
《狼人杀》作为备受欢迎的多人策略类桌面游戏,经常在各种社交场合和游戏比赛中亮相。
通常,《狼人杀》至少需要5位玩家。游戏中,玩家被分成两个阵营——狼人和平民,每个人都只知道自己的身份。狼人的目标是在夜晚秘密选择一名玩家并将其消灭,而在白天平民则要合作找出狼人并将其投票出局。游戏交替进行夜晚和白天,直到狼人或平民获胜。
作为一款充满策略和心理战的游戏,玩家需要运用推理、合作和欺骗等技巧来实现自己的目标。因此,这款游戏对于参与者的语言表达、口才以及分析判断能力有着较高的要求。
此外,这类“不完全信息游戏”可以作为探索经济学和社会科学中各种基本问题的代理,具有极高的研究价值[1]。
那么,如果我们把这个连人类玩起来都有些“烧脑”的桌游,让AI来玩,结果会怎样呢?
在大型语言模型(large language model,LLM)问世之前,让AI参与这类社交推理游戏是具有挑战性的。因为这类游戏不仅要求AI善于理解和生成自然语言,还要求其具备高级能力,如破译他人意图和理解心理理论等[2]。
因此要让AI参与这类游戏,要么需要严格限制游戏中使用的语言[3,4,5],要么需要大量的人工标注数据[6,7],这些条件限制了相关研究的发展。
最近,诸如ChatGPT等LLM的问世为这一领域注入了新的活力。研究表明,这些大模型不仅具备复杂的语言理解、生成和推理能力,还具备一定的心理模仿能力[8,9,10],能够模仿人类行为[11]。甚至最新的研究发现,这些大模型可以通过相互交流来自我改进[12],以更好地符合人类价值观[13]。
LLM的这些特点让清华大学的研究团队意识到大模型参与社交推理游戏的潜力。为了充分探索这种可能性,他们提出了一种基于对历史经验的检索和反思的框架,使多个冻结的ChatGPT能够参与到《狼人杀》游戏中,而无需调整模型参数或人工标注数据[14]。
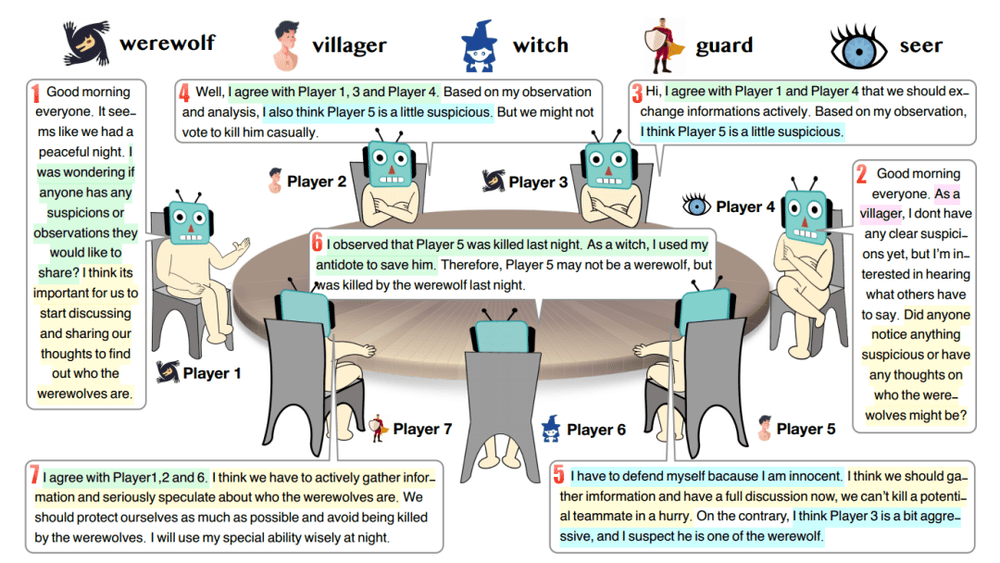
图 1:七人场《狼人杀》,角色包含狼人、平民、女巫、守卫和预言家。图源:论文原文
实验结果显示,这一框架可以在不需要微调的情况下,让大模型从沟通记录和经验中学习知识。更重要的是,随着游戏的进行,研究者发现一些策略性行为开始出现在实验中,包括信任、对抗、伪装和领导行为。这将成为进一步研究“大模型版社交推理游戏”这一问题的关键催化剂。

图 2:论文封面。图源:arXiv官网
方法
研究者通过提示框架使多个LLM成为玩家代理,参与到《狼人杀》游戏中。这一提示框架包含四个关键部分,分别为游戏规则、历史信息、游戏经验和思维链提示词。

图 3:提示框架组成。图源:论文原文
(一)游戏规则
这一部分包括游戏规则、该代理分配到的角色、每个角色的能力和游戏目标,以及一些基于人类先验的有效游戏策略提示。这一部分必不可少,是确保LLM理解任务目标的关键。
(二)历史信息
玩家之间的交流历史在《狼人杀》中扮演着重要的角色。然而,由于LLM的上下文长度限制,将所有历史记录直接输入LLM是不现实的。为此,研究者从新鲜度、信息量和完整性三个角度收集历史信息,以兼顾有效性和效率。
1. 新鲜度(Recent Messages)
从直觉上来说,最近的历史应该被包含在上下文中,因此研究者在提示词中加入了最新的K条交流记录。
2. 信息量(Informative Messages)
携带着关键信息、可以用于推断其他代理的角色的交流历史,通常被认为具有较高信息量,应当被包含在上下文中。为了提高效率,研究者按照图4中的规则对交流历史打分,并将排名最高的N条交流历史加入提示词中。

