
本文来自微信公众号:InfoQ(ID:infoqchina),作者:刘星,原文标题:《这20年,我“颠簸”在软件工程的列车上》,头图来自为作者与Spring之父的合影
世界格局在进入 21 世纪之后风云变幻,软件领域同样风起云涌。从硬件到软件,从单机到分布式,从孤岛到互联,程序员的创造力无比强大。但究其本质,软件工程和土木工程其实没有太大的区别,只不过一个是在码字母,一个是在码砖头。至于建筑的主体,设计缺陷,或者地基没打好,一样会垮塌,不管是楼塌了还是软件崩了,都可能成为整个世界都能感知到的大事件。
本文作者刘星先后经历安全行业和大数据领域,2011 年加入淘宝,参与了当时全球最大的 Hadoop 集群的开发和运维,在阿里先后担任数据开发平台研发负责人、研发效能 Aone 研发负责人。本文中,他将从 2003 年淘宝网成立那年开始,回顾总结这些年来软件工程体系的主线技术,探讨变化和趋势,并从自己的视角给出一些观点和思考。
一、开发模型的演进
选择何种模型对软件工程的工作开展至关重要,甚至对一段时期的技术特点都会产生本质性影响。所以,第一节必须从这里开始讲起。
20 年前还是以单机软件为主的时代,以操作系统、办公套件、ERP 系统等为代表的大型合作类型软件工程,特点是研发周期长、进度缓慢,一旦分发到个人电脑上则不容易被召回替换。一旦软件比较优秀,满足了用户的基本需求,就很难推动用户再去升级,所以当年 Windows 升级换代替换任何一个成功版本都非常艰难。
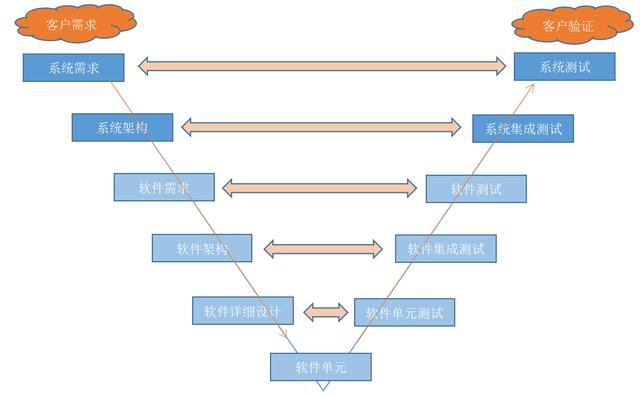
在这样的背景下,瀑布模型是最主流的一种开发模型,几乎垄断了所有大型软件的工程开展。瀑布模型的优点和缺点已经被总结的很好,本文不做展开,仅以我自身参与的瀑布模型工程体验来简单说一说。整个瀑布模型,就是大家经常提到的 V 字形,从需求到交付,位于 V 字最低端的是真正的编码过程,V 代表瀑布模型,简直是再恰当不过的字母,因为编码过程在这个模型中,真的就只占用那个端点的长度,其他时间都被各种讨论过程和文档占据。
好像一个武林高手,在擂台上做了几个小时的准备工作,万事俱备后,突然出手用手指点了一下目标,然后就立即收手又搞了几个小时的收拾现场工作,大家都沉迷于这位高手出手前后的花式展示,而真正出招的那个瞬间却都被大家忽视了。据此诞生的 CMMI 认证,专门用来衡量高手出招前后姿势漂不漂亮,热身动作到不到位。
