
中文互联网上一直流传着一则著名鸡汤:一流企业做标准,二流企业做品牌,三流企业做产品。
去年各家卷大模型的热潮已经过去,今年AI应用呼之欲出,概念最火的当属人工智能代理(AI Agent)。
比尔·盖茨说:Android、iOS和Windows都是平台,AI Agent将成为下一个平台……未来5年内,我们不用打开应用去做事儿,只要对你的手机或电脑说你想做什么,它们就能够处理你的请求。[1]
手机在努力,用AI帮你P图、记笔记、做总结、发信息。
PC在努力,用AI帮你设置系统、操作软件、提升画质、提高游戏战斗力。
AI pin和Rabbit r1这样新概念随身设备从出生就在往AI Agent的方向努力,帮你实时访问GPT-4、自动操控手机应用和电脑软件。
产品层出不穷的同时,标准也随即诞生——由清华大学智能产业研究院(AIR)与小米、华为、Vivo、理想几家大公司联合出品,邀请产业专家依照Agent的能力,将其分成了L1-L5的五个能力等级。

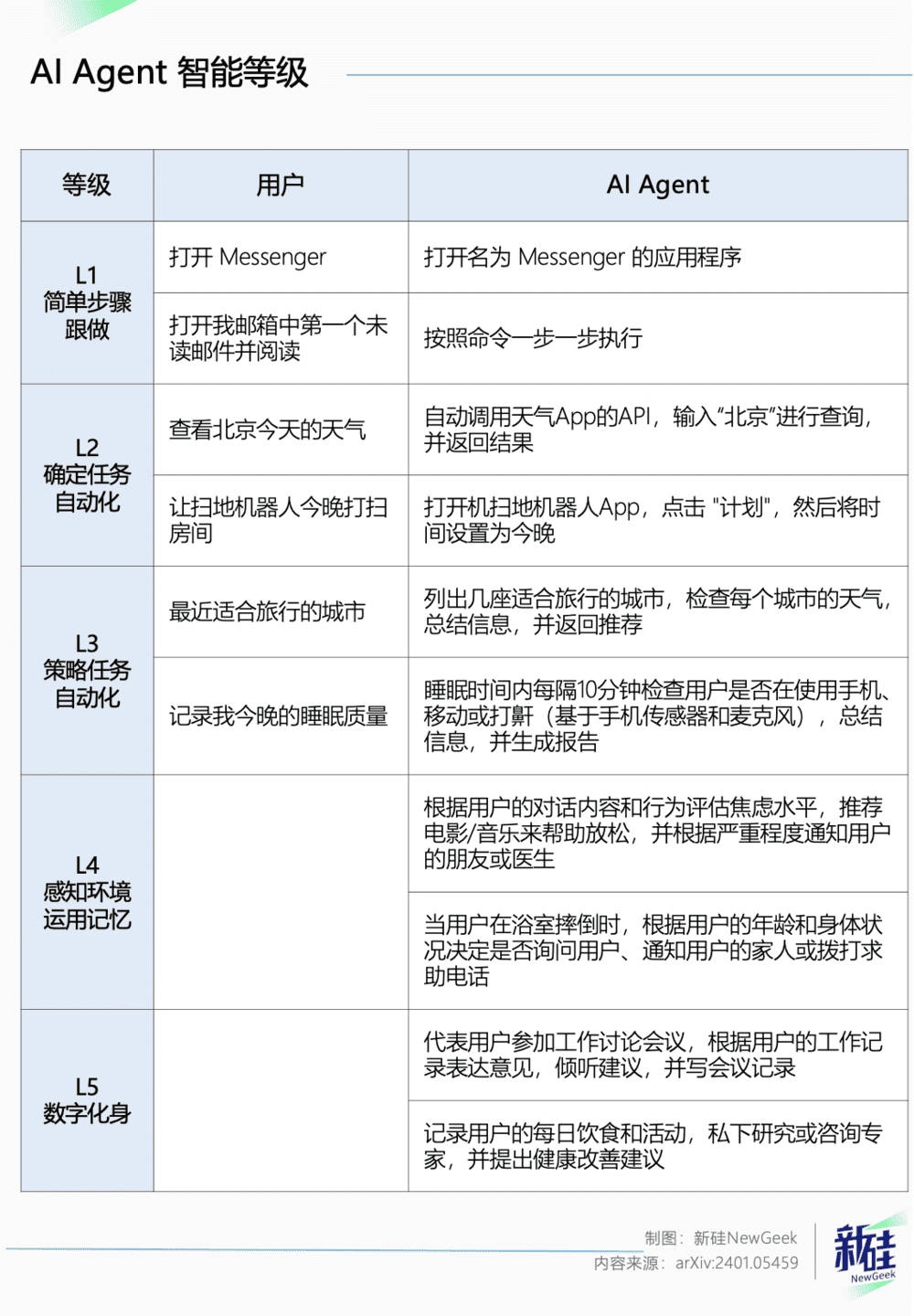
L1-L3级别的Agent需要用户给它定个目标。
L1级别用户说一步做一步,并且只能按照开发人员预制的步骤执行任务。
L2可以根据用户的目标自己拆解步骤,并操作相关App或者调用API。
