
心智模式指可用于解释许多不同现象的通用观念。经济学中的供给与需求,生物学中的自然选择,计算机科学中的递归,或者数学中的归纳证明——一旦你知道如何寻找它们,这些模式就无处不在。
正如理解供给与需求有助于对经济学问题作出推断,理解学习的心智模式也使思考学习问题变得更容易。
遗憾的是,学习很少被作为一门独立的课程来讲授——这意味着大部分心智模式只有专业人士才了解。在这篇文章中,我想与大家分享十种对我影响最大的心智模式,同时附上参考文献,以供你了解更多。
一、解决问题就是搜索
赫伯特·西蒙和艾伦·纽厄尔在他们里程碑式的著作《人类问题解决》中开启了对问题解决的研究。他们在书中指出,人们通过搜索问题空间来解决问题。
问题空间就像一个迷宫:你知道自己现在在哪儿,也知道是否已经抵达出口,但不知道如何到达出口。一路上,你的行动受到迷宫墙壁的限制。
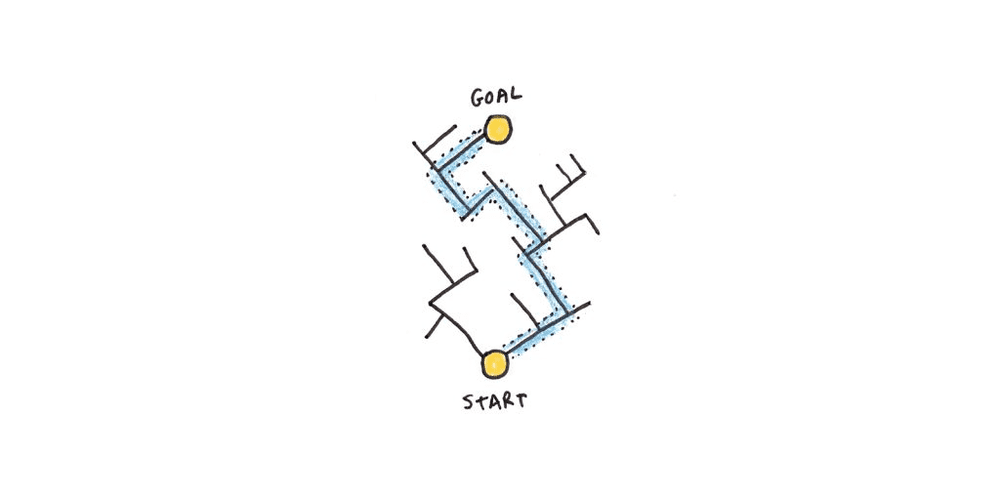
问题空间也可以是抽象的。比如,拼魔方意味着在一个由各种构型组成的巨大问题空间中移动——混乱的魔方是你的起点,每一面都是同种颜色的魔方是出口,而中间的扭转则定义了问题空间的“墙壁”。
现实生活中的问题通常比迷宫或魔方的范围更广,起始状态、结束状态和确切的移动方式往往并不明确,但搜索可能性空间仍然很好地描述了人们在解决不熟悉问题时的做法——也就是当他们还没有方法或记忆可以直接引导他们找到答案。
这个模式的含义之一是,如果没有先验知识,大部分问题都很难解决。一个魔方有超过43万亿个构型组合——如果你对它不算颇有心得的话,这是个巨大的搜索空间。学习就是习得模式和方法以减少暴力搜索的过程。
二、通过检索提取,记忆得以加强
检索提取知识比看第二次更能强化记忆。测验知识不只是衡量你掌握了多少知识的一种方法,它还能主动增强你的记忆力。事实上,测试是研究人员发现的最有用的学习技巧之一。
检索提取为什么如此有用?一个解释思路是,大脑为了节省精力,只会记住那些可能有用的东西。如果你手边总有答案,就没必要把它编码在记忆中。相反,检索提取带来的困难是一个强有力的信号,表明你需要记住它。
只有当有内容可以检索时,检索提取才会起作用,这就是为什么我们需要书本、老师和课堂。当记忆失效时,我们转而依赖搜索来解决问题。取决于问题空间的大小,搜索可能完全失败,无法提供正确答案。然而,一旦看过答案,我们通过检索提取它会比反复观看它学到更多。
