
11月7日凌晨,全球科技圈的目光都集中在旧金山市场街的一个展览馆中,离这里两个街区外,就是马斯克治下的X总部大楼。
OpenAI,这家引发了全球AI大模型军备竞赛的公司在这里召开第一届开发者大会(OpenAI DevDay),全球意图在AI浪潮下分一杯羹的参与者们都屏住了呼吸。
OpenAI的生态野心
45分钟的开幕发布会总结下来分成8个环节:
回顾:展示去年11月30日ChatGPT发布预览版以来的成果;
GPT-4 API升级为GPT-4 Turbo:功能更强大的新模型;
Assistance API: 为开发者提供创建辅助代理的简化流程;
GPTs:可通过自然语言创建用户自定义的GPT;
GPT store:类似App store,允许用户分享和使用GPTs,并提供收入分成;
感谢微软:微软CEO强调和OpenAI的友好关系;
感谢团队:老板感谢员工的努力;
功能展示:开发者体验负责人展示如何在GPT上开发应用。
刨去秀肌肉环节,整体来看这场发布会的核心主旨就一个:OpenAI正在全力创造一个围绕GPT存在的生态环境。
具体来看这些更新,对于普通用户而言,除去界面简洁化,过去GPT-4、DELL和Bing还得从菜单里选择一个使用,现在合并了之外,最重要的更新是GPTs和GPT store的组合拳。
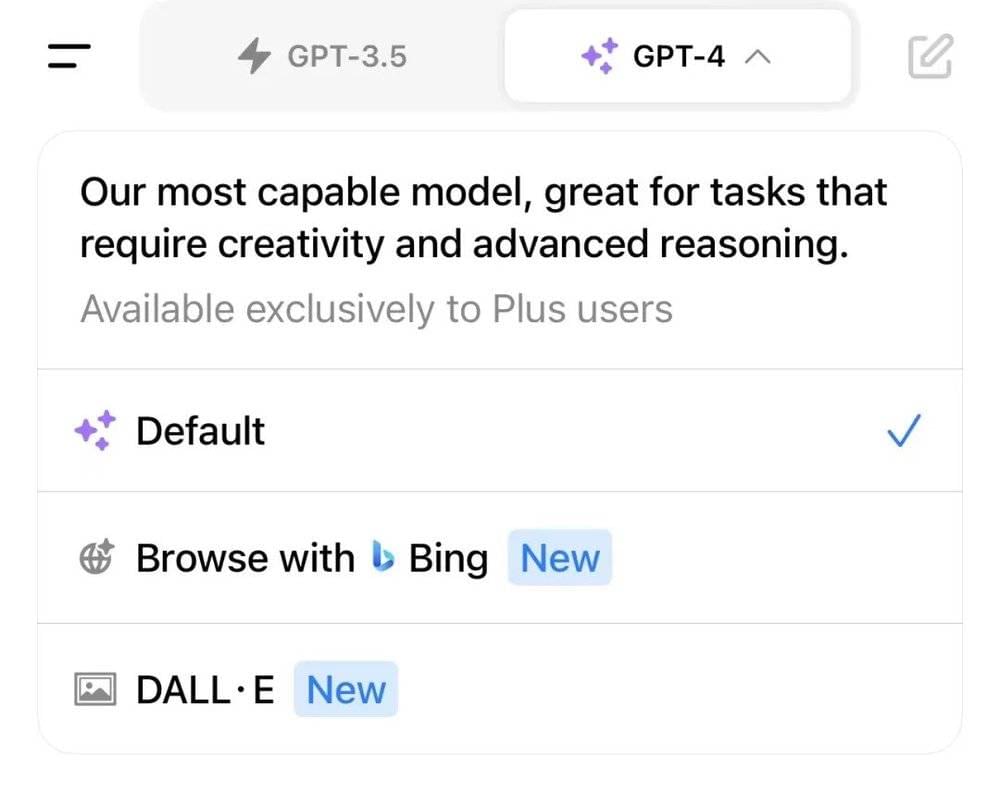
以后就不用这样选了
前者允许用户无需编写任何代码,通过自然语言和知识库即可创建一个定制版本的Chat GPT,比如专门画日漫的画手、专门写遥遥领先软文的作者、专门处理邮件短信回复的秘书等等。
这既可以为个人生成一个独属于自己的伴侣,也可以分享到GPT Store,向其它用户收费使用。
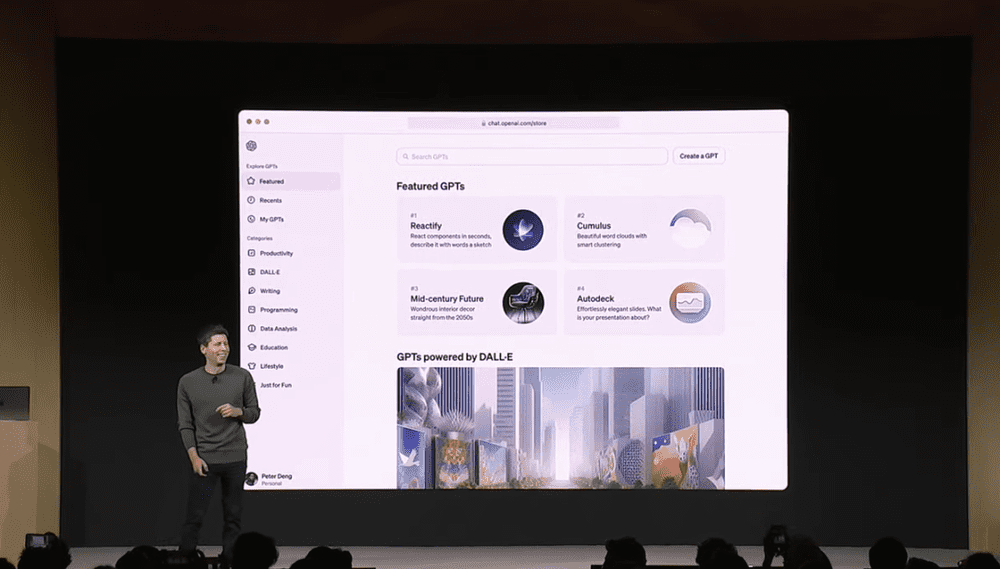
GPT store这页面是不是有种熟悉感
可以预想在这个商城中将会有大量由用户自发创建,用于高度垂直细分领域的GPT,但这种由自然语言创建的GPT功能并不会很强大。
毕竟其本质上就是将“指令、知识库、动作”三者结合,在AI的辅助下高速生成结果。
