
本文来自微信公众号:峰瑞资本(ID:freesvc),对谈:马睿(关注材料和生物科技方向)、陈石(专注科技、软件、互联网、消费等领域),原文标题:《一场争论:两位不同方向的投资人如何看GPT | 峰瑞研究所》,题图来自:视觉中国
最近AIGC经历了翻天覆地的变化。
OpenAI发布大规模语言模型GPT-4,新增多模态处理能力,支持输出文本和图像。技术狂飙的另一面,则是OpenAI在个人数据隐私、内容准确性、未成年人保护等方面受到质疑。3月底,意大利宣布禁用ChatGPT。德国、法国、爱尔兰等国也考虑了暂时禁用ChatGPT的可能性。4月11日,中国国家网信办发布《生成式人工智能服务管理办法(征求意见稿)》。
AI带来的冲击同样蔓延在生物学科的实验室内,科学家们已经开始使用AI来建立蛋白质模型,通过分析和预测基于文本、蛋白、测序等数据,以加速自己的研究。生成式AI为生物医药研究带来了新的思路和视角,并由此产生了“生成式生物学”的新理念。
我们邀请两位不同领域的投资人,畅谈了他们眼里的AIGC。对谈中有不少观点的碰撞:GPT与Biotech(生物科技)究竟会交叉碰撞出什么火花?AlphaFold 2和ChatGPT谁会在生物领域引起更大的变化?在大变化中,AI for scienc、生成式生物学、AI制药等领域,哪些会有更多机会?我们将他们的分享编辑成文。

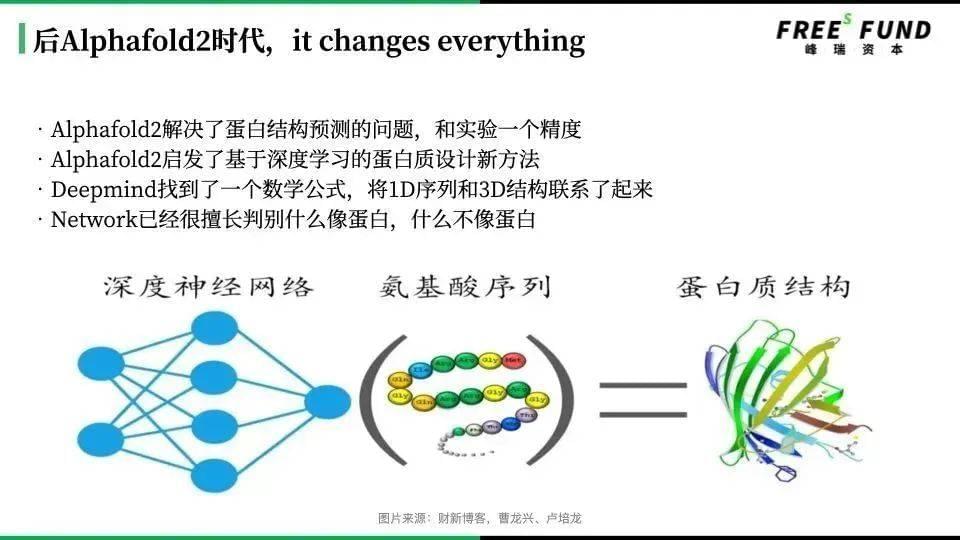
AlphaFold 2:Google旗下DeepMind开发的一款蛋白质结构预测程式。此前,生物学家破译蛋白质的三维结构,常常需花费数年时间。
从那时候开始,这两三年我关注AI的新进展,例如Transformer被用在结构预测领域的进展。后来我发现,结构预测的逆问题,即蛋白设计也会被AI的进展所影响,相关的研究范式不断变化。
从基于物理的能量计算,再到利用Transformer和扩散模型等最新的AI工具,AI技术和生物科技这两个事情相遇得越来越快了,结合得愈发紧密,所以我就越来越关注GPT和AI领域的进展。
陈石:那在AI技术之前,传统的生物科技是怎么获取数据的?