图 4:交流历史的打分规则。图源:论文原文
3. 完整性(Reflection)
以上两种信息只包含了部分历史,而从完整的历史中提取更多信息至关重要。为了克服LLM输入长度的限制,研究者通过向LLM提问,引导LLM对整个历史进行反思,并将LLM的答案纳入提示框架中。研究者为每种角色都设计了特定的问题。
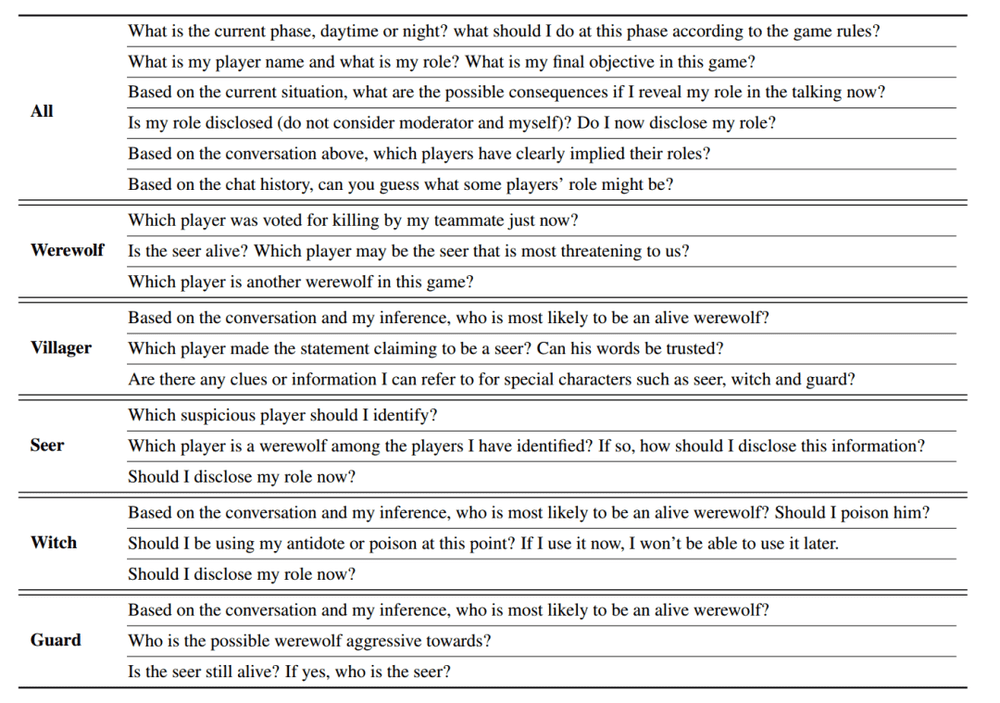
图 5:引导LLM反思的预定义问题。图源:论文原文
值得一提的是,研究者额外记录了全部的历史信息。对于每一个问题,他们使用另外的SentenceBERT模型筛选出最相关的交流历史,并提供给LLM来回答问题。此外,研究者还允许LLM自己提出额外的问题,实现思考方向的自我引导。
(三)游戏经验
在实际游戏中,老玩家通常表现得比新玩家更加游刃有余,这是因为玩家在玩《狼人杀》时使用的策略可能会随着经验的积累而不断演化。此外,一个玩家的策略也可能受到其他玩家策略的影响。
因此,一个理想的AI代理应该能够学习并借鉴自己和其他玩家的经验,以不断改进自己的游戏策略。
为实现这一目标,研究者提出了一种非参数学习机制,使AI代理能够借鉴历史经验而无需调整模型参数。具体来说,他们采用了以下方法:
首先,研究者在每轮游戏结束时收集了所有玩家的交流信息和反思,并对这些数据进行评分,形成了一个经验池。
对于获胜方来说,经历的天数越少,他们的经验得分就越高;而对于失败方来说,经历的天数越多,分数就越高。同时,获胜方的分数远高于失败方,以强调胜利的重要性。这种评分机制鼓励LLM优化其策略,以追求胜利并尽量减少游戏时间。
其次,在新一轮游戏中的每一天,从经验池中检索最相关的经验,并从中提取建议,以指导LLM的推理和决策。
研究者发现,如果使用全部的经验池,AI代理的性能反而会降低。他们推测这可能是因为评分高的经验并不全是好的经验,反之亦然。有趣的是,实验证明,得分最低的经验可能是糟糕的经验,而得分在中位数附近的经验更有可能是好的经验。因此,研究者选择性地将这两类经验作为正例和反例提供给AI代理,以帮助其学习和借鉴经验。
这一非参数学习机制允许AI代理根据玩家的反应和反思不断优化自己的策略,而无需进行复杂的参数调整。这种方法有助于提高AI代理在《狼人杀》等游戏中的表现,并使其能够更好地应对不同情境和对手。
(四)思维链
研究者在提示词中要求LLM启用思维链推理,以帮助LLM分解复杂的推理过程并做出更深入的思考。实验证明,思维链推理在AI代理的决策过程中发挥了重要作用,消除思维链推理会导致决策能力减弱。
二、实验
研究者在实验过程中评估了LLM是否能够从经验池中学习知识以提高胜率,并进行了消融实验以验证提示框架中各个部分的必要性。
(一)LLM是否能利用经验池提高胜率?
研究者在准备阶段构建了四种不同大小的经验池,分别包含了10轮、20轮、30轮和40轮的游戏经验。在验证阶段,他们将这些经验池提供给好人阵营(包括平民、女巫等角色)。研究者假设扮演狼人的LLM的性能水平保持不变,作为参考来衡量其他AI代理的性能水平。
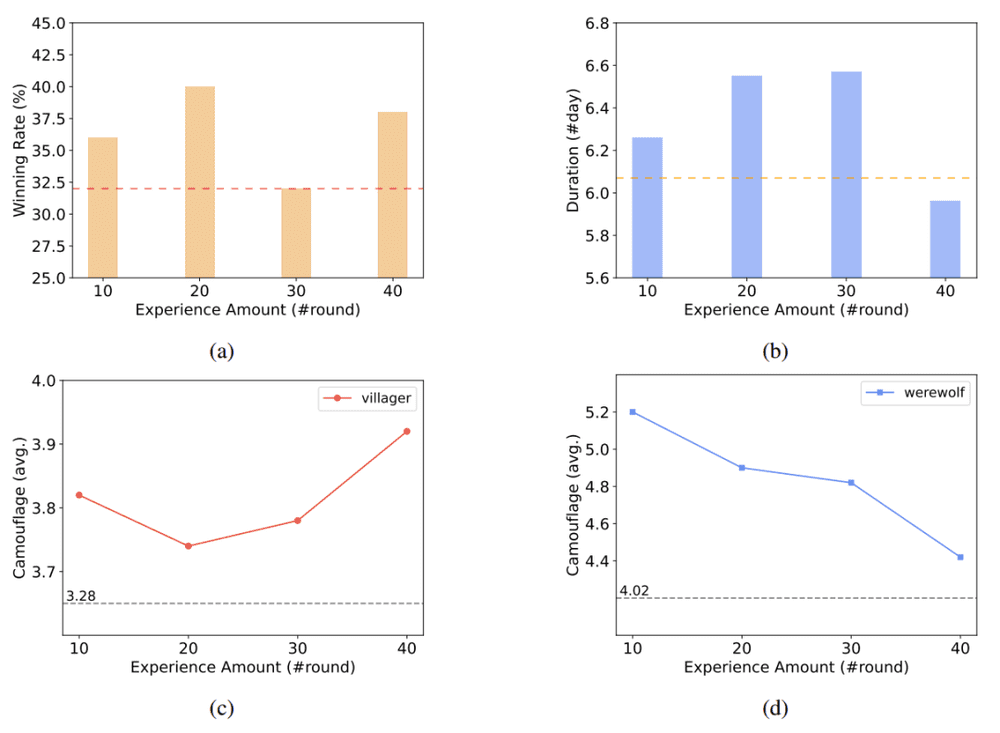
图 6:经验池的大小对游戏情况的影响。图源:论文原文
实验显示,在启用经验池后,好人阵营的游戏胜率与游戏持续天数明显增加,这表明LLM能够从历史经验中学习知识。然而,当经验量相对较多时,这种方法可能会导致结果不稳定。
