
上周扎克伯格把Meta AI聊天机器人向公众开放了。
用户可以在WhatsApp、Instagram、Facebook等Meta系社交软件上以搜索或聊天助手的方式召唤它。不过目前只能输入文本来生成答案和图片,除了一批明星角色定制机器人,并没什么其他太出彩的地方,也就没引起太大的社区反响。
不过有个人却第一时间破防,并把Meta狠狠阴阳了一把。
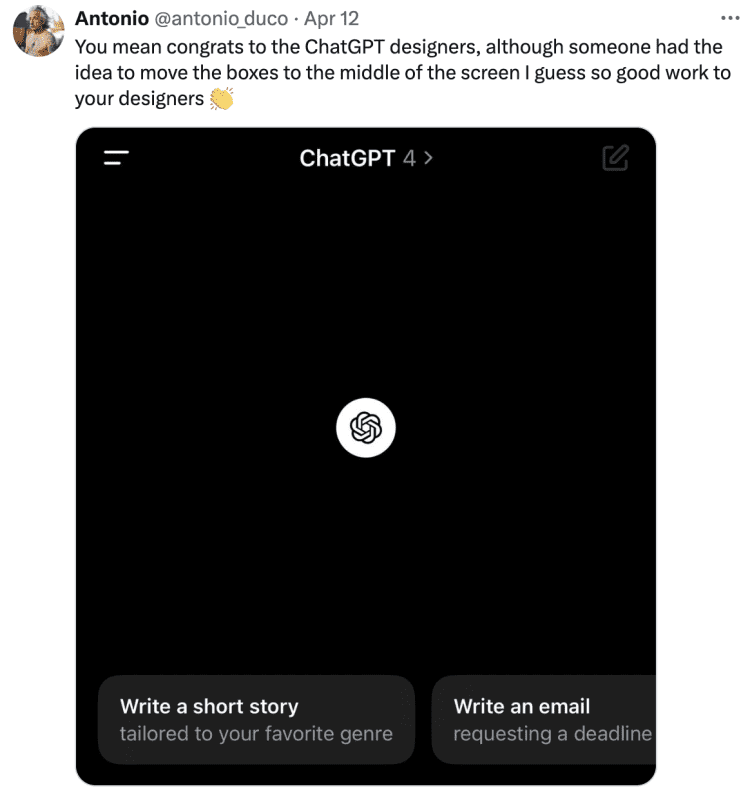
此人便是Perplexity的CEO Aravind Srinivas。4月12号他忽然在X平台发文,致敬自己公司的设计师,配图却是Meta AI的聊天界面。
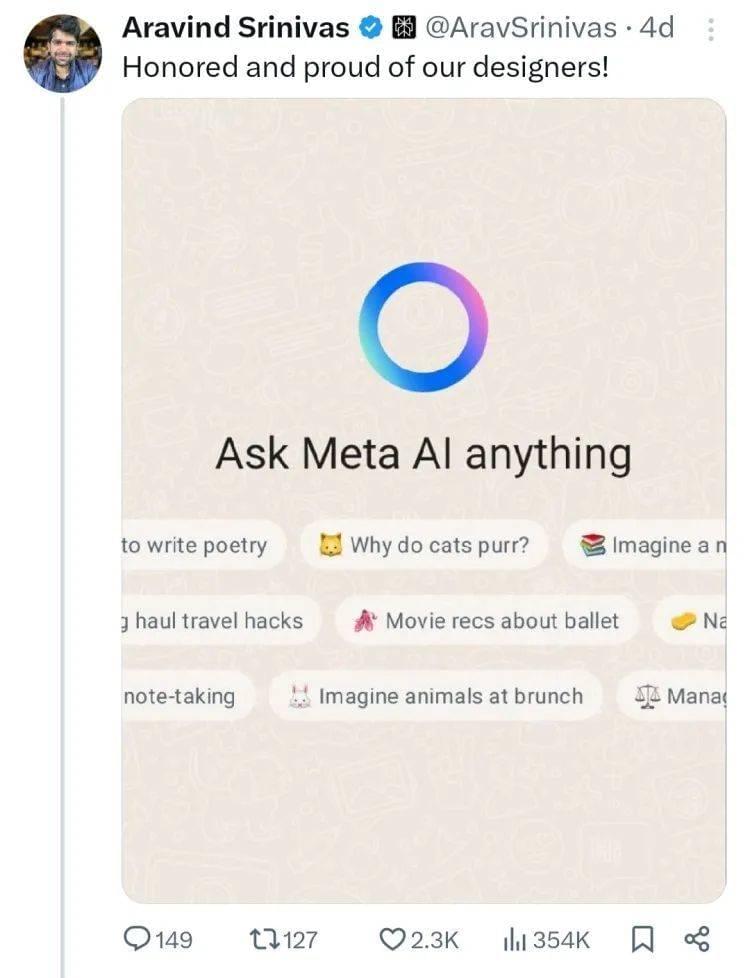
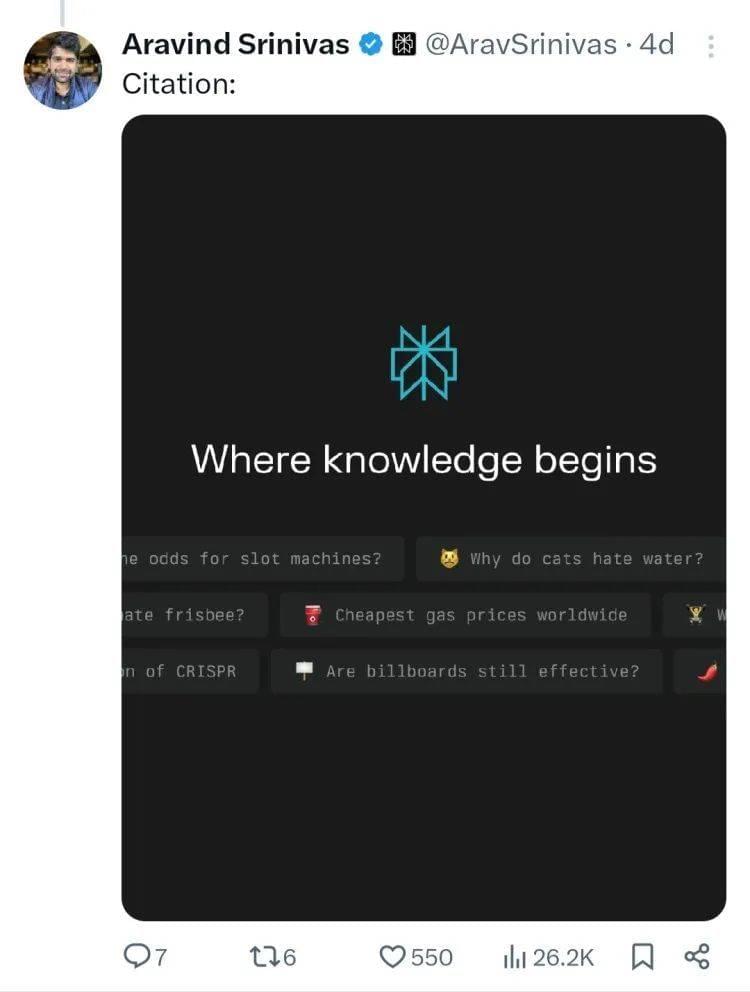
这是干啥?Aravind Srinivas紧接着用“引用源”加上Perplexity的界面截图解释:暗指Meta AI从醒目logo、标语,到加了表情包的灵感问题提示、整体页面设计全都“抄袭”了自家产品。
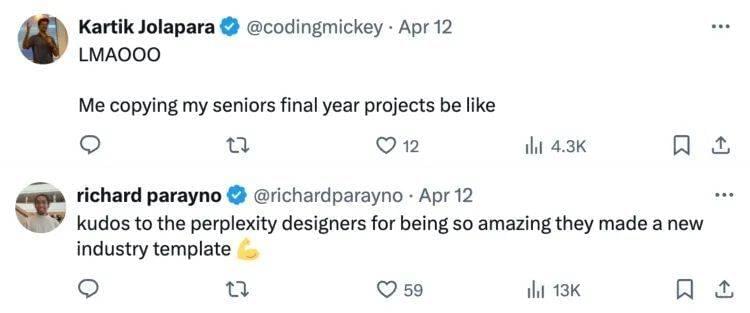
对此,评论区意见分成了两派,有的说小扎确实是能靠抄别人的东西拿奥斯卡奖。

“就跟我抄高年级的期末作业一样”“恭喜perplexity的设计师创造了新的行业模版”。
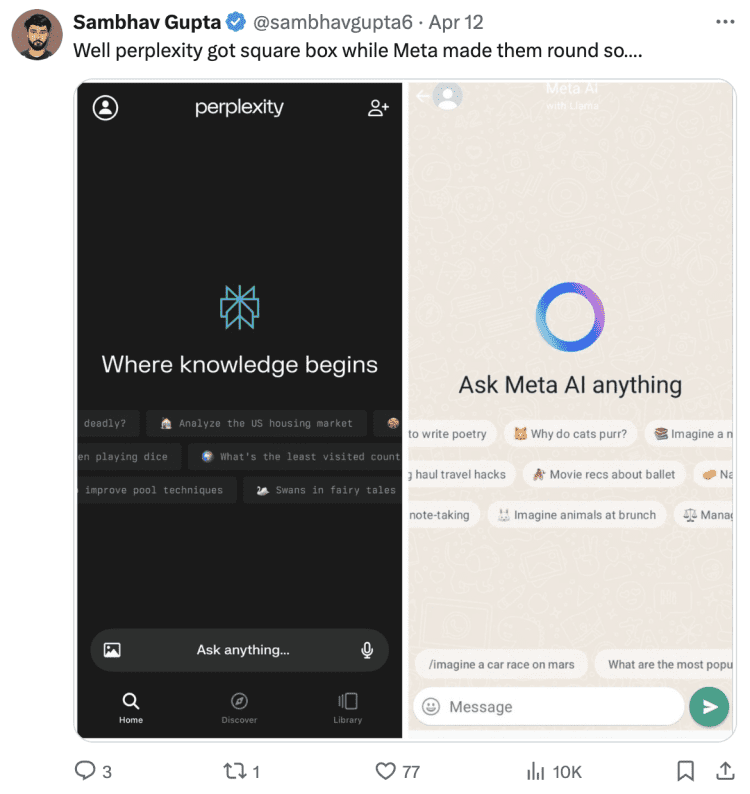
