
本文来自微信公众号:未来科技力 (ID:smartechworld),作者:李欣帅,题图来自:视觉中国
ChatGPT等AI工具的使用正越来越普遍。在与AI交互时,我们知道,输入的提示词差异会对输出结果产生影响。那么,如果相同意思的提示词,用不同语言分别表述,结果差异是否较大?另外,提示词的输入和输出是和模型背后的计算量直接挂钩的。因此,不同语言之间在AI输出和成本消耗方面是不是有着天然的差异性或者说是“不公平性”?这种“不公平性”又是如何产生的呢?
据了解,提示词背后其实对应的不是文字,而是token。当接收到用户输入的提示词之后,模型会将输入转换为token列表进行处理和预测,同时将预测的token转换为我们在输出中看到的单词。也就是,token是语言模型处理和生成文本或代码的基本单位。可以关注到,各家厂商会宣称自家模型支持多少token的上下文,而不是说支持的单词或汉字的数量。
影响Token计算的因素
首先,一个token并不对应一个英文单词或一个汉字,token跟单词之间没有具体的换算关系。比如,根据OpenAI发布的token计算工具,hamburger一词被分解为ham、bur和ger,共计3个token。另外,同一个词语,如果在两句话中的结构不同,会被记作不同数目的token。
具体token如何计算主要取决于厂商使用的标记化(tokenization)方法。标记化是将输入和输出文本拆分为可由语言模型处理的token的过程。该过程可以帮助模型处理不同的语言、词汇表和格式。而ChatGPT背后采用的是一种称为“字节对编码”(Byte-Pair Encoding,BPE)的标记化方法。
目前来看,一个单词被分解成多少token,跟它的发音和在句子中的结构有关。而不同语言之间的计算差异似乎较大。
拿“hamburger”对应的中文“汉堡包”来说,这三个汉字被计作8个token,也就是被分解成了8部分。
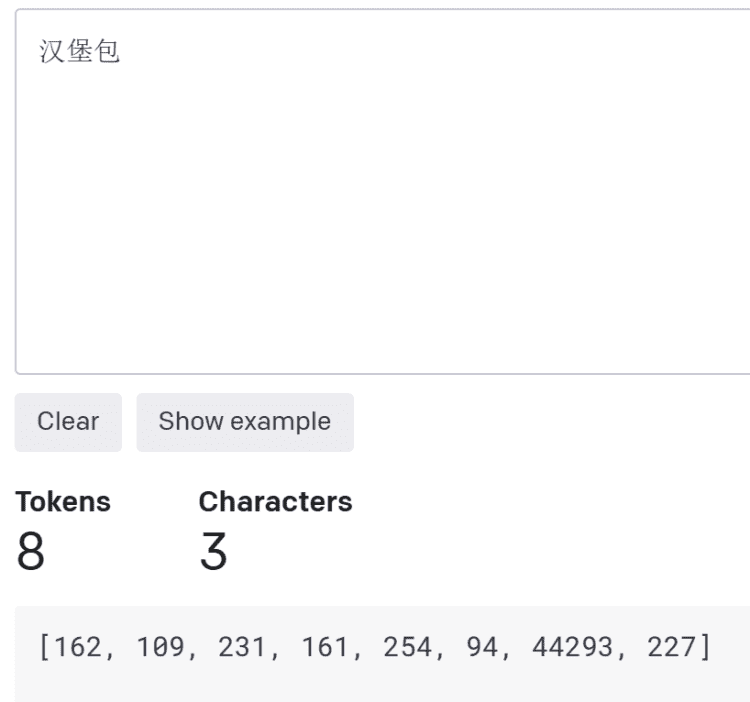
图源:OpenAI官网截图
再拿一段话来进行中英文语言token计算的“不公平性”对比。
下面是OpenAI官网的一句话:You can use the tool below to understand how a piece of text would be tokenized by the API, and the total count of tokens in that piece of text.这段话共计33个token。

图源:OpenAI官网截图
对应的中文为:您可以使用下面的工具来理解API如何将一段文本标记化,以及该段文本中标记的总数。共计76token。
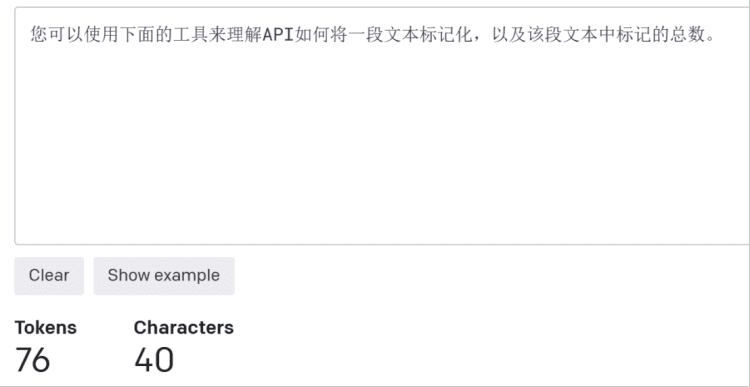
图源:OpenAI官网截图
中英文语言在AI上存在天然“不公平”
可以看到,相同意思的中文token数是英文的两倍多。中文和英文在训练和推理上的“不公平性”,也许是因为中文通常一个词汇可以表达多种含义,语言组成较为灵活,中文还有着深厚的文化内涵,具有丰富的语境意义,这极大增加了语言的歧义性和处理难度;英语语法结构较为简单,这使得英语在一些自然语言任务上比中文更容易被处理和理解。
中文需要处理的token更多,模型所消耗的内存和计算资源也就越多,当然所需要的成本也就越大。
同时,ChatGPT虽然可以识别包括中文在内的多种语言,但它训练使用的数据集大都为英文文本,在处理非英语语言时,可能面临语言结构、语法等方面的挑战,进而影响输出效果。近日的一篇题为《多语言语言模型在英语中表现得更好吗?》(Do Multilingual Language Models Think Better in English?)的论文中提到,当将非英文语言翻译成英文后输出的结果,要好于直接使用非英文语言作为提示词的结果。
对中文用户来说,先将中文翻译成英文,然后再与AI交互,似乎效果更好,也更划算。毕竟使用OpenAI的GPT-4模型API,每输入1千token至少要收费0.03美元。
那由于中文语言的复杂性,AI模型在使用中文数据进行准确训练和推理方面可能面临挑战,并增加了中文模型应用和维护的难度。同时,对开发大模型的公司来说,做中文大模型由于需要额外的资源,或许要承担更大的成本。
本文来自微信公众号:未来科技力 (ID:smartechworld),作者:李欣帅