
本文来自微信公众号:经纬创投 (ID:matrixpartnerschina),作者:经纬创投主页君,原文标题:《如何调教AI给你打工?提示词(Prompt)的秘密 |【经纬科创汇*AI】》,题图来自:《银翼杀手2049》
前段时间张颖在混沌学园的AI大会上,分享了一些对AI趋势的判断和对AI创业的7条建议,他在第一条建议中就提到:
“AI的学习和应用,大家一定注意,用起来、有效迭代大于一切。一个关键点就是要学会写提示词,知道如何提问非常关键,怎么能更好地与AI互动也是一门学问。”
今天我们稍微把“Prompt Engineering”(提示工程)展开聊一聊。年初,各种Midjourney用词宝典火遍互联网,比如:
熠熠生辉的霓虹灯 glittering neon lights
高角度视图 high angle view
未来主义抛光面 futuristic polished surfaces
古典风,18-19世纪 Vintage
浮世绘 traditional Japanese ukiyoe
……
直到最近,大神们又在二维码上玩出了花活,写好风格、元素的提示词,就能出一些别具一格的“AI艺术二维码”。
我们知道,能不能用好大语言模型,很大程度上取决于你提示词的质量。但别把提示词想简单了,它可不仅仅是在提问题时多说几个词或几句话那么简单,之所以叫Prompt Engineering(提示工程),就是因为有很多复杂的工程实践。
今天这篇文章,我们从两个案例入手,第一个是纯文本的例子,第二个是需要代码来实现的例子,来介绍Prompt Engineering(提示工程)的一些重要原则与技巧:
第一个案例,是在一些AI社区里很火的“爆款文案模型”,主要通过纯文本来给AI写好模板和规则提示。
第二个案例,是吴恩达与OpenAI官方合作的ChatGPT提示工程课程中,“订餐机器人”的例子。
最后,我们来总结一些Prompt的基本原则和技巧。
当然,提示词的纯文本和写代码之间,并没有本质区别,用代码实现是为了省token和令输出更稳定、精确,因为中文还是会占用更多token,当你需要大规模调用API的时候,成本会急剧上升。纯文本的提示词也可以构建得很复杂,比如我就见过600多行的文本提示词,并且由多组模块构成。
一个爆款文案模型(纯文本)
我们先简单介绍一下什么是“Prompt Engineering”(提示工程)。通常是指将你想提的问题,转换为特定格式的输入,并使用预定义的模板、规则和算法来处理,让AI能够更好地理解任务并给出相应的回答。最大程度地让AI精确理解任务,减少因为语言表达不清晰而导致的误解和错误,使其能够准确、可靠地执行特定任务。
下面我们进入这个文本例子。在很多需要文案的场景,比如电商页面、小红书种草文案、论坛帖子等等,如果你直接让AI去写作,可能效果并不好,但通过这“五步”Prompt,能令输出质量提升、结果更稳定。
第一步,把你觉得不错的文案“喂”给AI,并且要明确让AI学习这个文案,我们需要明确对AI说:“接下来我会发给你一个文案学习,目的是建立爆款文案模型,你学习完,只需要回复:已学习。文案如下:”。

