
语言和思维被认为是人类特有的能力,它们源于大脑强大的系统组合能力,可以通过已知部分理解和产生新的组合。例如,一旦人理解了“photobomb(抢镜)”这个词的意思,就能在各种情境中使用它,比如“photobomb twice(两次抢镜)”或“photobomb during a Zoom call(在Zoom会议里抢镜)”。同样,理解了“跳”之后便顺其自然地能理解“往后跳”。人类这种在新环境中轻松使用新习得词汇的能力,被称为系统泛化能力。
一直以来,科学家试图通过人工神经网络来模拟大脑,然而早在1988年,哲学家Jerry Fodor与认知学家Zenon W. Pylyshyn就曾声称人工神经网络缺乏系统泛化能力,因此并不适合模拟人类思维。在这场长达35年的激烈辩论中,反对者的论点主要集中在两个方面:首先,人类的组合能力也许并不像Fodor和Pylyshyn所说的那样系统化和规则化;另一方面,虽然人工神经网络的基本形式有限,但在使用过程中可以通过复杂架构来使其具有系统性。
近些年,神经网络在诸多方面(比如自然语言处理)取得重大突破,但与系统性计算有关的争论与挑战却一直存在。近期,来自纽约大学的心理学与计算科学家Brenden M. Lake和来自巴塞罗那庞培法布拉大学语言学系的Marco Baroni教授,利用人类实验与计算模型,证明了神经网络经过训练可以实现类似人的系统泛化能力,成功应对了Fodor和Pylyshyn提出的挑战。

图注:论文封面。图源:nature官网
为实现这一目标,他们引入了组合性元学习算法(meta-learning for compositionality,MLC)——一种利用少样本组合任务提升模型系统性的训练过程。MLC只需使用普通的神经网络,不需要添加额外的符号机制,也没有人工设计的内部表征或归纳偏差。相反,它强调的是从高层次的指示和(或)直接的人类行为数据中学习我们所期望的行为,这种学习过程又可以称为“元学习”。
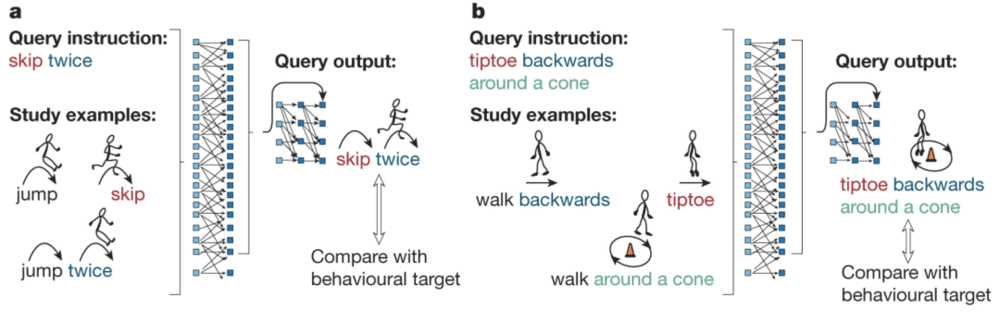
图注:网络结构和学习效果的语义图。a、b是两个不同的情境,对应两次神经网络的优化过程。模型的输入是查询指令与学习示例组合而成的整体。情境a中,学习示例演示了“跳两次”(jump twice)和“跨越”(skip)等指令如何与特定的输出对应,其中指令是单词形式而输出是基于文本的行为符号(箭头引导的火柴人图像)。查询指令中则将“跨越”这一个在训练过程中仅以单独形式出现的词汇进行了组合使用(“跨越两次”,“skip twice”),结果表明网络能够生成正确的输出。情境b展示的是对于“踮脚走”这个词实现了类似的功能,并且实现了更多情境的组合。图源:论文
为了更好地观察和阐释MLC的泛化能力,研究者直接一对一地比较了人类与模型的表现。
