
“读书破万卷,下笔如有神。”这一古语在现代大模型的训练过程中有了更为清晰的诠释。在足够多的训练数据基础上,AI在诸多任务上已获得了比肩人类的表现。为了方便理解,一种观点将大模型拟人化,认为大模型也与人类一样,拥有记忆,甚至拥有相似的记忆模式和机制。然而,正如不应简单将飞机类比为铁鸟,人类记忆从产生到提取的过程,都与基于上下文预测下一个词的语言模型有着本质的区别。
不过,对人类记忆的研究为我们理解大型模型的记忆机制提供了一个出发点。人类记忆分为长期记忆和短期记忆(又称工作记忆)。对于大型模型而言,其“长期记忆”存储在模型的亿万参数中,短期记忆则体现为模型一次对话中可回忆起的上下文长度的context。例如GPT-4的context是128k,这相当于可一次性输入10万汉字左右。
但这种类比真的有效吗?大语言模型与人类记忆有何异同?我们又该如何借助人类的记忆机制解决大模型应用尝试中所遇到的问题?
一、大模型的长期记忆与人类的相似
对任何动物而言,其大脑功能都只是为了在进化的无情筛选中胜出。作为交流工具的语言也并不例外。在语言中,诸如语法结构、递归嵌套等复杂特征,探究其最底层的目的,仍在于更高效、准确地完成沟通。既如此,在一般情况下,语言就不必追求完美无缺。对于经过人类强化调整过的大模型,其本质同样是概率的、随机的。于是可以通过调整温度(用于调整模型生成时文本创作和多样性的超参数)这一参数,让模型的输出看起来更具有创造性。
就记忆而言,大模型与人类一样,呈现出首因效应和近因效应 [1],尤其是当需要记忆的事实更多时(图1)。
