
本文来自微信公众号:芯世相(ID:xinpianlaosiji),作者:三分浅土,题图来自:视觉中国
存储的寒气从去年吹到现在,虽然今年开年以来不时听到触底反弹的声音,但市场仍未见明显解冻现象。
TrendForce数据显示,占据存储市场一半以上的DRAM,已经连续三个季度下跌。DRAM三巨头三星、SK海力士和美光在出货量方面仅美光略有上升,其余均衰退;平均销售单价三者均下跌,并且预计三巨头在Q2还将继续亏损。
以DRAM 4月的指标性产品DDR4 8GB为例,批发价为每个1.48美元左右,环比下跌1%;4GB产品价格为每个1.1美元左右,环比下跌8%。
在DRAM的整体颓势之中,HBM(高带宽内存,High Bandwidth Memory)却在逆势增长。身为DRAM的一种,与大部队背道而驰,价格一路水涨船高。据媒体报道,2023年开年后三星、SK海力士两家存储大厂HBM订单快速增加,HBM3规格DRAM价格上涨5倍。HBM3原本价格大约30美元每GB,现在的价格怕是更加惊人。
一边是总体DRAM跌到成本价,一边是“尖子生”HBM价格涨5倍。
HBM到底是什么?用在什么地方?为什么和其他DRAM差别这么大,价格水涨船高?
什么是HBM?
HBM(High Bandwidth Memory),意为高带宽存储器,是一种面向需要极高吞吐量的数据密集型应用程序的DRAM,HBM的作用类似于数据的“中转站”,就是将使用的每一帧,每一幅图像等图像数据保存到帧缓存区中,等待GPU调用。
正如其名,HBM与其他DRAM最大的差别就是拥有超高的带宽。最新的HBM3的带宽最高可以达到819 GB/s,而最新的GDDR6的带宽最高只有96GB/s,CPU和硬件处理单元的常用外挂存储设备DDR4的带宽更是只有HBM的1/10。
超高的带宽让HBM成为了高性能GPU的核心组件。自从去年ChatGPT出现以来,HBM作为AI服务器的“标配”,更是开始狠刷存在感。从“鲜有问津”的高岭之花,变成了大厂们争相抢夺的“香饽饽”。
HBM为什么可以拥有这么高的带宽?它和其他DRAM的差别在哪?为什么会成为高端GPU的标配呢?
先说一下HBM是怎么发展而来的。
按照不同应用场景,JEDEC(固态技术协会)将DRAM分为三个类型:标准DDR、移动DDR以及图形DDR,HBM属于最后一种。
图形DDR中,先出现的是GDDR(Graphics DDR),它是为了设计高端显卡而特别设计的高性能DDR存储器规格,是打破“内存墙”的有效方案。
由于处理器与存储器的工艺、封装、需求的不同,二者之间的性能差距越来越大,过去20年中,硬件的峰值计算能力增加了90,000倍,但是内存/硬件互连带宽却只是提高了30倍。当存储的性能跟不上处理器,对指令和数据的搬运(写入和读出)的时间将是处理器运算所消耗时间的几十倍乃至几百倍。
可以想象一下,数据传输就像处在一个巨大的漏斗之中,不管处理器灌进去多少,存储器都只能“细水长流”。而数据交换通路窄以及其引发的高能耗,便是通常所说的“内存墙”。
为了让数据传输更快,就必须要提高内存带宽,内存带宽是处理器可以从内存读取数据或将数据存储到内存的速率。GDDR采用传统的方法将标准PCB和测试的DRAMs与SoC连接在一起,旨在以较窄的通道提供更高的数据速率,进而实现必要的吞吐量,具有较高的带宽和较好的能耗效率。