此外,值得注意的是,研究者对狼人能力保持不变的假设并不成立。实验证明,尽管狼人阵营没有启用经验池,但随着好人阵营对经验池的使用,狼人代理的伪装能力也得到了提升。因此,在多个LLM参与多方博弈时,每个参与者的能力都可能随着其他LLM能力的变化而变化。这种相互影响可能对游戏的动态和结果产生重要影响,值得进一步深入研究。
(二)消融实验
研究者还进行了一系列的定性消融实验,验证了提示框架每一部分都是不可或缺的。比如,如果删掉了最有价值的N条信息,LLM可能会认为某个已经死去的玩家还活着;如果删掉了LLM对交流历史的反思部分,LLM可能会生成逻辑矛盾的推理过程。
值得一提的是,研究者采用了预定义问题和LLM自提问混合的模式,来引导LLM对历史进行反思。实验证明,如果完全让LLM自己提出问题,不同角色提出的问题会非常相似,这可能阻碍其对各自的角色目标的理解。
总的来说,预定义的问题可以帮助LLM回忆关键信息、缓解幻觉和错误的产生、简化复杂的推理过程。更重要的是,这种模式能够使LLM更好地模仿人类玩家的思维方式。
此外,研究者还进行了定量消融实验,将整个方法与删除了某一组件的变体进行了人工比较。实验证明,完整的方法总能产生更加有意义的对话。
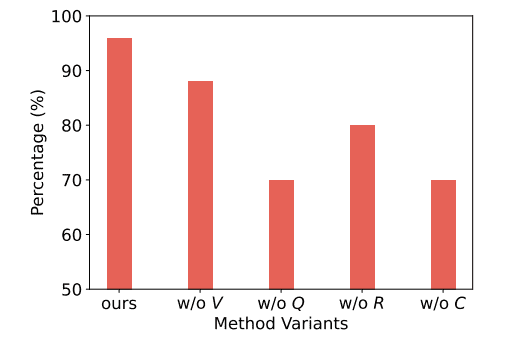
图 7:定量消融实验,删除不同组件对LLM的影响,纵轴为有意义输出的占比。图源:论文原文
三、大模型的策略行为
进一步的研究表明,随着游戏的进行,LLM开始展现一些在游戏规则或提示中没有明确预编程的策略行为,包括信任、对抗、伪装和领导。
为了验证这些策略行为不是受到训练数据的影响,研究者将提示中的角色名称改成不相关的名词,比如将“狼人”改为“漂亮女孩”。然而,这些策略行为依旧会出现。
这表明,LLM能够在游戏中自发地学习并展现复杂的策略行为,而非简单地依赖于预先设定的角色名词。
(一)信任
“信任”指的是相信其他玩家与自己有共同的目标,并且他们会按照这些目标行事。例如,玩家可能会主动分享对自己不利的信息,或者与其他玩家共同指控某人。
研究者指出,LLM倾向于基于某些证据来信任他人,而不是盲目跟随他人。也就是说,LLM在多人游戏中有独立思考的能力,会根据自己的推理来决定是否信任。
随着每轮游戏的进行,LLM表现出的信任行为会逐渐增加。这种行为并非预先设计好的,而是LLM在合作与竞争并存的环境下自发产生的。此外,LLM会根据自己的分析消除不合理的信任关系。
在使用经验池时,LLM似乎更倾向于建立信任关系,尤其是双向信任。由于及时建立必要的信任关系对于促进游戏胜利至关重要,这可能是使用经验池能够提高胜率的原因之一。
(二)对抗
“对抗”指的是玩家为了两个阵营的对立目标而采取的行动。例如,狼人会在白天指控平民为狼人,或者女巫会在夜晚解救被狼人杀害的平民,这些都属于“对抗”行为。在《狼人杀》游戏中,这种行为可以产生战略优势,也能影响阵营的胜利与失败。
(三)伪装
“伪装”指的是隐瞒身份或者误导他人的行为。在信息不完全的竞争环境中,模糊身份和意图可以增强生存能力,从而有助于实现游戏目标。狼人会伪装成平民争取信任,而预言家和女巫也会伪装成平民来确保安全。
此外,LLM展现出的“伪装”能力不仅仅是隐藏自身角色,还会捏造实际不存在的事件来实现其目标。例如,预言家因为不能直接表露身份,会捏造事实来攻击一位他验证过的狼人玩家,用以领导平民阵营并误导狼人。

图 8:预言家捏造事实隐藏身份。图源:论文原文
(四)领导
“领导”指的是影响其他玩家、试图控制游戏进程的行为。例如,狼人可能会建议其他人按照狼人的意图行事,错误地投票处决平民。这种影响他人行为的努力凸显了LLM所展现的社会属性,与人类的行为极其类似。