受此影响,早期的互联网 Web 工程的开发也是遵从瀑布模型的组织形式来进行的,也许在执行上有所变形,但从系统架构上看,瀑布模型的痕迹非常明显。比如我们公司十八罗汉之一的一指主导的 WebX 框架(刚入职那会我有幸通过旺旺向还身在加拿大的一指请教过技术问题),通过配置和 Package 将工程切分的非常细致,让每一个工种都能找到自己应该按部就班的地方,负责写 SQL 的,负责写 HTML 的,负责写 JS 的,负责展示层模板的,负责事务层的,负责数据模型的等等。
当页面上需要新增一个功能的时候,如果分工的每一层都需要一名专职程序员来做,那么很可能就要驱动 10 来位程序员进行修改,由于框架明确了这些人的工作范围和职责,所以这些人需要坐在一起讨论需求,通过文档来沟通对接细节,讨论单测和集测的展开。
最终这些文档和沟通工作都完成后,武林高手们终于在一瞬间出手,页面上添加的那个活动页终于在最后一瞬间出现了,这时候,收到交付产物的运营抬起头一看日历,双十一大促已经是半个月前的事情了,忙活了大半年,大家什么都考虑到了,就是没考虑到耗时排期的漫长。
对于交付到个人电脑上的产品来说,瀑布模型可以提供质量稳定、交互良好的产物,当然也是有失败的可能,只能说产出优秀产品的概率相对于其他模型来说会更高。但由于多级开发其实和真正的用户之间的沟通是完全脱节的,所以有时候用户希望得到一个圆柱体,拿到手的却是一个长方体,项目经理只能敷衍用户:“这两个物体的截面都是矩形”。
到了个人电脑上,软件缺陷就很难再通过简单便捷的升级来弥补。这有点像专有云,交付出去了,再想升级,可能要到半年后了,那么期间出了故障,只能请 ISV 到现场帮忙检测,有时候甚至只能通过拍照提供一些资料回来,碰到军工政府类型的专有云项目,审核更加严格,周期更加漫长。把整个专有云想象成当年你桌上那台没有网卡的单机电脑,还是比较形象的。
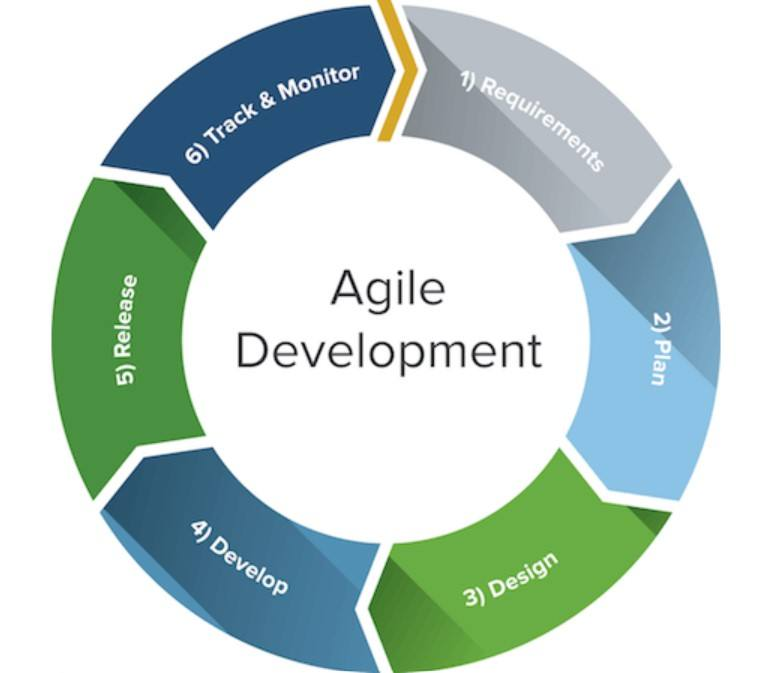
但是,互联网怎么可能静下心来慢慢欣赏你的瀑布。过程做的再好,交付出一个过期的产品都是不可接受的,所以坚持这个模型走上互联网之路的公司大多都死了,甚至有些过于注重过程的国家(比如日本)都因此在互联网时代销声匿迹。短平快地贴近用户需求进行极限开发才是互联网不变的主题,所以敏捷(Agile)开发快速在互联网的世界大行其道。因此带来的极限编程、结对编程,在 2010 年前后迅速点爆整个软件工程界,几乎不敏捷就跟不上时代了。
甚至由于深受瀑布模型缺点困扰多年的一些公司,会报复性地去实施敏捷,看到谁准备工作多了点,讨论得深入了些,那些还没进入行业几年的“资深”程序员就会斥责新人们不够 Agile。而互联网时代的指数级增长,动不动一个风口,使得大家都深陷浮躁之中,激进到甚至连错误的观念都被增长所掩盖,而得不到纠正的机会。因为吸引人们眼球的永远都是成功表面的浮华,谁会进去看看背后那堆臃肿杂乱的稻草呢?