另外一些网友却认为这有点牵强了,“那你要这么说,Perplexity形状是方的,meta是圆弧的……”
有人也阴阳了回去:“你是说致敬ChatGPT的设计师吧?尽管Perplexity想出来把提示问题移到屏幕中间的好点子,还是恭喜你们了。”
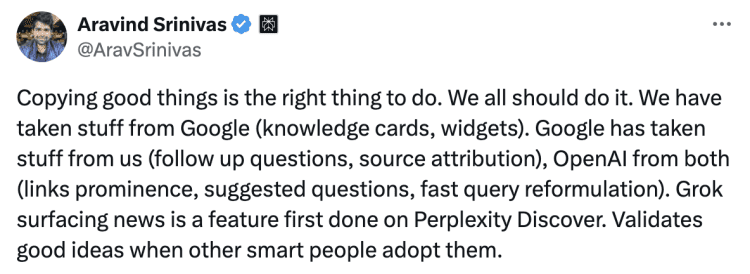
Aravind Srinivas那边似乎并不服气,凌晨四点又继续发文说:
“抄袭好东西是正确的做法。我们都应该这样做。我们从Google那里借鉴了一些东西(知识卡、组件)。Google也从我们这儿借鉴了一些东西(后续问题、来源归属),OpenAI则从双方那里都借鉴了(突出链接、提供建议问题、快速查询重构)。Grok拿走了在Perplexity Discover上首次实现的新闻曝光功能。当被其他聪明的人采用时,恰恰证实了这些想法是好的。”
配图是左边的Grok和右边的perplexity:
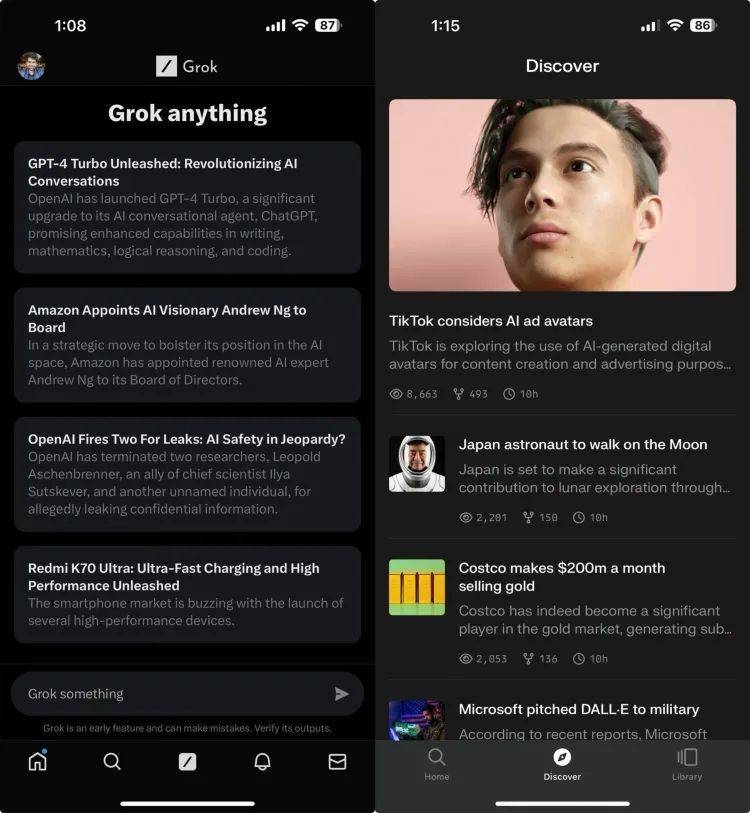
好家伙,这回Google、OpenAI、Grok都被含沙射影地射中了——所有做聊天机器人的公司,不约而同地都把Perplexity作为首要“抄袭”对象。
结果被这位大哥一句话直接扎心:“我们都不知道还有Perplexity Discover这种东西存在。”

“任何人都可以复制想法,然后加上自己的特色。世界就是这样的,天性如此,我们当然也可以这样做。”