首因效应:primary effect,即先入为主,记忆时对第一印象念念不忘;
近因效应:recency effect,即对事物的最近一次接触给人留下深刻的感知或认知。
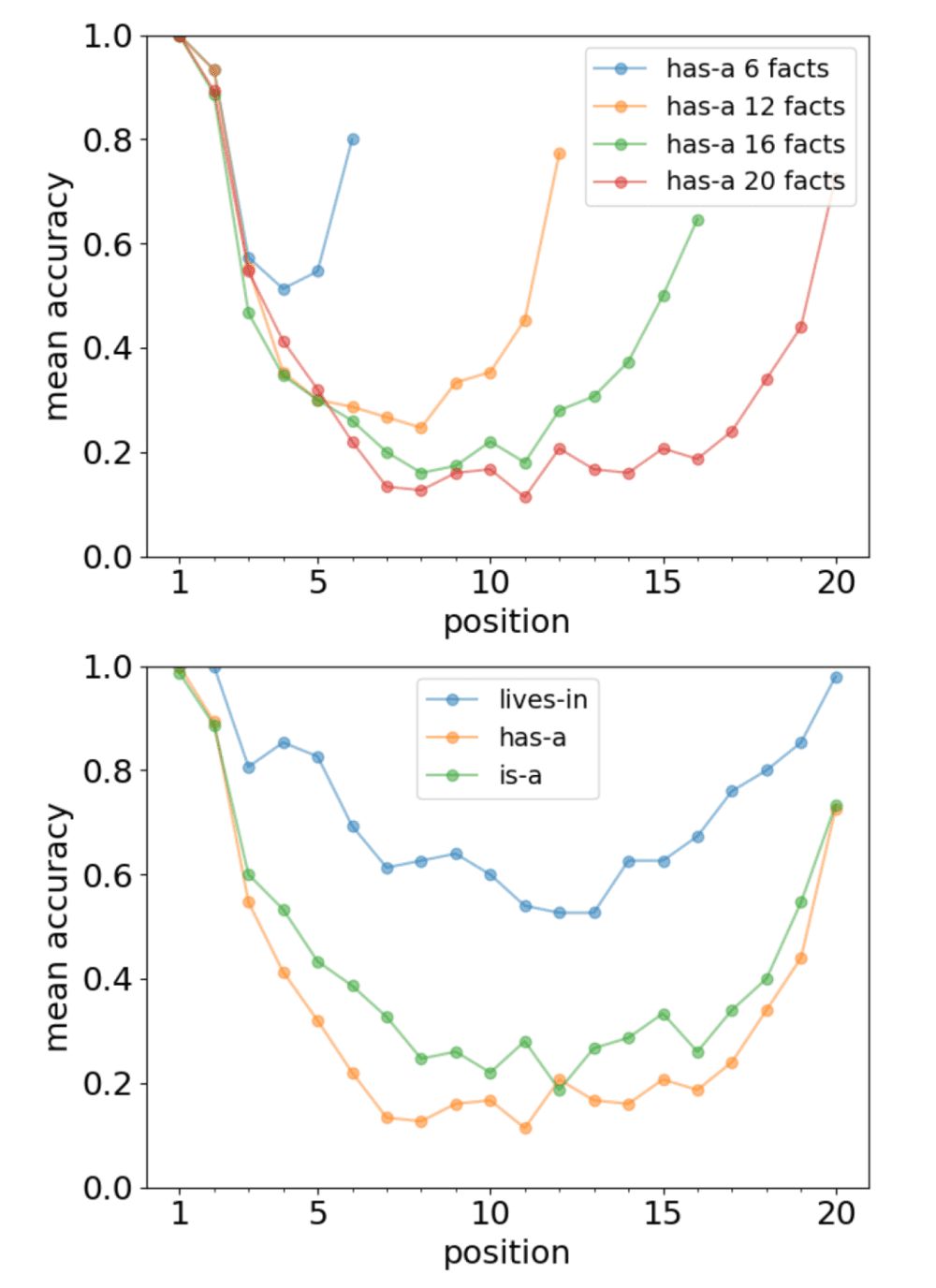
▷图1:大模型的预测准确性随词汇而呈现先下降再上升,与人类记忆类似。图源:参考文献1
这一性质是模型大小达到一定阈值之后出现的涌现特征(图2),而当模型参数只有70M时,模型实际上无法预测更远的单词,所以也不会出现首因效应。
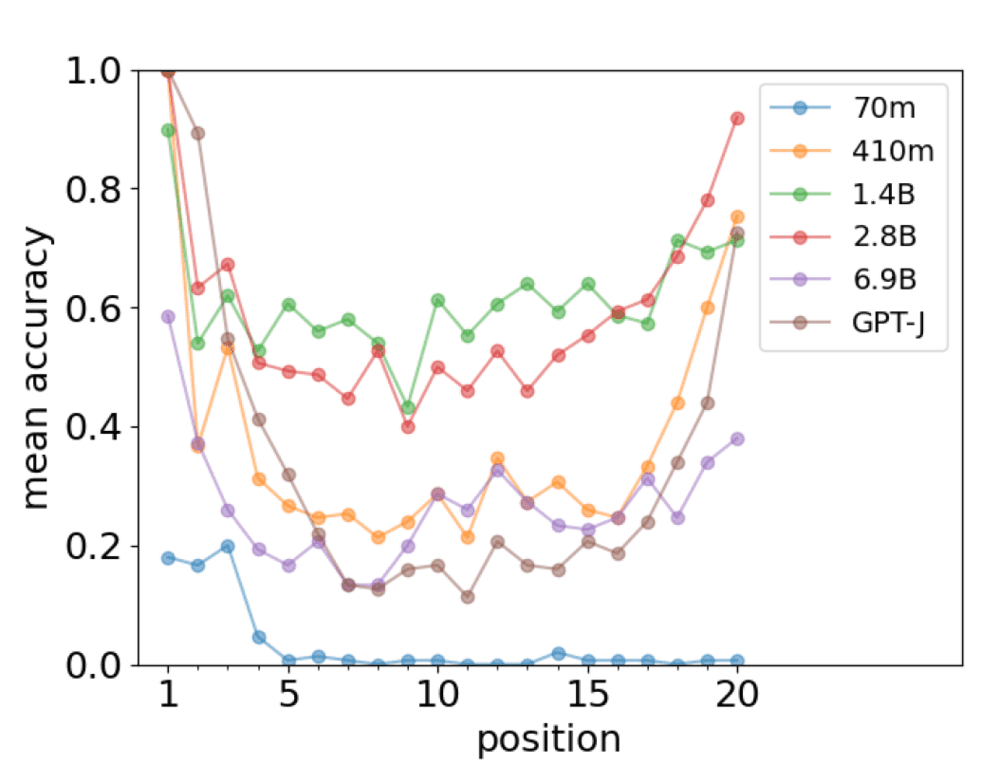
▷图2:不同参数大小的模型在预测不同位置单词时的准确性。图源:参考文献1
在学习过程中,人类可以通过重复来提升记忆效果,这一现象在大模型中也会出现(图3)。此外,相比于直接重复待学习的内容,将内容更改顺序后重复学习,模型的训练效果还会有所提升。
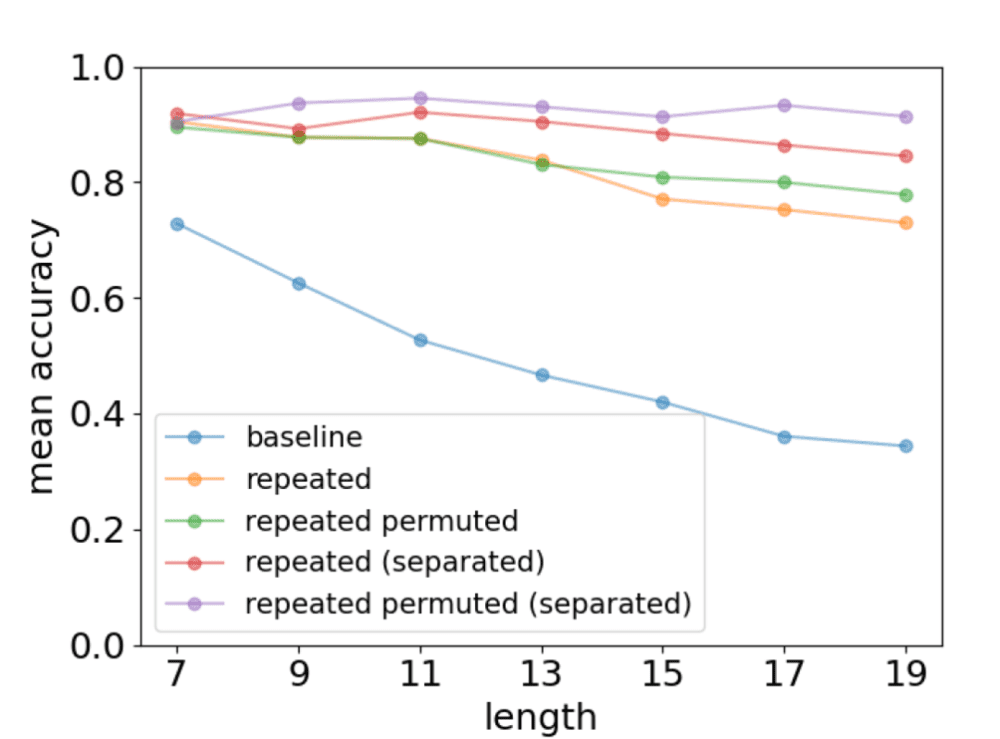
▷图3:对比模型在面对重复内容时的预测准确性。图源:参考文献1
当人类在面对相互矛盾的事实时,记忆会出现差错,这意味着遗忘的原因不在于记忆随时间衰减,而在于记忆产生时存在干扰。大模型在面对相互冲突的事实时,也会有类似的表现,当冲突越具体(例如冲突来自于同一个人而非不同国家的人),记忆的差错就越明显(图4)。
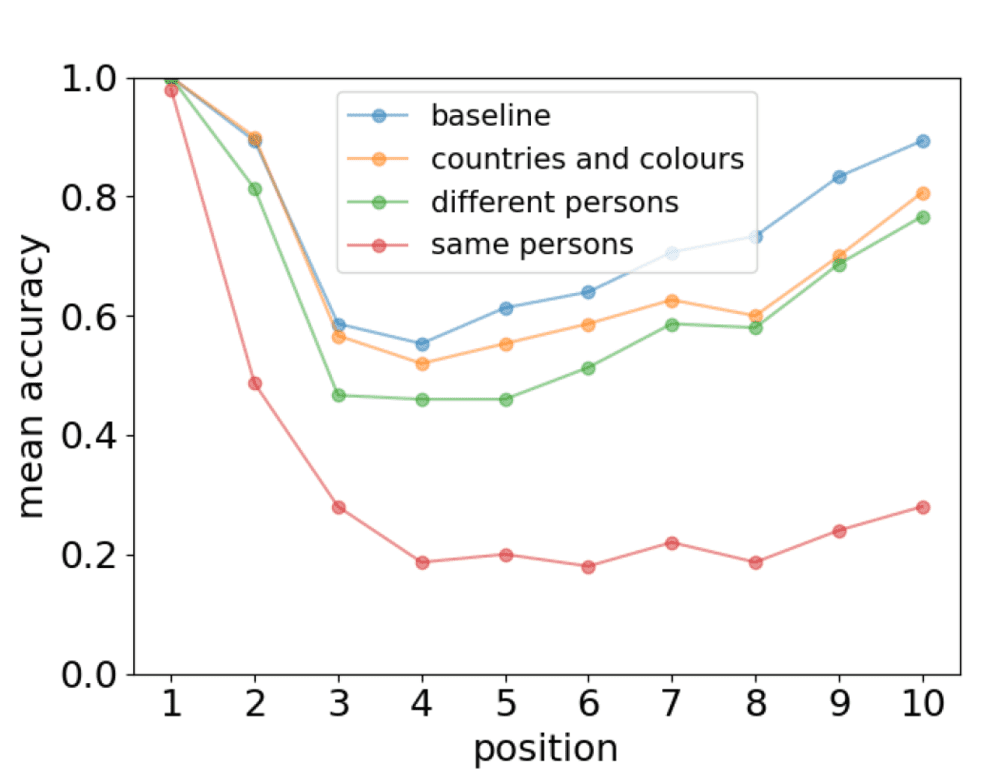
▷图4:在加入不同类型的干扰信息后,大模型的预测准确性显著下降。图源:参考文献1