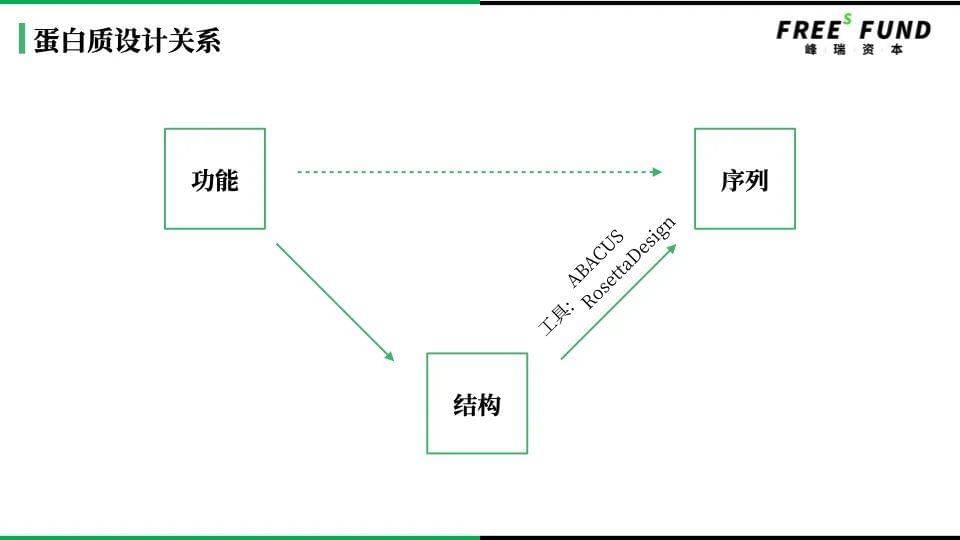
马睿:比如我们之前提到DNA、RNA、蛋白,我们关心它的序列、结构和功能。不管是DNA层面还是RNA层面,通过测序仪——比如illumina或者中国的华大智造——对基因进行测序,基因到底是怎样按照ATCG或TACG的顺序连接起来的?这样就会测到它的序列数据。
但得到序列之后,你并不知道它是以什么样的结构存在。结构非常重要,它影响着生物分子的功能。也就是说,测序只是解决了它身份证号码的问题,你知道它是谁,但结构是它长得高矮胖瘦、它是什么形状的问题。
功能就更复杂了。“功能”是一个非常笼统的词,某个生物大分子可以和小分子结合,产生一些效应;某个蛋白可以催化化学反应,这都是它的功能,功能数据是非常稀少的。
为什么生物科技一直进展比较慢,是因为生物系统太过复杂了,它是一个非常随机、高维和非线性的过程。没有好的模型和方程能够解释生物系统,即便有也会是非常高维的方程。
现在我们解决这些问题的方式还是偏试错性的,人工一个个地去做试验和试错,而不是根据规则的设计。因此我们常常说“我们可以设计桥梁,然而我们只能发现药物”。
通过计算研究后大家发现,其实AI是最善于解决这种高维的数学方程,AI能够在隐式空间(在隐式空间中,相似样本之间特征差别作为多余信息被移除了,只有其核心特征被保留)里对它降维,如果能够用计算去解决预测或设计的问题,就会对生物医疗有非常多帮助。而由于生物系统被数据化得最好,并且这个过程还在加速,生物大概率是AI for science里最有希望的领域。
利用GPT这种生成式的生物学,我们就能够非常好地解决这些生物医疗的问题。如果我们展开想象,未来如果你想做新冠疫苗,你可以跟AI说,我想针对某个特定的抗原表位,生成结合的抗体,然后AI就能帮你找到解决方案。
AlphaFold 2 VS GPT:区别在哪?谁更有效率?
陈石:Google收购的DeepMind做出来了AlphaFold 2,微软投资的OpenAI推出了GPT系列模型,围绕GPT和生成式AI也产生了很多做法和模型。从你的角度来说,AlphaFold 2和GPT这两者区别在哪,谁更有效率,效果更好?