这可能会成为GPT store最庞大的组成部分,但真正的生态主力军,依旧需要专业的开发者来完成。
Assistants API由此而生。
简单来说,这个提供给开发者使用的工具同样是创建一个“GPTs”,但相比于自然语言,它可以接受的指令、知识库、动作三者在API工具的加持下更为多样,从而诞生能力更加高级的自定义GPT。
同时通过其诞生的“助手应用”是可以直接用在开发者自己的软件中的,等于说只要大家愿意,所有软件公司都可以微调ChatGPT然后用来强化自家的应用,比如Soul上搞几个AI女友之类的。
这实际上就是当下AI应用场景中,作为“Agent”而存在的最佳体验。
为了刺激开发者使用这一功能,OpenAI宣布了全面降价。新模型的价格是每千输入token1美分,而每千输出 token3美分,总体使用降价约2.75倍,同时GPT-3.5Turbo 16k可以进行微调订制,价格相对此前报价较低。
这些实际上展示了OpenAI所走的一条商业化路径:全力打造以大模型为基础的闭环AI生态。
北美科技巨头的分化
在AI浪潮下,美国的科技巨头们已经出现了明显的路径分化:
OpenAI加持下的微软,DeepMind加持下的谷歌选择闭源,以底层模型为核心构建生态从而变现。
而Meta和亚马逊则选择开源,意图培养繁荣的开源社区,以求将其云服务送入千家万户。
这种路径分化是由技术储备所决定的,也就是微软和谷歌相对来说拥有更强大的AI模型技术。
从2017年的谷歌公开革命性的Transformer和Bert模型,到2020年的GPT-3和2022年的ChatGPT,AI领域先行者的地位明显由这两家巨头所主导,其它厂商只能跟着其开源资料和公开论文进行模仿和创新。
根据NeurIPS的统计,谷歌和微软(包含旗下公司)在2022年发布了约 60%的大语言模型相关学术论文,而当已经取得明显技术优势后,两家巨头纷纷开始商业化的探索,并走向闭源,不再公开细节。
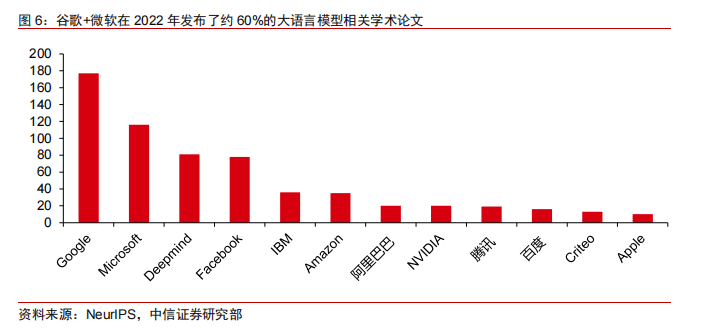
今年以来,微软和谷歌的商业化策略已经出现明显路径。
