
相信你或多或少对GPT有一定的了解,但我赌你没听说过bGPT。bGPT的意思是byte GPT,即字节GPT。
Meta 近日披露了两个新的 GPU 集群,将用于训练下一代生成式人工智能模型,包括即将推出的 Llama 3,以及 GenAI 和其他领域的人工智能研究与开发。新的集群在硬件、网络、存储、设计、性能和软件等方面进行了定制优化。
Meta 公布的两个 GPU 集群 GPU 总共拥有49152块 GPU,每个集群都装配了 H100 GPU,而 Meta 此前 AI 研究超级集群(RSC)GPU 集群约有16000块 A100 GPU 。RSC 在 Llama 和 Llama 2 的开发以及计算机视觉、NLP、语音识别、图像生成、编程等人工智能模型的开发中发挥了重要作用。
PyTorch 创始人,Meta 工程师 Soumith Chintala 在 X 上分享了关于 Llama 3 的一些细节:使用了 RoCEv2 网络,基于 Tectonic/Hammerspace 的 NFS/FUSE 网络存储,标准版本的 PyTorch,带有一些补丁的 NCCL:补丁和交换机优化使集群具有相当高的网络带宽实现,各种调试和队列监控工具,例如 NCCL 异步调试、内存行重新映射检测等。
Meta 表示,将使用新的 GPU 集群来微调现有的人工智能系统,并训练更强大的新系统,包括 Llama 3。此外,Meta 还透露正在对 PyTorch 人工智能框架进行升级,为支持更大规模的 GPU 训练需求做准备。
一、在算力军备的路上越走越远
新的 GPU 集群是 Meta AGI 路线图的一部分,目标是到 2024 年底,基础设施建设将包括350000块 NVIDIA H100 GPU,计算能力相当于将近600000块 H100 GPU。作为对比,OpenAI 训练 GPT-4,用了大约25000块 A100 GPU。而训练 GPT-5 预估需要30000块到50000块 A100。
要保持在 AI 领域的领先地位,意味着对基础设施的大量投资,对于 Meta 来说,军备还远未结束。根据市调机构 Omdia 发布的报告,Meta 在 2023 年买了超过 15 万块 NVIDIA GPU,与之相当的只有微软,而亚马逊、甲骨文、谷歌、腾讯等都只拿到了 5 万块左右。
2024 年 Meta 预计将购买超过 35 万块英伟达 H100 GPU,H100 售价为 2.5 万至 3 万美元(不考虑溢价),如果 Meta 支付的是较低的价格区间,那么将支付给英伟达接近 90 亿美元。
在 Dot-com 泡沫时代,任何人都可以以相对较低的基础设施成本启动一个网站,个人开发者和初创企业能够借助普及的智能设备和移动网络,在不同成本的范围内推出产品和业务。而现在,似乎只有那些互联网巨头和明星创业公司才能构建 AI 模型。
所有这些公司都从投资者那里拿钱,然后再把钱交给云计算公司和英伟达,这或许就是为什么英伟达的股价在如此短时间内超过 2 万亿美元的原因之一。
二、更多架构细节
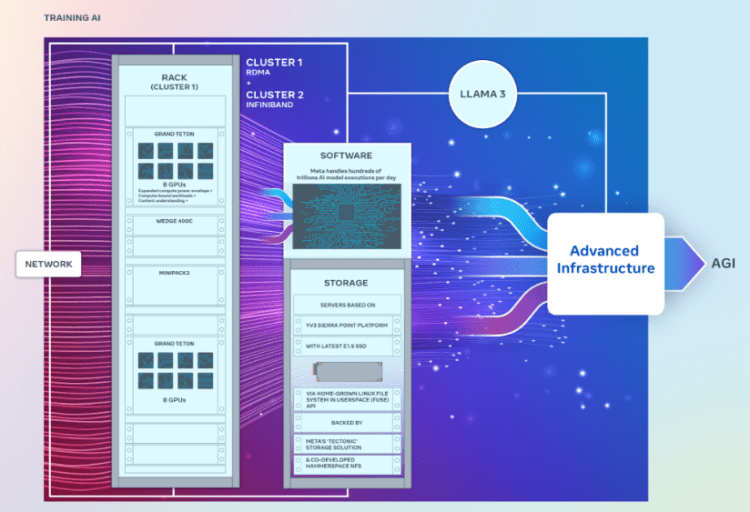
关于这两个 GPU 集群的具体架构细节,虽然这两个集群的 GPU 数量相同,通过 400Gbps 端点相互连接,但采用了不同的架构设计。网络方面,其中一个集群采用了一个集群采用了具有融合以太网远程直接内存访问(RDMA)(RoCE)网络结构解决方案,另一个则使用了 Nvidia 的网络架构技术 Quantum2 InfiniBand。

