
本文来自微信公众号:晚点LatePost (ID:postlate),作者:贺乾明、邱豪,编辑:龚方毅,题图来自:视觉中国
没有精心准备的发布会,没有声势浩大的宣传,凭借一篇博客文章、一份技术报告,全球大模型的格局可能又一次被改变。
当地时间 12 月 6 日,Google 发布三个版本的多模态大模型 Gemini(双子座),其中的 Gemini Ultra 版本对标最强大模型 GPT-4。Google CEO 桑达尔·皮查伊(Sundar Pichai)说:“这是我们迄今为止功能最强大、最通用的模型,在许多领先的基准测试中都领先。”
Gemini Ultra,参数规模最大、效果最好。Google 没有透露具体参数量,业内人士估计超过了万亿。性能对标 GPT-4 的大模型。
Gemini Pro,参数比 Ultra 版本少,优化推理成本,是 Google 在内部部署、对外提供服务的主力版本。现在已经应用于 Google 聊天机器人 Bard。
Gemini Nano,专门为移动设备训练的模型。针对不同内存的设备,训练了两个版本,参数量分别是 18 亿和 32.5 亿。
相比新模型在一些评测指标上追平甚至超过 GPT-4,Google 训练这个大模型的过程和方法,也许对整个大模型行业的影响更大。
作为由 Google 自研 TPU v4 和 TPU v5e 训练出来的大模型,三个版本的 Gemini 各有侧重,共同打破了之前的局限 —— 挑战 OpenAI 的同时,还有可能撼动英伟达在 AI 芯片的垄断地位。
Gemini Ultra 让 Google 进入大模型第一梯队
按照 Google 的说法,Gemini Ultra 在 30 项大模型能力测试中超过此前最强的大模型 GPT-4,在检验大模型数学、历史、物理、法律等 57 个学科知识水平的 MMLU 测试中评分达到 90%,是第一个超过人类专家的模型。
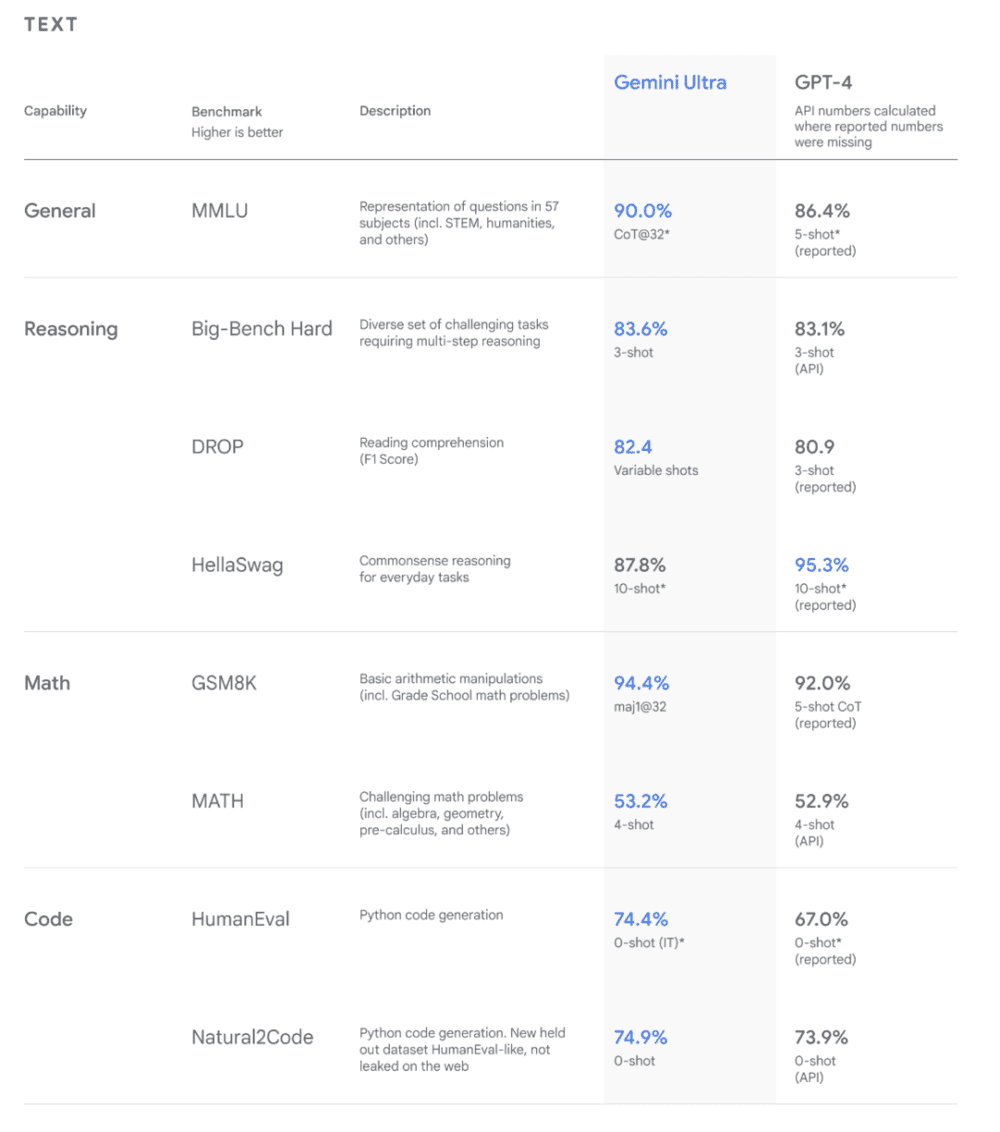