L3可以执行更复杂的任务,一边推测用户意图,一边调用手头所有资源,还要根据每步的反馈及时调整计划,直到完成任务。
而L4-L5级别的Agent已经不需要用户指挥,能主动感知当前的环境和用户状态,并且结合历史数据,主动给用户提供个性化服务。
这个分级和自动驾驶很类似,在L3之前都还需要人类高度介入,而到了高阶水平就可以完全替代人类。
在共同制定行业标准之外,产业大佬们还从385篇论文中总结出了AI Agent的过去、现在与未来。
过去我们就不回顾了,就看看现在,然后顺便展望一下未来。
Agent在大佬们眼中的样子
我们先来看看围绕Agent部署的问题,大佬们的见解是怎样的。
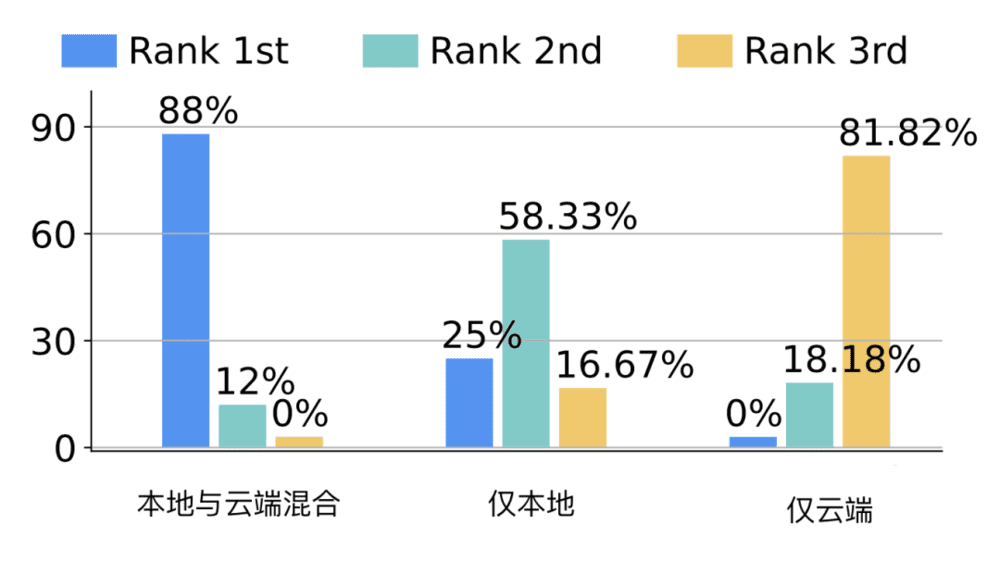
88%的人首选本地与云端混合方案,而且81.82%的人对现有的仅云端方案不满意。
不满意的原因主要是云端服务延迟高、个人隐私泄漏风险以及云服务的成本实在太高了。
仅本地的方案排名第二,主因是当下本地硬件的算力还无法支持高阶的Agent服务。
研究人员还调研了大佬们认为部署在个人设备上的AI Agent最需要哪种模态、最重要的能力以及哪种交互方式最有前景。
模态方面,大家可能是考虑到了本地部署,所以文本互动得分最高。
不过也有20%的人认为,影像(图片和视频)是未来AI Agent不可或缺的能力。
