
对于多年来一直在思考人工智能的哲学家来说,GPT-4就像是一个已经实现了的思维实验。
早在1981年,Ned Block就构建了一个“Blockhead”假说——假定科学家们通过编程,在Blockhead内预先设定好了近乎所有问题的答案[1],那么,在它回答问题的时候,人们就根本无法区分Blockhead和人类。显然,这里的Blockhead并不被认为是智能的,因为它回答问题的方式仅仅是从其庞大的记忆知识库中检索并复述答案,并非通过理解问题之后给出答案。哲学家们一致认为,这样的系统不符合智能的标准。
实际上,GPT-4的许多成就可能就是通过类似的内存检索操作产生的。GPT-4的训练集包括数亿个人类个体生成的对话和数以千计的学术出版物,涵盖了潜在的问答对。研究发现,深度神经网络(DNNs)多层结构的设计使其能够有效地从训练数据中检索到正确答案[2]。这表明,GPT-4的回答其实是通过近似甚至是精确复制训练集中的样本生成的。
如果GPT-4真的是以这种方式运行,那么它就只是Blockhead的现实版本。由此,人们在评估大语言模型时,也就存在一个关键问题:它的训练集中可能包含了评估时使用的测试问题,这被称为“数据污染”,是在评估前必须排除的问题。

▷原始论文:Millière, Raphaël, and Cameron Buckner. "A Philosophical Introduction to Language Models--Part I: Continuity With Classic Debates." arXiv preprint arXiv:2401.03910 (2024)[3].
有趣的是,最近有一篇论文对“LLMs不过只是Blockhead”的观点提出了挑战。
研究者指出,LLMs不仅可以简单地复述其提示的或训练集的大部分内容,它们还能够灵活地融合来自训练集的内容,产生新的输出。而许多经验主义哲学家提出,能够灵活复制先前经验中的抽象模式,可能不仅是智能的基础,还是创造力和理性决策的基础。
要论证这个观点,研究者将“LLMs仅仅是愚蠢、低效的Blockheads”的担忧设为零假设,并通过经典哲学理论来反驳这一观点。同时,在此过程中,研究者介绍了最先进的LLMs(如GPT-4)的结构体系、成就和围绕其展开的哲学问题。
大语言模型简史
对这个领域还不甚了解的读者,可以先花个5分钟来看LLMs是如何从多个基础学派假说中一路发展而来的(你也可以选择直接跳过本章节)。
历史基础
LLMs的起源可以追溯到人工智能研究的开始。早期的自然语言处理(natural language processing, NLP)主要有两大流派:符号派和随机学派。Noam Chomsky的转换生成语法对符号派影响重大[4]。该理论认为自然语言的结构可以被一组形式化规则概括,利用这些规则可以产生形式正确的句子。
与此同时,受香农信息论的影响,数学家Warren Weaver首创了随机学派。1949年,Weaver提出了使用统计技术在计算机上进行机器翻译的构想。这一思路为统计语言模型的发展铺平了道路,例如n-gram模型,该模型根据语料库中单词组合的频率估计单词序列的可能性[5]。
现代语言模型的另一个重要基石是分布假设(distributional hypothesis)。该假设最早由语言学家Zellig Harris在1950年代提出[6]。这一假设认为,语言单元通过与系统中其他单元的共现模式来获得特定意义。Harris提出,通过了解一个词在不同语境中的分布特性,可以推断出这个词的含义。