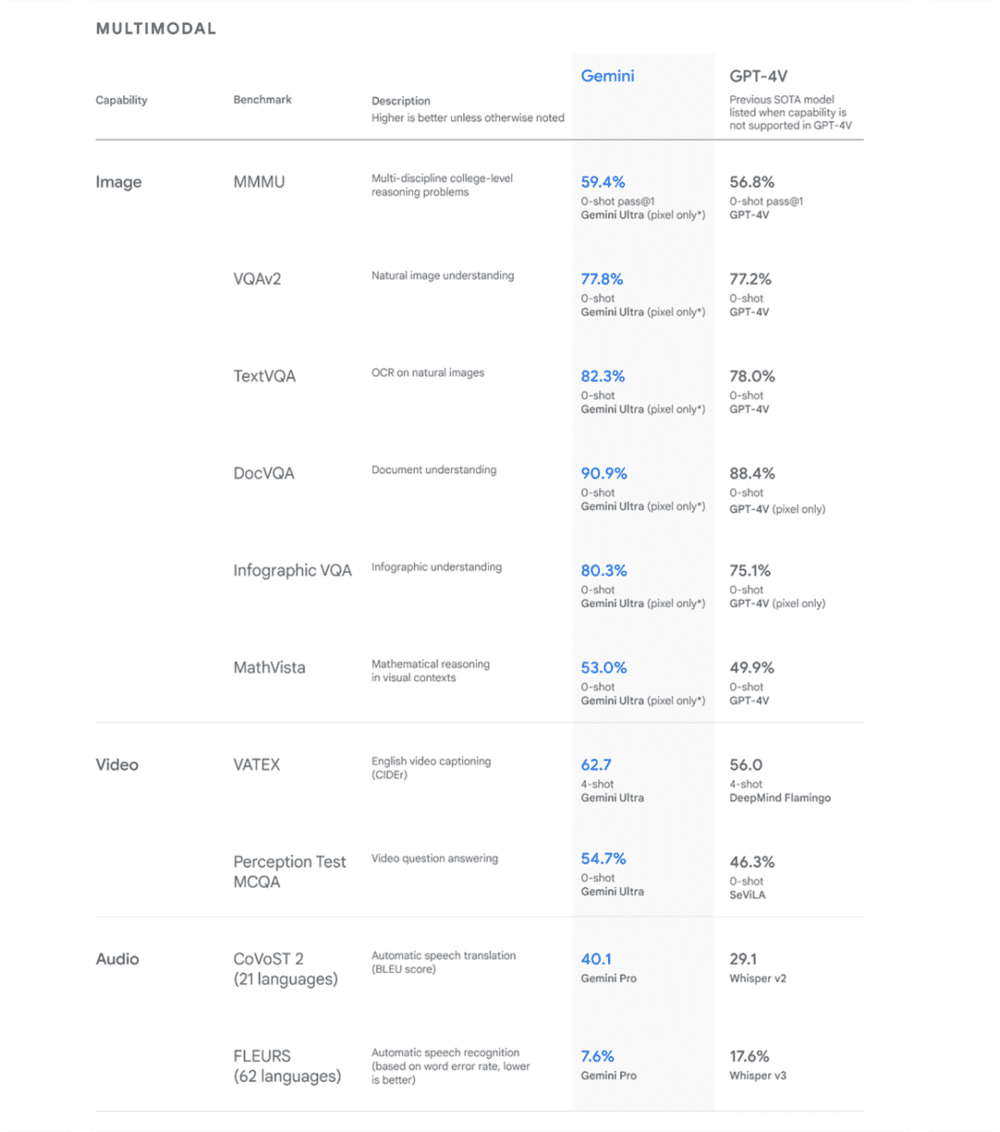
Gemini Ultra 在多项测评中超过了 GPT-4。左图是文本能力,右图是图片、视频、音频能力。图片来自 Google。
Google CEO 皮查伊用一段绘画视频展示了 Gemini Ultra 不同维度下的理解能力。当真人一边画鸭子一边与之说话时,大模型可以理解人类的每一步在做什么,并精确地说出来。
比如给鸭子涂蓝色的时候,大模型会说 “鸭子看上去是蓝色的”,接着在没有接受新提示指令的情况下,指出蓝色鸭子不常见。
但这个最强版本的 Gemini 要到明年才会向公众开放,它的真实效果能否超过 GPT-4 还有待验证。桑达尔·皮查伊在接受采访时解释,花更多时间是为了严格的安全测试,并挖掘它真正的功能。此前 OpenAI 训练完 GPT-4 后,花了半年时间做类似的事情。
另外两个参数更小版本的大模型已经以不同形式发给用户和开发者。Android 开发者已经能在 Google 的手机 Pixel 8 Pro 上使用 Gemini Nano 开发应用;Pixel 8 Pro 用户也可以用它总结录音纪要等。
同时,Google 把自己聊天机器人 Bard 背后的模型从原来的 PaLM 2 换成了 Gemini Pro。一些开发者测试后发现,效果虽然比原来的版本更好,但与 GPT-4 相比有不小的差距,甚至一些人说它只是 GPT-3.5 的水平。
看着 Google 的最新成果,人工智能领域专业人士和局外的华尔街多少有些淡漠。一些人工智能专家都没有像看到 GPT-4 时那样,感叹技术有了如此大的进步,而只是说 Google 回来了。在他们看来 Google 早该做到这些。
这似乎可以用来解释为什么 Google 盘后股价跌幅(0.74%)超过了纳斯达克指数。不过,这已经比它们年初发布聊天机器人 Bard 时好了 —— 那一次 Google 股价重挫 7.4%。