网友让Srinivas别抱怨了。再说那什么Discover,本质上不就是 News Feed吗?那可不是Perplexity发明的,Google的搜索引擎里已经有这个功能十几年了。
说起来,这也不是Aravind Srinivas第一次“指责”别人借鉴他的劳动成果了。
今年一月时,贾扬清在X上发布了一个基于LeptonAI云平台的对话式搜索引擎demo,用500行Python代码轻松实现了类似Perplexity的效果。这个“Lepton Search”的后端是Mixtral-8x7b模型,接入Bing搜索API,用户输入问题后就能返回答案、引用来源和相关问题。
LeptonAI通过这个演示向大家展现了现在构建一个人工智能应用有多简单。换句话说,等于把Perplexity这个产品 “剥皮”了。它的前端设计的确看起来很fancy,但技术门槛其实很容易实现。
这很快引来Srinivas的空降,转发贾扬清的推文并用一贯“委婉”的语气内涵道:“很高兴看到Perplexity成为未来融资动作的标杆,包括前Meta和阿里巴巴高管都来取经!Perplexity的影响力已经不局限于产品本身,而是辐射到了整个科技生态和行业发展,令人振奋!”
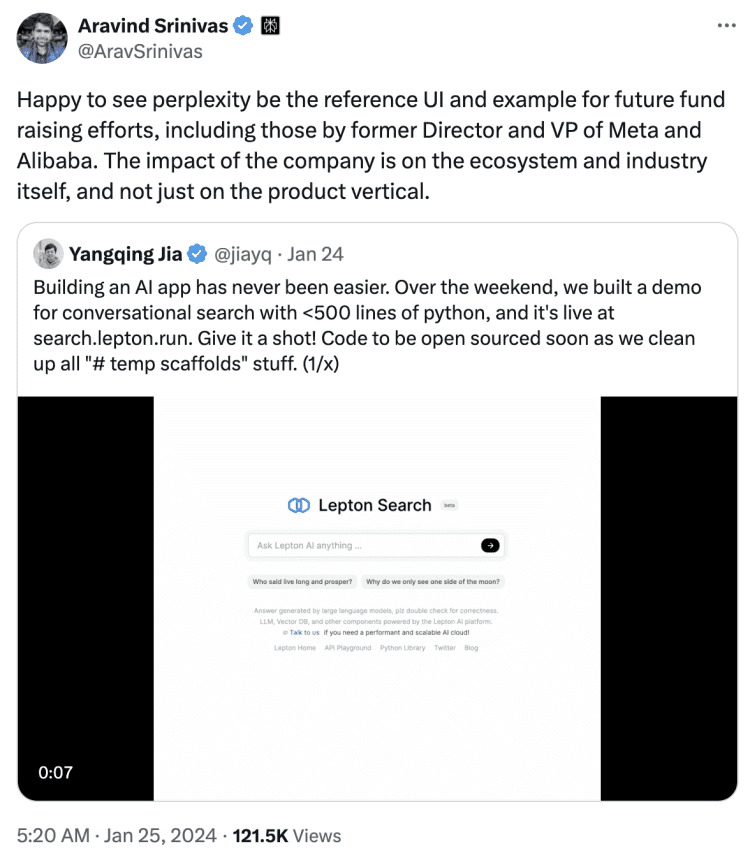
双方粉丝当时也各执一词。支持Perplexity的人认为Lepton就是抄袭,反对方觉得Lepton只是通过演示证明自己的能力,再说你perplexity也没有知识搜索专利,着实是反应过度了。
