
OpenAI 的 GPT-4 发布一年后,终于有了一个评测指标全面超越它的大模型。
3 月 4 日,Anthropic 发布三个版本的大模型系列 Claude 3,性能由强到弱分别是:Opus(拉丁语 “作品”)、Sonnet(英语 “十四行诗”)和 Haiku(日语 “俳句” 的音译)。
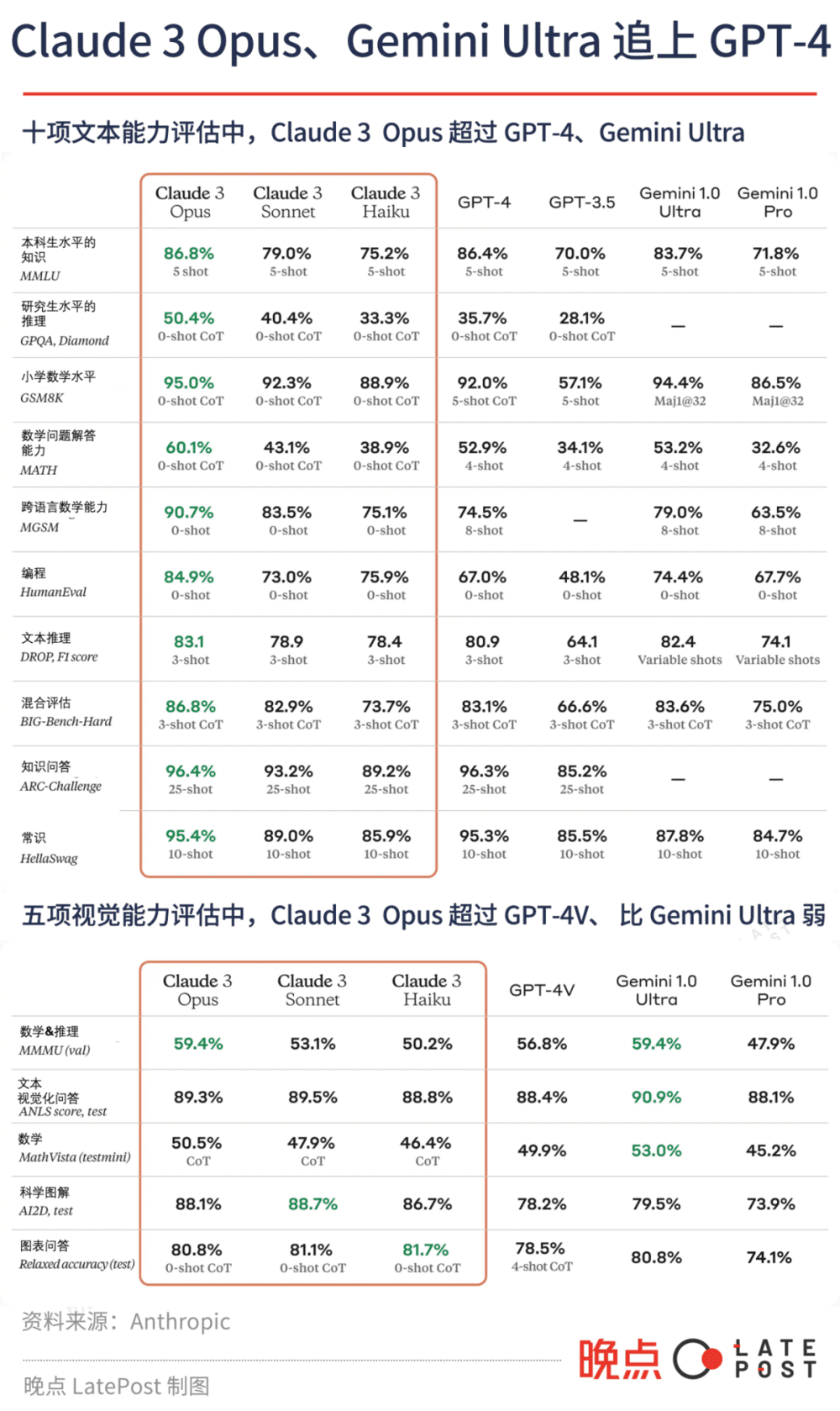
Anthropic 列出的十项常用模型能力评估数据集表明,Opus 得分全都超过 GPT-4,视觉识别能力评估数据集上的情况也一样。
Claude 3 的另两款模型智能水平不及 Opus,但用起来更便宜,适用于需要快速响应的场景,比如 Haiku 可以 3 秒阅读 1 万字的论文。Anthropic 没有公布两个模型的参数,也没有提及是否能用在手机上。
从部分开发者的测评反馈来看,Opus 的能力似乎与 GPT-4 接近。有一些开发者用 Opus 的视觉识别能力打扑克牌、麻将,还赢了几把。
Google 上个月发布的 Gemini Ultra 版本大语言模型被认为在技术上追平了 GPT-4,但很快陷入 “政治不正确”泥潭。Anthropic 出现类似问题的概率更低——它比大多数公司都更看重大模型的“普世价值观”。
相比 Google,Anthropic 的模型追上 GPT-4 给 OpenAI 的冲击更大。与 OpenAI 相比,它用的时间和资源更少。Anthropic 称,大模型还没有达到极限,他们计划未来几个月内密集更新 Claude 3 模型系列。
最熟悉 OpenAI 的团队
Anthropic 的模型赶上 GPT-4 并不只靠堆砌资源,他们本就是熟悉 OpenAI 技术路线的团队。成立于 2021 年的 Anthropic,早期的团队成员全部来自 OpenAI,他们具备开发一款大模型需要的不同能力。
Anthropic 联合创始人、CEO 达里奥·阿莫代(Dario Amodei)在 OpenAI 工作了 5 年,离职前担任研发副总裁,参与了 GPT-2、GPT-3 的研究。最初 OpenAI 尝试用多种方法探索 AI 的可能性,比如游戏、机械手。是阿莫代和 OpenAI 首席科学家伊利亚·苏茨克维尔(Ilya Sutskever)一起确定了 OpenAI 专注研究大语言模型的方向。
另一位联合创始人萨姆·麦坎利什(Sam McCandlish)在 OpenAI 负责研究如何扩展大模型,是大模型规模定律(Scaling Law)的核心作者。
Scaling Law 被称为大模型成功的关键之一。它可以较为准确地预测,随着大模型参数增长,模型的训练效率、能力上限会到什么程度,从而帮研究者更好地设计模型架构、分配训练模型的资源等。
此外,团队中还有负责 GPT-3 训练基础设施的汤姆·布朗(Tom Brown)、参与数据处理的本杰明·曼恩(Benjamin Mann)、参与算法研究的尼古拉斯·约瑟夫(Nicholas Joseph)等人。
