
出品 | 虎嗅科技组
作者 | 齐健
编辑 | 陈伊凡
头图 | 视觉中国
OpenAI在12月1日发布的NLP(自然语言识别)新模型ChatGPT,刚刚与广大网友度过了一个愉快而又有意义的周末。
该模型是OpenAI在2020年推出的NLP预训练模型——GPT-3的衍生产品。在此之前,一直有预测OpenAI将在今年底或明年初推出GPT-4,虽然本次放出的ChatGPT被称为GPT-3.5,而不是GPT-4,但业内人士同样认为这将是对NLP以及人工智能领域有重要意义的一款模型。
ChatGPT一经发布就被OpenAI挂到官网上,接受广大网友的“检测”。 免费公测版本的服务器很快被热情的测试用户挤爆了。
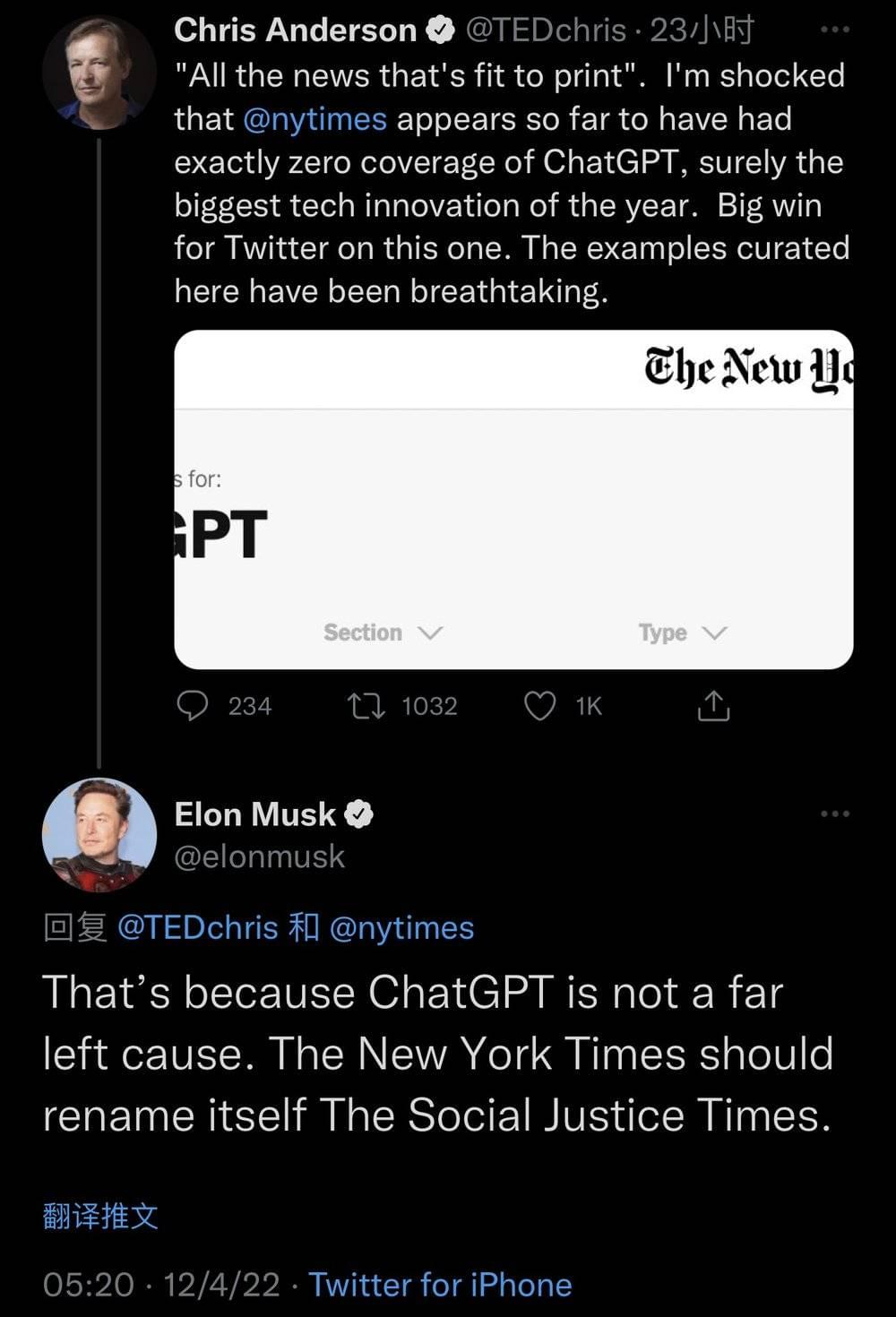
一时间,针对ChatGPT的调戏、探讨、询问、闲聊贴刷屏了Twitter和朋友圈。周末没有跟踪ChatGPT新闻的“纽约时报”甚至遭到了已离开OpenAI的创始人马斯克发推奚落。
ChatGPT有多厉害?