此外,加拿大认知心理学家托尔文(Endel Tulving)认为,记忆的存储和读取是两个相互独立的过程,这一点也适合大模型,其训练和推理过程中使用的机制截然不同。托尔文将长期记忆进一步分为陈述性记忆和程序性记忆,其中陈述性记忆包括语义记忆和情景记忆。
对于大模型来说,语义记忆对应于模型通过预训练或微调过程积累的知识库,这些知识隐式地存储在其参数中。与此同时,情景记忆的对应体现在模型处理或生成文本时,依赖于特定上下文信息的能力上。然而,当生成全新内容时,所需激活的是类似于程序性记忆的能力,这超越了单纯的情景记忆。[4]
尽管在训练过程中,大模型主要涉及显式的情景记忆的应用,程序性记忆并未显著涉及。在推理过程中,大型语言模型利用输入的上下文信息来引用先前的对话或与当前语境相关的数据,这一过程可以被视为对情景记忆的模拟调用。
这表明,尽管大模型在训练过程中主要处理与特定实例相关的显式信息,它们仍能通过处理与之前交互相关的上下文信息,展现出一种类似于人类情景记忆的能力。进一步地,有研究者认为,当模型接收到足够详细和具体的上下文信息时,它能够“激活”更复杂的行为模式,类似于人类的程序性记忆,从而展现出因果推断、心智模拟等高级涌现能力。
虽然大模型和人脑在特定表现上呈现出相似性,但这并不代表两者也有着相似的信息处理机制。实际上,对于大模型为何会表现出这样的特征,学界目前也还没有明确的结论。例如上述研究中,我们并不清楚如果只考虑大模型最上层的参数,能否重现诸如首因效应的特征,也不清楚限定上下文的范围时,模型的表现是否会改变。或许通过受限的大模型,可以更进一步定位大模型与人类记忆相似的模块,从而有助于对此现象给予解释。