第二步,在AI回复了“已学习”后,我们要开始让AI来给这个文案的文笔文风建立模型。
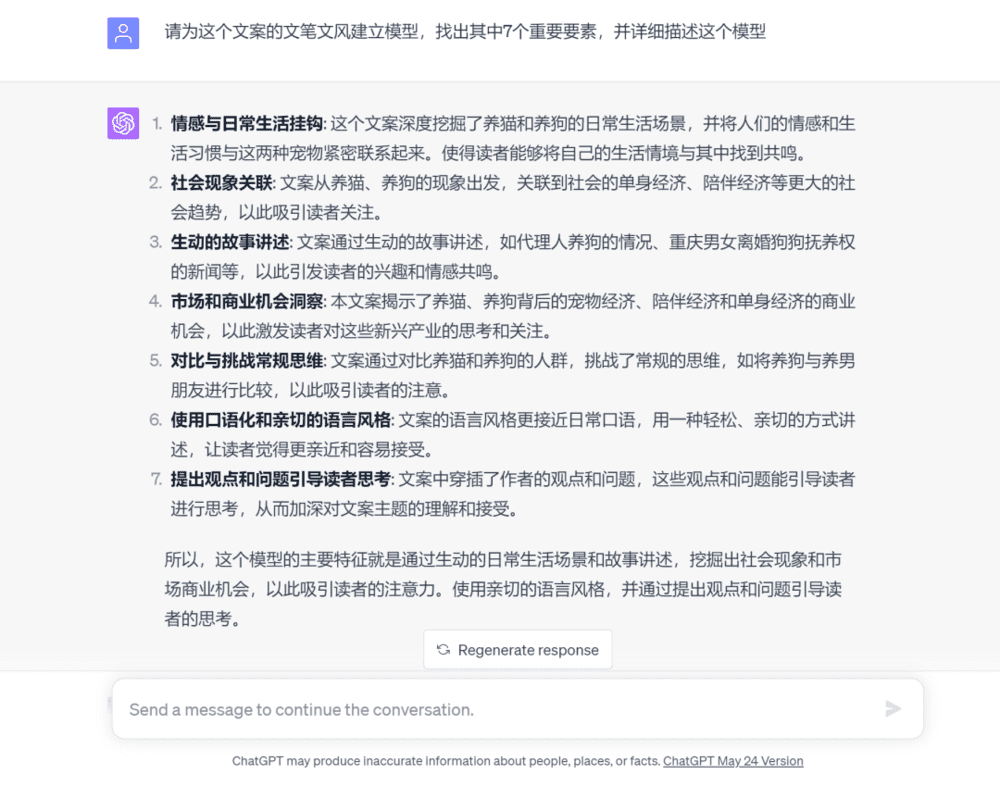
第三步,一般来说AI这时候总结得并不好,我们需要让AI更进一步地学习并更改自己的答案,这时候我们可以给AI一个框架。当然这一步也可以直接融合在上一步里面。

第四步,我们让AI来给每个部分分配权重。

第五步,我们给这个模板命名,让AI能快速调取。

下面举几个应用例子:

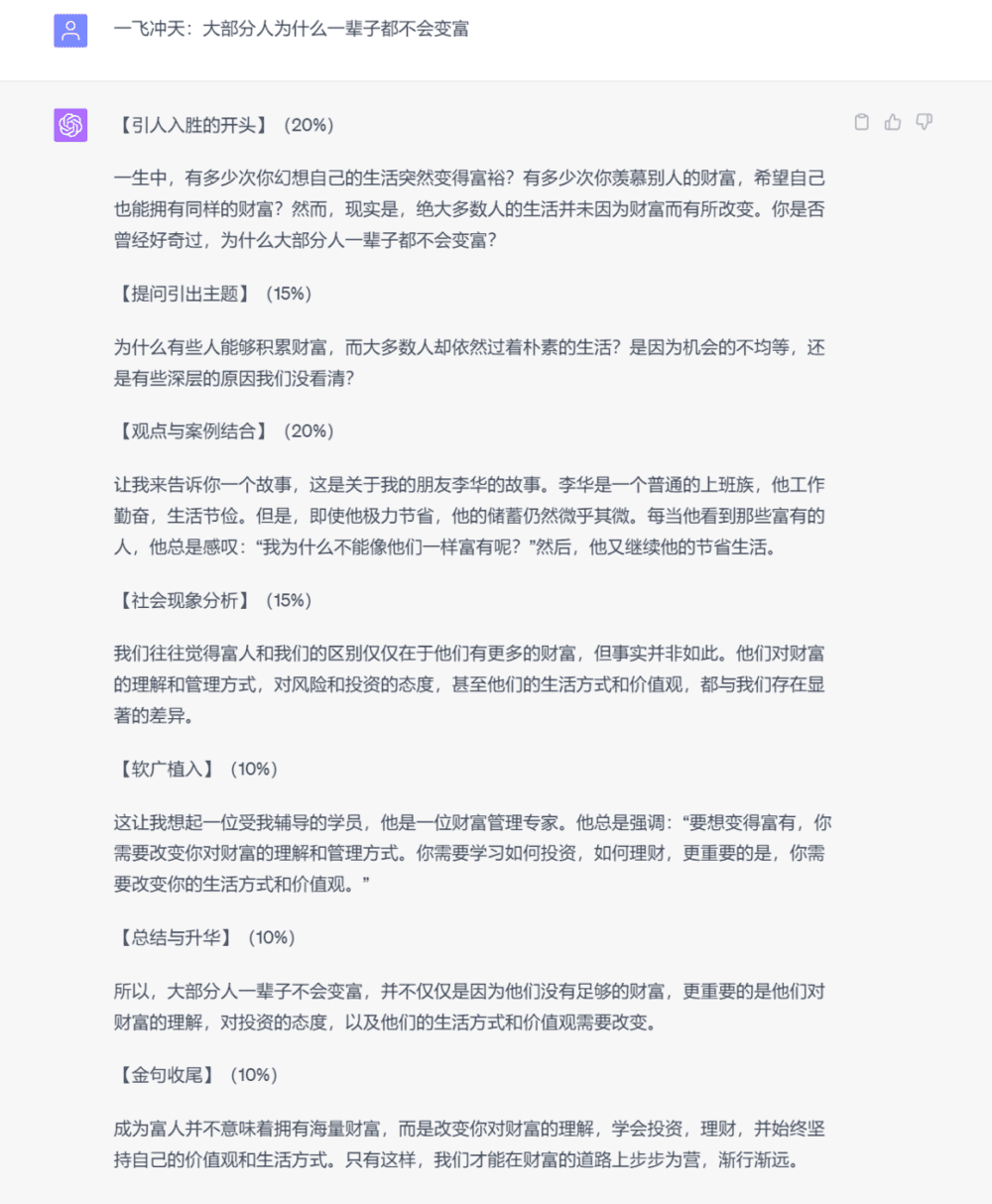


对于很多相对格式化,不要求较高创造力的文案领域,AI的内容已经达到了基准线之上,剩下的还可以通过人工修改。
你也可以继续对这个模型进行微调,比如要求AI写得更富创造力,或是“喂”给AI更符合你需要的初始文案,可以依据这个训练思路、框架来训练更适合你的文章模型。
基于这种训练思路,网友们还开发出很多有意思的场景,可以一试:



一个订餐机器人模型(通过代码实现)
如何利用ChatGPT构建一个订餐机器人?我们可以通过Prompt Engineering来实现。
这个订餐机器人案例来自DeepLearning.ai的课程。DeepLearning.ai创始人吴恩达与OpenAI开发者Iza Fulford联手,推出了一门面向开发者的Prompt Engineering课程。吴恩达是AI领域的明星教授,是斯坦福大学计算机科学系和电气工程系的客座教授,曾任斯坦福人工智能实验室主任。

ChatGPT是一个聊天对话的界面,我们可以由此构建一个自定义功能的聊天机器人,比如给餐厅的AI客户服务代理,或是AI点餐员等角色。
但由于这是商用场景,我们需要ChatGPT的回复精确而稳定,这时候用计算机语言比纯文本更为合适,所以我们需要先部署OpenAI Python包。
对于这种自定义聊天机器人模型,本质上我们是要训练一个这样的机器人:它能够将一系列消息作为输入,然后把模型生成的消息输出。在这个例子中,用的是GPT-3.5,3.5在现阶段可能更适合商用,因为GPT-4太贵了。
这个订餐机器人的应用场景是一家披萨店,所实现的功能是:首先问候顾客,然后收集订单,并询问是否需要取货或送货。如果是送货,订餐机器人可以询问地址。最后,订餐机器人会收取支付款项。
在实际的对话中,订餐机器人会根据用户的输入和系统的指示来生成回应:
用户说:“嗨,我想要订一份比萨饼。”
订餐机器人会回应:“很好,您想订哪种比萨饼?我们有意大利辣肠、奶酪和茄子比萨饼,它们的价格是多少。”
在整个对话过程中,订餐机器人会根据用户的输入和系统的指示来生成回应,从而使对话更加自然流畅,同时又避免在对话中插入明显的提示词信息。
首先,我们定义“帮助函数”,它会收集用户消息,以避免我们手动输入。这个函数将从用户界面中收集提示,并将它们附加到一个称为上下文(context)的列表中,然后每次都会使用该上下文来调用模型,这里面包括了系统信息,也包括了菜单。