在消费级层面,微软利用其AI能力为Dynamics、Office直接向用户提供高客单价服务,在开发者层面推出GitHub Copilot以支持生态拓展,在最上游则通过云计算平台Azure提供算力支持。
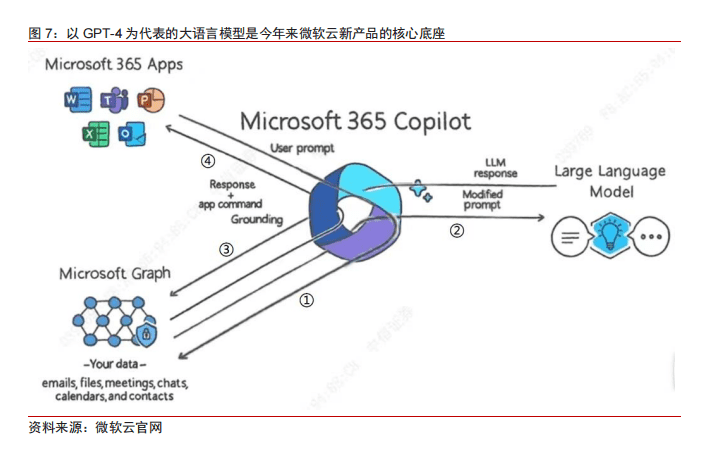
在日前微软发布的今年三季度财报中,AI带来的收入和利润增量已经开始体现。
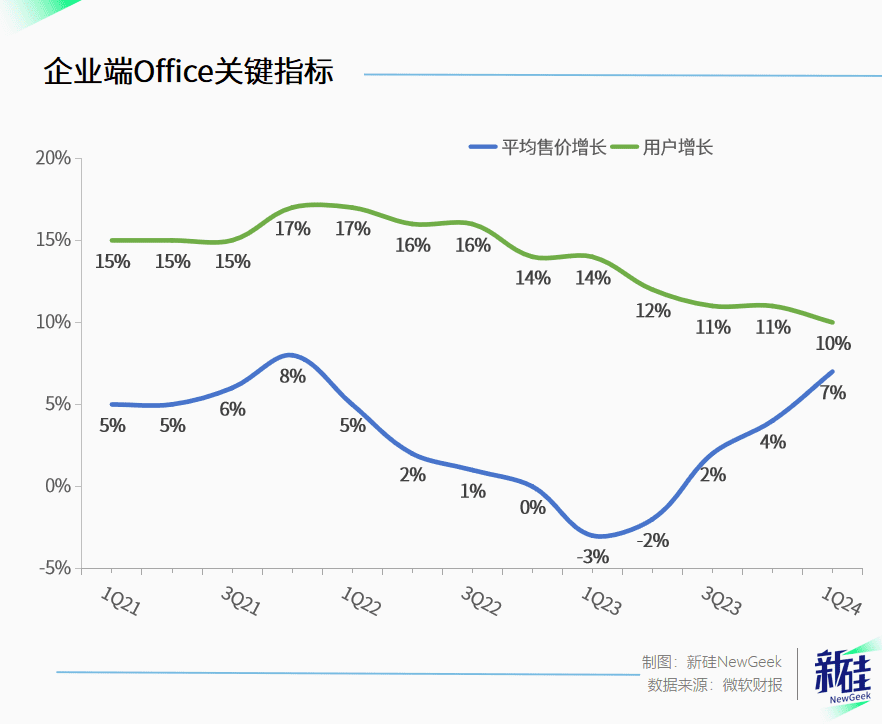
在企业端,Office 365的订阅人数增长实际上陷入了瓶颈,本季度同比仅增长10%,环比甚至下滑2.5%,在客单量达到3.08亿的情况下,客单价却上升2美元,最终导致该业务收入超预期增长。
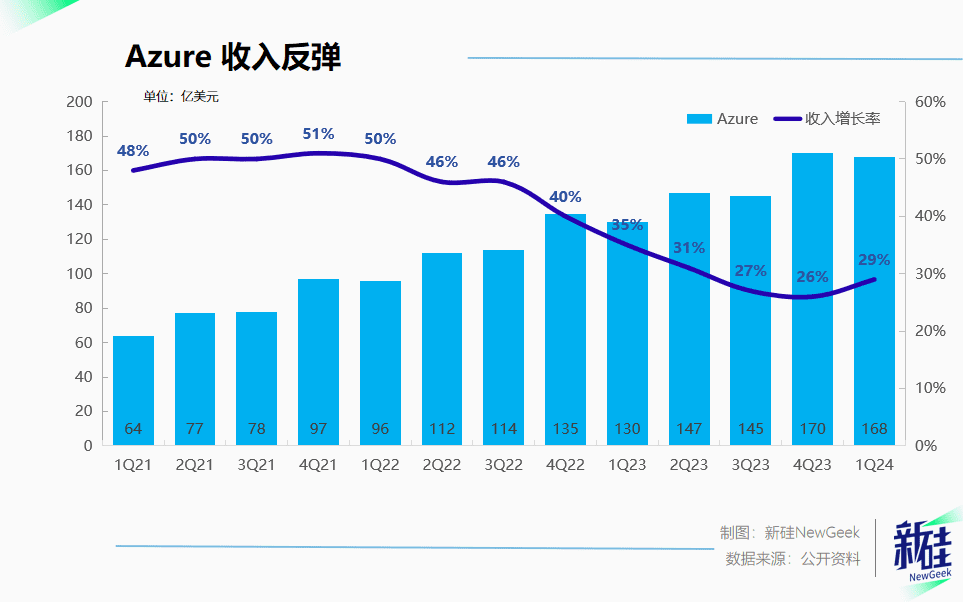
同时微软智慧云业务以Azure为核心,同比增速在连续7个季度放缓后,本季终于重新提速到29%,这背后就是AI浪潮下推动的算力需求。
与之类似,谷歌的Bard模型、Workspace与Vertex AI等产品以及谷歌云,OpenAI此次开发者大会公布的内容都和微软殊途同归,皆是以底层模型为核心,刺激软件生态开发,并不断扩充产品线。
另一边则是亚马逊和Meta。其Titan和LLaMa模型在技术指标上相对于GPT-4有明显的差距,因此当前两家公司都没有推出和模型相结合的应用端。
同时选择开源,寄希望于社区开发者的力量加速模型迭代以缩小模型技术差距。

因此,这两家公司当下AI相关收入只有云计算业务,尤其是大厂们会对AI初创公司进行投资,然后要求这些公司使用自家的云服务。
比如十月初亚马逊投资Anthropic后,公司宣布亚马逊AWS将成为Anthropic关键任务工作负载的主要云提供商。
在技术能力不足,应用端缺失的情况下,这也是一种应对之策,同时也极其类似智能手机市场安卓和ios之间的两条道路,可高度定制化的安卓和稳定性极强的ios之间并不存在明显的优劣之分。
国内大模型的类似道路
北美科技巨头已然出现分化,我国科技巨头也正在初现端倪。
