
本文来自微信公众号:硅星人 (ID:guixingren123),作者:Juny,头图来自:Hugging Face
由ChatGPT引发的人工智能风潮还在猛烈地刮着。但从各个角度来看,目前这都是一个巨头争霸的战场:更大的模型、更强的算力、更多的用户、更雄厚的资金……这些都似乎成为了想要加入这场角逐的门票。与此同时,核心技术的研究也逐渐开放走向封闭。
而在这高墙正在筑起的过程中,也有一些新锐的创业公司想要高举旗帜来一场革命。其中,尤其引人注目的是一家名为Hugging Face开源创业公司。
目前,Hugging Face已经是全球最受欢迎的开源机器学习社区和平台,不仅创下了GitHub有史以来增长最快的AI项目记录,估值也一路冲破了20亿美元。近期,微软和浙江大学联合发布的一篇关于HuggingGPT的论文更是把Hugging Face推到了舞台中心,也让更多人关注到了当前这股与众不同的人工智能发展力量。
HuggingGPT火了,Hugging是啥?
本月初,微软亚洲研究院和浙江大学联合发布了一项最新的名为HuggingGPT的研究,介绍了一个全新的协作系统,让开发者能够在ChatGPT的帮助下快速、准确地去选择合适的人工智能模型,从而完成包括文字、视频、语音等多模态在内的复杂任务。
该项目目前已经在Github上开源,还有一个超拉风的名字叫JARVIS(没错,就是跟钢铁侠的助手一个名字)。在这个研究中,主要涉及到两个主体,一个是众所周知的ChatGPT,另一个则是AI社区Hugging Face。
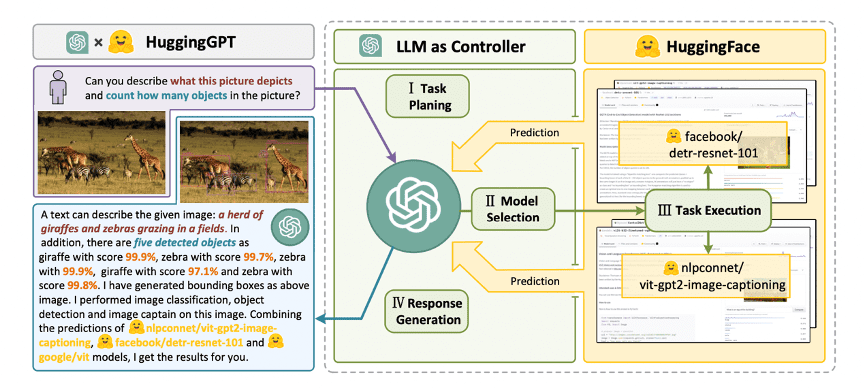
那么Hugging Face是做什么的?
简单来说,Hugging Face是一个针对人工智能的开源平台,用户可以在上边发布和共享预训练模型、数据集和演示文件等。目前Hugging Face上已经共享了超过10万个预训练模型,1万多个数据集,包括微软、谷歌、Bloomberg、英特尔等各个行业超过1万家机构都在使用Hugging Face的产品。
在HuggingGPT中,ChatGPT通过扮演了“操作大脑”的角色,能够自动解析用户提出的需求,接着在 Hugging Face 的“AI模型池”里进行自动模型选择、执行和报告,为开发者们开发更复杂的人工智能程序提供了极大的便利。
虽然在模型上ChatGPT跟Hugging Face能够牵手,但从本质上来说,Hugging Face跟OpenAI目前是在做两个相反方向的事。其中最大的不同点在于,在开发者服务方面,OpenAI现在正在搭建人工智能开发的围墙,仅允许满足条件的机构和个人进入,但Hugging Face则希望每个人都可以访问生成式 AI 模型,包括各类企业和所有普通开发者。
今年2月,OpenAI上线了一个名为Foundry的新开发者平台,用户可以在这个平台上运行OpenAI最新的机器学习模型,但在产品的描述中,OpenAI明确表示Foundry是为运行较大工作负载的尖端客户设计,而一份价格表显示,即使是 GPT-3.5 的轻量级版本,三个月费用高达7.8万美元,一年费用为 26.4万美元。
就在Foundry发布后,Hugging face便立刻宣布了其与 AWS 的最新合作伙伴关系,并发出了“让人工智能走向开放”的呼吁。通过该合作,任何开发人员都将能够使用 AWS 的托管服务并处理 Hugging Face 上可用的任何模型。

在现在巨头林立的人工智能战场上,Hugging Face就像是一支强有力的民间力量。当巨头们都在努力保持自己生成式 AI 的霸主地位的时候,Hugging Face 的目标则是寻找各种途径来保持 AI 研究空间的开放。
而这样的特点也让Hugging Face目前颇有一些“中立”的色彩。无论微软、谷歌、亚马逊、Meta这些大公司打得再激烈,但它们几乎全都是Hugging Face的支持者。
那么,Hugging Face究竟是如何发展起来的,它具体做着什么样的业务?