随着分布假设研究的不断深入,人们开发出了在高维向量空间中表示文档和词汇的自动化技术[7]。之后的词嵌入模型(word embedding model)通过训练神经网络来预测给定词的上下文(或者根据上下文填词)学习单词的分布属性。与先前的统计方法(如n-gram模型)不同,词嵌入模型将单词编码为密集的、低维的向量表示(图1)。由此产生的向量空间在保留有关词义的语言关系的同时,大幅降低了语言数据的维度。同时,词嵌入模型的向量空间中存在许多语义和句法关系。
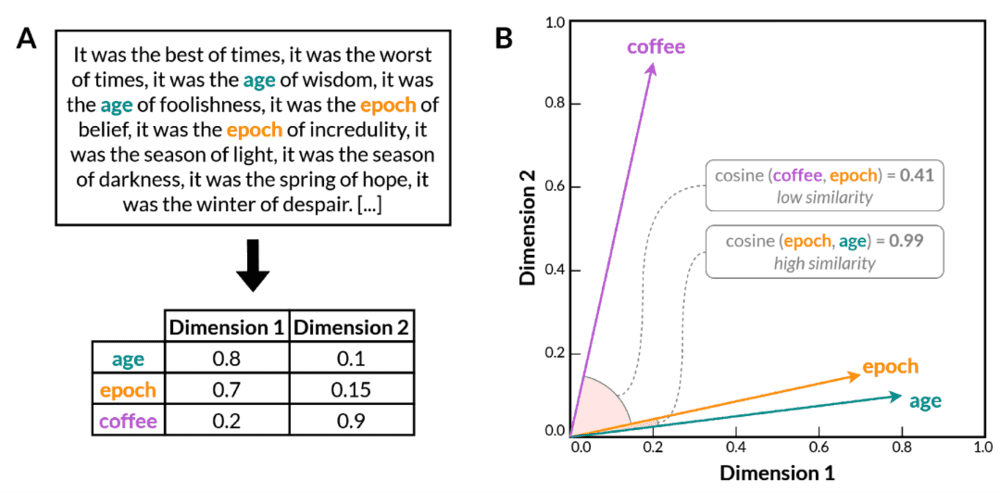
▷图1. 多维向量空间中词嵌入的一个例子。A. 一个在自然语言语料库上训练的词嵌入模型学会将单词编码成多维空间中的数值向量,为了视觉上的清晰性而简化为两维。在训练过程中,上下文相关的单词(例如“age”和“epoch”)的向量变得更加相似,而上下文无关的单词(例如“age”和“coffee”)的向量变得不那么相似。B. 在经过训练的模型的二维向量空间中的词嵌入。具有相似含义的单词(如“age”和“epoch”)被放置在更靠近的位置,这由它们的余弦相似度得分高度表示;而具有不同含义的单词(如“coffee”和“epoch”)则相对较远,反映在余弦相似度得分较低上。余弦相似度是一种用于确定两个非零向量夹角余弦的度量,反映它们之间的相似程度。余弦相似度得分越接近1,表示夹角越小,向量之间的相似度越高。(图片引自[3])
词嵌入模型的发展是NLP历史上的一个转折点,为基于在大型语料库中的统计分布在连续向量空间中表示语言单元提供了强大而高效的手段。然而,这些模型也存在一些显著的局限性。首先,它们无法捕捉一词多义和同音异义,因为它们为每个单词类型分配了单一的嵌入,无法考虑基于上下文的意义变化。
随后的“深度”语言模型引入了类似记忆的机制,使其能够记住并处理随时间变化的输入序列,而不是个别的孤立单词。这些模型虽然在某些方面优于词嵌入模型,但它们的训练速度较慢,处理长文本序列时表现也欠佳。这些问题在Vaswani等人于2017年引入的Transformer架构中得到解决,Transformer架构为现代LLMs奠定了基础。
Transformer-based LLMs
Transformer架构的一个关键优势在于,输入序列中的所有单词都是并行处理,而不是像RNN、LSTM和GRU那样顺序处理。这种架构不仅极大地提高了训练效率,还提高了模型处理长文本序列的能力,从而增加了可以执行的语言任务的规模和复杂性。
Transformer模型的核心是一种被称为自注意力(self-attention)的机制(图2)。简而言之,自注意力允许模型在处理序列中的每个单词时,衡量该序列不同部分的重要性。这一机制帮助LLMs通过考虑序列中所有单词之间的相互关系,构建对长文本序列的复杂表示。在句子层面之上,它使LLMs能够结合段落或整个文档的主题来进行表达。
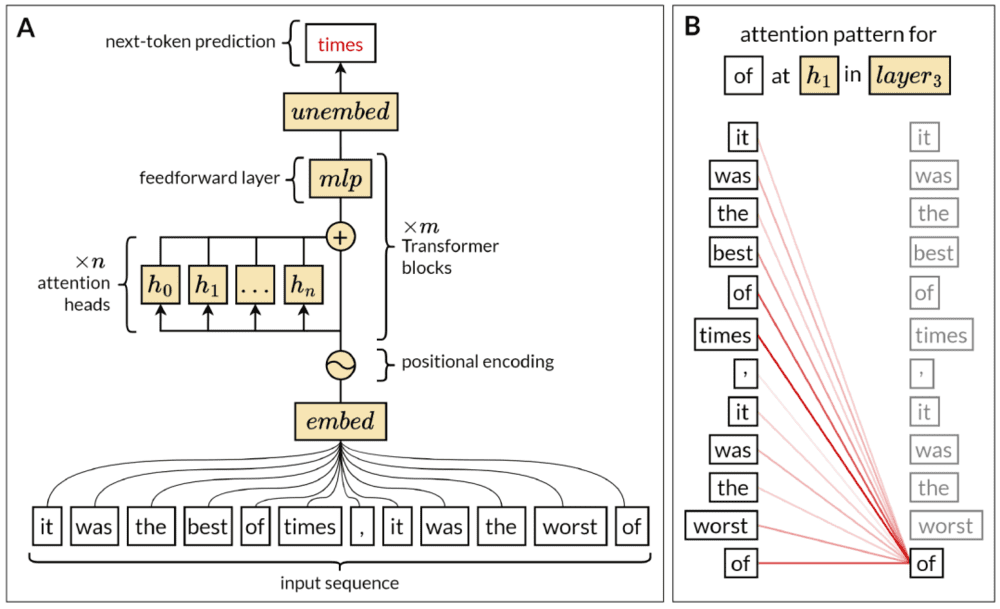
▷图2. A. LLM的自回归模型变体的结构体系。来自输入序列的tokens首先被嵌入为向量,这涉及将每个token转换为一个高维空间,其中在语义上相似的token具有相应相似的向量。位置编码将关于每个tokens在输入序列中位置的信息添加到向量中。然后,这些丰富的向量通过连续的Transformer块进行处理。每个块包含多个attention heads,可以并行处理所有向量,以及一个全连接的前馈层,也称为多层感知机(multilayer perceptron, MLP)层。最后,在取消嵌入阶段,向量经历线性变换,将它们投影到一个与词汇大小相同的空间中,生成一组Logits。