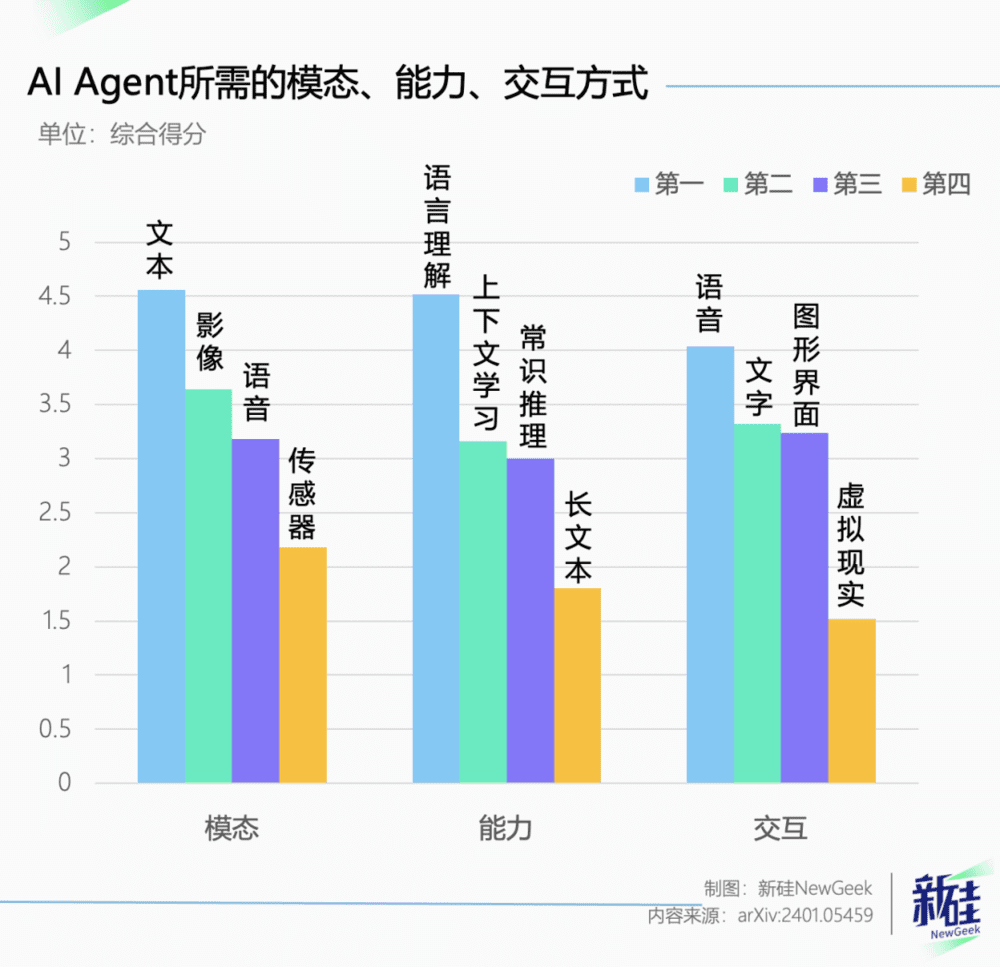
能力方面,虽然学术界对LLM处理长文本十分关注,但到了Agent应用这里,语言理解才是压倒性的第一。
毕竟你的Agent要是连用户的意图都识别不了,那接下来的推理和执行都进行不下去。
交互方式方面,大家目前最推崇的还是语音,即便VR今年有卷土重来的趋势,大佬们仍然觉得它价高不好推广且用户体验不佳。
Vision Pro那种空间交互方式压根就没在考虑范围内。
最后来看一下行业大佬未来想用Agent给客户提供些什么样的服务。
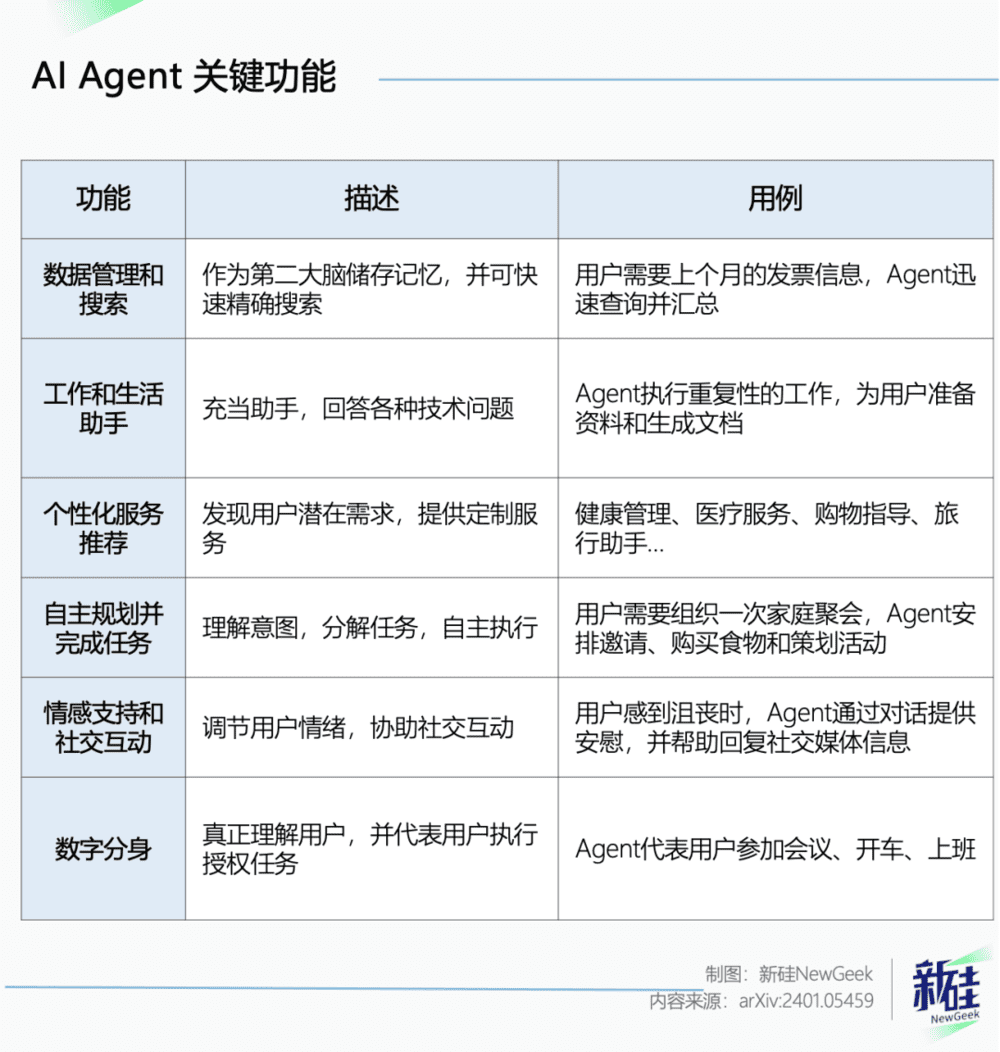
别说瞧见数字分身还真有点心动,克隆一个自己替自己上班的这天终于快来了(兴奋搓手)。
看了大佬们对Agent的见解不难发现,虽然LLM是Agent的灵魂,但只靠LLM是做不出一个好Agent的,或者说做不出一个L4-L5的Agent。
LLM之于AI Agent,就像中央处理器之于计算机,做的是对资源进行管理和调度。
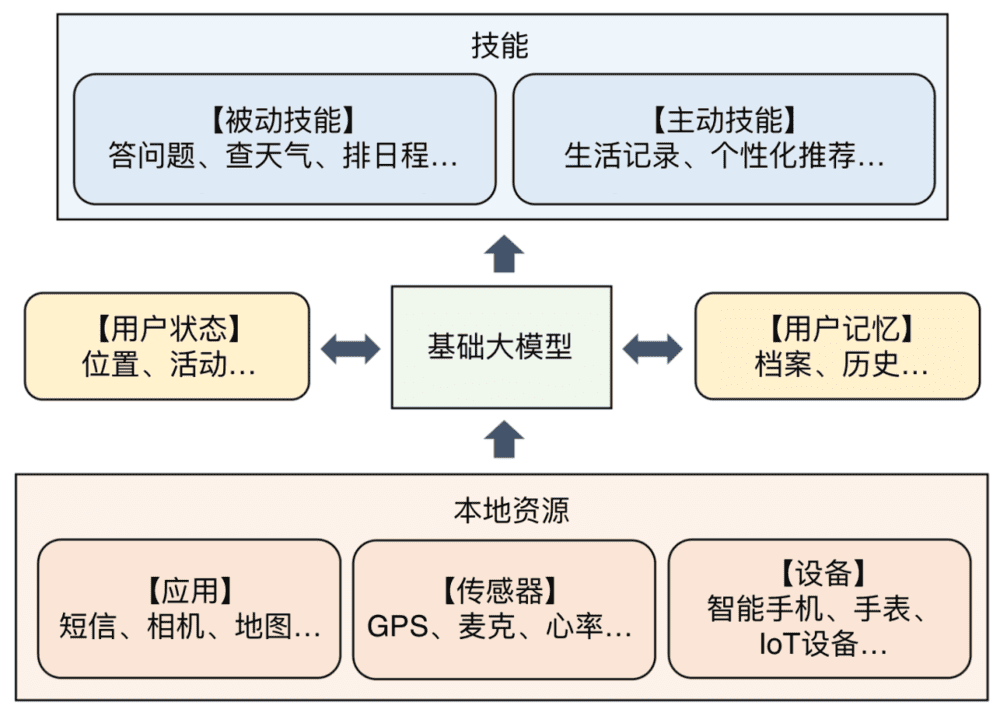
LLM首先通过获取顶层各种技能为用户提供服务,这些技能就像操作系统(OS)中的应用程序,可以添加也可以删除。