一次歪打正着的创业,造就AI界的顶流“笑脸”
在普通人的眼中,人工智能一向都属于“冷感”很强的技术领域,无论是充斥着大量数字、模型的算法,还是由各种机械零件组装成的机器人,都不免让人感到有些距离感。但作为专为人工智能开发者服务的Hugging Face却主打了一个反差萌,笑脸Emoji再加上一双摊开的小手,logo甚至有点过分可爱。

之所以有这样一个可爱的logo,是因为一开始Hugging Face做的产品其实是一款针对青少年群体的聊天机器人。
当时Hugging Face的想法是基于自然语言处理(NLP)的人工智能技术,来为年轻人们开发一个带有娱乐性、类似于电子宠物一样的个性化聊天机器人,让大家可以在无聊的时候跟它聊八卦、问它问题、让它生成一些有趣的图片之类的事情。
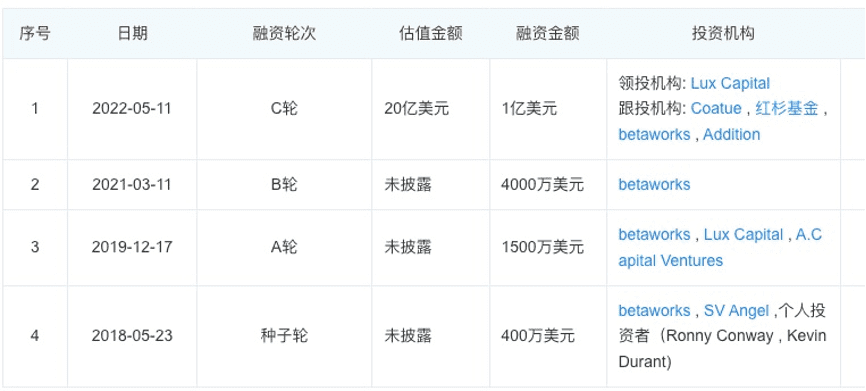
这种新颖的人机社交模式得到了一些关注。2017年3月9号,Hugging Face App在iOS App Store正式推出,并拿到了包括SV Angel、NBA球星杜兰特在内的120万美元的天使投资。此后一年多,Hugging Face都一直围绕着自己的聊天机器人业务在做着自然语言理解的相关训练并发布相关的产品,高峰时期每天处理的消息数量达到了1百万条。在2018年5月,它又获得了400万美元的种子轮融资。
虽然发展得还算不错,但由于当时的人工智能的理解能力和聊天水平远不及ChatGPT这样智能有趣,再加上并非刚需的业务场景,Hugging Face的规模一直都难以扩大。
但为了开发这个聊天机器人,Hugging Face的团队做了一个很重要的事,那就是构建了一个底层库来容纳各种机器学习模型和各种类型的数据集。包括帮助训练聊天机器人检测文本消息情绪、生成连贯的响应、理解不同对话主题等,并且在GitHub上始终以开源项目的形式持续发布该底层库的一些内容。
就这样不温不火地发展了一段时间后,2018年底,Hugging Face迎来了一个重要的转折。
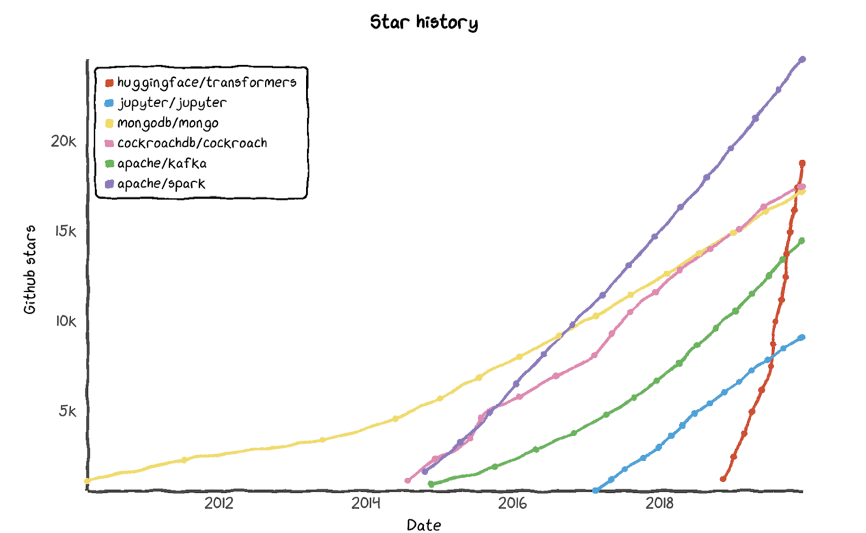
当年11月,谷歌宣布推出基于双向 Transformer 的大规模预训练语言模型BERT,瞬间成为了自然语言理解领域最受开发者关注的模型。但一开始,Google只发布了BERT的TensorFlow版本,Hugging Face就想为啥没有Pytorch版本呢?于是Hugging Face创始人之一的Thomas Wolf就用几天的时间完成并开源了PyTorch-BERT,但没想到,就是这么一个“无心插柳”的项目让Hugging Face一炮而红。
