
自从Grok-1公开发布后,越来越多的人坐不住了。比如这家成立了11年的数据公司Databricks,他们就在Grok-1公开后的一个多礼拜,发布了自己的大模型DBRX。
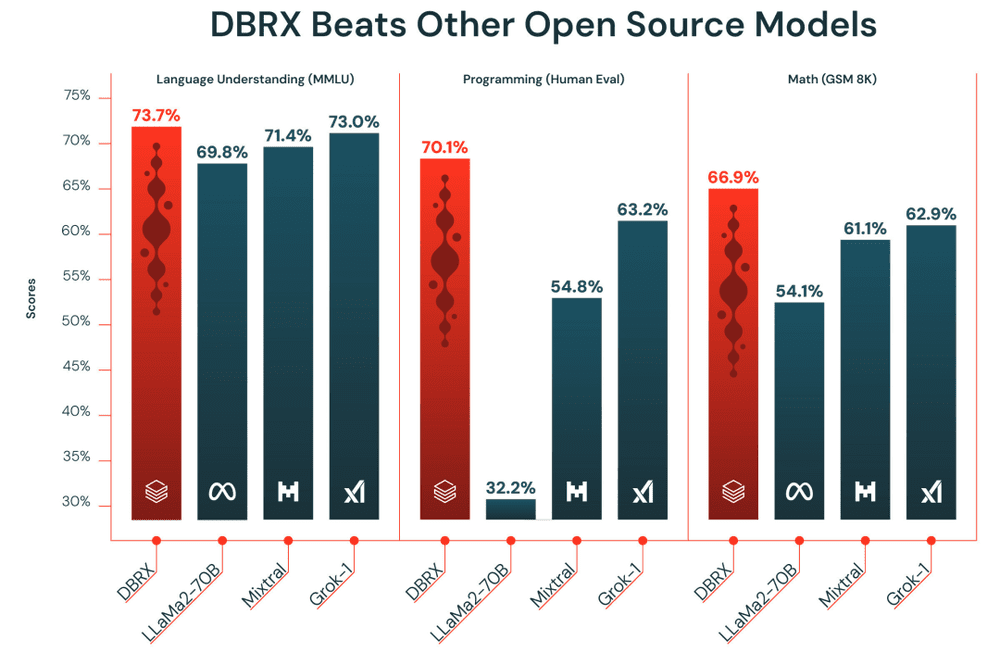
Databricks官方对DBRX的评价原话是“DBRX surpasses open source models across industry benchmarks”。那么翻译过来是DBRX在标准行业基准上,超越了所有开源模型,包括刚刚发布的Grok-1。
这里稍微补充一下,所谓行业基准,指的是大模型的语言理解、编程、数学和逻辑这些常见的业务,那些让大模型整活的内容是不算在内的。
根据Databrick在Hugging face上传的模型来看,DBRX总参数量为1320亿,其中在处理任何输入时有360亿参数处于激活状态。同时,DBRX已经在1.2万亿个文本和代码数据tokens上进行了预训练。虽然参数量远不及Grok-1那3000多亿的参数,但是放在开源模型这个圈子里依然是大哥大级别。
Databricks在Hugging face上这样写到,“相较于其他公开的MoE模型如Mixtral-8x7B和Grok-1,DBRX具有细粒度特性”。那什么是所谓的“细粒度特性”呢?简单来说,就是把事物或任务分解得非常详细、具体,就像用放大镜去看一样,关注每一个微小的部分或细节。
DBRX用的是混合专家(MoE)架构,它的细粒度主要表现在把这些专家变成了多个不同的小专家,每个专家处理更专业化的子任务,且可以根据输入灵活选择不同组合。因此,细粒度越高,代表分派任务的过程越细致,直白点说,它就能更精准地应对复杂情况,提高模型表现。
从Databricks给出来的数据看,DBRX拥有16个专家并从中选择4个参与运算,而Mixtral-8x7B和Grok-1是各有8个专家,每次选择2个。Databricks在Hugging face上写到,这种设计提供了高达65倍的专家组合可能性,还有助于提升模型性能。
说到MoE就不得不提及MegaBlocks,这也是DBRX的立足之本。MegaBlocks是一个专为在GPU上高效训练MoE模型而设计的系统。说白了,MegaBlocks是一次对MoE计算的重构。
为什么这么说呢,传统MoE有个大问题,那就是用户必须得取舍。此前的框架在处理MoE层动态路由时存在一定的局限性,这种局限性它来源于古早设计缺陷,毕竟过去没有像现在一样那么强大的GPU。因此这种局限性就迫使用户在牺牲模型质量或硬件效率之间做出权衡。等于说,用户必须选择要么丢弃计算中的部分输入token,要么浪费计算资源和内存用于填充以适应硬件要求。
MegaBlocks系统是将MoE层的计算表述为基于块稀疏操作的形式,并开发了新的块稀疏GPU内核,能够有效地应对MoE中存在的动态特性。这种方法确保不丢弃任何token,并能高效地映射到现代硬件加速器上,从而实现相对于使用最先进Tutel库训练的MoE模型高达40%的端到端训练速度提升,以及相较于使用高度优化的Megatron-LM框架训练的深度神经网络(DNNs),达到2.4倍的速度提升。
