
你到底对大模型这个东西了解多少?
如果你问百度,他会告诉你Generative Pre-trained Transformer(GPT),是一种基于互联网可用数据训练的文本生成深度学习模型,这时你对大模型产生了一个基本概念。
如果你看了很多报道,可能会知道GPT-3的参数量为1750亿,使用的数据集容量达到了45TB,GPT-4有1.8万亿参数规模,训练一次就要花费6300万美元,这时你会觉得大模型非常牛逼。
如果你亲自使用过,比如让ChatGPT写一篇关于“你到底了解多少大模型”的稿件,然后化身甲方,命令它一轮一轮地改,那么这时你已经知道大模型能做到什么了。
声明一下,本文不是这样写的,因为大模型不会告诉你这些机密问题。
所有人都在谈论大模型,所有人都在使用大模型,所有人都在展望大模型的未来。
可问题是,所谓AI的三要素,算法算力数据来源,我们顶多有一个数字知道算力有多少,算法和数据来源几乎一无所知。
OpenAI并不“open”。
OpenAI、Google和Meta等公司对自己的大模型信息守口如瓶。从来没有说明书告诉你这些模型到底能够执行哪些操作,没有说明对它们进行了哪些类型的安全测试。
很可能绝大多数人并不关心这些底层原因,就像人们没有兴趣知道手机为什么能打电话、巴以冲突为何发生一样。
但这并不正常。
大模型对于公众就是一个又一个的黑箱,我们通过一些民间高手分享的prompt咒语或者自然语言与它们交流,然后得出一些神奇的结果。至于为什么会是这样的结果——不知道。
10月18日,斯坦福大学的研究人员推出了一个人工智能评分系统,他们希望该系统能够改变这一切。
这个系统被称为基础模型透明度指数,对10个大语言模型的透明度进行评级。
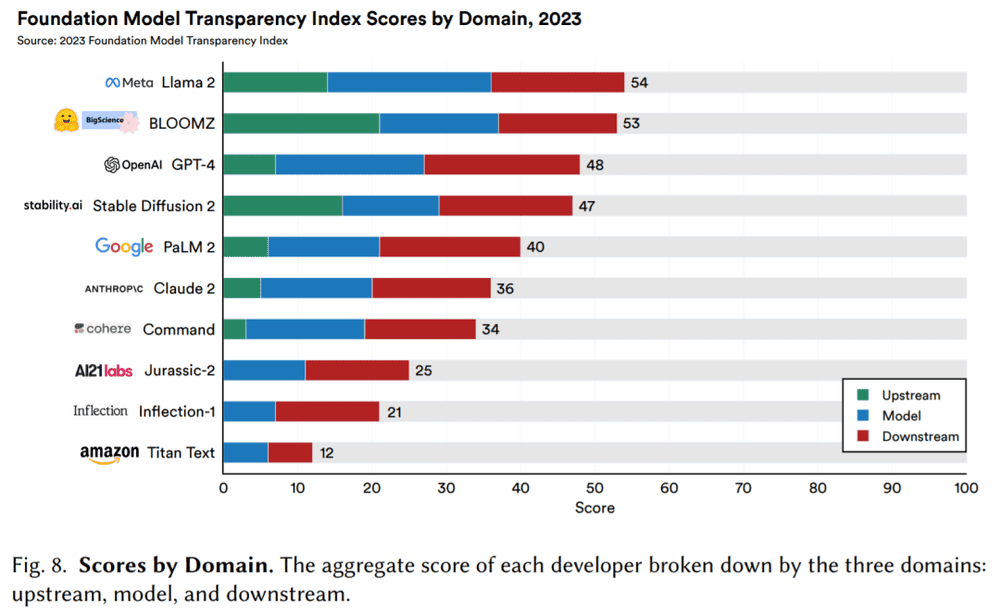
评分越高代表该模型越透明,论文链接:https://arxiv.org/pdf/2310.12941.pdf
为了得出排名,研究人员根据100项标准对每个模型进行了评估,包括其制造商是否披露其训练数据的来源、所使用的硬件信息、训练所涉及的劳动力以及“下游指标”,这些指标与模型发布后的使用方式有关。
例如,其中一个问题是:“开发者是否公开其存储、访问和共享用户数据的协议?”
研究表明,这10个模型中透明度最高的是LLaMA 2,得分为54%。GPT-4的透明度得分排名第三,为48%。垫底的是亚马逊的Titan Text,得分仅12%。
省流,无人及格。
研究人员称,该项目是对近三年来AI行业透明度下降的必要回应。随着资金疯狂涌入人工智能领域,尽管科技巨头们都在争夺主导地位,但许多公司的趋势是保密。
随着大模型变得越来越强大,并且全球数以亿计的人生活中融入了人工智能,透明度变得越来越不可忽视。我们越了解这些模型,我们就越能理解它们可能构成的威胁、它们可能带来的好处或它们可能如何受到监管。
既然透明度如此重要,科技公司的高管们为什么还要藏着掖着,不能大大方方地分享更多有关其模型的信息呢?