这些Logits表示词汇中每个潜在下一个token的未归一化分数。然后应用柔性最大值传输函数层,将这些逻辑转换为对词汇的概率分布,指示每个token成为序列中下一个token的相对可能性。在训练过程中,已知正确的下一个token并用于反向传播,而在推理过程中,模型在没有此信息的情况下预测下一个token。可以迭代地以自回归方式重复此过程,以生成多个token的预测。B. 自注意机制的可视化。每个attention head为序列中的每个标记分配权重或注意力分数,该分数适用于包括在内的序列中的每个标记0−。在这里,每条红线表示‘of’与输入序列中的每个其他标记之间的注意力分数,包括自身。在此示例中,注意力分数量化了每个标记相对于标记‘of’的相关性或重要性,较粗的线表示较高的分数。这个模式说明了注意力机制允许模型动态关注输入序列的不同部分,以得出每个标记的具有上下文细微差别的表征。每个attention head的注意力模式都不同,因为在训练过程中,每个头专门关注于选择性地关注标记之间的特定依赖关系。(图片引自[3])
值得一提的是,Transformer模型并非直接操作单词,而是操作称为tokens的语言单位。tokens可以映射到整个单词,也可以映射到更小的单词片段。在将每个单词序列提供给模型之前,首先进行标记化,将其分块成相应的tokens。标记化的目的是尽可能多地表示来自不同语言的单词,包括罕见和复杂的单词。
基于Transformer模型的最常见变体被称为“自回归”(autoregressive)模型(图2),包括GPT-3、GPT-4和ChatGPT。自回归模型以准确预测下一个token为学习目标。在每次训练时,模型的目标是根据先前的tokens预测语料库中抽样序列的下一个token。在第一次预测时,模型使用随机参数初始化,预测结果并不准确。随着每次预测的进行,模型的参数逐渐调整,直至预测出的token和训练集中实际的token的差异最小。
这个过程重复数十亿次,直到模型能够准确预测从训练集中随机抽取的内容的下一个token。Transformer模型的训练集包括百科全书、学术文章、书籍、网站,甚至大量计算机代码等多样化来源的大型语料库,旨在概括自然语言和人工语言的广度和深度,使Transformer模型能够准确进行下一个tokens的预测。
尽管这种方式训练的LLMs在生成文本段落方面表现出色,但它们对真实的、有用的或无冒犯性的语言没有固定偏好。为了让生成的文本更符合人类语言使用规范,近期的LLMs,如ChatGPT,使用了“从人类反馈中进行强化学习(RLHF)”的微调技术来调整模型的输出[8]。RLHF允许开发人员更具体和可控地引导模型的输出。这一微调过程在调整这些模型以更好地满足人类语言使用规范方面发挥着至关重要的作用。
LLMs具有出色的能力,能够利用文本提示中的文本信息来引导它们的输出。已部署的语言模型经过预训练,其参数在训练后保持固定。尽管大部分架构缺乏可编辑的长期记忆资源,但它们能够根据所提供的内容灵活调整输出,包括它们未经明确训练的任务。这种能力可被视为一种即时学习或适应的形式,通常被称为“情境学习”(in-context learning)[9]。情境学习可被解释为一种模式完成的形式,如果序列构造为一个熟悉的问题或任务,模型将尝试以与其训练一致的方式完成它。可向模型发出具体指令。
在所谓的“少样本学习”中,提示的结构包括要执行的任务的几个示例,后面跟着需要响应的新实例。在“零样本学习”中,模型不会得到任何示例,任务直接在提示中进行概述或暗示。少样本学习长期以来被认为是人类智能的重要方面。而老式机器学习则在少样本学习任务中表现较差。然而,经过训练后的LLMs在少样本学习上表现出色。在较大的模型(如GPT-3)中观察到,少样本学习能力似乎与模型大小高度相关[9]。通过RLHF精调后,LLMs的零样本学习能力得到增强。