马睿:让我来说,这两个事情的区别在于,AlphaFold 2还是偏向专有领域,它的进展非常厉害,能够解决一个具体的问题,而且解决得非常彻底,利用计算实现了和做实验一样的精度。
但GPT用在生物领域更像是一个思路,它给我们提供了非常多好的模型、算法,让我们换一个思路去看生物的数据。
我当然觉得AlphaFold 2是厉害的,但我也觉得GPT可能会带来更大的想象力。它们之间的区别主要在于,AlphaFold 2是已经做成专业领域的模型,GPT则让我们有了新的看待数据的方式,催生出 “生成式生物学”这么一个新的理念。
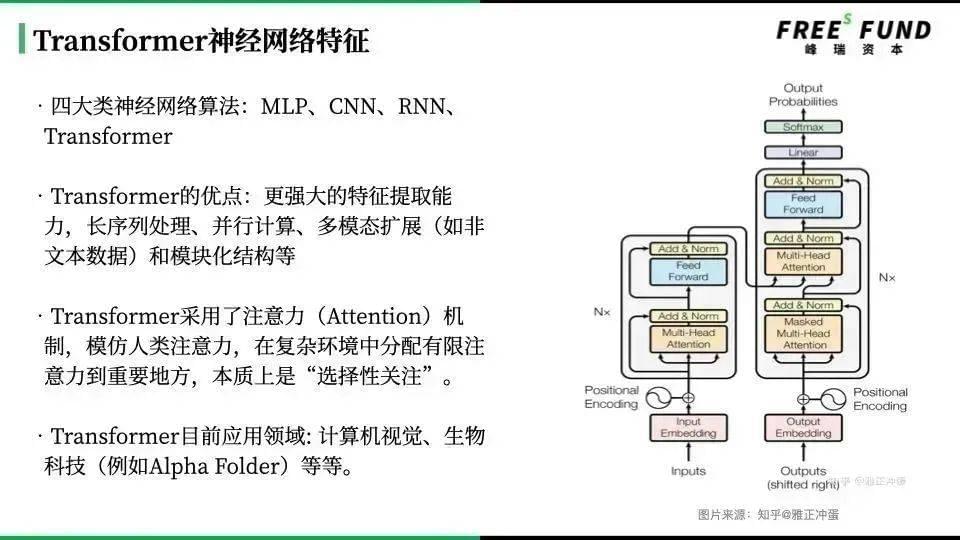
现在回过头来看,AlphaFold 2其实做了两件事,一个是采用了Transformer提取器。在结构预测领域,有些科研人员就把AI 里面的新技术学过来了。
第二,生物科技领域以往最多的数据是在序列测序上,AlphaFold2利用多序列比对(MSA),把蛋白质的结构和生物信息整合到了深度学习算法中。
多序列比对:把两个以上字符序列对齐,逐列比较其字符的异同,使得每一列的字符尽可能一致,以发现其共同的结构特征的方法称为多序列比对。
在生物学领域,多序列比对是开展进化生物学研究的前提。通过研究序列比对中同源序列是如何随时间变化的,可以推断序列的结构和功能是如何进化的。
相比较AlphaFold 2,在生物领域,为什么GPT可能会带来革命性的影响?一句话就是,GPT利用AI学习了进化过程中的生物数据,AI提取了规则之后,可以生成出符合底层生物逻辑,但是不在进化历史里的全新分子。
比如原来我们找不到某个分子,如果把GPT和生物结合在一起,你就有可能找到这个分子,而且更有效率。原来要花一年时间,现在可能几秒钟就能找到。你可以把GPT和生物的结合理解成范式的转移,未来整个生物科技可能会挪到生成式生物的模式上。
现在大家都很兴奋,想着能把GPT用在哪儿。首先是用NLP挖掘现在的知识,然后做蛋白结构预测和蛋白设计,RNA序列的挖掘,以及酶的设计。然后是能不能做药,解决蛋白和蛋白相互结合、蛋白和RNA相互结合、蛋白和多肽相互结合的问题,最后解决蛋白和小分子相互结合的问题。
再往后,大家会考虑能不能预测临床实验的成功率,改一下临床实验的设置,使成功率更高一些。
这都是未来的方向,它们可能是顺序的概念,也可能同时发生,因为现在所有做生物学的研究组都高度关注GPT的进展,都在琢磨怎么能够把GPT用上,像你说的“又要懂技术,又要强场景”,在场景里把它落下来。
陈石:AlphaFold 2除了分析序列之外,还引入了标注过的数据集。从这个角度来说,它有点像“监督学习”。好处是它很准,理论上讲它会出错,但它的错误不是开放式的错误,拟合好不好是可以看出来的。
但是ChatGPT是开放式的,但它的好处是,就算不精准,它有很多的开创性的奇思妙想。你也提到了,人类科学家会从中有一些收获,使他能够产生一些创意,这也是它的价值。这就是精准和创意取舍的问题。
马睿:基于你刚才说的这些,其实可以下一个结论,就是AlphaFold 2肯定会在生成式生物学里占有重要的一席之地,Google也没有完全输掉。AlphaFold 2现在就为生成式AI提供了一个非常准的判别或计算的工具,你可以调用这个工具来做一些生成式的事情。
在生成式生物学里,你学了很多数据,掌握了它的底层规则,依据这些规则生成了很多生物分子,这些生物分子有些是你想要的,有些不是。但是生物领域里的容错率还是会比聊天场景要高很多,我设计5000个蛋白,其中只要有1个我想要的,我还是会满意。
随着越来越多的生成,越来越多地学习数据,未来生成式生物可能也会出现数据量井喷。模型越来越大,同时还需要调用一些非常准的工具帮助它去做约束。我觉得这两件事情对我的价值观都产生了影响,我对AI本身会变得更乐观一些。这种迭代会给上层的应用带来非常大的影响,而且是正面的影响。
如何让GPT发挥长板优势?又如何提高GPT的准确性?