二、大模型通过“外挂”增加记忆容量
理解记忆的对于拓展大模型的能力至关重要。正如解决数学难题时在草稿纸上记录步骤可增强我们的工作记忆一样,为大模型引入“记忆外挂”技术,可以帮助模型显著提升其工作记忆。
例如,通过TiM系统应用,让大模型在每次回答问题之前,都对外部的存储空间进行一定处理,包括插入、遗忘和合并(见图6)。这样,大模型在应对多轮对话或问题时,可以更有效地处理并回忆上下文信息,准确检索出所需信息。类似的方式还包括递归式生成场景记忆[6],该方法可视作让大模型在每一轮回答完问题后,总结前一轮问题包含的上下文,将其放入外置记忆中,从而避免大模型在多轮对话时忘记前几次谈话中的内容。
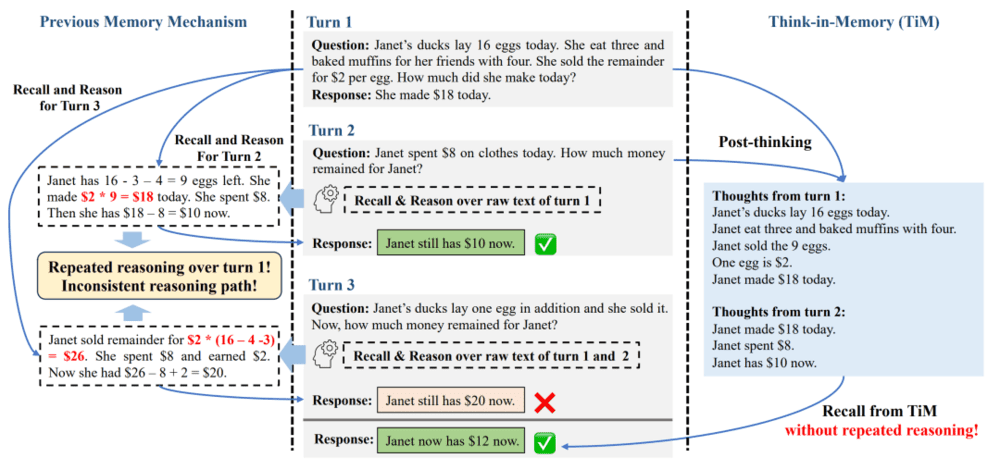
▷图6:对比大模型传统的记忆与新提出的TiM在回答问题时的表现。图源:参考文献5
为了解决长文本处理的挑战,2023年在NIPS上发表的一篇论文提出了一种名为LongMem的方法[7]。这项技术应对的问题不是多轮对话,而是一次处理一个长文本。通过将长文本切分成多个部分,每部分由固定的大模型独立处理,随后通过一个可训练的残差网络综合各部分信息,根据提问的具体内容选择最相关的部分进行回答。这样,LongMem可以让大模型更准确地提取信息。
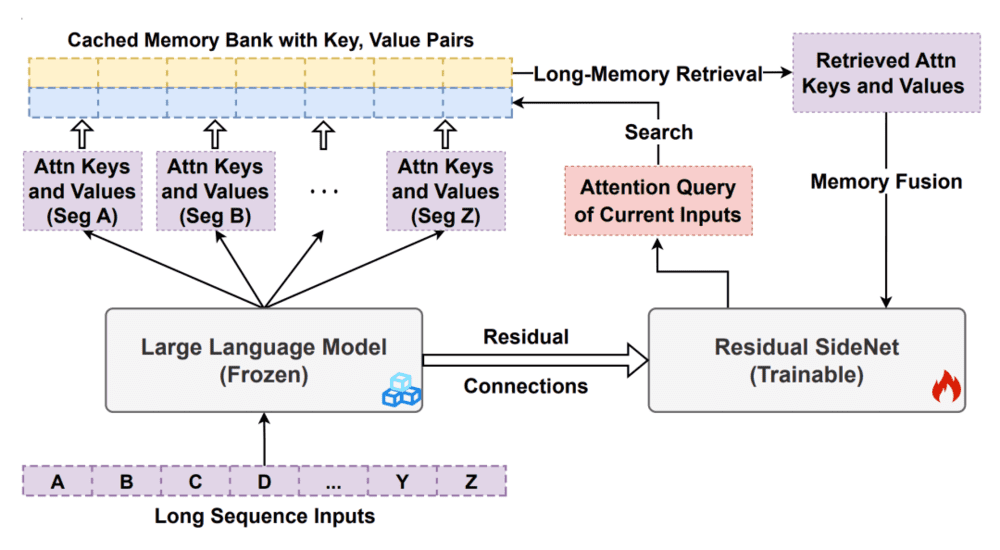
▷图7:LongMem机制的运作流程示意图。图源:参考文献7