为了支持这些技能,LLM还要取得管理底层本地资源的能力,比如通过你的智能手表获取你的实时心率。
想要更智能的个性化服务,LLM最好还能获取当前用户的状态和历史资料。
比如结合你跟相亲对象的聊天记录和见面时的心率变化,判断你喜欢的类型,然后继续帮你在交友App、社交网络里寻觅这个类型并主动搭话,提升你相亲的成功率。
Agent的基础能力
功能架构基本捋清了,那为了给Agent打造这些功能,都需要哪些底层能力呢?
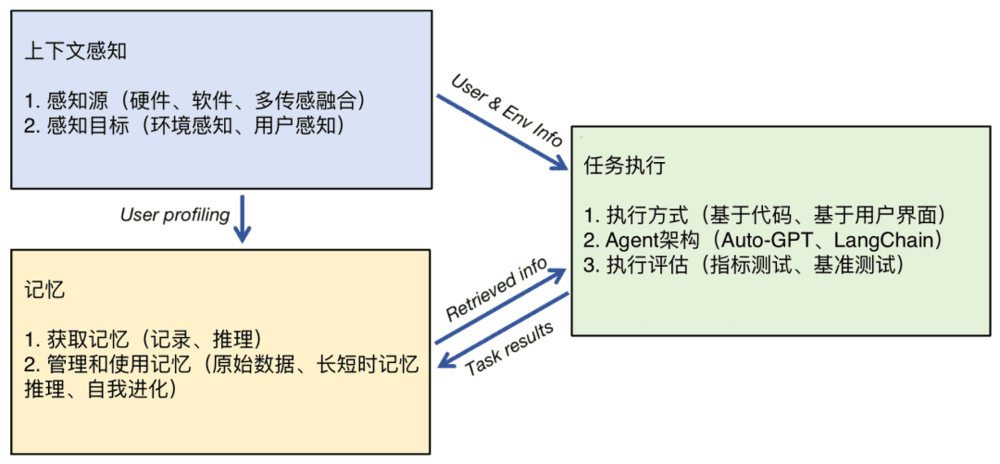
帮人干活,首先要有手(执行),再有眼(感知),最好再有个脑子(记忆)。
执行能力,也就是让LLM去触发帮用户干活的技能,主要有两种实现方式:通过代码或直接上手操作图形界面(UI)。
通过代码可以用传统的人工硬编码方式,也可以训练Agent自己写代码调用其他应用的API。
但是总有那么一些不爱配合别人的应用它不开放API,这个时候代码方式就不管用了。
所以有了第二种方式,让Agent直接模仿人类用户,通过滑动、点击等类人姿势操作应用以达成目的。
最近大火的Rabbit r1所用的LAM(Large Action Model)就是第二种。
不过UI方式执行复杂指令能力有限,让它点点手机App点个外卖是可以的,让它操作一下Blender这类3D建模的软件怕是连参数面板都找不全。
