
本文来自微信公众号:硅星人 (ID:guixingren123),作者:李禾子,原文标题:《大模型让数据库行业撕起来了:Databricks和Snowflake让开发者选边站》,题图来自:《尚气与十环传奇》
大模型的风已经不可避免地刮到了大数据行业,火药味还不小。
这不快临近了有人注意到,两家大数据行业的“宿敌”Databricks和Snowflake,今年双双把各自一年一度最重要的峰会选在了同一时段——6月26日-29日举办。
这可是这么多年来都没有过的事。
不仅如此,他们还“不约而同”把今年大会的主题都往AI靠拢了。Databricks直接给大会取名叫“Data+AI Summit”,官网一点进去就是一个硕大的“Generation AI”:

Snowflake也给自己的大会加了一个很牛的定语:“全球最大的数据、App和AI主题大会”:

这说明了什么?说明两家公司在明目张胆逼着参会者们做选择:你要去了他们的会,再来我们这恐怕是来不及了。
要知道这俩公司,一个在旧金山,一个在拉斯维加斯,自驾要9个小时,飞机也得飞1个半小时。参会者想兼得鱼和熊掌,怕不是要折腾个够呛。
下面重头戏来了,不仅时间重合,两家公司都各自请到了重磅嘉宾来发表主题演讲——Databricks请到的是微软的CEO萨蒂亚·纳德拉(Satya Nadella),Snowflake则是英伟达CEO黄仁勋。
个个都是大佬。
有网友提醒大家,鉴于两家公司的峰会在同一时间举办,“如果你还没选边站,那么现在该你选择的时候到了”。
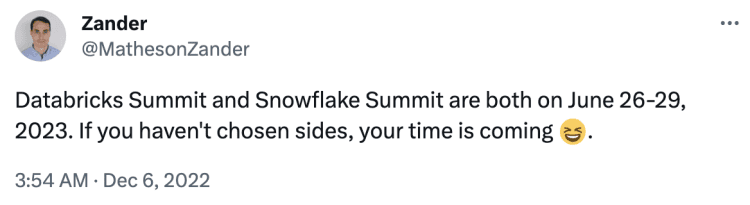
当然也有不乏准备两边跑的人。Striim公司的产品经理John Kutay就计划在两个大会上分别发表讲话,不过也“将评估拉斯维加斯和旧金山两地的路程和时间”。
有还没做好决定的网友问他在Databricks上的发言内容会是啥,他说:“我想去,但是到时候还得赶去SF,唉。”
对此,甚至还有个网友做了个离谱的梦:“刚刚梦到所有人都在Snowflake的大会上感染新冠了,因为Snowflake不想让我们参加Databricks的峰会……”