到 2015 年前,互联网技术风向标开始倡导全栈,对研发人员的要求也越来越多,最基本的是前后端的全栈通吃,测试、运维也转向服务化,设计了大量的测试和运维平台,围绕研发过程的自动化探索效率与质量的平衡点。
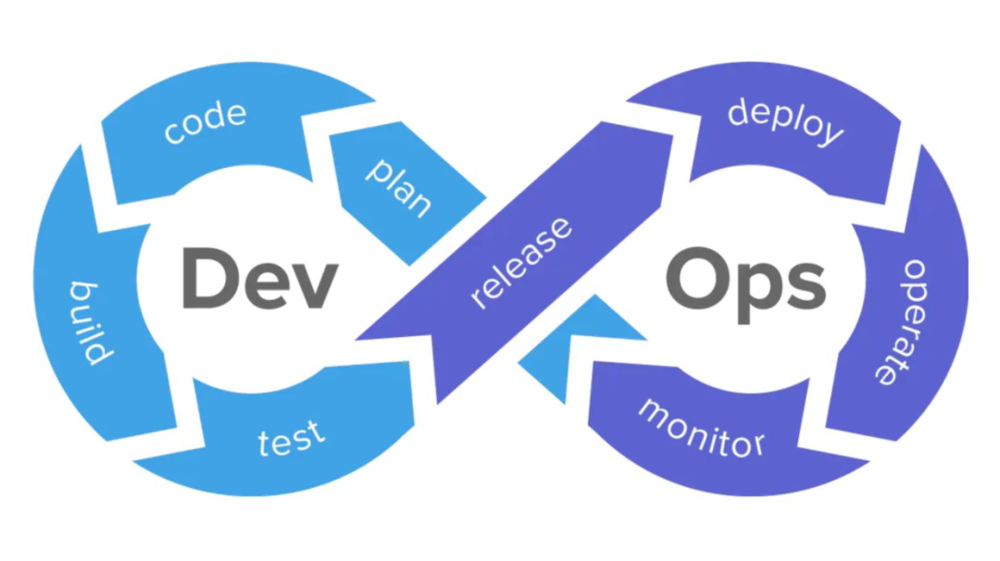
而随着硬件性能的提升,虚拟机技术越来越成熟,传统运维观念逐渐改变,开发测试运维的边界也越来越模糊,DevOps 概念呼之欲出,在敏捷的基础上继续推进变革,容器、弹性扩缩容、高可用等新技术的出现,终于将软硬件在 DevOps 这个模型上结合到了一块,就像 DevOps 的经典图形 ∞ 符号那样,未来甚至还看不到这一趋势的终点。
二、技术的演进
技术是服务于开发模式的,在一种开发模式下,适配的技术体系总是与之呼应,并相辅相成。所以随着瀑布到敏捷再到 DevOps,随着硬件性能的提升,也随着大神们改变世界的驱动力,技术在各种探索和喧闹中不断演进。
服务框架
上文提到我们阿里早期使用的 WebX,其实这个框架和当时流行的 SSH(Struts+Spring+Hibernate)思路差不多,发展到 3.0 版本之后,就逐渐退出了历史舞台,但是历史包袱还在,ATA 上还能看到有人在撰文写一些 WebX 的学习心得,大多数情况应该是接手了某个相当沉重的历史应用,不得不去面对这个古老的框架。
WebX 在互联网还没那么复杂庞大,软件基础模块也没有封装得那么完善的年代,是一个优秀的框架,它甚至让淘宝网躲过了 Struts 的 0day 漏洞满天飞的厄运。从 PHP 过渡来的淘宝网,正是在这个性能一般般、开发效率很低的框架下逐渐开始走上正轨。
WebX 无论是在开发还是部署上,都属于相当笨重的一套框架,而几乎是同年起步的 Spring 则轻巧灵活了许多。2017 年,我去湾区参加 Spring 大会,还有幸与 Spring 之父 Rod Johnson 要了合影,只是那会他已经淡出了 Spring 社区。(Spring 的编年史见原文附录 1)
在 Spring 的基础之上,面向企业级的 MVC 框架 SpringMVC ,更加轻量灵活、应用约定大于配置思想的 SpringBoot,还有关注微服务整合的 SpringCloud,最终组成的 Spring 家族,完整提供了面向不同需求的服务端解决方案。

2015 年是个分水岭,我们公司 2015 年前 SpringBoot 还只是零星试点,之后几年就立即遍地开花,好像书上常说的,历史的车轮滚滚向前,框架的车轮显然也不会停歇。持久层框架也从笨重的 Hibernate 转到了 iBATIS,再到 MyBatis。
前文提及的全栈工程师,到了 2015 年后,随着手持设备硬件性能的提升、浏览器 H5 标准的统一、移动端的兴起,前端三剑客 Vue、AngularJS、React 也开始逐渐引领大旗,一度被后端模板化渲染夺走的技术阵地,竟然在边缘计算这样的概念下,又复活了。