他们自创了一套伪语言,并要求被试在使用过程中来生成抽象输出(作为输入的单词序列和作为输出的符号序列是两类无意义词)。这与人工语法学习、统计学习和程序学习有所不同,因为在他们设计的训练过程中不需要明示或隐含的语法判断,后续计算系统能够直接基于人类行为构建序列到序列(seq2seq)的模型。
人类行为实验
他们首先测试了25名人类如何通过少样本学习将新学的词汇应用到不同情境中。被试需要学习14个“输入/输出对”,然后为10个新的查询指令生成输出。指令与输出序列之间符合一定的可解释的基础语法关系。
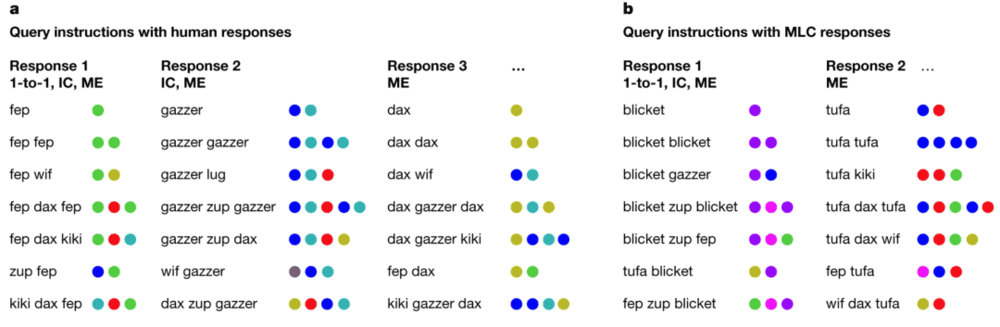
7个无意义单词中的4个被定义为语义词汇,又称为基本词汇,如“dax”“wif”“lug”和“zup”代表着基本的具体动作,如“跳”和“跃”;3个被定义为功能词汇,如“blicket”“kiki”和“fep”,指定了使用和组合语义词汇的规则,从而形成了类似“跳三次”或“向后跳跃”的序列。被试学习时需要学习语义词汇对应的符号输出,还需要通过符号的组合序列知道功能词汇的功能是什么,但他们不会被告知每个指令是什么类型的,而是只会看到如下图所示的14个对应关系。具体如下图所示。
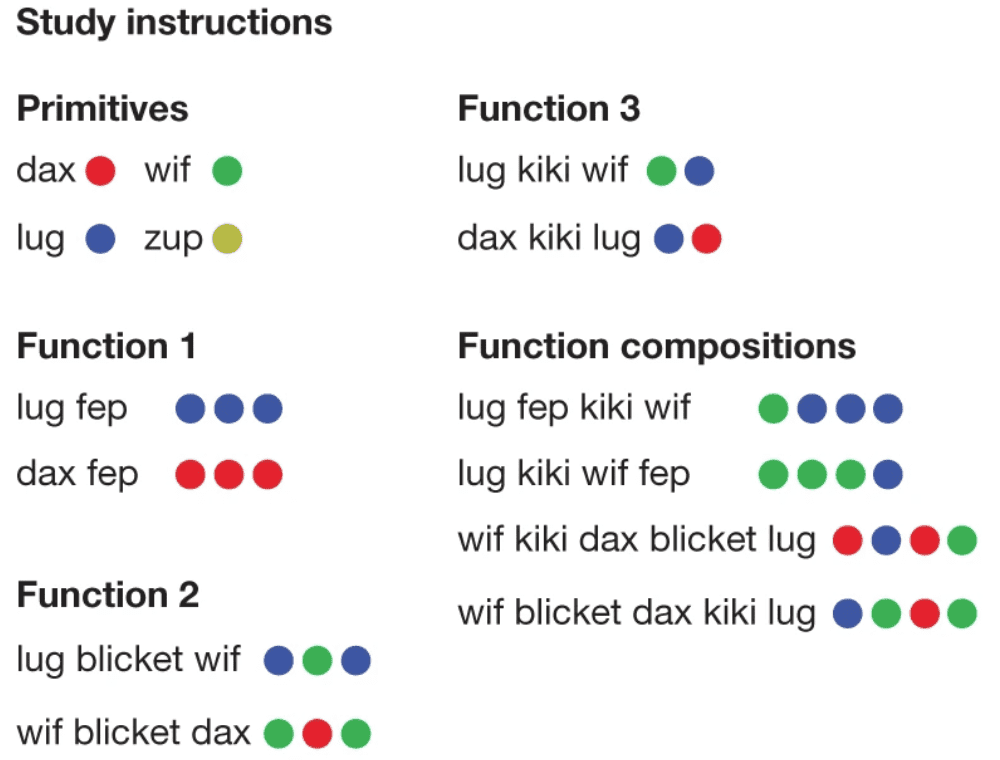
图注:指令学习。图源:论文
学习了基本语法后,研究人员让被试处理基本动作和功能的复杂组合,以测试他们应用这些抽象规则的能力。被试必须选择正确颜色和数量的符号,并将它们按照适当的顺序排列。
要取得好的成绩,被试必须从仅有的几个示例中理解单词的含义,并将其推广到更复杂的指令中。正如预测的那样,人类在这项任务中表现出色。平均来看,他们的准确率高达80.7%。这样的准确率是远无法通过随机选择获得的,并且对于长度最长的那些指令来说(在训练时也从未见过),人类被试的准确率也达到了72.5%,这样的泛化能力正是神经网络模型所遇到的困境之一。
研究者还对人类被试的常见错误进行了总结和归类。最常见的错误是“一对一”型的:被试没能理解功能词汇的功能,而是把它当作了具有单独语义的词汇,例如下图中被标记为“1-to-1”的错误。另一类常见错误是“符号串联”,这常常是因为被试使用功能词汇的时候不自觉地在输出中保持了与输入一致的顺序,例如下图中被标记为“IC”的错误。这些响应模式都与日常语言习得中可能发生的偏差相一致。
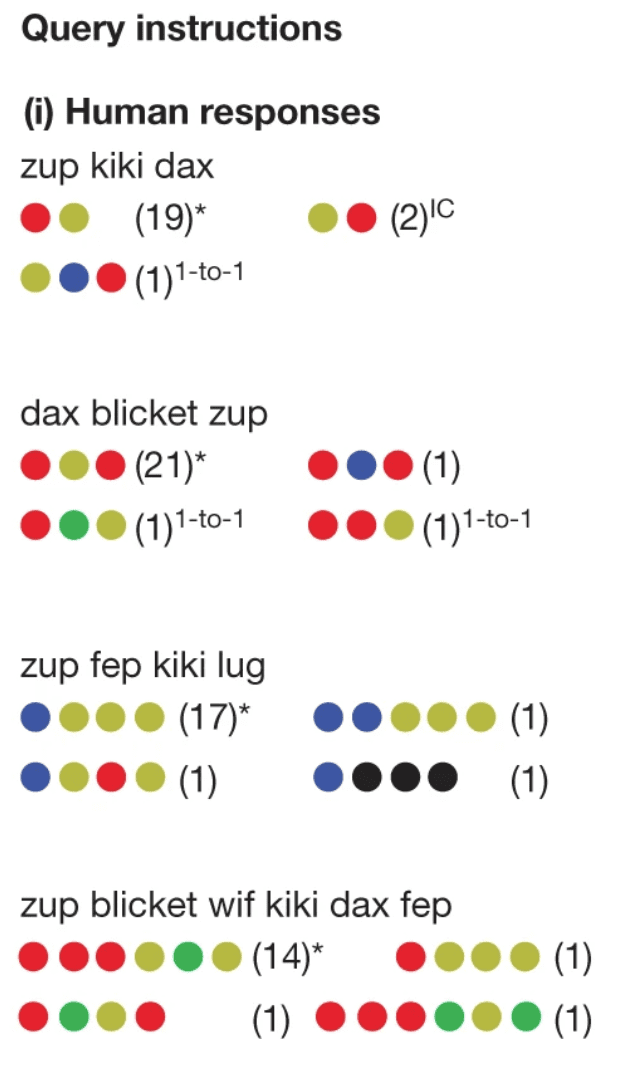
图注:四种最常见的回答,括号中标注了回答准确率(用计数表示)。图源:论文
为了更直接地评估上述归纳偏差,研究者还进行了一个开放式任务:被试不会看到任何学习示例,而是一次性看到所有查询指令,然后对它们之间的关系进行合理推测。通过这种方法,研究者可以更好地观察被试的先验偏好和归纳偏差,因为他们没有先前的学习示例来引导回答。
