,发现训练一个GPT-3,需要至少1024张A100显卡持续运转足足一个月[7]。而A100显卡最便宜的版本也要8769美元。
也就是说,什么还没算,就先给英伟达交了900万美元入场费,这还没算搭建机房的成本和后续源源不断的电费。
如今,ChatGPT训练一次的成本高达1000万美元,这是一般企业无法承受的。小冰公司CEO李笛算过一笔账:“如果按照ChatGPT成本来考量的话,每天我要烧3亿人民币,一年要烧1000多亿。”
回到2017年,仍是非盈利机构的OpenAI,根本无力负担这些费用。原本的大靠山马斯克也在2018年初宣布辞职,原因是避免与特斯拉AI业务有所冲突。
风雨飘摇之际,阿尔特曼悄悄修改了OpenAI“非盈利”的使命,开始给OpenAI另谋靠山。
此时,既无科研成果,又无大牛坐镇的微软,进入了阿尔特曼的视野。
作为美国高科技领域老牌列强,微软在AI上的决心不可谓不强,但长期被谷歌的DeepMind来回摩擦。
2019年,恨铁不成钢的微软遇见人才济济的OpenAI。当时,比尔·盖茨本人并不相信OpenAI会成功——投资谈判中,他很直白地对其发展路线表达了悲观,认为Transformer这类大语言模型在过去五年都没什么进展,没人知道它会有什么价值。
但话虽如此,微软还是爽快地掏出了10亿美元。
这次接盘,很可能会成为微软历史上最成功的一笔抄底。
2022年12月,OpenAI沿着Transformer路线开发出了最新款AI,名为ChatGPT。2个月后,ChatGPT的全球月活突破了1亿。
这回,该轮到谷歌睡不着觉了。
突围:难以复刻的奢侈品
ChatGPT登上热搜之后,公众常常会讨论一个问题:为什么又在美国?
事实上,复刻一个ChatGPT并非难事。ChatGPT的本质,其实以GPT-3模型为框架,通过“对话”这一场景,搭建了一个普通用户也能使用的AI应用,两者之间的技术进步并不算大。
如果翻一翻前两年的新闻能发现,早在GPT-3时代,中国公司已经在如法炮制,大可不必对各种中国版ChatGPT冷嘲热讽。在纯粹的技术层面,中国企业落后的并不太多。
我们回到一开始,大模型发展的三要素:算法、算力、数据。
算法,如同人类大脑,决定了AI的学习能力。
一个业内主流观点是,尽管没有率先做出来Transformer、GPT-3,但国内企业在大模型上的技术,距离ChatGPT的差距其实也仅在半年到两年之间。
比如GPT-3发布之后,百度、腾讯、阿里等企业诸如一言、M6、混元等十万亿参数级别的大模型也很快跟进。
算力,这意味着一种资源,决定了算法的运行效率。
AI训练高度依赖英伟达A100、H100等AI专用显卡。常见的消费级显卡通常会将部分算力让渡于光追等功能,相比之下,A100的特点则是从硬件设计到软件配套 all in AI。
尽管从2022年开始,美国已经限制英伟达向中国大陆销售A100/H100显卡,但很快英伟达也推出了A800,成为中国特供版A100平替。
数据,训练算法的优质教材,决定了AI会学到哪些知识。
站在OpenAI背后的,是一座数据富矿,即丰富的高质量英文文本数据。例如在全球最大的百科网站维基百科上,拥有最多百科文章的语言正是英文。
除此之外,英文互联网还有众多类似Github这样的专业论坛、海量的图书、学术论文、专业新闻等数据。尽管,中文互联网的文本质量有待提升,但数据总量却是碾压级别的优势。
无论是算法的调教,还是算力的堆积,本质都是砸钱砸人。在这方面,中国其实并不落后于美国。正如百米赛跑中,冠军和亚军的差距往往不到一秒钟。
然而不到一秒钟的差距,却决定了鲜花与掌声的归属,这可能也是ChatGPT和“中国版ChatGPT”的差别。
OpenAI的诞生似乎离不开无数偶然的堆积,但也有着同样多的必然。“造福人类”的AGI神教,聚集了世界上最有才华的青年AI学者;适时出现的技术突破让OpenAI的路径有迹可循,微软的出现组成了最后一块拼图。
ChatGPT的昂贵之处,既在于天文数字的投资和令人心生畏惧的烧钱速度,也在于一个能够包容疯狂想法的商业环境。正如阿尔特曼所说:
成千上万的创业公司在做社交软件,只有不到20家公司致力于核聚变。然而伟大的事情实际上更容易,因为飞向太空是每一个人的梦想。
梦想并不昂贵,但敢于梦想的勇气却是一件奢侈品。
参考资料:
[1] 深度学习革命,凯德·梅茨
[2] Why Elon Musk fears artificial intelligence,Vox
[3] SAM ALTMAN’S MANIFEST DESTINY,The NewYorker
[4] Inside OpenAI, Elon Musk's Wild Plan to Set Artificial Intelligence Free,Wired
[5] The messy, secretive reality behind OpenAI’s bid to save the world,MIT Technology Review
[6] AI的十年熬赢往事,Tech对角线
[7] 浅谈ChatGPT工作的底层逻辑
[8] How Microsoft’s Stumbles Led to Its OpenAI Alliance,The Information
[9] 中国如何缺席ChatGPT盛宴,红博士说
本文来自微信公众号:远川研究所 (ID:caijingyanjiu),作者:陈彬