借着BERT的东风,Hugging Face的Pytorch-pretrained-BERT发布3个多月后,快速达成了在Github上5000+ 星标的成就,到了7月份其Star数量已经超过了1万,发展速度远超其他同类开源项目,在Github的AI项目领域里一飞冲天。
在这样的发展势头下,Hugging Face的产品战略开始发生了调整。他们将更多精力放到了开源模型的建设上,将 Pytorch-pretrained-BERT项目正式命名为Transformers,同时支持Pytorch和Tensorflow 2.0。
借助 Transformers库,开发者可以快速使用BERT、GPT、XLNet、T5 、DistilBERT等NLP大模型,并使用这些模型来完成文本分类、文本总结、文本生成、信息抽取、自动QA等任务,节省大量时间和计算资源,此后Hugging Face在人工智能开源领域的名气也越来越大。
到了2019年12月,Hugging Face拿到了由Lux Capital 领投的A轮融资,融资额也比上一轮上了一个量级达到了1500万美元。值得注意的是,从这一轮开始,Hugging Face的标签不再是聊天机器人,而是把AI开源业务放在了首位。这张可爱的笑脸emoji也开始被广大人工智能开发者们所熟知。
朝着人工智能界的Github前进
在2019年底All in AI开源之后,Hugging Face开始着手构建一套完整的开源产品矩阵。用Hugging Face自己的话来讲,他们所做的事情,就是要架起人工智能科研和应用的桥梁(bridges the gap from research to production)。
过去这些年,人工智能领域的科研和商业应用是相对独立的两个板块,科研部门的任务就是对前沿技术进行研究,搞模型、发论文,应用部门的人则是要将最新技术用到产品中探索商业变现。如何将科研成果进行系统性的整合成为开源产品,让开发者们能够很快上手去应用转化是长期困扰业界的一个问题。
Hugging Face之前歪打正着地摸到了这个痛点,接着开始认真向下挖掘。简单来说,Hugging Face就是承担了人工智能科研走向应用这个过程中几乎所有复杂、繁琐、细碎的工作,然后方便任何人工智能从业者都可以去便捷地使用这些研究模型和资源。
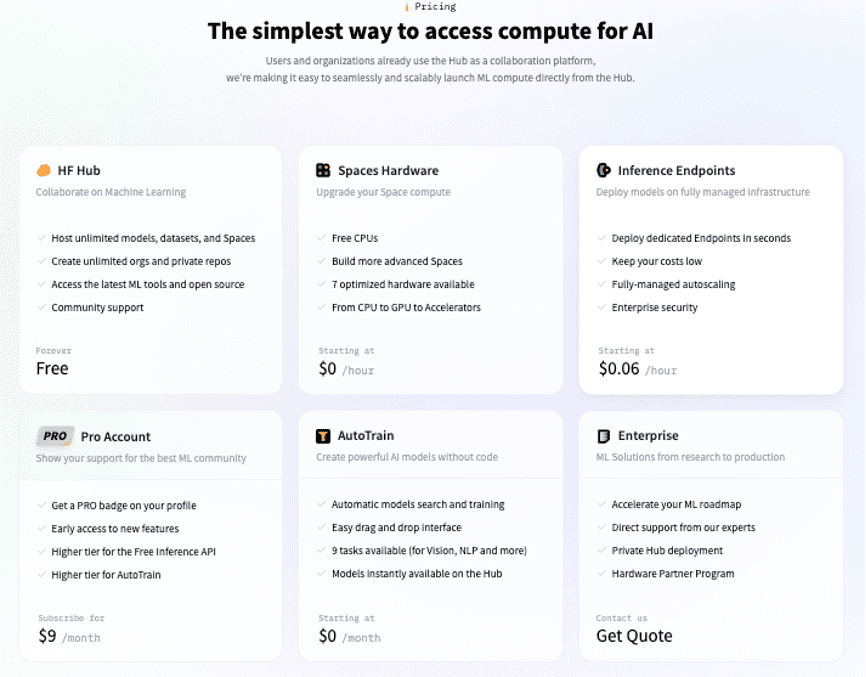