GPT-3目前的能力已经接近人类,甚至超过人类了。
ChatGPT模型看起来比以往的人机对话模型更强大,例如,其敢于质疑不正确的前提和假设、主动承认错误以及一些无法回答的问题、主动给拒绝不合理的问题、提升了对用户意图的理解以及结果的准确性。与之前的GPT3不同,相比于此前海量学习数据进行训练,ChatGPT中,人对结果的反馈成为了AI学习过程中的一部分。
ChatGPT 使用监督微调训练了一个初始模型:人类 AI 训练员提供对话,他们在对话中扮演双方——用户和 AI 助手,AI 训练员可以访问模型编写的对话回复,以帮助 AI 调整回复内容。
为了创建强化学习的奖励模型,该研究需要收集比较数据,其中包含两个或多个按质量排序的模型回复。该研究收集了 AI 训练员与聊天机器人的对话,并随机选择一条模型编写的消息,抽取几个备选回复,让 AI 训练员对这些回复进行排名。此外,该研究还使用近端策略优化算法(PPO)微调模型,并对整个过程进行了数次迭代。
目前已经有网友尝试让ChatGPT参加美国高考;诱骗ChatGPT规划如何毁灭世界;甚至让ChatGPT扮演OpenAI,在系统内构建ChatGPT套娃。



更多新功能还在持续等待网友开发中……
这么好玩的东西不会只是拿来玩的吧?
在网友排队“调戏”AI的同时,ChatGPT商业落地问题亦成为产业界关心的话题。
ChatGPT或将衍生出一批强大的NLP商业应用。一位人工智能行业专家告诉虎嗅,通用大模型的普及预计会在3-5年内实现,人工智能将很快替代简单重复劳动,甚至是一些流程性的技术岗位,比如翻译、新闻简讯编辑等。通用大模型很可能会在短时间内改变现在生产和生活的很多方式,大量基础性的工作流程会被基于大模型的智能应用渗透甚至取代。
那么代表着最新AI训练趋势的ChatGPT,在商业化方面有可能面临哪些挑战呢?
多位业内人士向虎嗅表示,今天的ChatGPT距离实际落地还有一段距离。其中最为核心的问题,在于模型的准确性和部署成本。
首先,ChatGPT的回答并不能保证准确性,这对需要准确回答具体问题的商业应用来说是致命伤。这也是ChatGPT要在C端大规模推广,所需要面临的挑战。一些业内人士担心,如果AI输出虚假信息的速度太快,可能会在互联网中淹没真实信息,甚至对整个社会产生误导。
这样的担心不无道理,也并非没有先例。Meta早些时候推出的一款大型科学预言模型Galactica,就因为回答问题过于“放飞自我”,在网上输出了大量凭空捏造的虚假内容,仅上线三天就匆匆下架了。
ChatGPT也并不能避免这个问题,OpenAI的科学家John Schulman在此前接受采访时曾表示,他们在解决AI编造事实的问题上取得了一些进展,但还远远不够。
商业化考虑的另一个问题就是经济性。ChatGPT目前尚处在免费的测试阶段,眼前最接近实际的应用场景是搜索引擎优化、营销媒体内容创作辅助和开发者编程。
由于,ChatGPT现在还处在一个优化迭代的阶段,目前开放的公测应该也是希望搜集大众使用的反馈对模型持续改进。OpenAI首席执行官Sam Altman曾提到过,OpenAI未来的重点更新功能之一,是对ChatGPT生成的内容提供Citation。
GPT-3参数量达到1750亿,在2020年6月发布之后, OpenAI开始尝试对GPT-3进行商业化。目前OpenAI以API的形式向开发者客户有偿提供GPT-3模型,并根据token使用量来收费。其客户包括传媒、营销等多个领域,基于GPT-3产生的App达300多个。
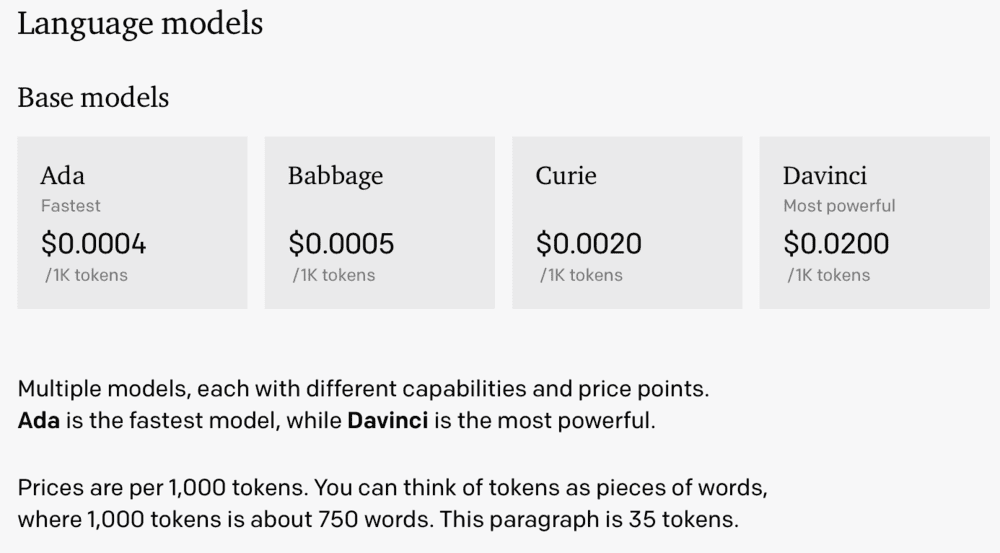