在人工智能浪潮中,Google 一直处于独特的位置。它是最早研究人工智能、也是技术实力最强的公司之一,拥有许多人工智能底层技术的专利。在 Google 的技术报告中,署名的 Gemini 贡献者有 837 人,比 OpenAI 整个公司的人(770)都多。
它也是世界上最大的互联网公司,每天服务数十亿人。它拥有的 Andriod 能直接影响全球 30 多亿人使用的手机。它比其他公司都更有能力收集海量的数据,不仅是文本,还有视频(YouTube)。
在基础设施层面,它已经研发人工智能芯片八年,很快将拥有世界上最多的人工智能算力。OpenAI 成立的原因之一,就是为了阻拦强大的人工智能只落在 Google 手中 —— 联合微软、英伟达,OpenAI 阶段性实现了这一目标。
Google 在云计算之后,再一次起了个大早、赶了个晚集。不过,它现在也有机会展示人工智能芯片的新选择:不用顶级 GPU,也可以训练出顶尖的大模型。
用自研 TPU 训练出顶级大模型,挑战英伟达
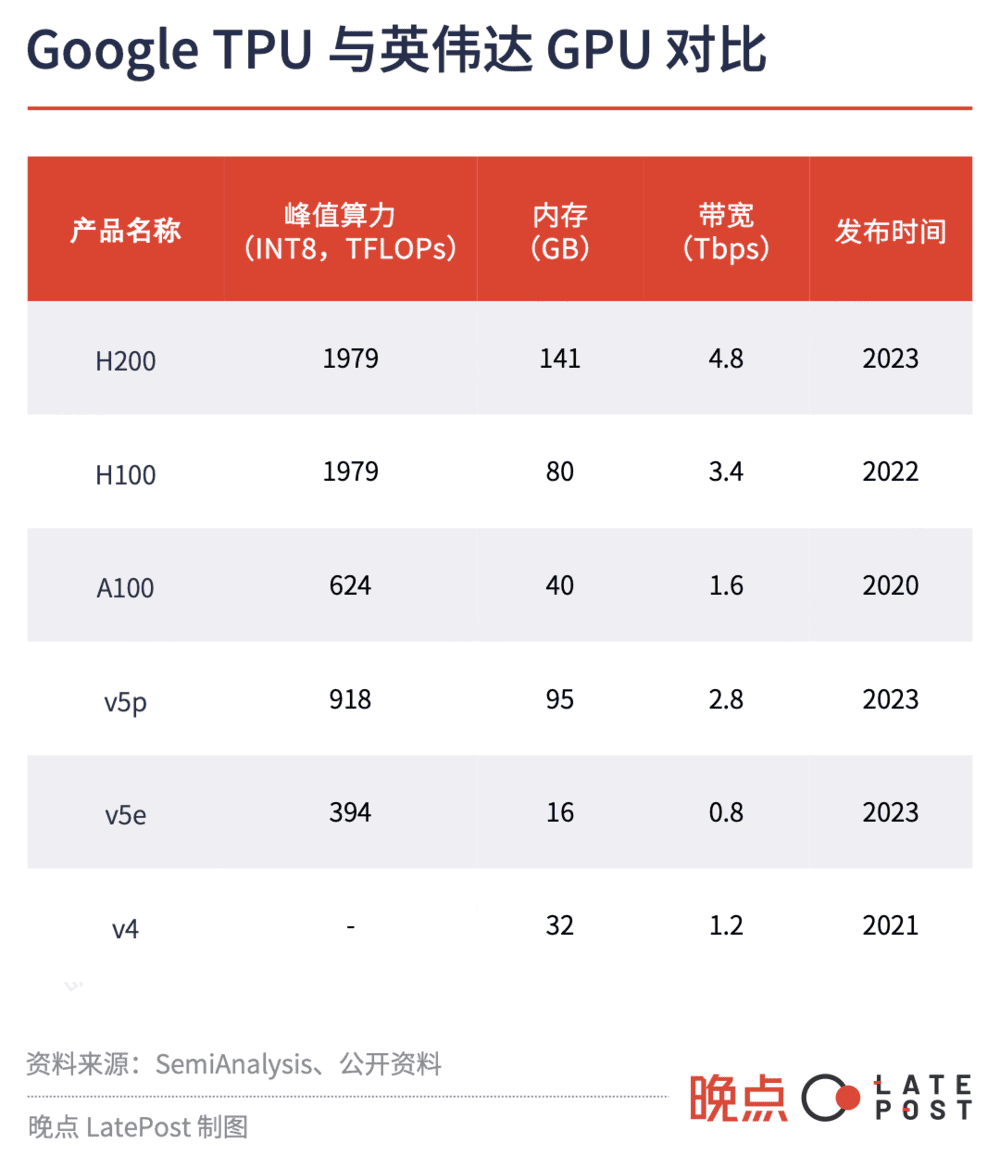
这次发布会上,Google 还带来新款 AI 芯片 TPU v5p,据称训练效果是上一代产品 TPU v4 的两倍。
只看单颗芯片性能,Google 训练出 Gemini Ultra 的芯片 TPU v4、TPU v5e,比不上英伟达的旗舰芯片 H100,各项性能指标最多只有英伟达三年前发布的 A100 的六成。
而且仅凭单个芯片或几十个芯片,已经很难训练参数规模动辄数十亿、上千亿甚至万亿的人工智能模型。据芯片研究机构 Semianalys 的首席分析师迪伦·帕特尔(Dylan Patel)估算,OpenAI 去年训练 GPT-4 动用了 2.5 万颗 A100 芯片,耗时三个多月。
Google 擅长把上千块 AI 芯片连接在一起,组成一个强大的算力平台。它 2015 年开始自研芯片,两年后就发布了 TPU 组建的训练集群(Pod),供庞大的内部业务(YouTube、Gmail、Google Map、Android)使用,一直迭代到现在。