目前,除了头号产品Transformers之外,Hugging Face还建立了Tokenizers、Datasets、Accelerate等库,从模型到数据集、从托管平台到性能优化,以开源社区为载体,Hugging Face已建立起了完整的人工智能开发生态,涵盖了 NLP、计算机视觉、语音、时间序列、生物学、强化学习等各个领域。
值得注意的是,Hugging Face并不是因为ChatGPT带火的。2022年5月,当市场的注意力都还停留在Web3、元宇宙之上时,Hugging Face拿到了有红杉、Lux Capital参与的1亿美元融资,让其估值一举突破了20亿美元。
Hugging Face当前的目标是想成为人工智能领域的Github。其创始团队认为,只有将那些少数人掌握的技术推广给更多人使用,才能真正最大程度地推进整个行业的进步。而从商业的角度来说,Hugging Face认为赋能整个AI社区所可能产生的价值可能比一个专有的工具高出千倍,而只要将其中的1%变现就能够足以撑起一个高市值的公司,类似的例子包括MongoDB、Elastic等等。
除了蓬勃发展的开源社区,从2020年开始,Hugging Face也开始做面向企业的定制自然语言模型,其客户涵盖彭博社、高通、英特尔等各类大中小型公司,并推出了包括AutoTrain、Inference API & Infinity、Private Hub、Expert Support等针对不同开发者类型的产品。据报道显示,从2021年开始Hugging Face就一直处于正现金流的状态。
Hugging Face在当前的人工智能领域中能够以开源社区的模式异军突起,有一些偶然也有必然。首先,过去这些年,人工智能技术所取得的进步都是由全世界的科研和产业领域共同协作所推动的,它的技术基因里其实就带着开放,因此建立起一个平台来链接研究者和开发者顺应了行业发展的历史和趋势。
此外,Hugging Face通过完成大量的基础性工作,来帮助弥补在人工智能领域里长期存在的科学与生产之间的鸿沟,这是过去很多开源平台没有关注和做到的。
在此前的一个采访中Hugging Face的CEO Clément Delangue表示,机器学习技术仍然还处于早期发展阶段,开源社区的能力将是巨大的。他认为,在未来5到10年,我们一定还会看到更多开源机器学习公司的崛起。
本文来自微信公众号:硅星人 (ID:guixingren123),作者:Juny