训练阶段的沉没成本过高,也导致人工智能应用早期很难从商业角度量化价值,也就是算不好“经济账”。随着算力的不断提高、场景的增多、翻倍的成本和能耗,将成为横梗在所有公司面前的问题。尽管OpenAI的估值目前为200亿美元,但此前亦有观点认为OpenAI应该是一家万亿估值的公司,而这家公司目前阶段主要产品和技术仍停留在实验阶段。
尽管很多小规模的预训练模型在今天的人机对话领域已经有很多成功的商业应用,但像ChatGPT这样大规模的模型,在To B领域中部署的难度很高,部署速度慢、成本高,商业价值也不明确,因此仅能停留在搜索、文化、娱乐等应用领域。
容联云AI科学院院长刘杰对虎嗅表示,To B行业对人工智能要求更严肃、严谨,目前的人机对话内容主要集中在客服、外呼、营销等领域,需要有针对的模型库,利用BERT(预训练的语言表征模型)基础上的UniLM框架等规模小一些的模型进行快速训练。
刘杰认为,包括ChatGPT在内的NLP,在商业化上还处在一个螺旋上升的阶段,未来应用场景很广,但当下技术和商业模式还需要尽快找到一个“共振”的频率。
不过,也有很多人认为ChatGPT未来的应用领域未必局限在人机对话,可能会扩展到更多应用领域,例如程序问题的识别和搜索引擎等。只是不论是哪一点,其都无法避免那些商业化的难题。
依托云厂商生长
数据是一切AI算法、AI模型的原料。
依附于云厂商,显然是一种聪明的做法,原料越丰富,做出来的菜色更多样。
2019年,OpenAI收到来自微软的10亿美元投资,此后一直与微软保持紧密合作。ChatGPT和GPT 3.5的训练也都是基于微软的Azure AI的超算基础设施完成的。
凭借着大规模通用AI模型在实际应用中对算力的需求,Azure AI可以利用ChatGPT秀一波肌肉。
去年11月,微软宣布,OpenAI的GPT-3将通过新的Azure OpenAI服务提供给开发人员。大幅加强了微软在NLP方面的技术能力。OpenAI的直接竞争对手DeepMind则在2014年被谷歌母公司Alphabet收购。谷歌和DeepMind合作的主要项目之一,是后者开发的人工智能推荐系统,这也大大提高了谷歌数据中心的效率。
微软和谷歌在与顶级人工智能研究实验室的合作中收获颇丰,而在这方面亚马逊的AWS可能已经落后于另外两家云业务不那么出众的竞争对手。Gartner于2021年3月发布的关于云人工智能的Magic Quadrant报告发现,AWS远远落后于微软、谷歌和IBM等竞争对手。
不过,在人工智能研究方面,AWS在2017年也推出了自己的机器学习解决方案实验室,提供机器学习专业知识,用于识别和构建识别AWS客户端的机器学习解决方案。在今年9月还推出了一款据说在机器学习任务上表现优于GPT-3的seq2seq模型AlexaTM 20B。
人工智能发展的瓶颈
一位在人工智能领域耕耘多年的业内人士告诉虎嗅,人工智能领域一直以来面临的瓶颈是建立在基础理论之上的,对于算法和架构的突破——大家习惯了用筷子夹丸子,但有没有想过,可能用签子串,效率更高。90年代末期,正在攻读博士的他就经历了一次AI的浪潮,过去40年,发生在AI产业上有三次浪潮,每一次都是由于理论发展的瓶颈最终退潮。
另一个瓶颈是伦理道德。一提到人工智能的伦理道德问题,多数人会想到自动驾驶定责等严重的问题,一位人工智能领域投资人向虎嗅指出,如今自动驾驶的技术走在了法律法规的前面。而如今,随着生成式AI的逐步成熟,AIGC的版权以及AI的价值观问题都成了制约人工智能发展的大问题。
在人类与AI交流的过程中,AI如何学习,能否输出正确的价值观?
大规模训练部分取决于数据的质量,AI无法主观判断什么是正确的,所以AI很容易“学坏”。虽然ChatGPT在“防骗”方面有了很大进步,但它仍然会在“不怀好意”的围观群众诱导下表达出一些不那么“政治正确”的观点,这可能会是通用AI模型商业化的阻力之一。