LLMs已经在NLP领域内外的许多任务中得到应用,且有不错的表现。除了传统的自然语言处理任务,LLMs还具有执行包括生成代码、玩基于文本的游戏和提供数学问题答案等。由于LLMs出色的信息检索能力,它们甚至已被提议作为教育、研究、法律和医学的工具。
LLMs中的经典哲学问题
人工神经网络(Artificial neural networks, ANNs),包括早期的NLP结构,一直是哲学讨论的焦点。围绕这些系统的哲学讨论主要集中在它们作为建模人类认知的适用性上。具体而言,争论的焦点在于,相比于经典的、符号的、基于规则的对应物模型,它们是否构成了更好的人类认知模型。
本节总结了部分关于人工神经网络能力的长期争论,这些争论因深度学习的发展和LLMs的成功而复苏和转变。
组成性
长期以来,研究者们批评ANNs无法解释认知的核心结构,在模拟人类思维方面存在局限。批评者认为,ANNs要么无法捕捉经典符号架构中可以轻松解释的认知特征,要么实际上只是实现了这种符号处理的架构,但在真正理解思维过程方面并没有提供新的见解[10-12]。
近年来,LLMs的迅速发展挑战了这种关于联结主义模型局限性的传统观点。大量实证研究调查了大语言模型在需要组合处理的任务上是否能表现出类似人类水平的性能。这些研究主要评估模型在组合泛化方面的能力,即它们是否能够系统地重新组合先前学到的元素,并将这些元素组成的新输入映射到正确的输出上[13]。这对于LLMs来说,是一项困难的任务,因为它们通常是用庞大的自然语言语料库训练而成的,而这些数据可能包含了很多特定的句子模式。但研究者通过精心设计的训练-测试划分合成数据集,克服了这一问题。
在组合泛化的合成数据集(如SCAN[14]、CFQ[15]和COGS[16])上,DNN未能正确地在句法分布转变中进行泛化。然而,许多基于Transformer的模型在这些测试上取得了不错的表现。
元学习,即通过从许多相关的学习任务中进行泛化以更好地学习[17, 18],也表现出无需进一步进行架构调整即可进行泛化的潜力。相比之下,标准的监督学习假设训练和测试数据来自同一分布,但这可能导致模型在训练数据上过拟合。元学习让模型接触到多个相关任务的分布,从而帮助它们获取通用知识。
通过元学习,在一系列不同人工任务上训练的标准的Transformer模型实现了系统性泛化,展现出与人类相似的准确性和错误模式,而且这些模型不需要明确的组合规则。这表明,要模仿人类大脑的认知结构,可能不需要严格的内置规则。
根据哲学家和认知科学家Fodor的心智模块化主张*,心理过程应该基于离散符号,而ANNs使用的却是连续向量,这引发了ANNs是否满足经典成分结构要求的质疑。对于主张联结主义的人们来说,他们认为ANN可能建立在一种非经典的建模认知结构之上。
*Jerry Fodor认为,思维和认知过程中涉及的信息以一种类似语言的形式存在,这种“心灵的语言”包含可以组合并且具有明确意义的符号。在Fodor的框架下,心理过程涉及对这些离散符号的操作,这些符号不仅在语义上可以被评估,还在认知处理中发挥直接的因果作用。相比之下,在ANNs中,信息通常被表示为连续的向量,而这些向量被认为缺乏离散的、语义上可评估的成分,这些成分在算法层面参与处理。在这种观点下,ANNs处理的是较低层级的激活值,而不是直接操作语义上明确的符号。