Anthropic 因此也被称为最有可能与 OpenAI 竞争的公司。创立两年后,Anthropic 迅速补齐了开发大模型所需的资源。截至 2023 年底,Anthropic 从亚马逊、Google、Salesforce 等投资者手中筹集了 70 多亿美元,融资规模仅次于 OpenAI。
这些投资人不只为 Anthropic 提供资金,还为他们提供了稀缺的算力资源,Claude 3 就是用 AWS 和 Google 的云计算平台的硬件训练出来的。
重点研究 RLHF,追求安全带来性能提升
Anthropic 与 OpenAI 最大的分歧是如何让大模型更安全。根据多家媒体报道,达里奥·阿莫代等人 2020 年底离开 OpenAI 是因为不满公司更偏重盈利,而降低了大模型安全研究的优先级。当时正值 OpenAI 发布 GPT-3 的 API,准备加快商业化节奏。
在 Anthropic 看来,他们的目标是开发一个“有用、诚实、无害”的大模型,而且无害的重要性不比有用低。
去年 7 月,《纽约时报》的专栏作家凯文·罗斯(Kevin Roose)去 Anthropic 采访多位工程师,发现大多数人都更愿意谈自己对人工智能的恐惧,还有人因此失眠。“我感觉自己像一个美食作家,去报道一家时尚的新餐厅,而厨房的工作人员只想谈食物中毒。”
对安全的关注,让 Anthropic 投入大量资源研究基于人类反馈的强化学习(RLHF)技术。
训练一个大模型需要预训练(pre-training)和精调(fine-tuning)两个步骤,前者是用庞大数据训练出初版的大模型,它不针对具体任务。精调是给模型一些具体任务的数据,提升模型的效果,也会调整模型的价值观以跟设计者保持一致。
RLHF 是一种精调大模型的方法,现在被证明是提升模型能力的关键。RLHF 的具体做法是,模型开发者招募大量人类标注员,让他们写出回答来教大模型什么是人类想要的答案,还会对大模型反馈的不同答案评分,告诉它哪个更好,让机器按人类的反馈改进。
去年发布 GPT-4 时,OpenAI 称,与 GPT-3.5 相比,仅经过预训练的 GPT-4 在回答事实性测试题时表现没什么改进,但经过 RLHF 训练后,其评估得分提升了 40%。
Anthropic 对 RLHF 的研究走得更远。他们在一篇论文中提到,因为 RLHF 训练环节靠人评估,而人会偏向符合自己预期的答案,所以会导致大模型出现阿谀奉承的情况,即反馈的答案迎合人类需求,但不一定正确。
在 RLHF 的基础上,Anthropic 开发出 “宪法式人工智能”(Constitutional AI)来解决这些问题。Anthropic 在技术文档中写道,“宪法式人工智能” 是他们训练 Claude 3 的关键步骤。
用普通人为 AI 设立 “价值观”