三、知识呈指数增长
你能学到多少,取决于你已经知道多少。研究发现,阅读文本后汲取的知识量,取决于关于该主题已有多少知识。在有些情况下,已有知识的影响甚至超过智力。
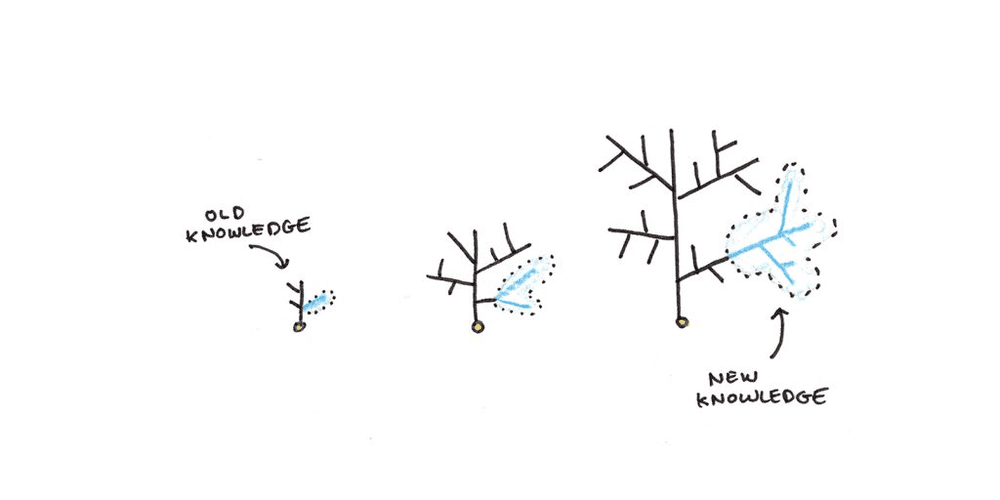
学习新知识时,你会把它们整合进已经掌握的知识中,这种整合为日后回想提供了更多钩子。然而,当你对某个主题知之甚少时,就没有那么多钩子来钩住新信息,导致信息更容易遗忘。就像水晶从一种子晶体逐渐生长而来,一旦打好了基础,未来的学习就会容易得多。
当然,这个过程是有限度的,否则知识会无限地加速累积。不过,记住这一点还是有好处的,因为学习的早期阶段往往是最困难的,而且会让人误认为该领域未来的学习也很难。
四、创新大多数时候是模仿
很少有哪个主题像创造力这样被误解。我们往往给有创造力的人披上近乎神奇的光环,但实际上创造力要平凡得多。
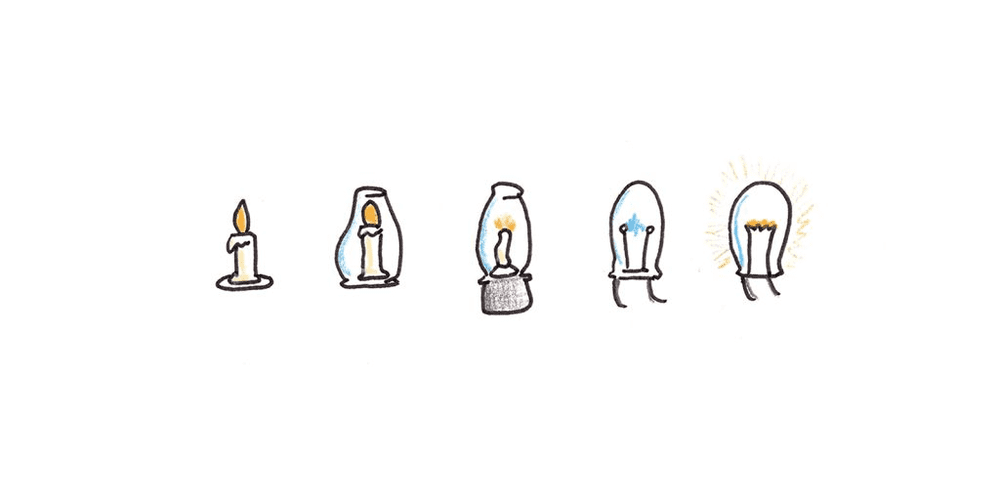
在一篇对重大发明令人印象深刻的评述文章中,马特·莱德利指出,创新是一个渐进演化过程的结果。新的发明并非一蹴而就,它本质上是旧思想的随机变异。当这些思想被证明有用时,它们就会扩展到新的领域。
支持这一观点的证据来自近乎同时出现的创新现象。历史上有无数次,多个互不相关的人取得了相同的创新,表明在被发现之前,这些发明在可能性空间中是“近在咫尺”的。
即便在美术领域,模仿的重要性也常被忽视。是的,许多艺术革命都是对过去趋势的明确反抗,但这些革命者自己,几乎无一例外地,都深深烙印着他们反抗的传统。对任何惯例的反抗都需要先了解那种惯例。
五、技能是特定具体的
迁移指的是经过一项任务的练习或训练后,在另一项任务中表现出能力提高。对迁移的研究揭示出一个典型模式:
练习一项任务,你能把任务做得更好。
练习一项任务,有助于完成类似任务(通常是过程或知识有重叠的任务)。
练习一项任务,对不相关的任务帮助不大,即使它们看起来需要广义上相同的能力,例如“记忆力”“批判性思维”或“智力”。
很难对迁移作出准确的预测,因为这需要对人类思维的工作原理和所有知识结构有准确的了解。不过,约翰·安德森发现,在更受限制的领域,产生式——即对知识进行操作的“如果-那么”规则——能够很好地匹配智力技能中观察到的迁移量。