Snowflake和Databricks都是目前大数据分析公司中的佼佼者。前者于2021年创办,并在2020年9月上市,上市首日收盘股价飙升111.6%,报253.93美元,成为美国有史以来规模最大的软件IPO。
此外,Snowflake的股东名单里还不乏Salesforce和巴菲特这样大名鼎鼎的投资方。
创办于2013年的Databricks则是目前一级市场中的超级独角兽,曾在2021年连续获得两轮10亿美元级别的大额融资,估值高达380亿美元(2021年数据)。
一些中国从业者也更习惯叫它“砖厂”。
两家公司不仅经常被外界拿来作比较,彼此之间也总是明着暗着各种较劲。
最著名的一次喊话是在2021年。当时眼看着Snowflake靠着云数据仓库就做到了千亿美元市值,Databricks坐不住了,发了一篇文章称其数据湖技术创下了TPC-DS基准测试新记录。
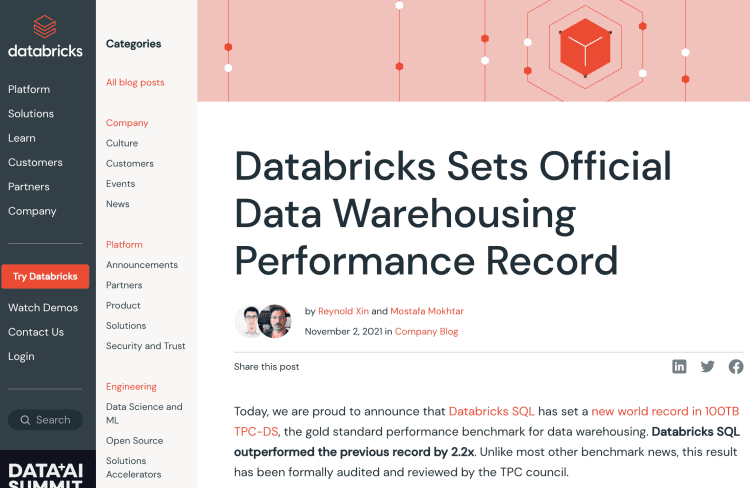
重点是,Databricks还强调了第三方研究表明其实际性能可达Snowflake的2.5倍。
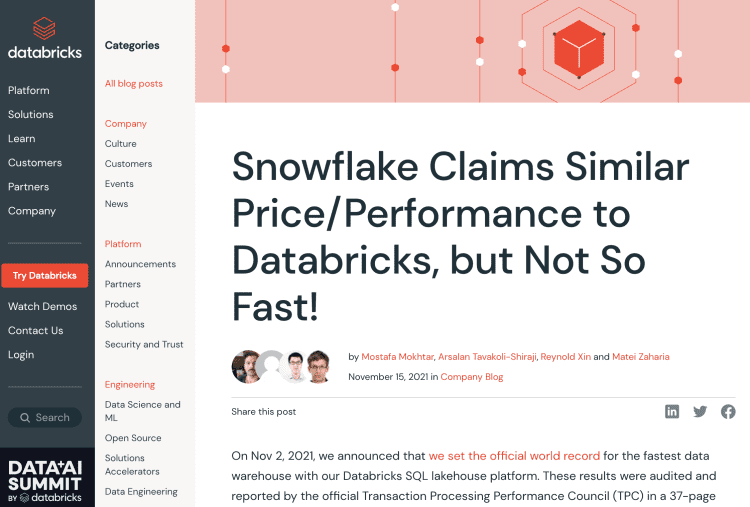
接着过了十天,Snowflake回应,发布了自己的测试结果,同时称Databricks公布的性能比较结论缺乏完整性,而且研究本身也存在缺陷。
Snowflake创始人还强调这种基准测试没什么意义,在这个年代发布数据库基准测试结果,是“将正常的技术交流变成了缺乏完整性的营销噱头”。

不甘心的Databricks再次回应,创始人发了一篇博客,这次是更严重的指控:Snowflake为了测试结果竟然改了TPC-DS的输入数据。
从那之后,两家之间的互呛就没有停过。
在去年和投资人Matt Turck的一次对话中,Databricks的联合创始人兼CEO Ali Ghodsi还不避讳地谈到了与Snowflake的竞争。
他先是商业性地夸了下Snowflake有着“可能是市场上最好的数据仓库”,并且“Databricks与Snowflake将共存于可能70%的客户中”。
这里补充一点,Snowflake主要用的是数据仓库技术,Databricks用的则是数据湖技术,这也是两家技术思路最主要的不同。
接着Ali Ghodsi就宣传起了自家的数据湖:“公有云计算供应商有动力推动更多人把数据存到他们的数据湖中……我认为数据湖的范式将获胜。”
产品性能上的你追我赶还没完,现在Databricks和Snowflake又暗戳戳在大模型上较上劲了。
Databricks在今年3月发布了一个名叫Dolly(据说是为了向第一只克隆羊多莉致敬)的开源大语言模型,称“只需30美元、一台服务器和三个小时,我们就能教Dolly开始进行人类级别的交互”。