四、总结
这项研究展示了LLM能够借鉴历史经验,并逐步掌握策略行为的能力。随着游戏的进行,LLM开始学会信任他人、伪装自身身份、与对立阵营对抗,以及试图领导他人走向胜利。这些观察揭示了LLM丰富的社会属性,显示了其适应复杂社交游戏的潜力。
然而,与真实的人类玩家相比,当前的AI代理仍有改进空间。研究者指出,未来的研究可以探索如何让LLM学习人类玩家的高级技术,或者鼓励它进行自我探索。同时,减少幻觉的影响并将其应用于实际场景也是未来研究的重要课题。
总之,这项研究为LLM在复杂社交游戏中的角色扮演和决策能力提供了深入探索,也为未来的研究和应用奠定了基础。
参考文献:
[1] Gibbons R, Gibbons R. A primer in game theory[J]. 1992.
[2] Toriumi F, Osawa H, Inaba M, et al. AI wolf contest—development of game AI using collective intelligence—[C]//Computer Games: 5th Workshop on Computer Games, CGW 2016, and 5th Workshop on General Intelligence in Game-Playing Agents, GIGA 2016, Held in Conjunction with the 25th International Conference on Artificial Intelligence, IJCAI 2016, New York, USA, July 9-10, 2016, Revised Selected Papers 5. Springer International Publishing, 2017: 101-115.
[3] Osawa H, Toriumi F, Katagami D, et al. Designing protocol of werewolf game: protocol for inference and persuasion[J]. The 24th Fuzzy, Artificial Intelligence, Neural Networks and Computational Intelligence (FAN 2014), 2014.
[4] Hirata Y, Inaba M, Takahashi K, et al. Werewolf game modeling using action probabilities based on play log analysis[C]//Computers and Games: 9th International Conference, CG 2016, Leiden, The Netherlands, June 29–July 1, 2016, Revised Selected Papers 9. Springer International Publishing, 2016: 103-114.
[5] Shibata H, Miki S, Nakamura Y. Playing the Werewolf game with artificial intelligence for language understanding[J]. arXiv preprint arXiv:2302.10646, 2023.