本来全栈的程序员们,也重新被划分成了前端和后端两个 Job Code,而此时两者的职责和最初的定义已经完全不同了。此时的后端更加注重对业务和需求的理解,专注于性能和架构的优化,而前端则更偏向于交互和体验,尤其在一些重前端的 toB 类产品上,前端的主导性更大。
后端提供零散接口,而前端更希望采纳整合后的统一接口,后来催化了多以 Node.js 语言为主开发的 BaaS(Backend As A Service)层微服务,一般也是由前端工程师来负责。个人感觉,BaaS 的引入更适合移动端的开发,对传统 PC 端浏览器应用的协作效率提升较小。前后端分离还带来了一系列新技术的诞生,例如 CDN 技术,使得前端更加独立,甚至在后端服务宕机的情况下,还能提供一定的挽留用户体验。
而在服务端技术上,中间件在过去十年间大放异彩,我们公司在中间件上做出的成绩就不用多讲了,这和当初提出的大中台小前台背景不无关系。庞大的中间件群体带来的效率提升也经常是变革性的,最初看起来一切都很美好,直到频繁升级开始带来效率反噬的时候,我们才意识到其中的问题。
框架使研发能够通过代码掌控一切,而中间件则通过集中式服务来降低代码工作量。所以无论是框架的演进,还是中间件的演进,都应该有一个平衡点,完全依赖某一方都会导致失衡,从而带来工程效率上的灾难。
在服务端依赖的底层基础设施上,虽然从 2003 年至今的大多数年份,电商始终处于风口上,但也依然有一些为了省钱应该要做的事情。从操作系统、数据库、计算能力等几个方向上节约成本,是效率最高的,在电商规模起来后,由章文嵩主导的 LVS、淘系的去 IOE 等重大技术变革,一方面为阿里省了钱,另一方面也让自主的技术体系不再受外部技术提供商的掣肘。进而电商系的技术自研能力逐步开始领导互联网时代。
编程语言
为什么编程语言放在了框架之后,因为提及语言,必然会引起程序员们的争论,假设说一句“PHP 是世界上最好的语言”,必然引爆此文,让众多读者弃之如敝履。上文的框架已经引入了经常被我司同学鄙视的祖传 Java,还有众多 Python、C/C++、Golang 等语言的大拿正在摩拳擦掌,准备群殴本文的观点。
但即便如此,我还是想提出一个看法,即语言是服务于系统架构的,适配于场景来选择我们需要的语言是一名程序员的基本素养,而不是基于爱好。软件工程一旦发展到比较庞大的规模,即使是再先进的语言,如果不能捡拾前人的积累,都会导致不得不重新造轮子,引发效率的下降。
虽然不少语言都会有一个典型的产品来代表,比如日本人设计的 Ruby 语言的代表作是 Gitlab,但如果让商业化公司来选用,也不得不面对冷门语言招聘困难的局面,即使招到了资深的冷门语言专家,他们的未来发展也是一个大问题。所以像 Kotlin 这样可以直接利用 Java 积累的语言,会更容易被接受一些。
最近在面试的时候,也发现快手和字节的一些主流用 Golang 的团队,正在重构回 Java 体系,问及原因,大多也是因为商业化企业需要的是多快好省。在风口上没有暴露的问题,正在互联网寒冬下逐渐浮现。
