
本文来自微信公众号:硅星人 (ID:guixingren123),作者:油醋,编辑:VickyXiao,原文标题:《搜索大变天!谷歌推出Bard对抗ChatGPT,打响保卫战》,题图来自:视觉中国(2004年,年轻的拉里·佩奇和谢尔盖·布林)
面对ChatGPT的来势汹汹,谷歌彻底慌了。
OpenAI发布ChatGPT也不过是4个月之前。但是在这4个月里,已经有不少预言,称ChatGPT带来的变革,将会颠覆谷歌的现有搜索产品和商业模式。
于是,谷歌CEO桑达尔·皮柴(Sundar Pichai)开启“战备”状态:先是在ChatGPT问世两周内就拉起了“红色警报”,然后创始人拉里·佩奇和谢尔盖·布林时隔3年再度被紧急唤回。
今天(北京时间,如无说明下同)皮柴更是在官网上称,谷歌一直在研发一款名为Bard的实验性对话AI服务,今天起,谷歌将把它对信任的开发者开放,然后将在接下来的几周内,把它向更广泛的受众开放。
谷歌终于加入了这场智能聊天机器人对搜索引擎发动的大战。
谷歌宣战
谷歌的第23号员工,Gmail的缔造者保罗·布赫海特在2月1号发推悲观表示,谷歌将会在一两年内被彻底颠覆——当人们的搜索需求能够被封装好的、语义清晰的答案满足,搜索广告将会没有生存余地。而占据全球接近84%搜索市场的谷歌,到现在仍然是一家50%营收直接来自搜索广告的公司。
眼看ChatGPT引起的战火烧到了自家主场,谷歌终于反应过来,在今天宣布推出类ChatGPT产品——一款实验性的对话AI服务Bard。
皮柴在今天发出的博文里称,谷歌一直希望通过大语言模型,把这些深度研究和突破变成产品来帮助人们。两年前,谷歌推出了大语言模型LaMDA,此后,谷歌就在LaMDA的基础上,开发出了Bard。
今天,谷歌将先对信任的开发者开放这项服务,然后将在接下来的几周内,把它向更广泛的受众开放。
谷歌强调,巴德会把世界上的信息知识和谷歌的大语言模型所带来的能力和智能相结合,它会获取网络上的信息,来提供新鲜的、高质量的回复。这意味着和ChatGPT受限于2021年以前的数据不同,巴德会是基于实时网络数据的,谷歌将把它与LaMDA的轻量级模型版本一起发布。
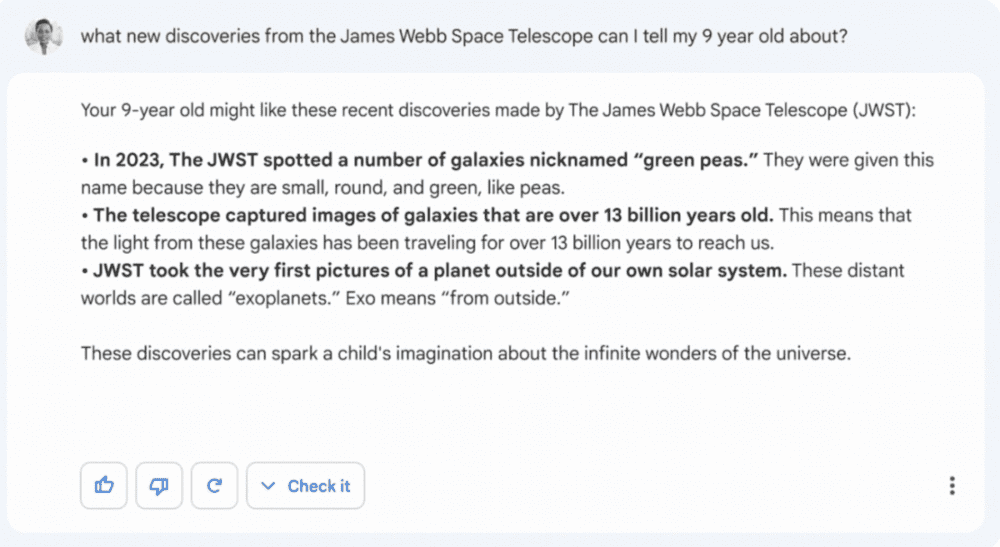
从博文里的图片来看,Bard也是和ChatGPT类似的聊天框形态,能做的事除了简化复杂的主题,比如”向9岁的孩子解释NASA的韦伯望远镜带来的新发现“,还能帮助人们做一些复杂的任务,包括”计划朋友的新生儿派对“、”比较两部奥斯卡提名的电影“和”根据冰箱里的食物给出一些午餐点子”等。
在谷歌看来,这个小得多的模型需要更少的算力,从而可以扩展到更多的用户,获得更多的反馈。他们会将外部反馈与自己的内部测试相结合,以确保 Bard 的回答在质量、安全性和真实信息的基础性方面达到高标准。谷歌希望通过这一阶段的测试,来提高 Bard 的质量和速度。
皮柴还在博文里称,很快,谷歌还将很快在搜索中整合基于AI的功能。除了像ChatGPT一样会将复杂的信息和多个视角提炼成易于理解的回答,谷歌还将进一步提供更多网页信息的选择。
不过,根据硅星人获得的消息,Bard大部分由华人团队开发,而且这次Bard的发布有点赶,在内部算不上完全准备好,所以才在现在以面向有限开发者的形式推出,而非像ChatGPT一样,一开始便开放给大众使用。