连续性原则认为,信息编码和处理机制应使用可以连续变化的实数表示,而不是离散符号表示的实数进行形式化。首先,这使得对自然语言等领域进行更灵活的建模成为可能。其次,利用连续性的统计推理方法,如神经网络,能够提供可处理的近似解决方案。最后,连续性允许使用深度学习技术,这些技术可以同时优化信息编码和模型参数,以发现最大化性能的任务特定表示空间。
总体而言,通过利用连续性的这些优势,可以解决离散符号方法在灵活性、可处理性和编码方面长期面临的挑战。因此,基于Transformer的ANN为“神经组合计算”提供了有希望的见解:它们表明ANN可以满足认知建模的核心约束,特别是连续和组合结构以及处理的要求。
天赋论与语言习得
另一个传统争议在于,人工神经网络语言模型是否挑战了语言发展中天赋论的论点?
这场争论集中在两个主张上:一种是较强的原则性主张(in-principle claim),另一种是较弱的发展性主张(developmental claim)。
较强的原则性主张认为,即使接触再多的语言资料,也不足以使儿童迅速掌握句法知识。也就是说,如果没有内在的先验语法知识,人类就无法学习语言规则。较弱的发展性主张则基于“贫乏刺激”理论,认为儿童在发展过程中实际接触的语言输入的性质和数量不足以诱导出底层句法结构的正确概念,除非他们拥有先天知识。Chomskyan派的语言学家认为儿童天生具有“通用语法”(Universal Grammar),这使得儿童能够通过少量的经验,高效适应特定语言中的特定语法。
LLMs在学习语法结构上的成功,成为了天赋论的反例。LLMs仅通过训练数据集,就能够获得复杂的句法知识。这对天赋论的原则性主张施加了相当大的压力[19]。从这个意义上说,LLMs提供了一种经验主义的证据,即统计学习者可以在没有先天语法的帮助下归纳出语法知识。
然而,这并不直接与发展性主张相矛盾,因为LLMs通常接收的语言输入量比人类儿童要多上几个数量级。而且,人类儿童面对的语言输入和学习环境与LLMs有很大不同。人类学习更具有互动性、迭代性、基础性和体验性。研究者逐渐通过在更接近真实学习环境中训练较小的语言模型,提供证据来支持这种发展性主张[20]。
但这些初步结果仍然是不确定的。目前尚不清楚,没有内置解析器的统计学习模型是否能像儿童一样有效地学习语法。一种可能的策略是尽可能模仿儿童的学习环境,例如,直接在符合发展阶段的口语文本数据集上训练模型[21],甚至可以使用安装在儿童头上的摄像头记录儿童以自我为中心的视听输入进行训练[22, 23]。如果未来在这些或类似数据集上训练的模型被证实能够展现出类似于儿童观察到的句法概括,这将对发展性可学性主张提出相当大的质疑,暗示即使是相对“贫乏”的语言刺激,对于具有广泛归纳偏好的学习者来说,可能也足够诱导出句法结构。
语言理解与基础
即便LLMs能够通过分析语言序列掌握句法结构,但这并不意味着它们是真的理解了语义。对这一点,学界存在很多批评。如Bender和Kolle认为,由于语言模型仅在语言的形式方面接受训练,它们无法从语言形式中直接学习到语义,因此LLMs本质上无法理解语言的含义[24]。
相关批评与Harnad在1990年所述的“基础问题”(grounding problem)[25]不谋而合。这个问题指出,NLP中的语言tokens与它们在现实世界中所指代的对象之间存在明显脱节。在传统的NLP中,单词由任意符号表示,这些符号与现实世界中的指代物没有直接联系,它们的语义通常由外部编程者赋予。从系统的角度来看,它们只是嵌入语法规则中的毫无意义的tokens。Harnad认为,要使NLP系统中的符号具有内在意义,需要这些内部符号表示与符号所指代的外部世界中的对象、事件和属性存在某种基础联系。如果没有这种联系,系统的表示将与现实脱节,只能从外部解释者的角度获得意义。
