
本文来自微信公众号:硅星人 (ID:guixingren123),作者:Juny,编辑:VickyXiao,头图来自:Dreambooth
注意看,这是一位小学老师,他正赤裸着上身在学校教室里自拍。
如果这是一张真实的照片,那么图片中这位名为John的小学老师很可能将被学校直接勒令开除。

但好在,这位John是一个由Arts Technica为了做人工智能社交图片实验而虚构出来的人物。John的人物设定是一位普通的小学老师,和我们生活中的大部分的人一样,在过去的 12 年里,John喜欢在 Facebook 上发布自己在工作记录、家庭生活、假期照片等。
Arts Technica团队通过从中选取了7张含有John的图片,再使用了近期大火的Stable Diffusion和谷歌研究院发布的Dreambooth两个AIGC工具,接着就在社交媒体上生成了不同版本、让人真假难辨的John。
在这些照片里,John从一位普通的、喜欢分享日常生活的英文老师,一会变成了一个喜欢在教室里、公众场合脱衣服自拍的“危险分子”,一会又变成了一个喜欢穿各种奇装异服搞怪的“小丑”……翻看照片,每一张似乎都不是John,但每一张却都有着John的脸。
而实际上,如今通过借助各种免费开放的AIGC工具,John的经历可能会轻易地发生在我们每个普通人的身上。
当AIGC遇上真人
Arts Technica表示,一开始在计划做这个实验时,他们征集了一些愿意分享自己的社交媒体图片来做AI实验训练的志愿者,但由于生成出来的照片太真实、带来的潜在名誉危害太大,让他们最终放弃了使用真人的照片,而是选择先用AI生成了一个虚拟的John。
实验结果让他们感觉到,在当前的技术环境下,我们每个普通人都处在一种潜在的危险之中。
整个实验过程其实非常简单:从社交媒体上拿到7张有个人脸部图像的图片,再使用网上开源和免费的Stable Diffusion及Dreambooth的合成代码,你就可以通过输入一段描述性的语句,生成各种不同风格和不同场景下有关这个人的图片。
比如网友们用马斯克网上的公开照片作为训练集,用它们生成了的各种风格的图片。

一些人也用维基百科的联合创始人Jimmy Wales的公开照片进行训练,把这个温文尔雅的企业家变成了一位运动型的健美先生。

在这里,首先要带大家快速回顾一下Stable Diffusion和Dreambooth的功能。
Stable Diffusion 是一个文字转图片的生成模型。可以只用几秒钟时间就生成比同类技术分辨率、清晰度更高,更具“真实性”或“艺术性”的图片结果。和其它同类型的AI生成图片相比,Stable Diffusion 的生成结果更为写实。
此外,Stable Diffusion还有一个重要特点就是其完全免费开源,所有代码都在 GitHub 上公开,任何人都可以拷贝使用。也正是“写实”和“开源”两个特性,也让它在DALL·E、Imagen 等封闭及半封闭同类产品中“杀”出了一条道路。
Dreambooth则是来自于谷歌AI实验室的一种新的从文本到图像的“个性化”(可适应用户特定的图像生成需求)扩散模型。它的特点是,只需几张(通常 3~5 张)指定物体的照片和相应的类名(如“狗”)作为输入,即可通过文字描述让被指定物体出现在用户想要生成的场景中。
比如你输入一辆汽车图片,就可以下指令毫不费力的改变它的颜色。你输入一张松狮狗的照片,你可以在保留它的面部特点的情况下将它转变成熊、熊猫、狮子等等,也可以让它穿上不同的衣服出现在不同的场景之中。


本来呢,Stable Diffusion聚焦于用文本生成创意图片,Dreambooth则聚焦于有条件限制地“改造”图片,这两个工具之间并没有什么直接的交集。但奈何广大网友们的想象力和行动力都太过强大,他们把这两个开源产品一捣鼓,很快就搞出了一个可以将Stable Diffusion和Dreambooth结合使用的新工具。
在这个新的工具中,你可以使用Dreambooth的功能用任何几张图片作为训练图,在生成目标之后,再结合Stable Diffusion强大的文本转化功能,就可以让这个指定目标以任何你所想要描绘的形式出现。
娱乐之外,也打开了“潘多拉魔盒”
在这个新玩法出现之后,网友们就像发现了新大陆一般,开始纷纷尝试改造自己的照片。
有人把自己化身为了西部牛仔、有人走进了中世纪的油画、有人变成了铁血战士等等……与此同时,各种关于教普通人如何使用Stable Diffusion+Dreambooth的工具的教程视频、文章也开始在网上出现。