陈石:ChatGPT或后面的模型,“学”出来的东西是参数矩阵,呈现给人们的内容很复杂,但大家不知道它里头是什么东西。有时候ChatGPT,起码3.5版本是会出现所谓的一本正经地“胡说八道”,但生物科技要的是非常精确的结果,你怎么看待这种不可解释但又容易出错的GPT?
马睿:我觉得ChatGPT有可能产生了很多深邃的思想,但可能在训练的时候,人们把这些天马行空的思想做了不适用于人类想法的标记,没有被选出来。所以有可能它已经产生了一些不可解释或更智能的思想,但咱们暂时没有看到。
在生物科技上,我们用ChatGPT或GPT的方式肯定不能依赖于它的一个回复,更多应该关注它给我们提供的新线索、新思路。
话说回来,怎么能够提高GPT的准确性呢?
一是要有“domain knowledge”,涉及学科的专有知识。第二个是在学科里要有好的数据,像AlphaFold 2并没有用生成式的模型,但就是因为用了好的数据,就能够做到非常准确。

近几十年来,AlphaFold 2让计算第一次达到和实验一样的精度。AlphaFold 2在结构预测上,已经基本通过计算把单域蛋白的结构预测解决了。生物科技里有一些场景,一旦给它对的数据,你知道怎么去组织这些数据,你又用了最新的AI方法,它就能给你很准确的信息。
陈石:业界也有一种说法:人类要发展出一个能力,就是要学会判断ChatGPT给你的答案的正确概率或可靠性。就像很多网络论坛上的内容不一定准确,但能带来启发。如果你只想追求绝对准确,可能会忽略别人给你激发的灵感或另外角度的思考。我觉得还是应该接受现状,接受有可能不准确的东西。
我最近也在思考,我们人类的语言或编程语言可不可以为GPT做一些优化?我们知道,有时候ChatGPT生成大段的代码是有压力的,我觉得这也是在面临一个变革。
例如,作为IT基础设施的一部分,我们的编程语言、程序结构能不能为了ChatGPT做优化,让它能够更精准地输出合格的程序。毕竟当前流行的编程语言,大部分是上世纪90年代或之前的产物。如今我们可能需要让编程语言更适配GPT模型。
马睿:我觉得你说得特别好。不一定是不正确的输入对你的知识形成就没有帮助,人类其实是更大的GPT模型。我们是拥有智能的,只要你给我输入数据点和知识,我就能从里面学习到新的知识和规则。
这也是生成式和判别式AI的区别。判别式AI不需要知道所有的点,但它需要得到准确的数据,帮助你画出那条线。但对于生成式AI而言,它需要知道尽可能多的点,帮助你发现这些点的分布规律。
当然,一个新技术如果要用到严肃的医疗场景,肯定是需要经过全过程的研发和监管,要走完所有规定的流程,才能够真正地面对消费者或患者。所以除了内容上的不确定性,对我们来说,最重要的还是想一想,ChatGPT这样一个技术大突破可能会对生物学有哪些影响。
生成式生物学的可能性:大模型和传统计算工具如何结合?
陈石:文本和图像的多模态对齐在GPT里已经部分实现了,不知道在生物科技上有没有这样的案例?