虽然技能或许是特定的,但广度却能产生通用性。例如,学会一个外语单词,只在听到或用到这个词时才有用,但如果你知道许多单词,就可以说许多不同内容。
类似地,知道一个想法可能无关紧要,但掌握许多想法就能产生巨大的能量。每多接受一年教育,智商就会提高1~5点,部分原因在于学校教授知识的广度与现实生活(以及智力测验)所需的知识有所重叠。
如果你想变得更聪明,没有捷径可走——必须学很多东西。但反之亦然,学得多让你变得比预想的更聪明。
六、思维带宽极其有限
我们在同一时间只能记住几件事。乔治·弥勒最初把这个数字定为7±2件,但最新的研究表明,这个数字更接近四件。
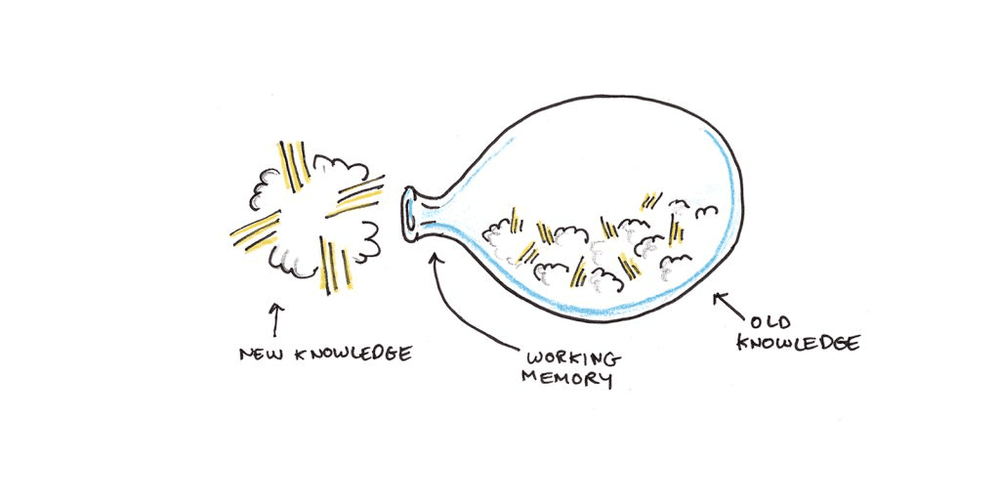
所有的学习,每一个想法、记忆和经验,都必须经过这个难以置信的狭窄瓶颈,才能成为我们长期经验的一部分。潜意识的学习不起作用,如果你没有集中注意,就没有在学习。
提高学习效率最主要的方法是确保从瓶颈流过的东西是有用的,将带宽用于无关内容可能会拖慢我们的速度。
从1980年代起,认知负荷理论一直被用来解释干预如何根据我们有限的思维带宽来优化(或限制)学习。这项研究发现:
对于初学者来说,解决问题可能适得其反。如果向新手展示工作实例(解决方案),他们的学习效果会更好。
教材的设计应避免要在页面或图表的各部分之间翻来翻去才能理解。
冗余信息会妨碍学习。
复杂概念如果先分部分介绍,会更容易理解。
七、成功是最好的老师
我们从成功中学到的比从失败中更多。原因在于,问题空间通常很大,而大多数解决方案都是错误的。知道什么方法有效,就能大大减少可能性,而经历失败只能告诉你一种特定的策略是行不通的。
一个好的原则是,在学习时将目标设定为大约85%的正确率。为此,你可以调整练习的难度(开卷与闭卷、有导师辅导与无导师辅导、简单问题与复杂问题),或者在正确率低于这个阈值时寻求额外的培训和帮助。如果你的成功率超越了这个阈值,那可能是找的问题不够难——只是在重复练习常规技能,而没有学习新技能。
八、我们通过实例来推理
人们如何有逻辑地思考是一个古老的谜题。从康德开始,我们就知道逻辑无法从经验中获得。无论如何,我们一定已经知道了逻辑规则,否则一个不懂逻辑的人是不可能发明出这些规则的。但若真如此,我们为什么又经常掉进逻辑学家提出的问题陷阱呢?