微服务起步后,给予更多小众语言以更好的生存环境,Service Mesh 技术让小众语言也可以通过接口或者系统调用获得更多中间件体系提供的便利。虽然当前还远未到完全成熟应用的阶段,尚处于前沿,但的确是一个很好的方向,让编程世界的多样性和竞争性充满了希望。
但在微服务之下的 SOA,大多数还是建立在传统语言之上。我司发展了那么多年的 Java 体系,带来的群体优势是其他语言无法比拟的。不少语言,虽然在编程效率上优于 Java,但一旦用来做大型工程,则会在到达一定规模的时候陷入自洽性矛盾:要么放弃语言的灵活性,要么放弃工程的可持续性。
在服务端技术上,当前我司还是以 Java 为主的,这就好比引擎层,大多是 C/C++ 为主,而算法层则是 Python 为主,成体系的事情,我们没必要多做讨论。至于更加冷门的语言,比如 Lisp、Scala 等更常见于特定的领域。
这一节就到此为止,不再引战。
大数据
2003 年是个神奇的年份,淘宝网在这一年诞生,Rod Johnson 正在编写 Spring 的初版,而 Google 则在这一年发表了奠定大数据基础的三大论文的第一篇《Google File System》,随后又在 2004 年发表了 MapReduce,2006 年发表了 BigTable。有了这三篇划时代的论文,在当时的搜索行业老二雅虎的支持下,Hadoop 迅速发展了起来。
在 21 世纪的第一个十年,大数据体系 HDFS + MapReduce 就已经完成了奠基工作(参照原文附录 2),对未来软件工程带来的积极影响无法估量,甚至可以说没有大数据的发展,后来的机器学习和 AI,都将因为没有土壤而无法顺利商用。建立在这个基础之上,计算的弹性也被明确定义,进而发展成云计算,再到后来与资源的弹性结合,促进了世界范围的云厂商的繁荣。
我认为,这里最重要的是第二篇论文 MapReduce 编程思想,它将复杂的问题划分成小块,然后逐一破解,再将结果汇总。如果一次 MR 不够,可以使用上一个任务的输出进行第二次、第三次、第 N 次的 MR,直到取得最终需要的结果。后来,无论是大量使用内存从而使计算更快的批处理产品 Spark、Impala、Spark Streaming(微批),还是流式计算 Flink、Kafka,在计算的核心思想上都沿用了 MapReduce。
这有点像微积分,Map 相当于微分学,Reduce 相当于积分学,当两者结合,就可以降低问题的复杂度,几乎就可以解决现实中的一切难题。数学上微积分用来对付无穷,而 MapReduce 用来对付趋近无穷的海量数据,的确是最恰当不过了。
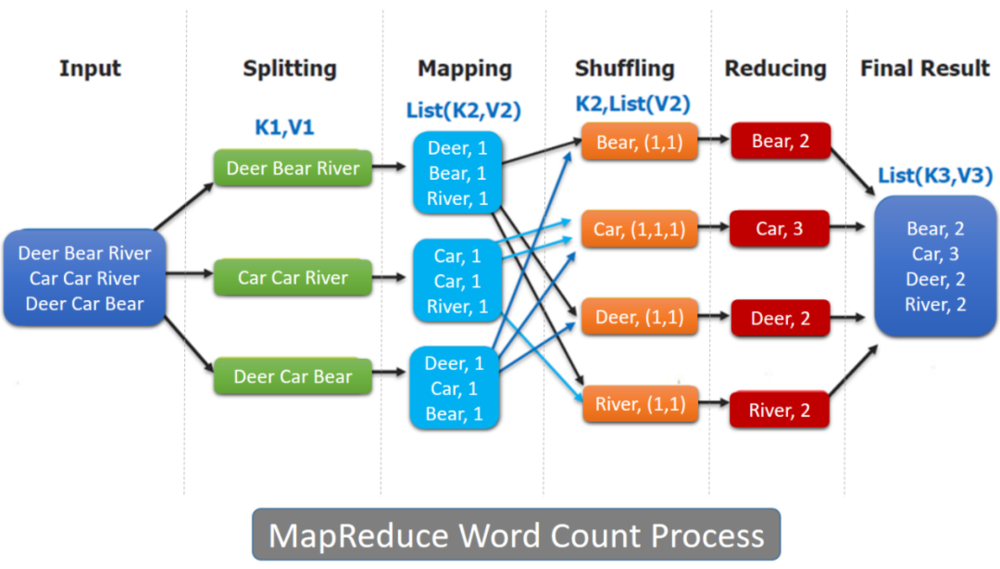