贾扬清也没有示弱,表示自己搭建这个demo的灵感来自于和微软技术专家@youwu_5u喝咖啡时,关于RAG的效果究竟是源自搜索还是大模型的讨论,并以代码全部开源正面回击。
所以从现在Srinivas又“出征”Meta和Grok,我们也看出来了,Perplexity还真是时刻处于战备状态,觉得全世界都在抄它!
不过来来回回,好像指责的内容总是离不了“创意、界面设计、功能”上的抄袭,除此之外再无其他。有网友无情戳穿,“这是不是因为,Perplexity明白,自己除了UI也真没什么可抄的了”。甚至有人说用任何AI聊天机器人都能生成类似的前端代码,只要再加上一些自己的想法,就能打磨出一款全新外壳。
从工作流程来说,Perplexity先获取用户输入,基于实时索引重构查询,再将回答问题的任务交给大语言模型,要求它阅读所有相关链接,从中提取出相关段落整合内容返回给用户。拆解下来,本质上还是靠Google和Bing们提供的检索API和GPT-4、 Claude 3等LLM。
作为一家应用类公司和API接口供应商,Perplexity并没有自己的基础大模型,默认的两款免费自研模型都是从GPT微调而来,也就没有坚固而不可逾越的技术护城河。搜索体验上的优化与创新才是Perplexity最初吸引用户的法宝,也自然成为他们握紧在手里,拼命捍卫的东西。
 Srinivas在X发布的记录Perplexity产品构思的第一块白板
Srinivas在X发布的记录Perplexity产品构思的第一块白板