尽管这一问题最初是针对经典符号系统提出的,但对仅在文本上进行训练的现代LLMs来说,也存在类似的问题[26]。LLMs将语言tokens处理为向量,而不是离散符号,这些向量表示同样可能与现实世界脱节。尽管它们能生成对熟练的语言使用者有意义的句子,但这些句子在没有外部解释的情况下可能就没有独立的意义。
第三则批评涉及LLMs是否具有交际意图的能力。这涉及到Grice传统中两种意义的区别*:一种是与语言表达相关的、固定的、与上下文无关的意义(通常称为语言意义),另一种是说话者通过话语传达的意图(通常称为说话者意义)。LLMs的输出包含按照实际语言使用的统计模式组织和组合的单词,因此具有语言意义。然而,为了实现有效的交流,LLMs需要具有相应的交际意图。批评的观点认为,LLMs缺乏交际意图的基本构建块,如内在目标和心智理论。
语义能力通常指的是人们使用和理解一种语言中所表达的含义的能力和知识。有人提出,即使在其局限性之外,LLMs也可能展现出一定程度的语义能力。Piantadosi和Hill认为,LLMs中词汇项的含义,与人类一样,不取决于外部引用,而是取决于相应表示之间的内部关系[27]。这些表示可以在高维语义空间中,以向量的形式进行描述。这个向量空间的“内在几何”指的是不同向量之间的空间关系,例如向量之间的距离、向量组之间形成的角度,以及向量在响应上下文内容时的变化方式。
Piantadosi和Hill认为,LLMs展示的令人印象深刻的语言能力表明,它们的内部表示空间具有大致反映人类概念空间的基本特性的几何结构[31]。因此,评估LLMs的语义能力不能仅通过检查它们的架构、学习目标或训练数据来确定;相反,至少应该部分地基于系统向量空间的内在几何结构。虽然关于LLMs是否获得指称语义能力存在争议,但一些观点认为,通过在语料库上进行训练,LLMs可能在一定程度上实现真正的语言指称。
虽然LLMs通过它们的训练数据与世界之间存在间接的因果关系,但这并不能保证它们的输出是基于真实世界的实际指代。Mollo和Millière认为,仅在文本上进行训练的LLMs实际上可能通过RLHF的微调,获得涉及世界的功能[28]。虽然经过精细调整的LLMs仍然无法直接访问世界,但RLHF的反馈信号可以将它们的输出与实际情况联系起来。
还有重要的一点是LLM不具有沟通意图。LLM输出的句子可能没有明确的含义,句子的含义是由外部解答产生的。当人类给定一个外部目标时,LLMs可能表现出类似沟通意图的东西。但是这个“意图”完全是由人类设定的目标确定的,LLMs在本质上无法形成沟通意图。
世界模型
另一个核心的问题是,设计用于预测下一个token的LLMs是否能构建出一个“世界模型”。在机器学习中,世界模型通常指的是模拟外部世界某些方面的内部表征,使系统能够以反映现实世界动态的方式理解、解释和预测现象,包括因果关系和直观的物理现象。
与通过和环境互动并接收反馈来学习的强化学习代理不同,LLMs并不是通过这种方式进行学习的。它们能否构建出世界模型的问题,实际上是在探讨它们是否能够内部构建出对世界的理解,并生成与现实世界知识和动态相一致的语言。这种能力对于反驳LLMs仅仅是“Blockheads”的观点至关重要[1]。
评估LLMs是否具有世界模型并没有统一的方法,部分原因在于这个概念通常定义模糊,部分原因在于难以设计实验来区分LLMs是依赖浅层启发式回答问题,还是使用了环境核心动态的内部表征这一假设。尽管如此,我们还可以向LLMs提出一些不能依据记忆来完成的任务,来提供新的证据解决这一问题。