最初我们使用 MapReduce 的时候,是直接通过编写 MR Job,通过 Split、Map、Shuffle、Reduce 等过程完成一个任务的设计开发。这对程序员的要求还是比较高的,编写过一些 MR job,就会意识到这样的任务在编程开始前,就要在头脑中形成数据全局观,从结果数据倒推初始数据的切分,稍有不慎就可能造成长尾计算或者数据倾斜。
上手难度大、调试成本高、开发周期长,这一切到了 2010 年使用 MySQL 解析引擎的 Hive 出现后,终于通过简单易学的 SQL 语言避开了上述难题,数据开发的效率像坐上了火箭一般迅速提升。也是到了此时,全球范围随着数据量的积累,大数据的威力逐步展现,数据开发工程师这个全新的 Job Code 也在此时诞生。
当时的中国,能够使用这些大数据产生商业价值的,只有百度和淘宝。而作为承载数据开发的平台,从云梯 1 时代的天网,到当前的 DataWorks,进一步降低了数据开发的门槛,就算没有什么基础,产品和运营也都可以通过简单的学习,就能在 DataWorks 之上具备基本的 ETL 能力。
而 DataWorks 通过其核心的调度系统,组装了千万级任务,通过每晚 0 点到早晨 9 点的大规模集中计算,实现了阿里巴巴体系下所有离线数据的生产。海量数据领域的门槛降低,效能却大幅度提升,轻易就可以将数据间的交互计算任务挂载到我司数百 PB 的商业大数据中,从而通过数据来激发工程能力。
此外,还可以通过 UDF 函数,在 DataWorks 平台上能够快捷的实现复杂计算逻辑,再通过 Function Studio 进一步提升编码调试效率。此外,由于数据开发语言具备一定的通用性,因此在 OLTP 和 OLAP 领域,为提升数据的利用率和复用开发人员的产出,流批一体(一条 SQL 既可以跑在流也可以跑在批)和数据湖(同一份数据可跑多种计算引擎)技术在持续演进。
至此,到了 21 世纪的第二个十年结束前,大数据领域的核心工作基本上已经全部完成,如今只剩下在前人基础上的修修补补,以及不断的压榨集群硬件的利用率和提升运维效率这几件事了。
还有 NoSQL 领域,代表作 HBase 在 2010 年成为 Apache 的顶级项目,我是在 2009 年跟随我当时的同事,身为 HBase 社区 Committer 的“Andrew Purtell”进入了 NoSQL 的世界。当时的 HBase 还完全是个玩具,动不动就彻底崩溃,回想起来,当时 Base 在美国的 Andrew 绕过大半个地球跑来中国满头大汗地给我讲解 NoSQL 的实现原理,虽然这项技术当时还很挫,但很快 HBase 就成熟并实现了商用。
NoSQL 成为当前主流的能够提供在线服务的 BigTable,也和 Google 的搜索引擎的实现技术有很大关联,尤其记得当年第一次来杭州面试阿里云的时候,当时的面试官问我 Google 如何实现海量数据索引,当我回答 NoSQL 的常规实现方案后,面试官甚为不解,进而和我为是否需要 NoSQL 吵了一下午。当年的云计算和大数据的前沿性可见一斑,领域内的行家屈指可数,虽然那次争吵非常不愉快,最终不欢而散。但在半年后,我还是参加了淘宝的面试,最终来到了杭州。
