
本文来自微信公众号:刘言飞语(ID:liufeinotes),作者:刘飞,原文标题:《从机器学习聊到 AIGC》,封面图来自:本文虎嗅编辑
一、几个问题
AIGC 近期成了热点,不少小玩法开始出现在小红书,比较流行的是头像二次元化,效果较好。高端局一般会用 Stable Diffusion,MidJourney 这样的工具来生成 AI 画作。
AIGC 是 Artificial Inteligence Generated Content (人工智能生成内容)的简称,实际当然不止是画画。包括声音、图像、视频,是都可以用类似的技术生成的。

作为破圈的先锋,AIGC 的画作还是更令人震撼:


于是,有关 AIGC ,引来了几个有意思的问题的讨论:
- AIGC 能否替代真正的创作者?
- AIGC 是否意味着人工智能的质变?
- AIGC 能解决哪些问题?不能解决哪些问题?
我自己有一些观察,跟大家分享下。
二、机器学习原理
我大学读研时的老本行就是机器学习,做过一些项目,略有了解,试着用白话简单说下机器学习的逻辑。
我们可以设想一下,科学家观测一个现象后,总结出定律的方法。
古代科学家认为天圆地方,这是最直观的推测,因为太阳月亮星星的运转用这个解释是合理的;后来观测到了地球是球型,那地心说就是直观的逻辑;再后来观测到了更多天文现象,就知道太阳才是太阳系中心,地球是公转中做自转的。
这个演进是符合一个逻辑的:依据当前的信息,解释一个现象,用最简单的方式。新的现象出现,解释不了了,再加入别的因子让它变复杂,再解释新的现象。
机器学习正是如此。
我们要识别一个人会不会买口红,最直观的方法就是判断 ta 的性别,是女性,就有更大的概率会买口红。人的属性千变万化,但性别就是我们判断“买口红”这个命题的“特征提取”。我们找到这个规律以后,就能用性别作为特征,建立模型。
输入用户资料 - 提取性别并判断 - 输出
现实情况更加复杂,可能男性也会买,往往是在逢年过节的时候送礼用。那么性别(男)+购买日期(临近节日),也能成为重要的特征,我们就要引入新的特征向量,即购买日期。
输入用户资料 - 提取性别&购买日期并判断 - 输出
根据新的用户资料和购买行为,我们持续会发现新的特征有利于我们的判断。于是就引入更多新的特征,比如除了公共节假日,可能还要看用户女朋友/家人的生日;比如女性里面,购买口红概率更大的,可能会出现在某个年龄段,等等。这样“特征”就越来越多。
输入用户资料 - 提取性别&购买日期&年龄&....... 并判断 - 输出
我们输出的结论肯定就越来越准确。这就是机器学习运作的基本逻辑。
即然要提取这么多特征做判断,就要看不同的特征影响输出的程度有多大。性别和年龄可能权重大一些,其它的可能权重小一些。怎么判断呢?肯定不能人为,那就要训练一个模型。
机器学习的模型就是投入我们认为筛选出来的特征维度(性别、年龄等)、大量的正向和负向的案例(训练集),让机器学习出一个极度复杂的公式,公式来解释每个特征影响结果的程度。
这里面训练集的规模就成了重点,案例越多肯定越准确。在过去的时代,很多训练集是需要人工标注的,标注员会跟富士康的工人一样算是劳动密集型的工作,去判断这个案例是正的还是负的。比如文字识别,这个字是哪个字?图像分类识别,这是猫还是狗?一段翻译,是否翻译准确?
这也是为何互联网公司团队往往拥有最好的“算法”。当我们提到算法好的时候,大部分情况下其实讲的是这个公司的机器学习模型准确度高,这个准确度来源于公司收集的大量用户行为数据,用户是在用准确的行为免费帮企业做标注,比如购买消费行为、浏览点击行为,等等。
此为机器学习的原理。当然这是白话说的,具体怎么提取特征、怎么判断权重和因子间相互的影响、怎么分类、怎么建模等等,其实是很复杂的技术操作。
三、深度学习与 AIGC 原理
机器学习发展到 21 世纪,计算机的性能大幅提升,开始演化出深度学习(Deep Learning)。
深度学习之所以是“深度的”,就因为除了能学习模型怎么做精确,还能学习怎么建模本身。
前面讲的案例里,我们要识别一个人会不会买口红,还是从“生活观察”出发,去猜想,诶,这个特征是不是有关系?那个特征是不是有关系?