拼过拼图的朋友一定有这种经历:在拼图的过程中,会先找上面颜色比较丰富的或者有特殊图案的。因为这些拼图比那些上面只有单色的信息量要大得多。块稀疏操作也是如此,我们把信息丰富的拼图想象成非零值,单色的则是零值,进而只关注非零值,忽略零值。
这样做的好处是减少了不必要的计算量,因为不需要对明显没有信息的零值进行处理。对于机器学习中的大型模型,尤其是像MoE这样的复杂结构,其中像是专家网络这样的部分,可能只对输入数据的特定部分有响应,其余部分则保持“沉默”(输出为零)。块稀疏操作可以捕捉这种局部活跃、全局稀疏的特性,使得计算集中在真正产生影响的部分,极大地提高了计算效率。DBRX的核心技术便是如此。
不过这还没完,刚才咱们说了,MegaBlocks是对MoE的重构,所以这个系统也包含了在GPU上执行块稀疏矩阵乘法而设计的高性能计算程序组件,也就是所谓的“高效率块稀疏矩阵乘法内核”。这些内核针对含有大量零值且这些零值以块状而非散乱方式分布的矩阵,实现了高效的乘法运算。
内核专门处理块稀疏矩阵,这意味着它们仅对矩阵中非零(就是咱们刚才聊的有信息量的拼图)元素所在的“块”进行实际计算,而忽略由零值构成的大片空白区域。高效率块稀疏矩阵乘法内核可以说是是MegaBlocks系统的核心组成部分,它们利用块稀疏表示和针对性的算法优化,实现了对MoE模型训练过程中大规模稀疏矩阵乘法的有效处理,确保了在GPU上进行模型训练时的高效计算和资源利用。
别看又是优化,又是针对的,可DBRX跟Grok-1一个“病”,普通计算机根本跑不动。在DBRX的标准配置中,需要300多GB的显存才能带得起来,相当于4块英伟达H100。我实在没那个家庭条件对其进行测试,“抱一丝”。即便是在第三方云上运行,它的硬件要求也非常高,谷歌云上有一个DBRX实例,使用的是完整的一颗英伟达H100。
另外提一嘴,严格意义上来说,所谓“开源”是指软件在开发与分发过程中,其中包括软件产品的源代码、训练数据等事物在内对公众完全开放。换句话说,DBRX并不是真正的开源。
实际上我们如果想完全理解DBRX,得先了解Darabricks。这个公司是做数据服务的,比如数据管理、清洗、分析等等。本来这些业务和现在以神经网络为主的人工智能是不沾边的,它是古典人工智能那套逻辑。
但是2023年11月的时候,Databricks发布了一个产品叫做Lakehouse,是一种结合了数据湖和数据仓库优势的数据管理平台,旨在提供一个统一的数据存储与分析环境,既能实现大规模、低成本的数据存储,又能支持高级分析、事务处理以及数据治理等传统数据仓库功能。
所谓数据湖是一种数据存储架构,能够容纳来自不同源头、格式各异的数据,包括结构化数据、半结构化数据、非结构化数据以及二进制数据。还能以原始或近似原始格式保存,无需预先进行复杂的结构化处理或转换。数据仓库则是一种专为支持决策分析而设计的集成化数据存储系统。从这个事的逻辑来讲,Lakehouse就是仓库+配送一条龙服务。
你在了解这么个大前提后回来看DBRX。Databricks只花费了两个月就开发出了这么个性能还算优异的大模型,它训练模型的基地就是Lakehouse,也能透过MegaBlocks系统的应用来反哺Lakehouse。
本文来自微信公众号:硅星人Pro(ID:Si-Planet),作者:苗正