然而,当大家都在开心地po着自己的图片,大夸技术有趣炫酷的同时,也有很多人开始关注到这个技术背后的隐藏的巨大风险。
相较于此前已经被讨论得很多的“深度伪造(Deepfake)”技术来说,AIGC类工具让伪造从“换脸”直接进化到了“无中生有”的阶段,也就是说,任何人通过一句话的描述就可以凭空“变出”一个你。此外,“伪造”技术的门槛也变得更低,跟着一个Youtube视频学个10分钟,没有技术背景的小白也可以轻松掌握。
据统计,目前全世界有超过 40 亿人使用社交媒体,如果你曾在社交媒体平台上公开上传过自己的照片,那么一旦有人产生了不良的动机,就将很容易地使用这些的图片进行造假和滥用。最后的结果可能是一张暴力照片、一张不雅照、一张侮辱性的照片,而这些照片则将能轻易地被用于栽赃嫁祸、校园霸凌、造谣伤害等各种灰暗的场景之中。
目前,从Stable Diffusion目前的生成图片来看,如果仔细观察还是比较容易分辨出人物的真假。但问题在于,鉴于最近几年来AIGC技术的进步非常迅速,人们或许将可能很快就无法用肉眼分辨生成照片和真实照片之间的区别。
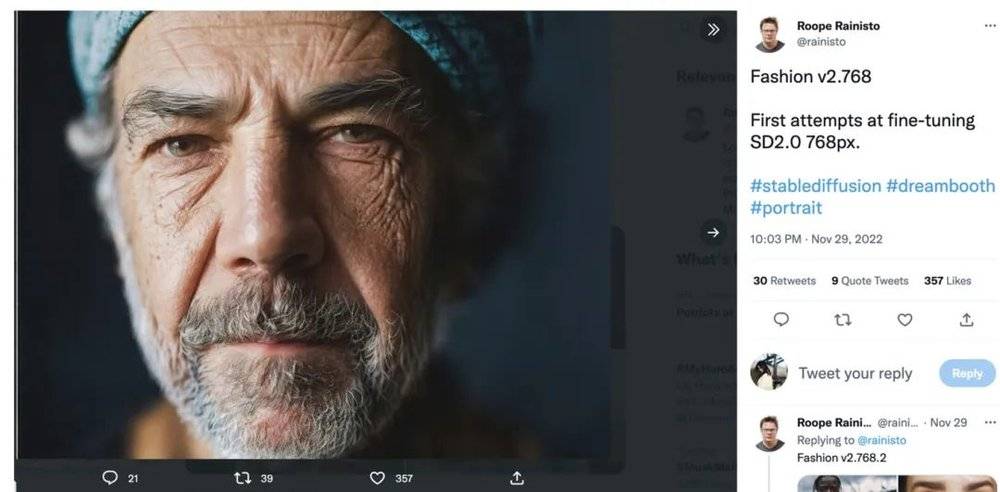
而且,即使就是一张经不起推敲的照片,但传递的负面信息其对一个人的破坏力也可能是惊人的。比如。若真的有文章开头这位名为John的小学老师,当有人看到他在教室里或者其他不雅照时,无论真假,很可能仅仅是一个怀疑或者是谣言,就能毁掉他的声誉和事业。
这就像是丹麦电影《狩猎》里演的一样,即使最后证明小女孩对男教师的猥亵指控都是编造的,但由传言所带来的恶意依然在男教师的生活中如影随形。
尝试用“魔法打败魔法
其实对于AIGC技术,开发人员们也早已意识到了其可能带来的危害。比如当谷歌宣布推出Imagen、Dreambooth时,在解释文档中都避免使用了真人的照片,而是用物品和可爱的动物的图片举例进行了说明。
不仅是谷歌,DallE等同类工具也无一不是如此。对此,麻省理工评论曾对这种转移公众视线的做法进行了强烈质疑。他们在文中写道:“我们只看到各种可爱的图像,但看不到任何包含仇恨、刻板印象、种族主义、暴力、性别歧视的画面。但即使不说,我们也清楚的知道,它们就在那里。”
目前,针对这个问题,很多平台也在尝试着用各种方法解决。其中,OpenAI和谷歌等一些平台的解决办法是将工具关在笼子里,仅开放给少数受信任的用户使用;Stability AI 在最新发布的 2.0 版本的训练数据集中删除了大部分含有不良信息的数据,同时在软件许可协议中明确规定不允许创建人物图像。
但政策性的规定毕竟指标不治本,近期,包括Stable Diffusion在内的一些平台也在尝试使用技术手段解决这个问题,其中包括“不可见水印”技术。通过这种人眼看不到的水印,系统将能够自动识别图片的真假,同时能对图片的编辑和再生成进行保护。
此外,针对训练的源头——原始图片保护上,上个月,MIT的研究人员宣布开发了一项过专门针对AI照片编辑的 PhotoGuard 技术,用以阻止 AI 使用某些图像接受训练。比如同样的一张肉眼看不出区别的照片,使用了PhotoGuard技术之后,AI便无法从中提取到足够的有效信息。

最近一两年来,AIGC的技术突飞猛进,一大批图像生成工具和ChatGPT的爆火出圈,让大家意识到老生常谈的人工智能时代这次似乎真的已经在拐角了。
不久前Stable Diffusion的研究人员就曾表示,Stable Diffusion 将很可能在一年之内就在智能手机上运行。很多同类工具也都开始着手在更轻量化的设备上训练这些模型,比如目前ChatGPT的各种插件已经开始被用户广泛使用。因此人们可能很快就会看到,由人工智能推动的创意产出将在未来几年出现爆炸式增长。
但随着AIGC走向公众化、平民化,深度合成内容制作的技术门槛越来越低,普通人仅需要少量的图像、音频、视频、文本等样本数据,就能够模糊信息真实和虚假的边界。在没有出台相关法律规范的前提下,技术一旦被滥用,将会给个人、企业造成巨大风险与实质性危害。
自从今年AI绘画类工具爆火以来,很多人把目光放在了AI对于艺术创作的颠覆上,但实际上,AI不仅是改变了创作模式,而是可能也对社会秩序发起了挑战。有条件地限制AI的能力,这也可能是在让AIGC改变我们的生活之前,必须要首先解决的问题。
参考文章:
1.https://arstechnica.com/information-technology/2022/12/thanks-to-ai-its-probably-time-to-take-your-photos-off-the-internet/
2. PhotoGuard技术:http://gradientscience.org/photoguard/
本文来自微信公众号:硅星人 (ID:guixingren123),作者:Juny