
像一个人的学习成长一样,每个全新的大模型,都需要从大量的文本中学习 “知识”,才有能力去解决一个个问题。
Google 训练 70 亿参数的 Gemma 开源模型,让它 “看过” 6 万亿 Token(6 万亿个词)的文本。微软投资的 Mistral 训练 73 亿参数模型,“看过” 8 万亿个 Token 的文本。
用如此大规模的数据训练参数不到 100 亿的模型,已经是行业中比较重的方法。按照 DeepMind 研究人员提出的策略,如果考虑性价比,这么大的模型,看 2000 亿 Token 的文本就够了。不少中国一线创业公司的同等规模大模型只用了 1 万亿~2 万亿个 Token 的文本。
Meta 的 CEO 马克·扎克伯格(Mark Zuckerberg)不满足于此,他直接把下一代开源大模型送进了 “县中”,用更多习题拔高能力。Meta 昨夜推出的 Llama 3 系列大模型,80 亿参数模型用了 15 万亿 Token 的训练数据,比 Google 的多学了一倍还不止,是很多小公司产品的十倍。
根据 Meta 公布的数据,在 5 个常用大模型能力评估测试集上,它新发布的 80 亿参数模型和 700 亿参数模型,得分基本都比同级竞争对手高。尤其是 80 亿参数的 Llama 3,各项评测得分大幅超过 Google 和 Mistral 开发的同级别模型,数学、编程能力翻倍。Meta 称它们是目前 “功能最强大的、公开可用的大模型”。
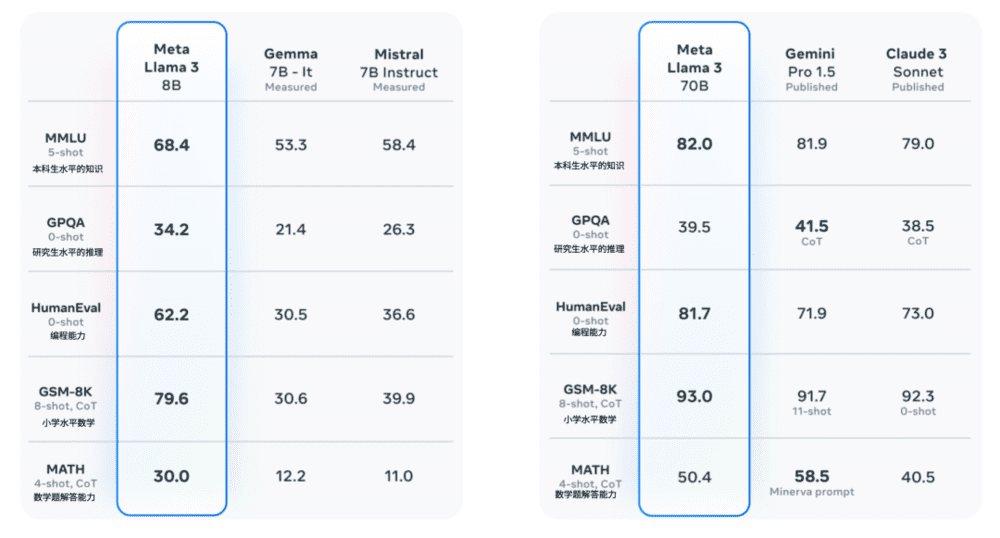
Llama 3 在部分测试数据集上得分超过竞争对手。图片来自 Meta。
Meta 透露,他们还在训练 4050 亿参数的大模型,初步评测得分达到 GPT-4 水平。这则消息帮 Llama 3 获得大量关注。英伟达高级研究经理 Jim Fan 说,Meta 让开源社区得到 GPT-4 级别的大模型会是一个行业分水岭,将改变许多研究工作和创业公司的经营状况。
OpenAI 原资深研究科学家安德烈·卡帕蒂(Andrej Karpathy)认为,80 亿参数的 Llama 3 “会非常受欢迎”,效果接近参数更多的 GPT-3.5,而且需要的算力低、反应快,甚至可以在手机、电脑上本地运行,“希望大家继承这个趋势,训练和发布用更长时间训练更小的模型。”
打破 Scaling Laws:用超出行业预期的数据和算力训练模型
2020 年初,OpenAI 提出大模型的 Scaling Laws,认为在 Transformer 架构中,要提升大模型的效果,需要按照特定比例提高训练大模型的数据量、模型本身的参数以及算力。
这个规律在 OpenAI 随后发布的 GPT-3 中得到验证,他们调整这几个元素的配比,以更低的成本训练出更强的模型。
OpenAI 的接连成功,让 Scaling Laws 成为许多研究者训练大模型的关键指引。按照他们发现的规律,其他训练条件不变,大模型参数每提升 5.3 倍,训练数据量需要提升约 1.9 倍、算力提升 10 倍,是最有性价比的方案。