同时,谷歌内部对ChatGPT感到恐惧的另外一层原因,是人才的流失。和很多公司一样,谷歌内部也采用赛马制,有好几个做类似模型的团队,但内部其它大语言模型团队向OpenAI流失人才的情况比较严重。
当然,不管内里如何焦虑,皮柴至少在博文里信心满满地宣布,下个月,谷歌将开始让个人开发者、创作者和企业尝试自家的生成语言 API (Generative Language API),该 API 最初会由 LaMDA 提供支持,并有一系列模型可供选择。“随着时间的推移,我们打算创建一套工具和 API,让其他人可以轻松地使用 AI 构建更具创新性的应用程序。”
与此同时,ChatGPT开发者OpenAI背后的金主微软,也在紧锣密鼓地想要把ChatGPT整合进自己产品中。
微软正在与OpenAI洽谈一笔100亿美元的投资,并在年初传出计划将ChatGPT添加到自己的搜索引擎Bing中,搜索结果将首次显示为带有信息来源的完整句子,这个新的版本会在3月左右发布。
而就在皮柴的博文发出不久,微软就宣布,将在2月7日(当地时间)召开一场发布会,主要就是关于微软和OpenAI的合作,以及ChatGPT和微软Bing搜索的整合。
与此前的危机都不同的是,这是谷歌的搜索根基在20多年后第一次受到挑战。几年以后“Google it.”会不会让位给“ChatGPT it.”?这是让人兴奋的地方。Bing和百度们想追上谷歌,谷歌不想变成雅虎。
谷歌的搜索霸权会在今年被动摇吗?
停滞的搜索
让我们的目光先回到谷歌诞生之初。
拉里·佩奇和谢尔盖·布林在千禧年前夕嗅到了互联网繁荣在即与信息检索陈旧逻辑之间的间隙,贯穿谷歌生命的算法Page Rank由此诞生。
20世纪90年代,互联网仅仅是一个为全球2%的人受用的先锋概念。网络资源匮乏,雅虎甚至以手工录入的方式就足够建立起最初的互联网搜索概念。1995年Alta Vista出现,互联网历史上有了第一个全网页内容的索引工具,后者第一次设计出爬虫技术(web crawl),并在1995年8月完整完成了第一次网络爬取。
但以Alta Vista为首的搜索工具对搜索关键词与索引结果之间的关联分析仍然十分薄弱,这很大程度源于搜索工具最初的受用人群。在互联网普及之前,信息搜索只是服务于文献查找的工具,其框架长久建立在学术圈以关键词加权平均为信息搜索基础的逻辑上。
极度理性且表达精确的学术内容搜索逻辑并不适用于互联网的信息抓取。反映在Alta Vista上,就是它能搜索到大量信息,但准确性却非常低。
只有拉里·佩奇注意到了互联网信息之间关联性的利用潜力。
他将互联网想象成一个多节点的矩阵,每一个网页都是“点”,网页之间的超链接关系则是“边”。指向一个网页的超链接越多,则这个网页被判断为越重要,这个过程中每个网页都可以找到统一标尺下的重要性参数。

这是日后知识图谱技术甚至图计算的最初想象,也是算法作为一种思维第一次进入搜索领域。
受制于互联网的发展阶段,雅虎和Alta Vista是不可能产生算法思维的,而Page Rank对Alta Vista的取代则成为“搜索”历史上最闪耀的时刻。
但至今关于“搜索”的所有变革,也在24年前Page Rank诞生那一刻就宣告结束了。