不过,随着AI等新需求的出现以及风靡,对带宽的要求更高了,GDDR也开始不够用。但是按照GDDR现有的模式很难有突破性的带宽进展,存储厂商们望着现有的GDDR,终于顿悟:这样“躺平”下去不行,得“叠”起来。于是,HBM出现了。
所以,HBM其实是GDDR的替代品,是将DDR芯片堆叠在一起后和GPU封装在一起,实现大容量,高位宽的DDR组合阵列。听起来有点复杂,看下面这张图就一目了然了。
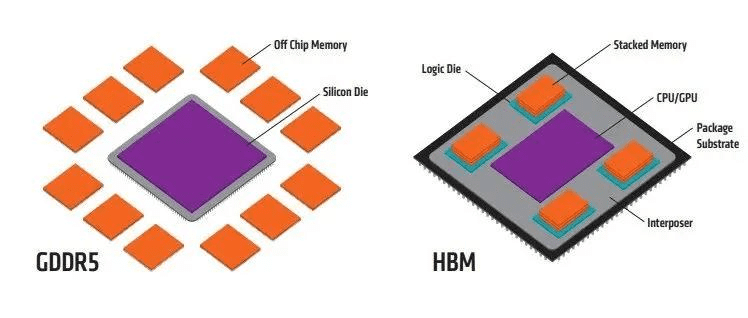
来源:AMD
GDDR作为独立封装,在PCB上围绕在处理器的周围,而HBM则排布在硅中阶层(Silicon Interposer)上并和GPU封装在一起,面积一下子缩小了很多,举个例子,HBM2比GDDR5直接省了94%的表面积。并且,HBM离GPU更近了,这样数据传输也就更快了。
HBM之所以可以做到这样的布局,是因为采用了3D堆叠技术。HBM将DRAM裸片像摩天大楼一样垂直堆叠,并通过硅通孔(Through Silicon Via, 简称“TSV”)技术将“每层楼”连接在一起,贯通所有芯片层的柱状通道传输信号、指令、电流,以增加吞吐量并克服单一封装内带宽的限制。你可以将HBM想象成一个切得整整齐齐的三明治,TSV就是扎在里面的那根牙签,将整个三明治固定并打通。
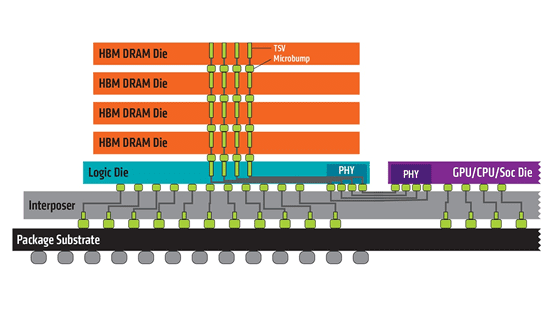
从侧面来看HBM,来源:AMD
采用3D堆叠技术之后,其直接结果就是接口变得更宽,其下方互联的触点数量远远多于DDR内存连接到CPU的线路数量。从传输位宽的角度来看,4层DRAM裸片高度的HBM内存总共就是1024 bit位宽。很多GPU、CPU周围都有4片这样的HBM内存,则总共位宽就是4096bit。
因此,与传统内存技术相比,HBM具有更高带宽、更多I/O数量、更低功耗、更小尺寸。
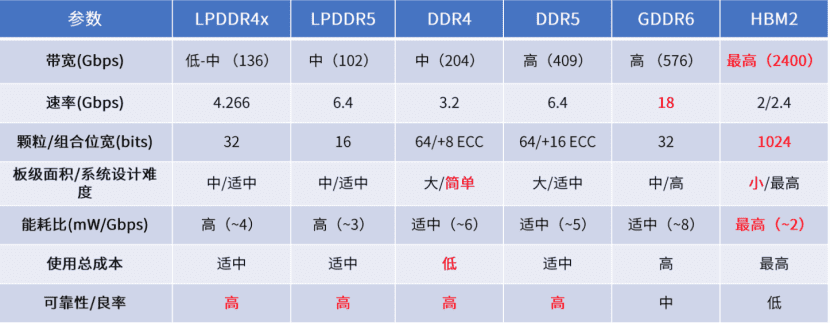
HBM与其他几种内存方案的参数对比;来源:芯耀辉
HBM朝着不断提高存储容量、带宽,减小功耗和封装尺寸方向升级,目前已升级到HBM3。从最初的1GB存储容量和128GB/s带宽的HBM1发展到目前的24GB存储容量和819GB/s带宽。

来源:SK 海力士、Rambus
不过,虽然HBM拥有优秀的带宽,但也不是适用于所有应用,HBM也有自身的局限性:
第一,缺乏灵活性,由于HBM与主芯片封装在一起,所以不存在容量扩展的可能;其次,容量小,虽说一片HBM封装虽然可以堆8层DRAM裸片,但也仅有8G Byte;第三,访问延迟高。HBM由于互联宽度超宽,这就决定了HBM的传输频率不能太高,否则总功耗和发热撑不住,所以延迟高(延迟指从读取指令发出,到数据准备就绪的过程,中间的一个等待时间)。
简单概括一下,同一个GPU核心,往往低端显卡用DDR内存,高端用GDDR内存,再高端用HBM2内存。目前,HBM已经可以算是高端GPU的标配了。
借AI东风,HBM需求激增
2021年的时候,HBM位元需求占整体DRAM市场只有不到1%。主要是因为HBM高昂的成本以及当时服务器市场中搭载相关AI运算卡的比重仍小于1%,且多数存储器仍使用GDDR5(x)、GDDR6来支持其算力。