闭源的百度文心一言更接近微软和谷歌的道路,而阿里云及其通义千问则有着Meta和亚马逊的影子。
2012年,吴恩达的老师,如今高喊着人工智能毁灭世界理论的辛顿教授带着自己另外两名学生,创造出了一个名为AlexNet的算法。
其极低的算力使用和超高的图像识别准确度轰动了整个计算机科学界,同时也为深度学习的引爆奏响了第一个音符:
同年的12月,为争夺辛顿团队,四家公司参与了一场秘密竞拍,它们分别是Google、微软、DeepMind和百度。
前面三位如今成为了北美AI领域的领导者,而在国内,百度则是最早一批把真金白银投进AI的科技公司。
2013年1月,李彦宏宣布百度将成立专注于Deep Learning深度学习的研究院——即Institute of Deep Learning,简称IDL。
IDL成为了百度搜索、语音识别、自动驾驶技术的孵化器,文心一言大模型也自其中诞生。而在今年百度的诸多发布会上,李彦宏及一系列高管都在强调同一件事——AI原生应用重于一切。
“没有构建于基础模型之上的丰富 AI 原生应用,大模型就一文不值”,李彦宏在百度世界大会上说道,这种思路与微软和OpenAI异曲同工。
在消费端,今天我们可以看到百度在不断尝试将文心大模型融入其自家的搜索、网盘、文档等应用,在开发者端部署了千帆大模型平台以降低开发门槛,在云计算端同样有百度智慧云。
而另一边的阿里,从这次云栖大会的slogan“计算,为了无法计算的价值”就可以看出,其核心主题在于一个ABC合流的概念,即AI+Big data+Cloud。但在云栖大会上,阿里云却更加强调云计算作为“辅助AI大模型发展”的身份而存在。
比如云栖大会第一天上午的开幕式上,蔡崇信为阿里云提出新定位,“要打造AI时代最开放的云”,同时将绝大多时间都留给了其AI合作伙伴,比如王小川的百川智能。
又比如阿里当天发布开源的通用模型通义千问2.0,同时发布基于其训练的八个垂类行业模型。这条路看似又和Meta亚马逊不谋而合。
两条道路最后谁能赢?不妨让子弹再飞一会儿。
本文来自微信公众号:新硅NewGeek(ID:gh_b2beba60958f),作者:张泽一,视觉设计:疏睿,编辑:戴老板