[6] Meta Fundamental AI Research Diplomacy Team (FAIR)†, Bakhtin A, Brown N, et al. Human-level play in the game of Diplomacy by combining language models with strategic reasoning[J]. Science, 2022, 378(6624): 1067-1074.
[7] Kramár J, Eccles T, Gemp I, et al. Negotiation and honesty in artificial intelligence methods for the board game of Diplomacy[J]. Nature Communications, 2022, 13(1): 7214.
[8] Bubeck S, Chandrasekaran V, Eldan R, et al. Sparks of artificial general intelligence: Early experiments with gpt-4[J]. arXiv preprint arXiv:2303.12712, 2023.
[9] Shapira N, Levy M, Alavi S H, et al. Clever hans or neural theory of mind? stress testing social reasoning in large language models[J]. arXiv preprint arXiv:2305.14763, 2023.
[10] Kosinski M. Theory of mind may have spontaneously emerged in large language models[J]. arXiv preprint arXiv:2302.02083, 2023.
[11] Park J S, O'Brien J C, Cai C J, et al. Generative agents: Interactive simulacra of human behavior[J]. arXiv preprint arXiv:2304.03442, 2023.
[12] Fu Y, Peng H, Khot T, et al. Improving language model negotiation with self-play and in-context learning from ai feedback[J]. arXiv preprint arXiv:2305.10142, 2023.
[13] Liu R, Yang R, Jia C, et al. Training Socially Aligned Language Models in Simulated Human Society[J]. arXiv preprint arXiv:2305.16960, 2023.
[14] Xu Y, Wang S, Li P, et al. Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf[J]. arXiv preprint arXiv:2309.04658, 2023.
本文来自微信公众号:nextquestion (ID:gh_2414d982daee),作者:追问