而到了今年年初,HBM的需求激增,并且业内人士称,与最高性能的DRAM相比,HBM3的价格上涨了五倍,HBM“逆袭”的主要原因,就是AI服务器需求的爆发。
在ChatGPT火了之后,一下子点燃了AIGC(生成式AI)的热潮,谁不追,谁就要被抛下,于是大厂们纷纷开始推出自己的类ChatGPT的大模型。据不完全统计,自3月16日百度率先公布“文心一言”以来,国内已有超过30项大模型产品亮相。
而AI大模型的基础,就是靠海量数据和强大算力来支撑训练和推理过程。AI服务器作为算力基础设施单元服务器的一种类型也来到了台前,备受追捧。TrendForce集邦咨询预估,2023年AI服务器(包含搭载GPU、FPGA、ASIC等)出货量近120万台,同步上修2022-2026年AI服务器出货量年复合成长率至22%。
HBM成本在AI服务器成本中占比排名第三,约占9%,单机ASP(单机平均售价)高达18,000美元。所以,AI服务器是HBM目前最受瞩目的应用领域。
AI服务器需要在短时间内处理大量数据,包括模型训练数据、模型参数、模型输出等。要想让AI更加“智能”,AI大模型庞大的参数量少不了,比如ChatGPT基于的GPT3.5大模型的参数量就高达135B。数据处理量和传输速率的大幅提升,让AI服务器对带宽提出了更高的要求,而HBM基本是AI服务器的标配 。
AI服务器GPU市场以NVIDIA H100、A100、A800以及AMD MI250、MI250X系列为主,这些GPU都配备了HBM。2023 GTC大会发布的ChatGPT专用最新H100 NVL GPU,也配置了188GB HBM3e内存。HBM方案目前已演进为主流的高性能计算领域扩展高带宽的方案。
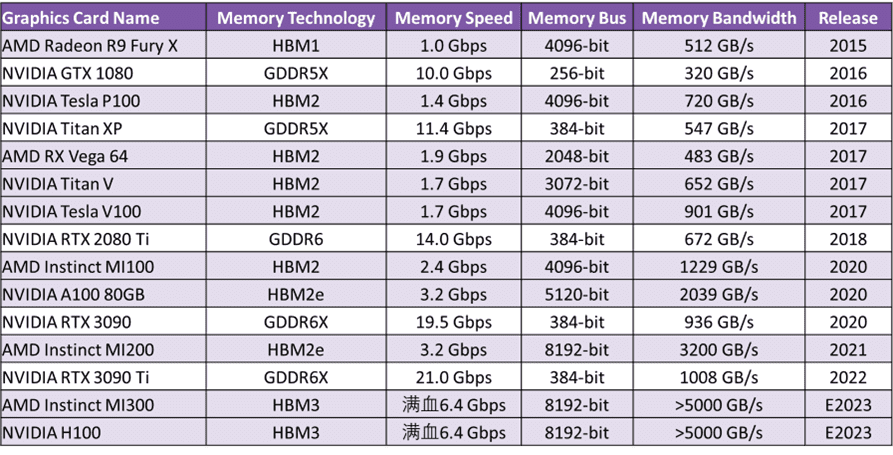
目前推出的搭载HBM和GDDR的GPU产品,来源:奎芯科技
随着高端GPU需求的逐步提升,TrendForce集邦咨询预估2023年HBM需求量将年增58%,2024年有望再成长约30%。
除了AI服务器,汽车也是HBM值得关注的应用领域。汽车中的摄像头数量,所有这些摄像头的数据速率和处理所有信息的速度都是天文数字,想要在车辆周围快速传输大量数据,HBM具有很大的带宽优势。但是最新的HBM3目前还没有取得汽车认证,外加高昂的成本,所以迟迟还没有“上车”。不过,Rambus的高管曾提出,HBM 绝对会进入汽车应用领域。
AR和VR也是HBM未来将发力的领域。因为VR和AR系统需要高分辨率的显示器,这些显示器需要更多的带宽来在 GPU 和内存之间传输数据。而且,VR和AR也需要实时处理大量数据,这都需要HBM的超强带宽来助力。
此外,智能手机、平板电脑、游戏机和可穿戴设备的需求也在不断增长,这些设备需要更先进的内存解决方案来支持其不断增长的计算需求,HBM也有望在这些领域得到增长。并且,5G和物联网等新技术的出现也进一步推动了对HBM的需求。
不过,目前来讲,HBM还是主要应用于服务器、数据中心等领域,消费领域对成本比较敏感,因此HBM的使用较少。
可以肯定的是,对带宽的要求将不断提高,HBM也将持续发展。市场调研机构Omdia预测,2025年HBM市场的总收入将达到25亿美元。据新思界发布的分析报告显示,预计2025年中国HBM需求量将超过100万颗。
存储巨头争霸HBM