在最近这次新模型发布前几天,Anthropic 联合创始人丹妮拉·阿莫代(Daniela Amodei)在一次访谈中再次提到 RLHF 和他们重点研究的 “宪法式人工智能” 的差异。“RLHF 在改变模型行为方面相当有效,但很难调整模型深层次的一些反应和信念。”她说,“所以我们想赋予模型一种更广泛的‘宪法’,就像在人类社会里的那些基本原则,让模型知道哪些行动和参与社会的方式是好的。”
Anthropic 在一篇介绍“宪法式人工智能”的公告中写道:“无论有意无意,AI 模型会形成自己的价值体系。”他们比其他大模型创业公司花更多精力研究人类社会,试图将一些跨越国界、种族的“基本共识”用于培养 AI 的价值观。
Anthropic 撰写给 AI 模型的初版“宪法”中,有几条原则来自 1948 年出版的联合国人权宣言,另有几条原则受到苹果公司服务条款的启发,补充回应 1948 年人类还没遇到的数据隐私问题。“宪法”还包括 Anthropic 训练模型时总结的,以及 DeepMind 等其他前沿 AI 实验室确立的价值观。Anthropic 声称他们也试图“鼓励模型考虑不仅仅来自西方、富人阶层或工业化文化的价值观和观点。”
2023 年 10 月,Anthropic 公布了“宪法式人工智能”的最新成果,把这个有关“基本共识”的研究延伸成一场更广泛的公民实践。他们邀请约 1000 位美国公民协助他们制定大语言模型回答问题时的原则。
这 1000 多位参与者中,近 400 人年龄在 50 岁以上,还有约 100 位超过 70 岁——总是中青年在主导科技前沿浪潮,老年人在其中近乎隐形,Anthropic 的样本选择或将减少年龄带来的偏见。
Anthropic 在这次研究的报告中总结,这次公开征集的原则比 Anthropic 团队的原始版本更注重大模型回应时的“客观性和公正性”,如新增的原则“选择最平衡客观信息、反映事情各方面的回应”“选择对残障人士最包容、适应、友善和灵活的回应。”一些人类自己还在争论不休的价值观不会纳入新准则,如 AI 到底该优先考虑集体利益还是优先考虑个人的责任和自由。这项研究最终确定了 75 条原则——其中有四成是在本次研究中新增的——用于后续的模型训练。
在达里奥·阿莫代的设想中,想把 Anthropic 的理念变成现实,最有效的方法就是自己研发出领先行业的大模型,这样才能理解先进的大模型会遇到什么问题,从而找出解决办法。
研发出更安全的大模型后,他也不打算延续 OpenAI 最初的愿景——靠开放、开源让更多人用上好的 AI。
Anthropic 成立至今,都没有详细公布 Claude 系列模型是具体如何训练出来的,也不打算开源。他们认为,如果没有做好充分的保护措施,开源大模型会导致滥用。
在曾经普遍拥抱开源的硅谷 AI 界,今天模型产品技术最领先的三个团队 OpenAI、Google DeepMind、Anthropic 都带着类似的自负走向另一个方向:AI 是个危险的技术,不能开源开放,必须商业化运营。毕竟,只有自己才靠得住。
本文来自微信公众号:晚点LatePost (ID:postlate),作者:贺乾明、朱丽琨,编辑:黄俊杰