深度学习的逻辑不需要判断,就是一股脑把所有的信息,转化成数据投入进深度学习的模型里去,它会自己去判断哪个有用、哪个没用。
这样的好处是很显然的:能覆盖更多的特征、能采集更多的数据。并且由于深度学习的算法是可以叠加很多层次的,就能解决更复杂的场景、更复杂的数据。
所以深度学习的效果会明显变好。
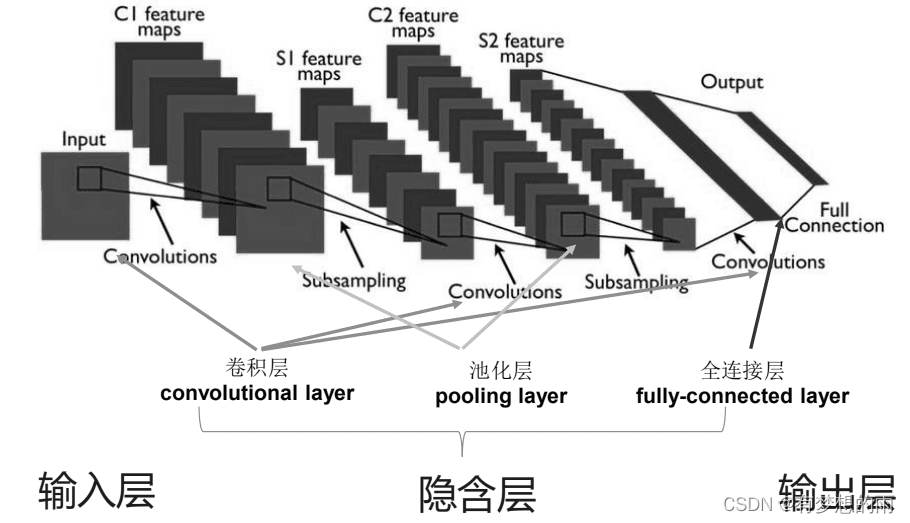

它的具体实现当然又更加复杂了。我们只需要知道,它在图像方面,有最出色的表现,很适合基于原始内容(噪音)、补充和丰富细节。
GAN 是 AIGC 最常用的机器学习算法之一,另外一个常用的是 diffusion model,在某些方面很像,比如也是适合基于原始内容(噪音)来生成内容。文章一开头的那几张图,就是基于 diffusion model 原理的。
所以总结下就是,机器学习的发展过程中,大大简化了人工参与的环节和步骤、丰富了输入和输出的维度及准确性,继而从“会不会买口红”这样简单的问题,进化到了可以生成一幅宠物的照片、一段以假乱真的视频、一条模仿某人的声音。(推荐英剧《真相捕捉》,讲的是围绕 Deepfake 这类技术的罪案故事。)
这个过程中,很多公式和模型的复杂性已经到了难以解释,甚至无法去遍历和阅读的程度。聊到这,可能诸位也能有一种感受:这些年机器学习的进展飞快,不过仍然都围绕在最初机器学习的原理上——通过海量的数据训练机器,让机器能更好地预测概率。
四、统计、概率、训练与经验主义
我们换个视角,用更形象的表述,可能有助于理解机器学习是怎么实现我们看到的人工智能的。
自然语言处理/机器翻译领域,我们目光所及的翻译工具,用的方式可以这么理解,比如是中文翻译到英文,机器做的事情是:
当给出的第一个中文词出现的时候,翻译是哪个英文词的概率更大?
当给出的第二个中文词,出现在第一个中文词后面的时候,翻译是哪个英文词的概率更大?
......
类比到 AIGC 领域,比如我们要画一个小狗,机器做的事情是:
当给出的关键词是小狗的时候,第一个像素点在哪个位置、哪个颜色的概率更大?
......
当画完脸部后,它有没有耳朵?
有的话,有几只耳朵的概率更大?
当应该要有左耳的时候,它的第一个像素点出现在哪个位置、是哪个颜色的概率更大?
......