这明摆着也是在针对ChatGPT这样门槛更高的产品,意思就是AI不再是只有大型科技公司才能负担得起的东西,不用拿多少融资,任何人都能开发出一个真正像人类的AI。
Databricks接着又在4月发布了该大语言模型的开源迭代版本Dolly 2.0。
Snowflake这边也在不断炒作大模型,在4月发布文章称正在为生成式AI和大语言模型搭建一个以数据为中心的平台,并在文中详细解读了这么做的依据和将带来的影响。
随后的5月,Snowflake宣布收购初创公司Neeva,以在其数据云平台中添加基于AI的生成搜索。

虽然在AI大模型方面两家公司还没有互踏进对方的领地,不过这次年度峰会举办时间的重叠已经说明了他们的态度。
有趣的是,有人在谷歌搜索“Snowflake conference”,出来的第一个结果却是Databricks家的大会链接,其次才是Snowflake的链接。
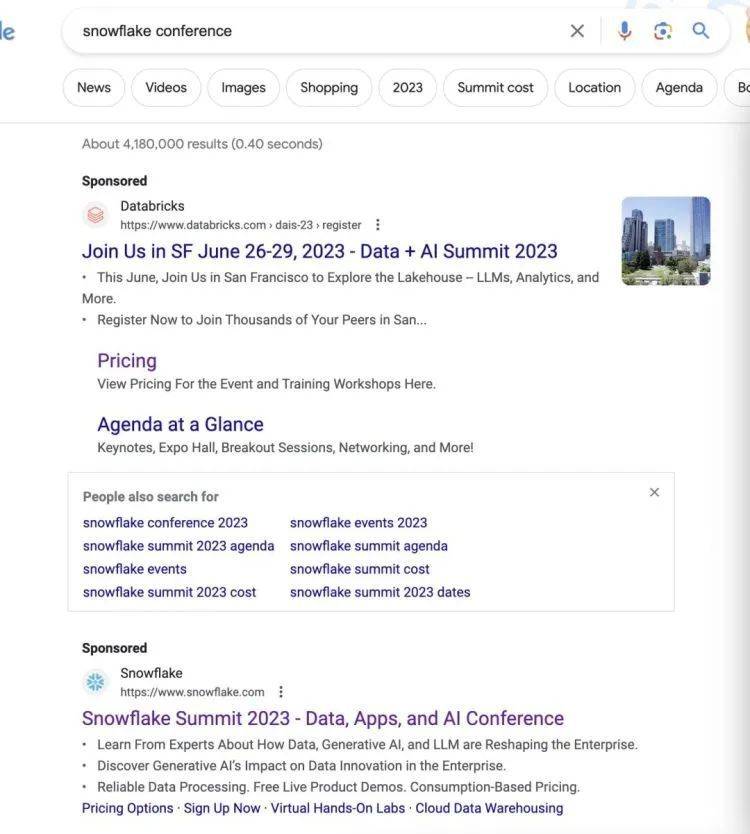
就等于说,Databricks买了竞争对手的关键字,来卖自己的广告。

我们也发现,在谷歌同时输入“Databricks+Snowflake”搜索,前两条都是广告(这个结果是动态展示的)——Databricks依然在竞价排名的第一位置宣传着自己取得的成绩,但第二则是一家技术服务商,在宣传自己帮客户迁移到Snowflake的服务,这个投放甚至比前面有人发现的两家直接竞价的情况更有意思。Databricks依然可以被解读为(在商业攻势上)进攻性更强、更有战斗力的一方,但在两家的竞争中一些技术服务商也在抓紧寻找商机,而且似乎认为转移到Snowflake的需求更大。
不论如何,一场大战又要打响了。现在大模型领域不缺搅局者,到了Databricks和Snowflake这里,兴许就成了谁先干掉谁的问题。
本文来自微信公众号:硅星人 (ID:guixingren123),作者:李禾子