尽管在测试过程中,被试的行为不受限制,但他们的答案仍然高度结构化。除了再次验证了上述两种归纳偏差外,被试的回答还遵循了与互斥性相关的第三种偏差:将独特的含义分配给独特的词汇。这表明人们在处理任务时倾向于将不同的词汇与不同的含义关联起来,以保持它们的唯一性。
元学习与transformer架构模型
想要在具有挑战的泛化性任务中模拟人类的系统性泛化和错误模式,一个成功的模型必须能够从极少的示例中以系统性的方式学习和使用词汇,并能捕捉输入与输出之间的结构化关系。
MLC的目标是引导神经网络调整参数值,以便在面对未知任务时实现泛化,并克服以前关于系统性的限制。重要的是,这种方法旨在模拟成年人掌握语言后的组合能力,而不是关注语言习得的过程,后者则是另一个问题。MLC采用的是标准的transformer架构,进行基于记忆的元学习。元学习指的是,不仅仅学习某一对输入/输出之间的联系,而是学会由输入产生输出的抽象规则。
下图展示了模型的编码(底部)和解码(顶部)过程,MLC利用查询输入和学习示例(输入/输出对)来优化transformer。这种方法允许人工智能在完成每个任务时学习,而不是使用静态数据集。每当有新的学习和查询示例出现时,模型都会进行优化。
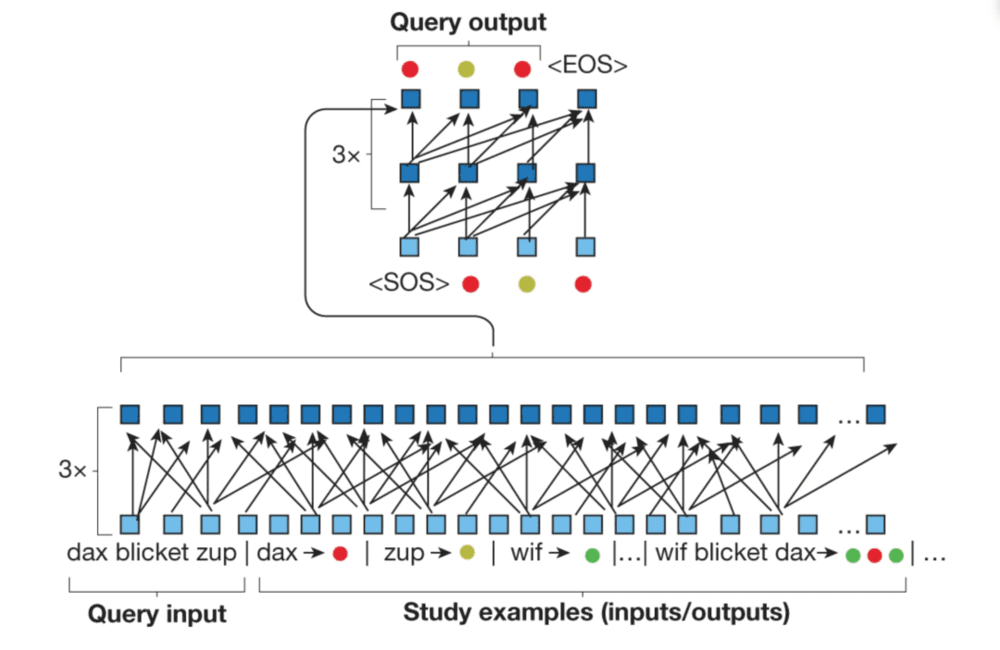
图注:MLC架构。标准的transformer编码器(底部)处理查询输入以及一组学习示例(输入/输出对);示例由竖线(∣)符号分隔。图源:论文
在这个任务中,每个训练集对应一个不同的序列对应任务,也就是每个被试学习的那些随机生成的隐藏语法,用来将输入与输出进行对应。
为了成功解码,transformer必须从学习词汇中提取出合适的参数值并利用它们生成查询答案,这个过程依赖于元学习训练,也离不开transformer这样的创新架构。而这些创新在Fodor和Pylyshyn的论证中都没有被预见到,例如可变长度的输入、参数共享和自注意力机制。
在测试阶段,模型权重全都被固定了,也不再提供任何任务特异的参数。最后,考虑到此模型的最终目标是模拟人类行为(包括犯错行为),研究者还将标准答案或错误输出(由一对一转换或错误使用规则产生)随机配对,这种随机配对的比例与人类被试的观察数据大致相同。
模型与人类行为对比
接下来,实验者评估了MLC在处理这些具有挑战性的泛化任务时,产生类似人类的系统性泛化和错误模式的能力。结果表明,MLC能够优化模型以实现高度系统化的行为。在某一次训练中模型达到了与人类被试完全相同的系统化行为(100%的精确匹配),而且能够推导出元学习过程(模型训练阶段)中没有出现过的新规则。