上下文感知主要是自动为Agent提供周围环境和用户信息,可以让Agent有主动判断主动执行的能力。
比如当Agent知道我现在身处图书馆,就可以自动帮我接听快递小哥的电话,然后把对话内容总结成文字发给我。
要感知这个世界,Agent可以从硬件传感器(GPS、麦克风、摄像头、光感、温度...…)和软件内(应用使用情况、通话记录、打字习惯)获得信息。
还可以把多个来源的信息综合到一起判断更复杂的事情,比如通过耳机和手机麦克风的声差进行动作检测。
通过这些感知,Agent需要分析出两个状态:环境状态和用户状态。
根据不同的环境,Agent可以侧重更场景化的应用,例如在会议室的时候集中精力做会议记录和安排工作计划;在健身房的时候就好好检测用户的呼吸和心率。
用户状态分为短期和长期两种,短期方面更聚焦于情绪、压力、动态,如果检测到压力指数上升,Agent可以通过聊天、推荐音乐电影等方式帮你缓解。
长期方面则是作为一个陪伴用户的老师、指导的形象而存在,比如可以根据用户的喜好、技能、市场环境来进行贴身的职业规划。
记忆能力,一方面是指Agent记录、管理、利用用户历史数据的能力,另一方面则是Agent本身可以不断学习新技能、新知识的能力。
获取记忆的方式有两种:直接从感知到的原始数据里获得,或者从原始数据里推理出来。