机器在过程中,虽然用的是模型,实际上模型都是基于统计概率的模型。机器更像是在疯狂回忆它记住的所有过往的画作里,所有小狗的形象,力图让结果更接近“大概率”。
这也是为什么在各个 AI 绘图的工具里,关键词给的越精确,画作就会越成立。因为精确意味着缩小了范围,同样类型画作的风格、样貌是更接近的,画作的模仿效果就会更好。
这里训练出来的统计概率模型的过程,恰似古代的杂技工作者,让宠物做计算题的方式。当出现哪几个数字的时候,应该选择怎样的答案,宠物是靠背的,这个是统计概率的问题,不是数学计算的问题。训练的过程给的奖惩,跟机器学习是一样的(机器学习里也有奖惩概念)。
这也是机器学习里的神经网络,跟人的神经网络目前看差异最大的地方。我们很好地运用了计算机夸张的性能和存储能力,让它拥有巨型的统计概率模型,来存储海量数据训练集得到的记忆结果,但说到底,它有的还是围绕统计和概率的。
这也意味着,它是完全经验主义的。AlphaGo 可以参考天下古往今来所有的棋谱,但下不出没见过的棋谱;Novel AI 可以参考所有的小说,但不会用没见过的词组和表述。
只不过在 AIGC 的领域,内容的复杂性,在观感上,就弱化了我们对统计概率逻辑的认识,以为这个就是机器天马行空做出来的。其实机器还是在采纳大量过往画作基础上做“创作”的,但的确不同的拼凑和处理,会出现意想不到的效果,这是因为画作本身就是对现实世界的抽象,若离若即效果最佳。
如果是在书写长篇小说、拍摄一部逻辑完整的电影方面,就要吃力太多了。
五、几个问题的解答
我们再回到最初的问题,试着解答一下。
- AIGC 能解决哪些问题?不能解决哪些问题?
如前文所说,AIGC 可以解决的,是从历史里做总结和学习,凭借统计概率,解决已被解决过的问题。
不能解决的,则是创造新的事物、总结规律、解释世界的问题。
- AIGC 能否替代真正的创作者?
一定程度上会。
哪怕只是经验主义、原理与 AlphaGo 并无本质区别,AIGC 也有很大的价值,那就是在某些足以乱真的领域,替代掉很多人工的成本。
比如 AIGC 的画作,如今就能替代不少插画。很多自媒体的朋友已经在用它们替代无版权图片作为封面了。
老话说,读书破万卷,下笔如有神。AIGC 的文本工具,其实就是替我们读了万卷书的助手。比如我们要写作,它帮我们生成一段人物小传作为参考、帮我们提供一些场景描述作为素材,就大有帮助。
只不过,对于很多真正需要“创造”的场景,AIGC 就爱莫能助了。例如,机器学习的训练集若是在三年前的,肯定就无法写出疫情故事、也难以想象疫情中我们常人都很难预知的场景。
几年前就出现过 AIGC 替代作者的说法,不过如今再看,应用比较多的还是在短新闻方面。它能很好地基于概率给出一篇“不错”的新闻通稿,但这也是过往短新闻格式一致、风格类似,较好模仿。观点、态度、延伸的想法,自然是很难用统计概率去捉摸的。
- AIGC 是否意味着人工智能的质变?
没有。
AIGC 的逻辑,与半个世纪前统计机器学习的根本逻辑并无二致,还是基于统计概率的,基于训练集去猜测的。哪怕 Siri 里偶尔出现精妙的回答,那也是曾经有对话真正发生过,Siri 从概率出发模仿的而已。
哪怕 AI 绘制的最拍案叫绝的画作,也是基于人类历史所有画作的基础创作的,还是人类作品的杂交。哪怕艺术性很高,也不代表 AI 有了“智慧”。
人类是可以归纳、演绎、总结背后逻辑的,这点机器依然做不到。甚至随着机器学习的黑盒越来越黑、模型越来越难以解释,让机器在更擅长做统计和记忆的路上一去不返,放弃了做解释、研究规律。
不过说到这里,也可以反问一句:是否通过统计概率就真的无法产生智能?这个目前看很难,但未必一定是假命题。人类自己的神经网络都还是朝阳研究学科,这就得留给时间去解答了。
参考与推荐:
AI时代的巫师与咒语-Rokey
当我沉迷AI画图几百小时后,我在思考什么?-少楠
深度学习 – Deep learning | DL(https://easyai.tech/ai-definition/deep-learning/)
“生成对抗网络 - GAN”基本原理(https://blog.csdn.net/weixin_45508265/article/details/115446736)
由浅入深了解Diffusion Model (https://zhuanlan.zhihu.com/p/525106459)
卷积神经网络(convolutional neural network, CNN)(https://blog.csdn.net/qq_41536160/article/details/125015435)
本文来自微信公众号:刘言飞语(ID:liufeinotes),作者:刘飞