为了更深入地比较人类和机器的学习效果,研究者对模型输出的分布进行采样,发现MLC还能实现更微妙的受偏差驱动的行为,使transformer以接近人类表现(80.7%)的平均比例(82.4%)生成了系统化的输出。在处理更长的输出序列时,系统输出的比例(77.8%)也很接近人类水平(72.5%)。
在“一对一转换”和“符号串联”这两项人类常犯的错误上,MLC transformer也表现出了和人类被试相近的比例。此外,MLC的表现还能预测人类行为,即对于MLC来说准确率更低的指令对于人类被试来说也更难。

图注:四种最常见的回答,括号中标注了回答准确率(人类的用计数表示,MLC的用样本百分比表示)。图源:论文
模型间的性能对比
为了更准确地测试MLC模型在完成“少样本学习任务”过程中的效果,作者还训练了另外若干个模型,并比较不同模型与人类回答的相似程度(对数似然)。
用来比较的模型有以下几种。
1)概率符号模型:假设人类可以推断出真实语法规律,但是会偶尔出现随机的失误。
2)带偏差的概率符号模型:一类特殊的概率符号模型,出现失误的概率基于人类发生偏差的频率得出。
3)基础编码-解码模型:仅仅学习某一套规则而不进行元学习训练。
4)仅具复制功能的MLC:一个具有优化复制能力而不是系统泛化能力的MLC模型,在训练阶段查询示例总是匹配某一个学习示例。
5)仅学习代数规则的MLC:一个和MLC经历了相同训练过程,严格符合代数输出回答但是不具有偏差。
6)联合MLC模型:针对少量指令和开放式任务进行联合优化。
结果发现,MLC比大多数模型都表现得更好。不过,在少样本学习任务中,带偏差的概率符号模型的表现基本达到了MLC的水平。这不意外,因为MLC做的是类似的优化,隐式地推断系统规则,并以相同的偏差模式进行作答。
虽然MLC和概率符号模型都可以很好地描述人类的少样本学习行为,但在开放式行为测试中,MLC更具优势。
图注:开放式指令任务。参与者在没有看到任何示例的情况下对询问(语言字符串)给出了回答(彩色圆圈序列)。图源:论文
训练过程与之前类似,利用相同的transformer模型,基于人类被试在开放式实验中的行为进行优化,然后逐一产生针对七个指令的输出,从而测试模型在开放式任务中的表现。结果发现,在65.0%的样本中,MLC变换器与人类被试产生了完全相同的回答,完美地呈现了三个关键的归纳偏差。
而除了基于少样本学习任务训练的MLC模型,表现最好的其实是联合MLC模型,它能够同时实现少样本学习任务和开放式指令任务优化,并且在预测人类行为方面表现出色。
基准测试集评估
除了预测人类行为之外,研究者还利用机器学习领域的系统性泛化任务基准数据集——SCAN和COGS——进行了测试。这些数据集中的示例都是由其设计者通过代数规则生成的,没有直接的人类行为数据。本研究重点关注它们的系统词汇泛化任务,探讨如何处理新词汇和词组(而不是新的句子结构)。