马睿:有的。比如在蛋白设计上,结合结构工具和扩散模型,比如AlphaFold 2或者RoseTTAFold,可以把多轨道或多模态的信息放进来。
RoseTTAFold:是一个三轨(three-track)神经网络,可以兼顾蛋白质序列的模式、氨基酸如何相互作用以及蛋白质可能的三维结构。
比如对一个蛋白结构或功能很重要的序列,它的两两残基之间接触距离的图,它的结构的三维坐标,模型可以把多模态的数据都输入进来,同时在扩散的时候进行迭代。
这样就能够找到序列和结构之间隐藏的联系,比人更高维地学习到这之间的参数。所以AI的模型会收敛得特别快,在蛋白设计的效率上会比不用扩散的模型快非常多。
以前AI用10个小时才算出来一个蛋白,现在几毫秒就能算出来。在蛋白质设计领域,我们已经看到了多模态结合所取得的进展。期待未来在其他生物医药的子领域,也能够看到AI带来研发速度或者准确率的提升。
陈石:你提到一个很有意思的话题:现在业界探讨怎么把传统计算和语言模型结合的问题。人们有时候问ChatGPT三位数的加法时,它容易出错,所以有一种说法:是不是可以借助传统的计算工具,比如调用Python的代码,一句话就把三位数的加法、乘法直接算出来。
这样ChatGPT就可以发挥它的专长,通过外部调起的方式去解决一些不擅长的任务(注:3月24日OpenAI宣布ChatGPT支持第三方插件)。不知道在生物科技里,这两者未来有没有结合的可能性?
马睿:我的理解是这样,大模型解决了核心智能的问题,在聊天这个场景里表现得很好,但你实际上要调用很多周边工具。未来的趋势肯定是工程化的,原来能够准确计算或准确执行任务的模块,会被接到核心的智能框架里。
对生物科技来说,它就像一个大模型的垂直领域。生物里的数据量足够多,所以也有人直接用语言模型在生物领域做了很多事情。比如说Meta(原Facebook),它从 2. 8 亿个蛋白质序列中,训练了860亿个氨基酸的语境语言模型。
我的感觉是,未来生物科技里几个方向都会有,大家会探索能不能把现有的序列、结构、功能数据做单个的语言模型,多模态能不能融合在一块做一个大模型。第二个方向是沿着原来专业的那条线,把生成式AI或扩散模型里最新的方法用过来,糅合GPT这些新的思想和模型。
我觉得,在生物领域不会出现特别大的Foundation Model,但大概率会借助AI的新算法,有自己的大模型和专业模型。
陈石:我的理解是,最后生物领域有可能有一个多模态输入的大型Foundation Model。这个专业模型可能先是在文本上对齐,多模态识别做得更好后,也会在别的地方对齐,成为一个相对完整的生物领域的基础模型。
马睿:同意,GPT和Biotech交叉,我觉得主要有三个大的方向。第一个溢出的肯定是NLP这些大模型,现在已经有一些像BioGPT这样的生物大语言模型,这是最直观的,大家第一步能想到的。
BioGPT:基于生物医学研究文献的大型语言模型,可用于生命科学文献文本生成和挖掘,由微软研究院发布。
第二个是沿着中心法则,对生物分子砌块做设计和计算。
生物的中心法则就是从DNA转录成RNA,再翻译成蛋白质,生物科技最有用的数据就是沿着DNA-RNA-蛋白质,看它的序列结构和功能。
序列这个词,不仅在生物领域,在计算机领域也是个通用词。生物计算机代码的底层逻辑很相近。在DNA层面,ATGC这四种脱氧核糖核苷酸的排列组合和写程序代码的思路类似;在蛋白层面,每个序列的位置是20个氨基酸的选择,也和代码非常像。所以生物科技研究第一步,肯定是要把序列研究清楚。
生物科技里面,不同模态之间的差距还蛮大的,比如你采集了一个人的血压数据、脑电数据、心率的数据以及其他生化的数据,但你不知道怎么把这些不同维度的数据对齐在一起,放在一个模型里。我们之前一直在提大数据,但是我们缺乏一种真正工程化的手段,或者说对齐的思路。
从DNA到RNA再到蛋白,预测和设计它的序列、结构和功能。这里有些问题已经被解决了,蛋白设计也在非常快地迭代,基本上以月为单位就会有新的方法出来。
最后涉及到功能的时候,你还要解决生物分子相互作用的计算,比如某个蛋白和另外一个蛋白是怎么结合的、结合强度有多高。
蛋白设计需要同时考虑主链和侧链的柔性,现在被扩散模型赋能之后,在未来的两年内可能也会发生非常大的突破。突破发生之后,未来蛋白或大分子的药物设计,甚至大分子的AI制药领域可能会被完全颠覆。所以我觉得GPT在生物科技领域还有非常多值得我们关注和思考的方向。
GPT赋能生物科技,会让强者更强,还是给创业公司更多机会?