这两个集群均采用 Meta 的开源 GPU 硬件平台 Grand Teton 构建,该平台专为支持大规模AI工作负载而设计。据称,Grand Teton 的主机到 GPU 带宽是前代 Zion-EX 平台的四倍,计算和数据网络带宽是两倍,功率需求也是两倍。
Meta 表示,这些集群整合了其最新的 Open Rack 电源和机架基础架构架构,旨在为数据中心设计提供更大的灵活性。根据工程师们的说法,Open Rack v3 允许电源架可安装在机架的任何位置,而不是固定在母线上,从而实现更灵活的配置。
存储在 AI 训练中起着重要作用,尤其是处理大量的图像、视频和文本数据的多模态训练任务。存储方面,Meta 新集群使用自主开发的“Tectonic”分布式闪存存储解决方案满足数据和检查点需求,并与 Hammerspace 合作部署并行网络文件系统,解决了数千个 GPU 数据和检查点的需求。提高开发体验。
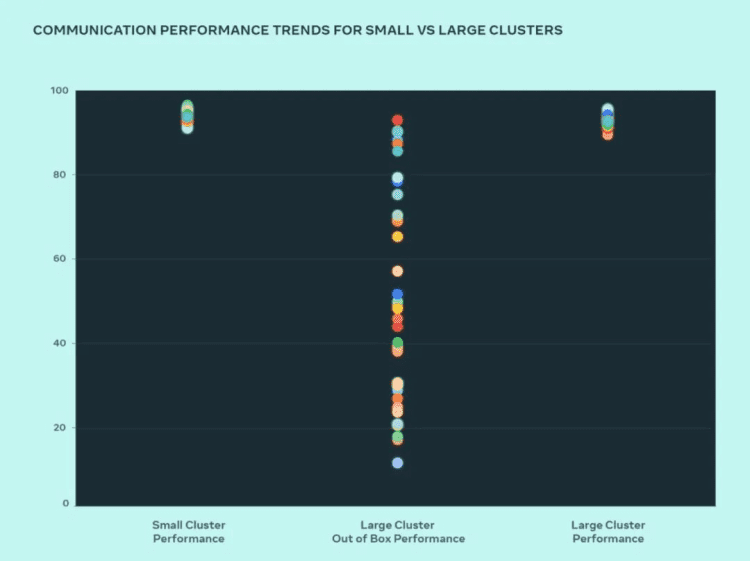
性能方面,Meta 建立大规模AI集群的原则是同时最大化性能和易用性,通过优化内部作业调度器和网络路由策略,以及与 NVIDIA 集体通信库(NCCL)的改进,提高了大型集群的性能,实现了与小型集群相同的优秀性能。
在实际测试过程中,Meta 比较了小型集群和大型集群的性能,以发现瓶颈所在。在上图表中,展示了大量 GPU 在预期的屋顶线性能消息大小下相互通信时的 AllGather 集体性能(以0~100的标准化带宽表示)。
大型集群的开箱即用性能最初很差且不一致。为了解决这个问题,Meta 对内部作业调度器如何根据网络拓扑感知调度作业进行了多项改进,这在减少网络上层流量方面带来了延迟上的好处。

Meta 还提到,公司将继续全力支持在人工智能硬件技术栈方面的开放创新,Meta 强调了对开放式计算和开源技术,新的集群均基于 Grand Teton、OpenRack 和 PyTorch 等平台构建而成。
三、离 Llama 3 更进一步
在 AI 领域,Meta 去年推出了大型语言模型 Llama 2、定制芯片 MTIA、文生图广告工具以及聊天机器人Meta AI 。
其中,Llama 2 的发布以及开源可商用是开源模型社区的里程碑,扎克伯格曾表示,虽然 Llama 2 不是行业领先的模型,但它是最好的开源模型,而 Llama 3 及以后的版本的目标是构建处于行业领先地位的模型。
根据 The Information 的报道,Meta 计划于 7 月发布 Llama 3,可能达到超 1400 亿参数,比 Llama 2 模型的最高参数翻了一倍。据内部人士透露,Llama 3 相对于 GPT-4、Gemini 和 Llama 2,放宽对安全限制的设定,即所谓的“安全围栏”。
这意味着在处理具有争议性的问题时,Llama 3 旨在提供更好的回答。Meta 的这一举措显然是希望至少能够提供有关用户查询的相关上下文,而不是简单地忽略或拒绝回答用户提出的问题。简而言之,目的是提升用户体验,通过提供更多信息,而不是简单地限制对话。
新的基础设施,更多的 GPU 储备,扎克伯格 All in AGI 似乎比投入元宇宙更靠谱,股价也迎来上涨,招聘 AI 人才时也可以底气更足地说自己是“GPU RICH”,看上去一切都走上了正轨。

只不过还是没躲过美国网友的无情(无脑)吐槽:“堆了这么多算力,为啥在 IG Reels 上刷短视频还是比不上 TikTok ?”
参考链接:https://engineering.fb.com/2024/03/12/data-center-engineering/building-metas-genai-infrastructure/
本文来自微信公众号:硅星GenAI(ID:gh_e06235300f0d),作者:周一笑