在机器人控制问题上,应用大模型同样需要给其配上记忆模块[8],这一类模型被称为具身AI。在机器人控制任务中,具身AI的“眼睛”通过处理视觉传感器的输入来产生周围环境的语言描述,之后其“神经Nerve”结合机器人的自身动作,生成以第一人称为中心的状态信息描述。这些信息随后被编码并存储于一个高级的语言处理系统中,即所谓的“大脑”。同时这个大脑还可根据导航任务,产生控制指令。
这样的运作方式,能够实现机器人与人经由自然语言的直接互动,还可利用大模型中存储的海量常识,来识别和适应环境变化,例如某些东西是有生命会运动的,我需要避开它。这样构建的机器人,就会在导航时“意识到”眼前的猫尽管趴着不动,也可能会在自己靠近后避开。这类具身AI的基础,就在于生成、存储及更新关于自身状态的记忆模型。
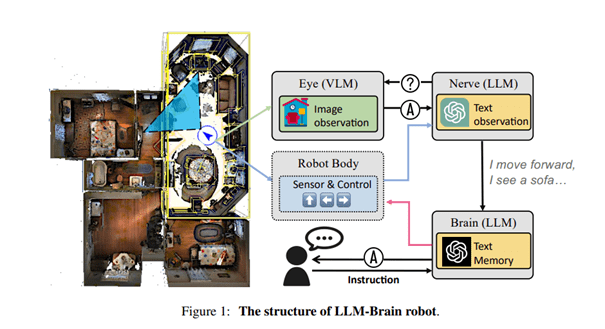
▷图8:LLM-Brain具身AI的架构。图源:参考文献8
另一个应用大模型加记忆的例子来自于搜索场景。研究者提出名为CoPS[9]的架构,其由三个部分组成:外部记忆模块存储用户的搜索记录和行为,之后交由大模型来推断搜索用户的意图及背景,并基于推断的个人档案对传统搜索引擎给出的链接进行重现排序,从而使搜索引擎给出的结果更加个性化。
由于利用了预训练的大模型,CoPS可以进行零尝试学习,即不需要招募测试用户,收集用户数据及反馈,就可以利用大模型中的知识提升搜索的准确性。
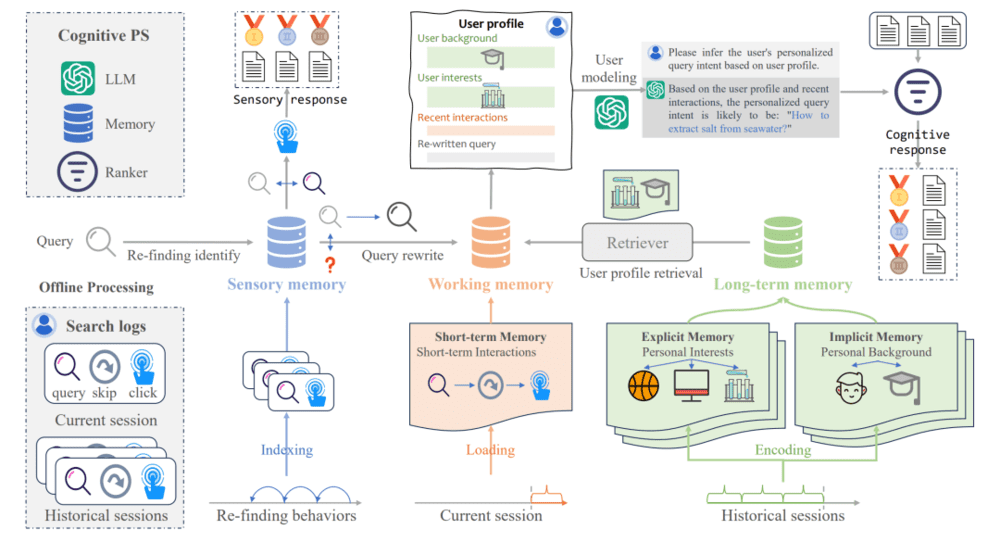
▷图9:CoPS架构。图源:参考文献9