有研究发现,GPT-4可以为新任务生成可运行的文本游戏,这可能意味着它对游戏环境中物体互动方式有一定理解[29]。然而,要验证这一假设,需要深入分析模型内部编码,这对于非常庞大的模型来说相当极具挑战,而对于像GPT-4这样不公开权重的封闭模型来说,更是不可能实现。
有理论支持LLMs可能学会了模拟世界的一部分,而不仅仅是进行序列概率估计。更具体地说,互联网规模的训练数据集由大量单独的文档组成。对这些文本的最有效压缩可能涉及对生成它们的隐藏变量值进行编码:即文本的人类作者的句法知识、语义信念和交际意图。
文化知识传递和语言支持
另一个有趣的问题是,LLMs是否可能参与文化习得并在知识传递中发挥作用。一些理论家提出,人类智能的一个关键特征在于其独特的文化学习能力。尽管其他灵长类动物也有类似的能力,但人类在这方面显得更为突出。人类能够相互合作,将知识从上一代传到下一代,人类能够从上一代结束的地方继续,并在语言学、科学和社会学知识方面取得新的进展。这种方式使人类的知识积累和发现保持稳步发展,与黑猩猩等其他动物相对停滞的文化演变形成鲜明对比。
鉴于深度学习系统已经在多个任务领域超过了人类表现。那么问题就变成了,LLMs是否能够模拟文化学习的许多组成部分,将它们的发现传递给人类理论家。目前研究发现,现在主要是人类通过解释模型来得到可传播的知识。
但是,LLMs是否能够以理论介导的方式向人类解释它们的策略,从而参与和增强人类文化学习呢?有证据表明,基于Transformer的模型可能在某些训练-测试分布转变下实现组合泛化。但目前的问题涉及到一种不同类型的泛化——解决真正新颖任务的能力。从现有证据来看,LLMs似乎能够在已知任务范围内处理新数据,实现局部任务泛化。
此外,文化的累积进步(棘轮效应)不仅涉及创新,还包括稳定的文化传播。LLMs是否能够像人类一样,不仅能够生成新颖的解决方案,还能够通过认识和表达它们如何超越先前的解决方案,从而“锁定”这些创新?这种能力不仅涉及生成新颖的响应,还需要对解决方案的新颖性及其影响有深刻理解,类似于人类科学家不仅发现新事物,还能理论化、情境化和传达他们的发现。
因此,对LLMs的挑战不仅仅在于生成问题的新颖解决方案,还在于培养一种能够反思和传达其创新性质的能力,从而促进文化学习的累积过程。这种能力可能需要更先进的交际意图理解和世界模型构建。虽然LLMs在各种形式的任务泛化方面表现出有希望的迹象,但它们参与文化学习的程度似乎取决于这些领域的进一步发展,这可能超出了当前体系结构的能力范围。
总结
作者在这篇综述文章中首先考虑了一种怀疑论,即LLMs只是复杂的模仿者,它们仅仅是从训练数据中记忆和复述语言模式,类似于Blockhead思想实验。将这种观点作为零假设,批判性地审视了可以用来否定这一观点的证据。在许多情况下,LLMs远远超出了非经典系统性能上限的预测。
与此同时,作者发现超越Blockhead的类比仍然取决于对LLMs学习过程和内部机制的仔细研究,而我们对它们的理解才刚刚开始。
特别是,我们需要了解LLMs对其生成的句子以及这些句子所描述的世界的表征。这些理解需要未来进一步实证调查。
参考文献:
[1] Block, N., Psychologism and Behaviorism. The Philosophical Review, 1981. 90.
[2] Zhang, C., et al., Understanding deep learning (still) requires rethinking generalization. Communications of the ACM, 2021. 64(3): p. 107-115.