那么来看看各大公司的三大理由。
首先是诉讼。人工智能公司经常陷入官司,被指控非法使用受版权保护的作品来训练他们的人工智能。前几天,Anthropic就被指控滥用至少500首受版权保护的歌曲歌词来训练其聊天机器人Claude。
我们经常看到,有著名画师表示自己的图变成别人帖子中的“AI生成”就是这种情况。

大多数诉讼都针对开源人工智能或披露详细信息的项目。毕竟,只要我不说,你就不知道我用没用。说得越多,反而越容易面临昂贵、烦人的诉讼。多说多错,这种情况下的占优策略无疑是保持沉默。
经典的不是版权买不起,而是直接用更实惠。不过动辄数十数百TB的数据,光是一个个分辨它们的版权到底在谁家就是个天文数字级别的工作量。
嗯,为了省钱还可以理解一下。
第二个原因是竞争。很多AI公司相信他们的模型之所以有效,是因为他们拥有秘密武器——其他公司没有的高质量数据集、产生更好结果的微调技术、赋予他们优势的一些优化。
如果强迫AI公司披露这些秘诀,就会让他们将来之不易的智慧拱手让给竞争对手,而竞争对手可以轻松复制它们。
嗯,商战嘛,也可以理解。就像量化公司不会公开它们的代码一样。
第三个原因是安全。一些专家认为,公司披露他们的模型会加速AI的进步——因为每家公司都会看到所有竞争对手正在做什么,并立即尝试通过建立更好、更大、更快的模型来超越他们,进而陷入AI的军备竞赛。
这些人说,这将使“留给社会监管进步的时间变少,以及加速人工智能的发展”。如果人工智能出现这种情况,我们所有人都可能面临危险,因为人工智能的发展速度会快于人类接受新事物的速度。
披露信息比不披露更加不利于监管,要不要听听你在说什么?
至于减缓人工智能的发展……您是AI公司吗——是。您想让公司盈利吗——想。那您想让自己公司的AI加速发展吗——当然想啊!减缓AI发展与公司的目标完全是冲突的,搁这儿负反馈调节,怕不是有什么大病。
另外,如果他们担心的是启动人工智能军备竞赛……我们不是正陷入其中吗?
研究人员显然并不相信这些高管的理由,他们敦促AI公司发布尽可能多的大模型的信息,并表示“当透明度下降时,可能会发生不好的事情”。
他们的担忧是有道理的。低透明度的模型缺乏有效的监管,最后极有可能酿成恶果。
2016年3月,微软上线了聊天机器人Tay,能抓取和用户互动的数据以模仿人类对话,上线不到一天,Tay就学成了一个鼓吹种族清洗的极端分子,微软只好以系统升级为由将其下架。
ChatGPT前身GPT-2,就充斥着性别歧视思想,有70.59%的概率将教师预测为男性。AI图像识别还总把在厨房的人识别为女性,哪怕对方怎么看都是个男性。Google照片应用的算法甚至曾将黑人分类为“大猩猩”。
2021年12月25日,贾斯万特·辛格·柴尔打扮成西斯尊主,手持十字弓进入温莎城堡,他是来“杀死女王”的。后来发现,这一整个刺杀计划都是一位19岁的年轻人和一款名为Replika的聊天机器人一起密谋的行动细节。
说“密谋”也不准确,Replika又不是他自己训练的。但是他和Replika交换信息超5000条,APP上愣是没有任何监管机制发现不对劲。
技术乐观主义者可能不以为意。毕竟如果需要建立一个庞大的审核团队去实时审核每一条AIGC内容,那和过去的人工客服有什么区别?科技在发展,现在的AI早就不这样了。
如今就诞生了一种名为“宪法AI”的技术,目的是探索使用AI系统来帮助监督其他AI的可能,从而扩大监督规模。从人类反馈强化学习(RLHF)进化到AI反馈强化学习(RLAIF),也就是从利用人类反馈训练AI到利用AI训练AI。
带“宪法”人工智能可以实现自我批评和自我监督,从而优化输出。说白了就是利用先进的AI技术自己管自己。
有了这么多新鲜的监督技术,AI的错误率应该大大下降了吧?
理想很丰满,现实很骨感。
很巧的是,前几天GPT-4刚刚爆出一个重大缺陷——自我纠正成功率仅1%。研究发现,LLM在推理任务中,无法通过自我纠正的形式来改进输出,除非它已经提前知道了正确答案。
这不就又绕回去了,还是得靠程序员把答案一条一条输进去。
对国内大模型而言,这可能才是最大的威胁,毕竟很多“不正确”的言论,都是可以人为一步步引导模型自己说出来的,锅还得公司背。
参考材料:
[1] Maybe We Will Finally Learn More About How A.I. Works, The New York Times
[2] Stanford researchers issue AI transparency report, urge tech companies to reveal more, Reuters
[3] This week in AI: Can we trust DeepMind to be ethical? TechCrunch
[4] Peering Into AI's Black Box, Who's the Real Techno-Optimist? And Reading Ancient Scrolls With AI, The New York Times
[5] The Foundation Model Transparency Index, Stanford University, MIT and Princeton University
[6] Constitutional AI: Harmlessness from AI Feedback, Anthropic
[7] GPT-4不知道自己错了!LLM新缺陷曝光,自我纠正成功率仅1%,LeCun马库斯惊呼越改越错,新智元
[8] 全都不及格!斯坦福 100 页论文给大模型透明度排名,GPT-4 仅排第三,IT之家
[9] GPT-4“终极大揭秘”:1.8万亿巨量参数、训练一次6300万美元!全天候科技
本文来自微信公众号:新硅NewGeek(ID:gh_b2beba60958f),作者:成思怡,编辑:张泽一,视觉设计:疏睿