SCAN数据集涉及将指令转换成动词序列,例如将“walk twice”转换为“WALK WALK”。在“add jump”分组中,训练集只包含一个“jump”的示例(映射到“JUMP”),测试集则包含了该动词的组合使用(例如“jump around right twice and walk thrice”),这样的功能与之前介绍的人类学习任务相似(例如“跳跃”可以类比为“zup”)。COGS涉及将句子转换成表达它们含义的逻辑形式,例如,将“一个气球被Emma画了”转换为“balloon(x1) v draw.theme(x3, x1) v draw.agent(x3, Emma)”。COGS评估了21种不同类型的系统化泛化,其中大多数涉及名词和动词的单样本学习。
MLC仍然只使用了标准的transformer组件,但为了处理更长的序列,它在处理学习示例的方式上增加了模块化的设计。为了增加少样本推理和意义组合,研究者在两个基准测试集中使用了表层词类置换——这是元学习的简单变体,使用了最少的结构性知识。通过置换,可以在原有词汇表的基础上改变词汇的含义,用来近似更自然、持续引入新词的情况。
总的来说,在两个基准数据集中,MLC的错误率极低。在SCAN测试中,MLC解决了三组系统性泛化任务,错误率低至0.22%以下。在COGS测试中,MLC在18类词汇泛化任务中实现了0.87%的错误率。没有进行元学习的情况下,基本的seq2seq模型在这些基准测试中的错误率至少是元学习的7倍。
总结
35年前,当Fodor和Pylyshyn提出关于神经网络的系统性问题时,他们无法想象当今模型所能达到的效果。尽管将本文开发的工具应用于各个领域还有很长远的路要走,但从中可以看到,元学习在使人工智能系统的行为更像人类方面确实大有可为。
自然语言专家Elia Bruni表示,这项研究可能会使神经网络成为更高效的学习者。这将减少训练诸如ChatGPT等系统所需的巨大数据量,并减小模型中“幻觉”的问题,即当人工智能感知到不存在的模式并创建不准确的输出。
参考文献:
Lake, B.M., Baroni, M. Human-like systematic generalization through a meta-learning neural network. Nature 623, 115–121 (2023). https://doi.org/10.1038/s41586-023-06668-3
https://www.nature.com/articles/d41586-023-03272-3
本文来自微信公众号:nextquestion(ID:gh_2414d982daee),作者:赵诗彤