通过向大模型增加外部记忆来拓展大模型的应用范围,其还有众多案例。研究表明[10],在被赋予可读写的关联性外部记忆后,当前Transformer架构的语言模型在计算上可被视作“通用图灵机”。这意味着,这些模型不仅能够处理有限长度的输入字符串,还能够模拟任何算法,处理任意大小的输入。
三、大模型的“幻觉”无需克服
认知科学家莉莎·费德曼·巴瑞特(Lisa Feldman Bartlett)指出:“记忆不是简单地重新激活无数固定的、毫无生趣的、细碎的痕迹,而是一种富有想象力的重构或者构建。”这一描述似乎对大模型也颇为适合。
理解了生物记忆的不完美,我们也许不该再将大模型的“幻觉”视为一种需要克服的顽疾,而是将其视作一种内生的、不可避免的涌现特征。就如《红楼梦》中贾宝玉所言,“古来杜撰的多了,偏我杜撰不得”。
事实上,《红楼梦》的作者也践行了笔下人物的话,在书中杜撰了多个典故。可这丝毫不会影响《红楼梦》的伟大。一旦我们将大模型的幻觉视作记忆生成过程中的副产品,就不应当在大模型自身的框架内试图消除“幻觉”,而应通过外部记忆的方式解决幻觉在特定场景下带来的问题。甚至,还可以将“幻觉”视作通向AGI过程中遇到的山谷,需要先设法让模型增加幻觉,从而促进模型的创造力。
虽然无论对于大模型还是人脑,我们目前都没有完全理解其记忆的运作机制。不过,神经科学研究中有着对记忆的多种分类方式,这或许提醒了大模型开发者,不应只采用一种记忆模式。通过在大模型外部增加显式的记忆,可以显著提升大模型在长文本,以及多轮对话中的表现,同时扩展大模型的应用场景。这给只想通过简单扩大模型规模以卷出更好模型的开发者,提出了另一条更为经济且资源节省的优化路径。
在神经科学中,记忆是相互竞争的,这样的动态特征意味着记忆的提取、更新、强化与遗忘应当在同一框架下被审视。而在当今的大模型中,记忆的产生和读取是相互独立的。大模型不会由于反复读取某段记忆就更新对其的存储,而人类每次读取长期记忆都是一次生成式的往日再现,反复读写之后,最初的原始记忆就可能发生改变,这也是之后大模型和记忆相关研究者需要注意的差异。
参考文献:
[1] https://arxiv.org/abs/2311.03839
[2] https://arxiv.org/ftp/arxiv/papers/2309/2309.01660.pdf
[3] https://arxiv.org/abs/2402.15052
[4] https://arxiv.org/pdf/2401.02509.pdf
[5] https://arxiv.org/pdf/2311.08719.pdf
[6] https://arxiv.org/pdf/2308.15022.pdf
[7] https://arxiv.org/pdf/2306.07174.pdf
[8] https://arxiv.org/pdf/2304.09349v1.pdf
[9] https://arxiv.org/pdf/2402.10548.pdf
[10] https://arxiv.org/abs/2301.04589
本文来自微信公众号:追问nextquestion (ID:gh_2414d982daee),作者:郭瑞东,编辑:存源、邵文