“对于人工智能基础设施而言,系统能力比微架构更加重要。” 帕特尔说。Google 并没有公布训练 Gemini 动用了多少 TPU,只是强调动用了不只一个集群,甚至不止一个数据中心。
一个 TPU v4 集群最多有 4096 块芯片。帕特尔估计,Gemini 的 1.0 版本使用了 14 个 TPU v4 集群,耗费算力已经超过 GPT-4;而基于 TPU v5p 集群的 Gemini 的迭代版本(预计今年底完成预训练),消耗的算力可能是 GPT-4 的 5 倍。
原本受芯片、训练集群之间数据传输的带宽、甚至是宇宙射线影响(高能粒子穿透大气层,会影响芯片性能),利用大量芯片训练单个模型会提高故障率,硬件利用率也会大打折扣。但 Google 可以靠着更强的基础软件研发能力,尽可能让每个芯片都发挥作用。
Google 在技术报告中介绍如何训练 Gemini 时,一段话提及了三个训练框架——TensorFlow(其中的 XLA)、JAX、Pathways,都是 Google 自研的。
今年 11 月,腾讯机器学习平台部总监陶阳宇在一场技术交流会上透露,主流的开源框架动用大量芯片训练大模型时,硬件利用率只有 26%。同样的条件下,基于腾讯自研的 AngelPTM 框架训练大模型,利用率可以提高到 53%。
虽说英伟达一直自称软件公司,并投入数千名工程师优化 CUDA 等基础软件,但在大模型领域,Google 围绕 TPU 软硬件集成能力,可能更胜一筹。毕竟大模型的基础技术,如 Transformer,也是出自 Google。
Google 新发布的 TPU v5p ,算力性能大约是 H100 的一半,内存略高,带宽略低,单个集群容纳芯片的规模,达到 8960 块。“直到最近,许多组织训练大模型、用它提供大规模服务,仍然过于复杂、昂贵。”Google 云高管阿明·瓦赫达(Amin Vahdat)说,“借助 TPU v5p,可以让他们更划算地利用人工智能。”