1983年,菲利浦·约翰逊-莱尔德提出了一个解释:我们通过构建情境的心智模式来推理。
要检验一个三段论,“所有人终有一死,苏格拉底是人,因此苏格拉底终有一死”,我们想象一群人,他们都终有一死,并想象苏格拉底是他们中的一员。通过这样的检验,我们推断这个三段论是正确的。
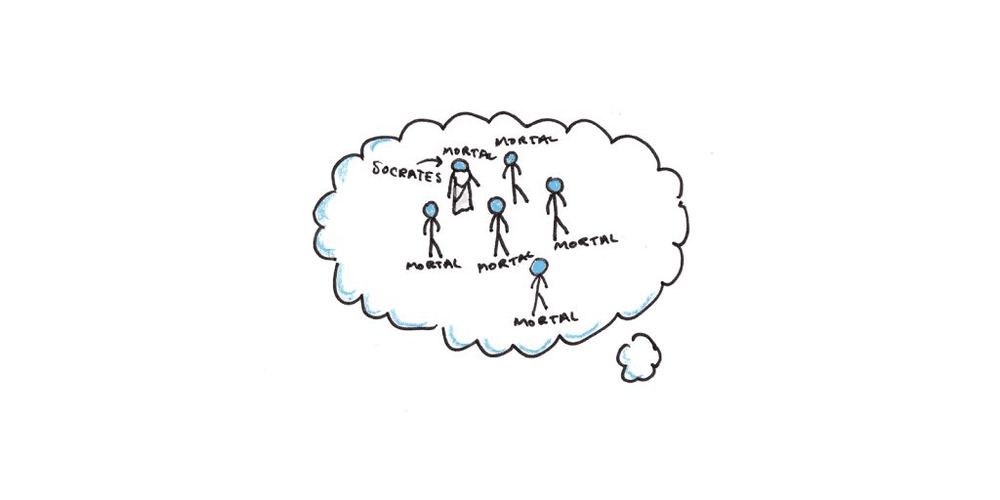
约翰逊-莱尔德认为,这种基于心智模式的推理也可以解释我们的逻辑缺陷。我们在处理需要检查多个模式的逻辑语句时最为吃力。需要构建和检查的模式越多,我们就越可能出错。
丹尼尔·卡尼曼和阿莫斯·特沃斯基的相关研究表明,建立在实例基础上的推理可能让我们误以为想到例子的顺畅程度就是事件或模式真实发生的概率。例如,我们可能认为 K_ _ 形式的单词比 _ K _ 形式的单词更多,因为前者(例如KITE,KALE,KILL)比后者(例如TAKE,BIKE,NUKE)更容易想到。
依靠实例推理有以下几方面的含义:
通过例子学习往往比抽象描述更快。
要学习一种通用模式,我们需要许多例子。
我们在基于少数例子进行广泛推论时必须小心(你确定考虑了所有可能情况吗?)。
九、随着经验积累,显性知识转变为隐性知识
随着练习,技能变得越来越自动化,这降低了我们对技能的关注程度,不需要占用宝贵的工作记忆容量就能完成。以开车为例,起初,打闪光灯和踩刹车时要经过反复思考,多年驾驶后,几乎不用动脑就能完成。
但技能更加自动化也有缺点。一个缺点是,向他人传授技能变得更加困难。当知识变得隐性时,明确做决定的过程就变得更加困难。专家经常低估“基础”技能的重要性,因为这些技能早已被自动化,似乎并未在他们的日常决策中起到多大作用。
另一个缺点是,自动化的技能不太容易受意识的控制,这可能导致进步停滞不前。你可能一直按照固有的方式做某件事,即使这种方式已经不再适合。寻求更高难度的挑战变得至关重要,因为这些挑战会让你从自动化的流程中跳出来,迫使你尝试更好的解决方案。