[3] Millière, R. and C. Buckner, A Philosophical Introduction to Language Models--Part I: Continuity With Classic Debates. arXiv preprint arXiv:2401.03910, 2024.
[4] Lees, R.B., Syntactic structures. 1957, JSTOR.
[5] Jelinek, F., Statistical methods for speech recognition. 1998: MIT press.
[6] Harris, Z.S., Distributional structure. Word, 1954. 10(2-3): p. 146-162.
[7] Salton, G., A. Wong, and C.-S. Yang, A vector space model for automatic indexing. Communications of the ACM, 1975. 18(11): p. 613-620.
[8] Christiano, P.F., et al., Deep reinforcement learning from human preferences. Advances in neural information processing systems, 2017. 30.
[9] Brown, T., et al., Language models are few-shot learners. Advances in neural information processing systems, 2020. 33: p. 1877-1901.
[10] Fodor, J.A. and Z.W. Pylyshyn, Connectionism and cognitive architecture: A critical analysis. Cognition, 1988. 28(1-2): p. 3-71.
[11] Pinker, S. and A. Prince, On language and connectionism: Analysis of a parallel distributed processing model of language acquisition. Cognition, 1988. 28(1-2): p. 73-193.
[12] Quilty-Dunn, J., N. Porot, and E. Mandelbaum, The best game in town: The re-emergence of the language of thought hypothesis across the cognitive sciences. Behavioral and Brain Sciences, 2022: p. 1-55.
[13] Schmidhuber, J., Towards compositional learning with dynamic neural networks. 1990: Inst. für Informatik.
[14] Lake, B. and M. Baroni. Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks. in International conference on machine learning. 2018. PMLR.
[15] Keysers, D., et al., Measuring compositional generalization: A comprehensive method on realistic data. arXiv preprint arXiv:1912.09713, 2019.
[16] Kim, N. and T. Linzen, COGS: A compositional generalization challenge based on semantic interpretation. arXiv preprint arXiv:2010.05465, 2020.
[17] Conklin, H., et al., Meta-learning to compositionally generalize. arXiv preprint arXiv:2106.04252, 2021.
[18] Lake, B.M. and M. Baroni, Human-like systematic generalization through a meta-learning neural network. Nature, 2023: p. 1-7.
[19] Piantadosi, S., Modern language models refute Chomsky’s approach to language. Lingbuzz Preprint, lingbuzz, 2023. 7180.
[20] Huebner, P.A., et al. BabyBERTa: Learning more grammar with small-scale child-directed language. in Proceedings of the 25th conference on computational natural language learning. 2021.
[21] Lavechin, M., et al., BabySLM: language-acquisition-friendly benchmark of self-supervised spoken language models. arXiv preprint arXiv:2306.01506, 2023.
[22] Sullivan, J., et al., SAYCam: A large, longitudinal audiovisual dataset recorded from the infant’s perspective. Open mind, 2021. 5: p. 20-29.
[23] Long, B., et al., The BabyView camera: Designing a new head-mounted camera to capture children’s early social and visual environments. Behavior Research Methods, 2023: p. 1-12.
[24] Bender, E.M. and A. Koller. Climbing towards NLU: On meaning, form, and understanding in the age of data. in Proceedings of the 58th annual meeting of the association for computational linguistics. 2020.
[25] Harnad, S., The symbol grounding problem. Physica D: Nonlinear Phenomena, 1990. 42(1-3): p. 335-346.
[26] Mollo,D.C. and R. Millière, The vector grounding problem. arXiv preprint arXiv:2304.01481, 2023.
[27] Piantadosi, S.T. and F. Hill, Meaning without reference in large language models. arXiv preprint arXiv:2208.02957, 2022.
[28] Grand, G., et al., Semantic projection recovers rich human knowledge of multiple object features from word embeddings. Nature human behaviour, 2022. 6(7): p. 975-987.
[29] Wang, R., et al., ByteSized32: A Corpus and Challenge Task for Generating Task-Specific World Models Expressed as Text Games. arXiv preprint arXiv:2305.14879, 2023.
本文来自微信公众号:追问nextquestion (ID:gh_2414d982daee),作者:吴婷婷,编辑:存源