短时间内,Google 想在单颗芯片性能上超过英伟达可能不太现实。但对于 Goolge 来说,通过软硬件高度集成能力,做出来一个能替代英伟达、不再给它交税的方案,已经就算成功。
当竞争对手们苦于买不到足够多的英伟达 GPU 时,Google 通过自研带来的算力资源不仅能让它更快地迭代大模型,还有机会通过出售硬件获取更多收入。它们宣称 Salesforce 和 Lightrick 等客户已经在使用 Google Cloud 的 TPU v5p 超级计算机来训练大模型。
多年来 Google 人工智能产品的研发和上线,要比小公司更多考虑法律和社会舆论风险,所以看起来异常保守,这也是不少 Google 员工认为 OpenAI 能抢先推出 ChatGPT 的原因之一。
面对着 OpenAI 和微软联盟的强劲攻势,Google 快速行动,整合习惯单打独斗的 Google AI 和 DeepMind,并开始推迟对外公开最新的研究成果,试图把原本失去的优势补回来——错失了云计算时代的 Google,已经很难接受自己在人工智能时代落后。
在 Gemini 技术文档中和公开发言中,Google 高管多次强调目前只是 1.0 版本,明年还会发布更先进的大模型。
今年早些时候,皮查伊被问到 “没抢在 ChatGPT 前发布 Bard,你错过什么”。他给了个大公司 CEO 的标准回答,Google 不是第一个做出搜索引擎,也不是第一个做出浏览器,“有时候成为第一很重要,但有时候无关紧要。” 他认为,只要不断改进产品,实现更好的功能,后发也能先至。
现在,皮查伊接受采访时,问题变成了 “你们通过 GPT-4 学到了什么?” 他的回答是:“现在远不是零和游戏,人工智能影响巨大,我们还处于很早期的阶段。前方充满机遇。”
本文来自微信公众号:晚点LatePost (ID:postlate),作者:贺乾明、邱豪,编辑:龚方毅