2022 年,DeepMind 的研究者发布论文,认为这个比例不对,低估了训练数据量的要求。他们认为,算力提高 10 倍,模型参数和训练数据量各提升约 3 倍才更有性价比。DeepMind 的新比例取得更好的效果,成为从业者训练大模型的重要参考。
现在,Meta 又进一步提高训练数据的重要性。根据 Meta 公布的信息,他们训练 80 亿参数的 Llama 3 时,把训练数据提到 15 万亿 Token,是 DeepMind 方案估算的 75 倍,发现模型能力达到 700 亿参数 Llama 2 的水平,大幅超过竞争对手。
Meta 为此付出更多算力——用 H100 训练了 130 万个小时,算力成本预计超过 100 万美元。如果用 5000 张 H100 组成的集群计算,需要不间断训练大概 11 天。而在 Meta 只需要 2 天多,因为它有 2.4 万张 H100 组成的算力集群。而且有两个。
一场小模型竞赛正在进行
根据 Meta 的说法,当前版本的 Llama 3 还没有达到性能极限。“我们一直使用的大语言模型,明显缺乏训练。(训练数据量)可能需要提高 100~1000 倍,甚至更多。” 安德烈·卡帕蒂说。
OpenAI 用 GPT-3.5 和 GPT-4 证明大模型的实力后,许多公司加速追赶的同时,也在研究如何用更低的成本利用大模型。
与传统的软件应用不同,大模型不仅开发起来费钱,运行起来(推理)也会消耗大量算力资源。大模型想要处理用户输入问题,基本要挨个处理文字中的每个字,处理 100 个字的问题,基本就要运行 100 遍大模型。
英伟达把它当作 GPU 销量增长的空间,但对于想用大模型改造业务、创造新商业机会的公司,却是负担。发布 Llama 3 时,Meta 宣布把它整合到旗下每天有数十亿人使用的 Instagram、Facebook 等产品中,如果用参数较大的模型,推理成本根本无法承受。
想要降低成本,最直接的方法是训练参数更小的模型,让用户的手机、电脑直接在本地运行,分担平台的压力。
怎么让更小的模型有更好的效果,成了大模型公司们的竞争焦点。过去一年,Google 每次发布大模型,都会推出参数较小的模型。Anthropic 发布 Claude 3 系列时也采用类似的做法。不过它们没有详细公布小模型的参数,以及如何让小模型有更好的能力。
根据 The Information 报道,微软选择利用 GPT-4 生成高质量数据,训练更小的模型,以降低部署大模型应用的成本。
Meta 训练 Llama 3 的方法截然不同,但最适合它。为了应对 TikTok 的竞争,Meta 在 2022 年采购了大量 H100,用于训练更强的内容推荐模型,为它奠定算力优势。
为了训练 Llama 3,Meta 动用了两个 2.4 万张 H100 组成的训练集群,今年计划把 H100 数量推到 35 万张——每张 30000 美元。大部分互联网巨头也只有数万张 H100,而且不少还会对外出租。
Meta 接下来大概率会沿着相同的方向,继续做更小的模型。“80 亿参数的模型,对于很多场景来说还不够小。” 扎克伯格接受采访时说,“我很想看到一个 10 亿参数,甚至 5 亿参数的模型,看我们能用它做些什么。”
本文来自微信公众号:晚点LatePost (ID:postlate),作者:贺乾明,编辑:黄俊杰