HBM作为DRAM的一种,其市场也被三巨头瓜分。目前技术走在最前面的是SK海力士,并且它也拥有第一的市占率,高达50%,紧随其后的是三星,市占率约40%,美光约占10%。预计到2023年,SK 海力士市占率有望提升至 53%,而三星、美光市占率分别为38%及9%。
下游厂商主要是CPU/GPU厂商,如英特尔、英伟达以及AMD。因为HBM是与GPU封装在一起的,所以HBM的封装基本也由晶圆代工厂一同包揽完成,而晶圆代工厂商包括台积电、格芯等也在发力HBM相关技术。国内厂商布局规模不大,只有一些企业涉及封测。

来源:财联社
总的来说,HBM的竞争还是在SK 海力士、三星以及美光之间展开。
从技术上来看,SK海力士是目前唯一实现HBM3量产的厂商,并向英伟达大量供货,配置在英伟达高性能GPU H100之中,持续巩固其市场领先地位。根据此前的资料介绍,SK海力士提供了两种容量产品,一个是12层硅通孔技术垂直堆叠的24GB(196GB),另一个则是8层堆叠的16GB(128GB),均提供819 GB/s的带宽,前者的芯片高度也仅为30微米。相比上一代HBM2E的460 GB/s带宽,HBM3的带宽提高了78%。此外,HBM3内存还内置了片上纠错技术,提高了产品的可靠性。
三星在2022年技术发布会上发布的内存技术发展路线图中,显示HBM3技术已经量产,其单芯片接口宽度可达1024bit,接口传输速率可达6.4GBps。2024年预计实现接口速度高达7.2GBps的HBM3P,预计2025年在新一代面向AI的GPU中见到HBM3P的应用。
美光科技走得较慢,于2020年7月宣布大规模量产HBM2E,HBM3也仍作为其产品线在持续研发之中。
HBM之后的发力点在于打破速度、密度、功耗、占板空间等方面的极限。
为了打破速度极限,SK海力士正在评估提高引脚数据速率的传统方法的利弊,以及超过1024个数据的I/O总线位宽,以实现更好的数据并行性和向后设计兼容性。简单来讲,即用最少的取舍获得更高的带宽性能。
另一方面厂商也在致力于提高功耗效率,通过评估从最低微结构级别到最高Die堆叠概念的内存结构和操作方案,最大限度地降低每带宽扩展的绝对功耗。
不过要想有上述突破,存储厂商要与上下游生态系统合作伙伴携手合作和开放协同,将HBM的使用范围从现有系统扩展到潜在的下一代应用。
HBM的下游也在持续发力,英伟达历代主流训练芯片基本都配置HBM;英特尔Sapphire Rapids发布全球首款配备HBM的X86 CPU;AMD也在持续更新HBM产品线。
借着AI的东风,HBM最近热度大幅上升,从原来的“小透明”变成了“网红”。并且,AI的浪潮还在愈演愈烈,HBM今后的存在感或许会越来越强。集邦咨询预计2023年至2025年HBM 市场年复合增长率有望增长40%至45%。而其他机构预测DRAM5年内(2022-2027)年复合增长率仅有6.1%。不过要清楚的是,与庞大的DRAM市场比起来,HBM还是“渺小的”,大约只占整个DRAM市场的1.5%。
参考资料:
[1]HBM高带宽内存:新一代DRAM解决方案,方正证券
[2]HBM 成高端 GPU 标配,充分受益于 AI 服务器需求增长,广发证券
[3]HBM,增长速度迅猛!半导体行业观察
[4]存储巨头竞逐HBM,半导体行业观察
本文来自微信公众号:芯世相(ID:xinpianlaosiji),作者:三分浅土