十、重新学习相对迅速
上了那么多年学,如今我们中有多少人还能通过毕业考试?面对课堂上的问题,许多成年人都会羞怯地承认他们记不起来什么。
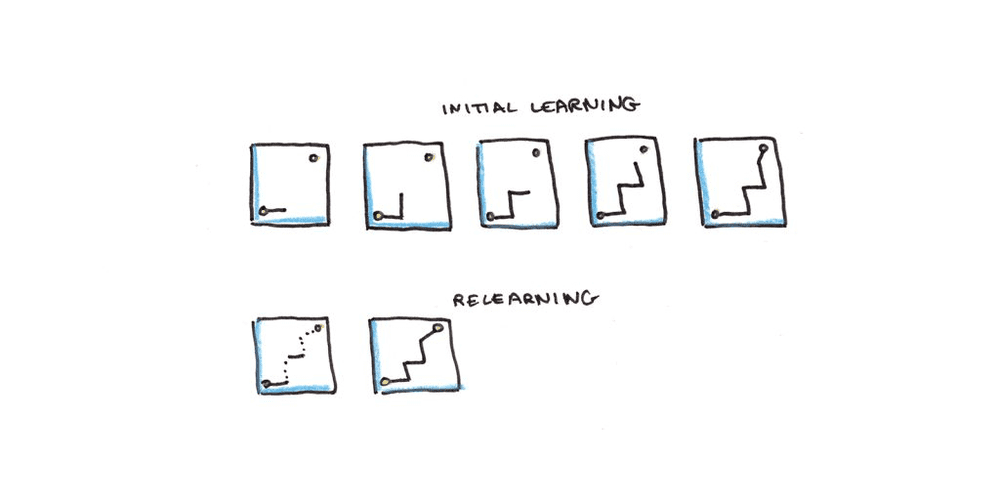
任何不经常使用的技能都难逃遗忘的命运。赫尔曼·艾宾浩斯发现,知识以指数速度遗忘——一开始最快,随着时间推移逐渐变慢。
不过也有一线希望。重新学习通常比第一次学习快得多。有些时候这可以理解为一个阈值问题。假设记忆强度位于0到100之间,低于某个阈值时,比如35,记忆就无法提取。因此,如果记忆强度从36掉到34,你就会忘记已经知道的东西。但重新学习带来的哪怕一丁点提升,也足以修复记忆,使其能够被唤起。相比之下,(从零开始的)新记忆则需要更多努力。
受人类神经网络启发的连接主义模型,为重新学习的强大效果提供了另一种论证。在这些模型中,计算神经网络可能要迭代数百次才能达到最优点,而如果你“晃动”网络中的连接,它就会忘记正确答案,给出的回答与瞎蒙的差不多。然而,和上文阈值的解释一样,神经网络重新学习最佳答案的速度要快得多。
重新学习是件麻烦事,尤其是被以前毫不费力的问题难住令人沮丧。然而,这并不是我们不深入、不广泛学习的理由——即使是被遗忘的知识,恢复起来也比从头开始要快得多。
脚注:
这些网络是通过梯度下降法训练的。梯度下降法的原理是沿着下坡的方向滚动。正确的知识就像陡峭峡谷中坡度平缓的底部——沿着峡谷向下是正确的方向,但两侧的山壁却相当高。与描述物理峡谷的三维空间不同,大多数网络都处于极高维的空间中,这意味着方向上的任何偏离都会导致沿着峡谷一侧上升。因此,网络在到达长长的峡谷底部之前,通常会四处晃动。然而,当你在系统中添加一些噪音,“下坡”方向通常直接回到最优点。
本文来自微信公众号:SCOTTHYOUNG(ID:Scott-H-Young),作者:斯科特·扬