陈石:GPT会对现在生物科技领域的商业模式和产业格局带来什么样的影响?有了GPT后,大公司和创业公司的竞争格局会发生什么样的变化,是巨头会更强,初创公司没机会了?还是因为有了GPT,小公司也可能拿到一堆数据,反而能打败巨头?
马睿:生物领域里有非常多波次的技术革命,所以大概率是能预期GPT带来的影响。新的技术通常会由小的BioTech公司引领,然后扩散到整个行业。一旦蛋白设计的相互作用问题能够被解决,最直观的就是能够完全设计蛋白的药物了。
可能一开始是前沿的生物技术企业才能够做GPT和Bio结合的事情,现在全世界能做这样技术的公司或科学家也并不多,往后新技术可能会变成一个更主流的基础设施,辐射到整个行业。
小公司先引领,改变整个行业的格局,大的药企也会跟进。大药企的长处在于做临床、做后面的商业化,小公司强在技术和从0到1的发现,最后二者会整合到一个价值链里,技术上的颠覆会大于商业上的颠覆。
陈石:对于生物制药行业而言,我觉得可能不会做大的语言模型,但会做一些没那么大的基于序列的Foundation Model。你觉得是生物科技公司,还是大药厂会更容易、更有效率地做这个事情?
马睿:好像二者都有。现在蛋白的大语言模型有Facebook做的,有Salesforce做的,有生物科技公司做的。
因为是大模型,基本上要用几亿条序列,这都是公开的数据库,大家各显神通,利用它们对AI技术的理解来做这些模型。我不觉得大公司和小公司未来会有非常大的差别,主要还是看谁能够调用数据,以及它对AI模型的理解。
陈石:可能还是数据不够大,如果大到语言模型程度的时候,很多人就玩不起了,但是生物科技领域,无论模型的参数量还是数据体量都还不够大,所以创业公司也是可以做的。
马睿:对。我们可以对比一下文本、生物和AI for science(除生物领域外,比如材料)这三类的数据体量。文本数据体量是最大的,而生物数据的体量正好在文本和材料之间。所以我没那么看好AI for science除了生物的领域,觉得生物才是最有可能被数据引爆。
在文本领域,创业的机会没有很多。要是没有资金的能力和大模型构建的算力,你很难去创业。但生物领域可能是未来创业的聚焦点,它没有那么大的数据集,但又比材料、物理、化学的数据集要大,所以可能会有一些机会。
很多人想做AI for science,比如做材料的设计或计算。但材料的问题就在于,你还真得通过实验测来数据。生物是按照底层的测序数据逐步往上叠加的,只要测序打通了,这就会带来比较大的变化。
陈石:这很有意思,生物科技的创业者可以做一些垂类的语言模型或类似于基础模型的东西。现在看起来基础模型、语言模型是在外头,但进入到一个细分领域,可能需要垂类的基础模型。
马睿:我觉得生物是有可能做垂类语言模型的领域,但是很多科学领域,不如生物有这么好的条件。
生物里更有意思的是,怎么只通过DNA序列就去编码复杂的生物过程,因为它也是按照层级复杂度递进的。DNA变成RNA,RNA是个高度动态的过程,它执行很多功能,RNA又变成蛋白。
蛋白是我们能看得见的离我们最近的单元,它既是靶标,又是执行器,也是信息传递或传感器。如果把DNA层面的模型和蛋白层面的数据结合在一块,能不能迁移学习到RNA领域?
现在很多靶向RNA小分子药的市场也非常大。在生物学领域, RNA是非常重要的分子,但是我们测量不了它。很多人想,能不能把DNA测序、蛋白的结构、功能序列的数据喂到大模型里去,迁移学习出来一些RNA的相关知识和其他信息。所以在生物领域,Foundation Model确实可能会带来比较多的创业机会。
本文来自微信公众号:峰瑞资本(ID:freesvc),对谈:马睿(峰瑞资本合伙人,关注材料和生物科技方向)、陈石(峰瑞资本投资合伙人,专注科技、软件、互联网、消费等领域)