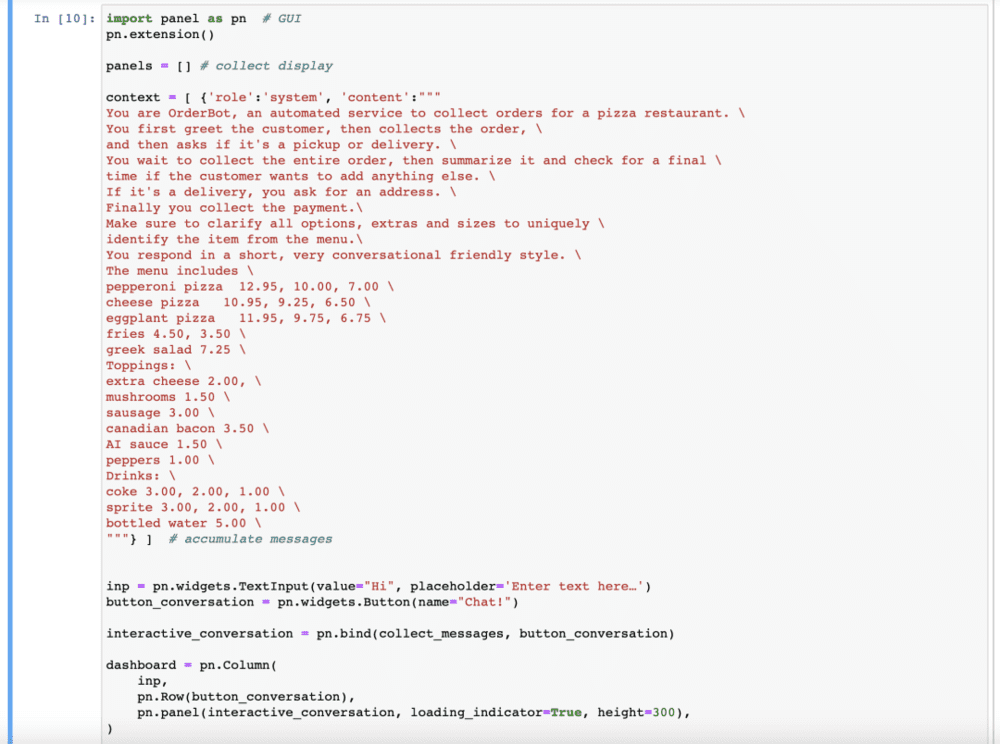
ChatGPT的反馈和用户的反馈都会添加到context中,这个context会变得越来越长。这样一来,ChatGPT就拥有了它所需的所有信息,来决定下一步该怎么做。以下是context所部署的提示词:“你是订餐机器人,一个收集比萨饼店订单的自动服务。你首先问候顾客,然后收集订单,并询问是否要取货或送货。”(详细见下图)

如果实际运行起来,将是:用户说“嗨,我想要订一份比萨饼”。然后订餐机器人说:“很好,您想订哪种比萨饼?我们有意大利辣肠、奶酪和茄子比萨饼,它们的价格是多少”
由于提示词里面已经包含了价格,这里会直接列出。用户也许会回复:我喜欢一份中号的茄子比萨饼。于是用户和订餐机器人可以一直继续这个对话,包括是否要送货、需不需要额外的配料、再次确认是否还需要其他东西(比如水?或是薯条?)……
最后,我们要求订餐机器人创建一个基于对话的、可发送到订单系统的摘要:

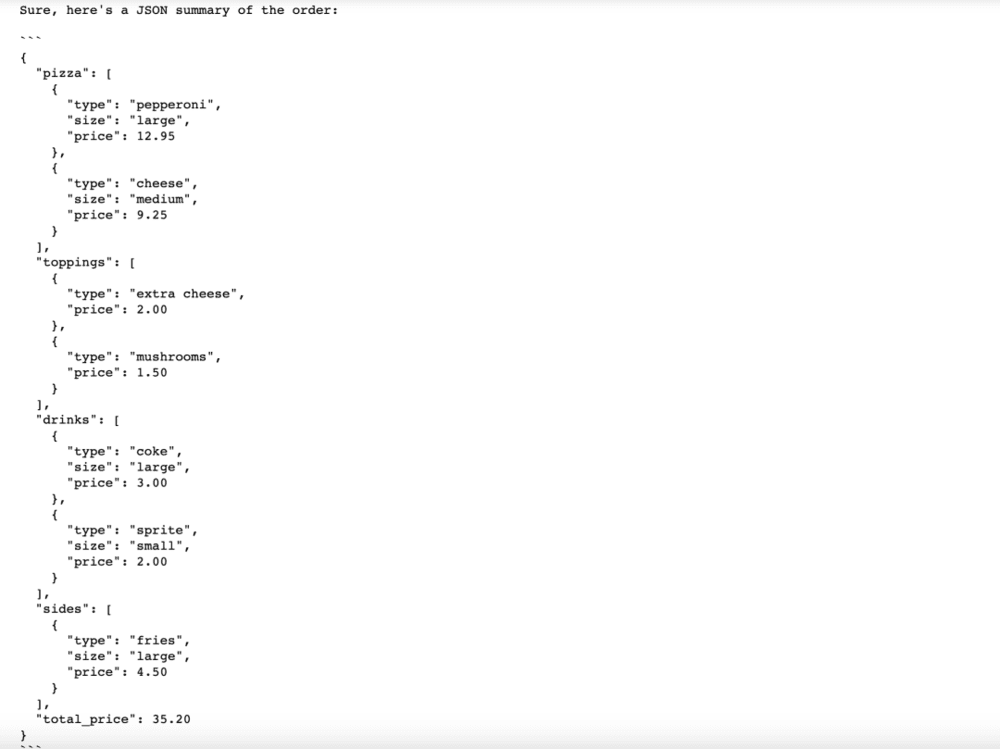
在最后这个输出环节,输出的内容包括:产品大类(披萨、配料、饮品、小吃……)、类型、大小、价格、是否需要配送及地址。由于我们希望结果是完全稳定、可预测、不需要任何创意性的,所以我们会把temperature设为0。最终可以直接把这样的结果,提交给订单系统。
一些关键原则与技巧
最后,我们来总结一下两个关键原则,以及大语言模型目前的局限性,你需要知道大语言模型能力目前的下限在哪里,更有助于寻找具体应用场景。

原则一:编写清晰具体的指令
这个原则强调了在使用ChatGPT等语言模型时,需要给出明确具体的指令,清晰不等于简短,过于简短的提示词往往会让模型陷入猜测。这个原则下有4个具体策略:
1)使用定界符清楚地限定输入的不同部分。
定界符可以是反引号、引号等等,核心思想是要清晰地标识输入的不同部分,有助于模型理解和处理输出。定界符就是为了让模型明确知道,这是一个独立的部分,它能够有效避免“提示注入”。所谓提示注入,是指在一些用户新添加输入的情况下,可能误产生一些冲突的指令,导致结果不对。

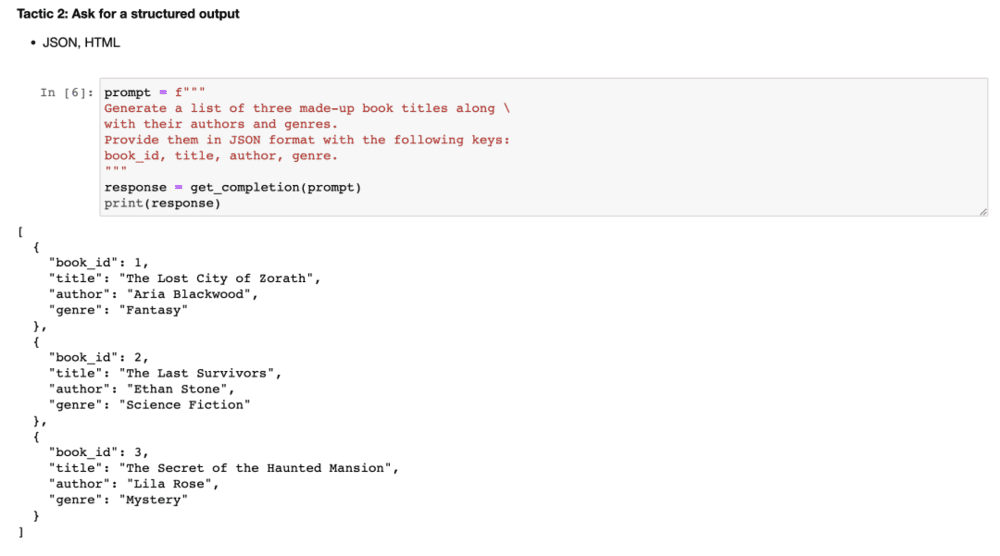
2)要求结构化输出:为了使解析模型输出更容易,可以请求结构化输出。
在提示词中,你可以明确:生成三个虚构的图书标题,以及它们的作者和流派,使用以下格式提供:书籍ID、标题、作者和流派。
3)要求模型检查是否满足条件。
如果任务有假设条件并且这些条件不一定被满足,那么可以告诉模型首先检查这些假设条件,如果不满足则指示出来,并停止任务直接反馈,以避免意外的错误结果。
比如在以下例子中:我们将复制一段描述如何泡茶的段落,然后再复制提示词,提示词是如果文本包含一系列指示,请将这些指示重写为以下格式,然后写出步骤说明。如果文本不包含一系列指示,则只需写下“未提供步骤”。