尽管对于平台类公司来说,这种彼此间的“借鉴”已经太司空见惯,打车软件Uber和Lyft、点餐应用DoorDash、Uber Eats和Postmates、国内的美团和饿了么等等,例子不要太多。但年轻的Perplexity在还没有形成稳定而广泛的客户群,功能也比较朴素、尚未全面开花,还需要考虑用卖广告来加持现金流的情况下,这种担心随时被替代的焦虑感会更严重。甚至需要抓住一切机会去“碰瓷”,即使这看起来难免有些应激。
另一个不可否认的现实是,市场上形形色色的AI初创公司们之间存在一个清晰的估值断层。那些开发了基础大语言模型或具备核心技术的OpenAI、Anthropic、Cohere、Scale AI等总是处于领先的第一梯队,而Perplexity或Poe这样的平台类公司,估值一旦达到某个位置就难以突破。
Poe现在冲的是最快速地集成市场上最新的大模型,以及Poe bot创作者共享经济模式,加上Quora做后备,也算找到了自己的一条路。而对Perplexity这个目前仅靠对话式搜索引擎一个饭碗的公司来说,也必须承认,创意一旦公开就不再是秘密,人人都有权利去借鉴和优化。
最后也说句公道话,时至今日,作为一名Perplexity订阅用户,它对于琐碎信息的整理能力和杜绝AI幻觉的准确性,依然是吸引人的付费的点。做得最快能证明团队足够敏锐和优秀,做到最好更是需要持续研习的智慧。Perplexity与其紧盯着对手们在网上抱怨,不如放下独创性的执念,巩固优势并继续沉下心洞察市场、打磨产品,用下一个耳目一新的功能证明自己。
本文来自微信公众号:硅星人Pro(ID:Si-Planet),作者:张潇雪