无论是2001年出现的百度,2009年出现的Bing(当然也包括使用Bing核心搜索技术的雅虎),都再也没有逃出以Page Rank所建立起的逻辑框架,即把用户的开放性问题转换成互联网信息图谱上具有关联性优先级的、一个更具体的选项扩列,再还给用户去甄别。
2021年新兴的搜索引擎You.com,最大的卖点仅仅是集成式的把推特等其他平台的搜索结果分门类地纳入到了信息搜索结果中,并且赋予用户对于信息来源平台一定的权重设计能力。
在搜索的发展停滞中,这样一个“谷歌的挑战者”就足够获得2000万美元的种子轮融资。
中文互联网世界里没有另一个综合搜索引擎获得长期繁荣,反倒是在移动互联网信息孤岛的压迫下,微信和字节跳动提供的更垂直的搜索服务开始占领百度的内容盲区。
类似You.com的搜索引擎短期内仍然不会在国内出现,这是百度遗憾的地方。而无论抖音搜索或是微信搜一搜,也都没有从搜索技术效率上取代百度的野心。一个自有生态内的内容连接器角色已是这类垂直搜索服务的上限,这本质上是新的互联网巨头们适应各自商业逻辑所做的模式创新,而非技术创新。
所以抖音搜索们对抖音重要,对“搜索”却不重要。
2002年加入谷歌并主导设计了后者日中韩文搜索算法的吴军在2012年出版的《浪潮之巅》中这样描述Page Rank:
“虽然今天Google和其他搜索引擎相比当初的Google已有了长足的进步,但是这种进步基本上属于量变。搜索引擎领域迄今为止的质变只有Page Rank取代Alta Vista那一次。”
这个判断到现在仍不过时,直到ChatGPT带着生成式搜索的面目出现。
未必颠覆一切
ChatGPT可以写代码、需求文档甚至初步实现所有办公软件的AI化,但大部分人用不着这些——就像大部分搜索引擎的用户只是简单的提问,然后要一个答案。
于是撇开这些,ChatGPT与谷歌(或者百度)相比最大的优势,是它可以——几乎是毕其功于一役的——生成一个极高质量的首条信息结果。
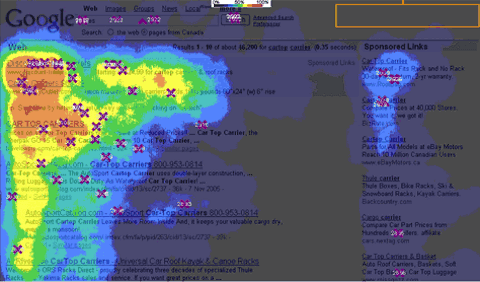
康乃尔大学的研究人员曾经通过眼部追踪实验获得了精确的谷歌搜索结果的用户行为分析。分析结果显示,首条结果获得了 56.38% 的搜索流量,第二条和第三条结果的排名依次降低,但远低于排名第一的结果。
这十分考验ChatGPT生成内容的准确性,而这个大型语言模型背后是一个信息来源与即时性的黑盒。
由于ChatGPT的回答中并不展示信息来源,用户目前无法从回答中分辨信息真伪。
在即时性上,ChatGPT无论是以频繁增加标注数据并一次次重新对模型进行预训练的方式,还是用Fine-Ture的思路来修改现成的训练结果,都会遇到新的问题。前者是极大的算力成本,后者是新知识对原有知识的过度覆盖隐患。
ChatGPT是搜索领域苦等的一次效率革命,被认为是一种“导弹”对“弓箭”的降维打击。但如果说Page Rank是算法逻辑第一次进入搜索领域,ChatGPT也并没有背离这个技术原点。
ChatGPT的成功基于一场以1万个英伟达V100 GPU支撑、用深度学习和人工智能对人类信息历史反复咀嚼的苦功。从这个角度上看,它仍然是渐进式的,并非一个完全的颠覆者。
而哪怕谷歌本身,也并不意外ChatGPT在技术层面所实现的东西:
去年开发者大会 I/O 上,谷歌展示了大语言模型LaMDA如何以冥王星作为对话主体来与人进行交流,这种回答是即时生成的,并不是学习了大量预定义的结果。大语言模型LaMDA和多模态多任务模型MUM所表现出来的素质,意味着谷歌已经具备与ChatGPT相近的AI能力。
而让皮柴感到紧张的是,ChatGPT在上线五天就成功吸引了超过100万的用户,这个数字在两个月后涨到1亿。
OpenAI做了第一个吃螃蟹的人,而大众接受了它。
而一家市值超过1.4万亿美元的大公司注定比小型创业公司更保守。
谷歌人工智能负责人杰夫·迪恩在几个月前对员工表示,倘若通过(ChatGPT)这样的服务提供错误信息,会给谷歌带来更大的“声誉风险”。
谷歌的一位高级工程师曾在去年公开表示大语言模型LaMDA“有意识,有灵魂”,随即被勒令停职。他在被停职的前一天把一些包含谷歌及其技术涉嫌宗教歧视的证据交到了一名美国参议员的办公室。
种种困扰,让谷歌即使有了大语言模型LaMDA,也无法轻易抛出一个可能会乱说话,又容易动摇自己商业化根基的聊天机器人。
但Open AI可以冒这样的风险。
这看起来就像曾经拉里·佩奇和谢尔盖·布林在对雅虎所做的事。现在时隔多年再次因为搜索业务现身谷歌硅谷办公室所需要面对的,是一个神奇却仍被算力成本困扰笼罩、生成内容充满漏洞的ChatGPT,两人或许在Open AI的莽撞中看到了曾经的自己。
1997年,拉里·佩奇和谢尔盖·布林在买下google.com域名后,提着穷得叮当响的西装口袋为谷歌找了一年的投资,最后终于在1998年遇到了斯坦福校友、太阳公司创始人安迪·贝托谢姆的一张10万美元支票。
今时已不同往日,根据CB Insights提供的市场情报,与生成式AI概念相关的初创公司已经达到250家以上,其中有接近7成已经拿到至少天使轮的融资,其中11%的公司已经走到B轮以上。在这众多初创公司中,价值最高的就是OpenAI。
那张陈年的10万美元支票打开了一扇互联网搜索引擎的门,而人们现在对于ChatGPT的信心和期望,也几乎是从那个成功的谷歌延续而来。
谷歌也在近日拿出了3亿美元提前布局与OpenAI的攻守战。这笔投资给到了Anthropic——一家以前OpenAI核心员工为骨干,同样做生成式AI,并且此前估值已高达50亿美元的人工智能公司——换取了后者10%的股份,以及一个独家云提供商的身份。
此外,谷歌选择对内部的类ChatGPT项目Bard压下重注。
与ChatGPT不同的是,Bard在描述中可以涉及当下的时事,这意味着其可以解决ChatGPT所欠缺的信息即时性问题。
百度的“ChatGPT计划”也将以生成式搜索的形式出现。目前在内部“高度机密”,甚至不可以被公开讨论,最终这项会融入目前的百度搜索引擎中。
李彦宏在去年年底的一次内部讲话中表示,AIGC和ChatGPT这些新的技术进展会变成什么样的AI产品,仍然有很多不确定性,但这件事“百度必须做”。对于这个即将在下个月面世的项目,李彦宏给出的定位是“引领搜索体验的代际变革”。
现在无论主动还是被动的,蝴蝶效应已起。“搜索”这片已经平静20多年的湖面,一颗石子久违地抛下了。
参考资料
《浪潮之巅》,吴军
《百度将推出类似ChatGPT服务》,财经网
本文来自微信公众号:硅星人 (ID:guixingren123),作者:油醋,编辑:VickyXiao