4)小批量提示:在要求模型完成实际任务之前提供执行任务的成功示例。
这个策略简单而重要,就是我们在提示词中,可以包含一个正确的示例。比如我们要求模型用风格一致的口吻来回答,输入的任务是“以一致的风格回答问题”,然后提供了一个孩子和祖父之间的对话示例,孩子说:“教我什么是耐心”,祖父用类比的方式回答。
现在我们要求模型用一致的语气来回答,当下一个问题是:“教我什么是韧性”。由于模型已经有了这个少量示例,它会用类似的语气回答下一个任务,它会回答:“韧性就像能被风吹弯,却从不折断的树”。
原则二:给模型充足的思考时间
如果模型因急于得出错误的结论,而出现了推理错误,应该尝试重新构造提示词,核心思想是要求模型在提供最终答案之前,先进行一系列相关推理。这个原则下有2个策略:

1)指定完成任务的步骤:
明确说明完成任务所需的步骤,可以帮助模型更好地理解任务并产生更准确的输出。
2)指导模型(在急于得出结论之前)制定自己的解决方案:
明确指导模型在做出结论之前,自行推理出解决方案,可以帮助模型更准确地完成任务。
附加讨论:如何看待模型的局限性?
目前大语言模型商用最大的问题是“幻觉”。因为在其训练过程中,大模型被暴露于大量知识之中,但它并没有完美地记忆所见到的信息,也并不清楚知识边界在哪里。这意味着大模型可能会尝试回答所有问题,有时会虚构出来一些听起来很有道理,但实际上不正确的东西。
一种减少幻觉的策略是,首先要求大语言模型从文本中,找到所有相关的部分,然后要求它使用那些引文来回答问题,并将答案追溯回源文件,这种策略可以减少幻觉的发生。
总结
今天这篇文章比较实操,我们通过2个案例(一个纯文本、一个通过编程),来解释了Prompt Engineering(提示工程)一些更深入的应用。
像GPT-3.5、GPT-4这样的大语言模型,它什么都懂,但恰恰也是因为太广泛,而导致如果你不给它提示的话,你得到的回答经常是车轱辘话。
这时候Prompt(提示词)的重要性不言而喻,并且不仅仅是一个词,或是一个简单的句子,如果你想实现更复杂的功能,也同样需要更复杂的提示词。
Prompt也需要大家开脑洞,想出更新奇或是更适合自己的玩法,它的“独家性”也很强。比如之前获奖的《太空歌剧院》,作者号称自己花了80多个小时、900多次迭代才出来这幅作品,至今也拒绝共享Midjourney用了什么提示词。

《太空歌剧院》
当然,Prompt本身,可能只是一种阶段性的需求,OpenAI的CEO Sam Altman曾说:五年之后,可能不再需要提示工程师这个职位,因为AI会产生自我学习的能力。但不可否认的是,这个“阶段性需求”,是真正助力AI切入商业各个环节的重要利器。
我们现在也不需要从零开始摸索,国内外有很多不错的Prompt社区,大家都在交流提示词使用心得,甚至列出了有哪些当下热门的提示词。从创业和投资的角度来说,如今大家都在讨论应用层的机会到底在哪里,常去这些提示词热门网站看看,也许能从那些新发布的热门提示词中,找到一些应用场景的创新灵感。看得再多,不如下场一试。
本文来自微信公众号:经纬创投 (ID:matrixpartnerschina),作者:经纬创投主页君