比如说原始数据是用户每天回家路上都会在一个特定的地点停留5分钟,Agent通过位置信息和支付记录推理发现,用户每天停留是为了买烤肠。
那Agent就会记录下用户喜欢吃烤肠这一爱好。
记忆的类型还分为短时记忆和长时记忆。
短时记忆也称为工作记忆,也就是Agent在处理某一项任务周期内调用的所有相关信息。
长时记忆则用来储存每一次任务周期产生的经验,可以在今后遇到相似任务时再调出来参考。
有了长时记忆的Agent好比一个记吃又记打的孩子,可以一点点建立自己对这个世界的认知了。
想端侧,提效率
有了这些能力,Agent要是还住在看不见摸不着的云服务器里,那对用户来说还是用处不大。
一个能帮上忙的Agent,还是要做到真正融入用户的生活,那部署方式最后还要选择端侧。
但是端侧的算力和能源十分有限,要想在有限的资源里提升Agent的智能水平,那就只能从效率入手。
这篇综述里给大家整理了3大类8小项,具体20种提升端侧Agent效率的方式。
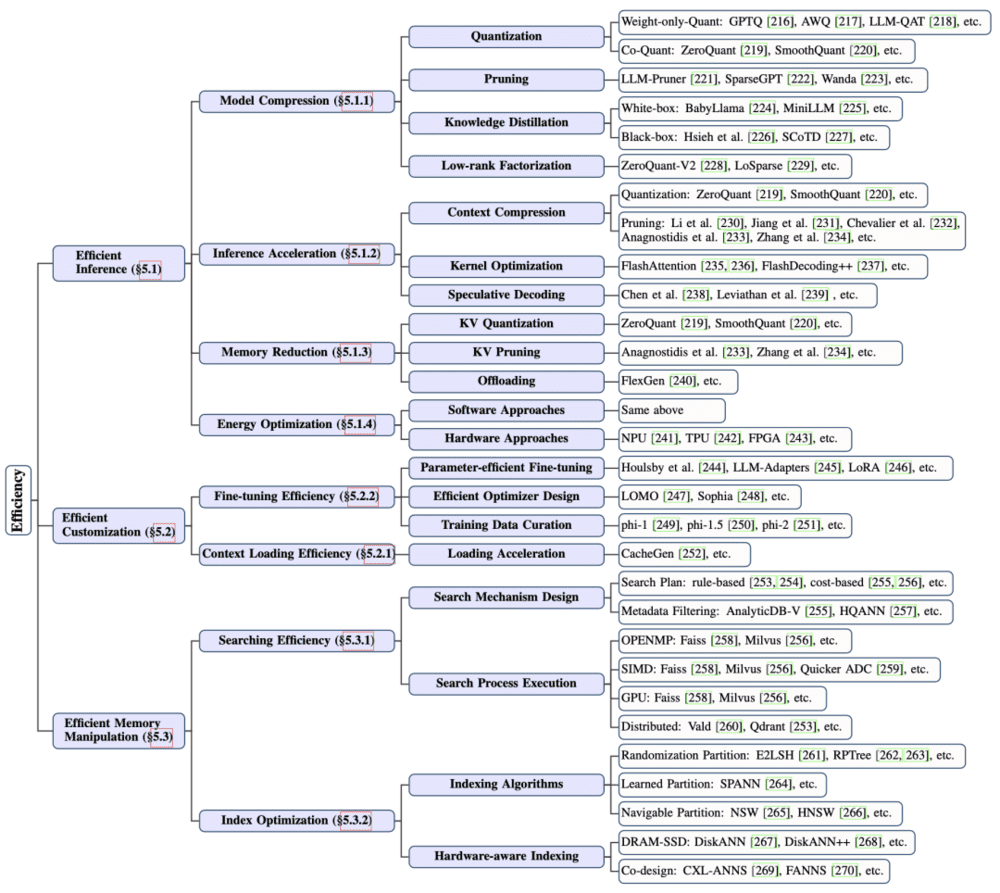
首先,LLM推理能力是重中之重,任务规划、调度执行资源、上下文和记忆的理解调用都需要用到推理,处理不好直接就成了Agent的性能瓶颈。
文中总结常用的推理提效方式有:把模型变小(模型压缩)、加速推理过程(增强上下文计算效率)、内存优化和从软硬件入手减少能耗。
然后,满足不同用户需求的必经之路是定制化,快速定制服务于不同用户群不同场景的Agent,以及让它低成本的与时俱进,是商业化必啃的一块硬骨头。
所以现在大家都忙着提升微调效率和上下文加载效率。
最后的内存优化管理则不只是Agent领域的提效方式了,不过的确是Agent要达到L5不得不做好的一件事。
Agent之后要打交道的数据不止文字,还有图片、语音、视频,还有可穿戴设备传回的健康情况,还有智能家居检测的环境状况。
单个用户的数据信息跨度动辄以年为单位,颗粒度甚至细致到每秒,如何管理如此庞大的数据库并提取出有效信息,还是个未解的难题。
这篇论文总结分析了很多,但硅基君看来,更像是大厂们联合起来发了个声明:以后做Agent,就都按照我们这套体系来评级吧。
参考资料:
[1] 比尔·盖茨都为之倾倒的AI Agent,究竟是什么|36氪
[2] Personal LLM Agents: Insights and Survey about the Capability, Efficiency and Security. arXiv preprint arXiv:2401.05459.
本文来自微信公众号:新硅NewGeek(ID:XinguiNewgeek),作者:刘白,编辑:张泽一,视觉设计:疏睿