我在 2011 年加入淘宝云梯 1 团队的时候,当时的 Hadoop 集群只有一千多台机器的规模,到 2014 年云梯 1 的 Hadoop 集群下线前达到了单集群双机房 1 万台物理机(当年的单体规模全球最大)。当时的 C 和 Java 性能之争,开源和自研之争,激烈的观点冲突放到现在来看都是上乘的技术探讨典范。然而时过境迁,斯人已去,唯有当初那台签满研发人员名字,承载过 Hadoop Master 的刀片服务器,还留在云智能的飞天博物馆永久陈列。

机器学习与 AI
数据到了海量之后,机器学习才有了生根发芽的土壤,通过机器学习的积累,人工智能的威力在最近的 5 年间开始爆发。2010 年 Hadoop 上的机器学习工具 Mahout 成为 Apache 的顶级项目,但真正在深度学习领域发挥实力的还是大神贾扬清的 Caffe 和他参与的 TensorFlow。
这个领域在商业上的应用相对来说起步很晚,基本上到了 2015 年后,才在千人千面、猜你喜欢、无人驾驶等领域开始大放异彩。对于 21 世纪第三个十年的软件工程来说,可以看得见机器学习与 AI 必将成为产品上不可分割的一部分,算法工程师不再沉迷于和人类对战国际象棋,而开始深度参与到直面用户需求的过程中。
但是,当前承载算法,如神经网络、深度学习的平台还不够优秀,距离 Hive 之于 Hadoop 这样的效率提升还有不小的差距。我司的 PAI 平台已经在探索算法优化的道路上前进了一大步,它将数据和算法当做材料,通过 DAG 组织算法序列,在易用性上已经提升了不少,但对于普通开发者来说还是过于复杂了。
Jupyter Notebook 则另辟蹊径,将论文与代码相结合,可以让算法研究者一边写论文一边写代码,待论文完成后,就可以在 Jupyter 平台上执行新的算法验证效果,因为算法大多属于文档远多于代码的一种开发过程,因此 Jupyter 的创意带来的沉浸式体验提升了学者的创新效率,也降低了他们进入工程领域的门槛。
更早的时候,淘系搜索推荐采用效率更高的线上分桶方式,快速验证算法的效果,类似于工程上的灰度,将不同算法灌装到不同的桶里提供给用户,通过用户的成交率、客单价等指标快速优选出合适的算法,这样的产品比如 TPP(The Personalization Platform)。
虽然业界已经在快速发展,但整体来说,算法还是相对于工程之外相当独立且门槛还没降到足够低的一个领域,如果能够出现类似 Hive 这样跳跃式降低大数据门槛的产品,那么机器学习与 AI 领域的发展可能就会被直接引爆,人类社会的进化进程说不定都会因此而加速(也许是机器代替人类,谁知道呢)。
其他
围绕软件和互联网行业,技术新进展层出不穷,还有一些相对来说没有在聚光灯下,但也非常重要的技术领域,本文限于篇幅没有提及。比如安全技术、测试技术、运维技术、存储技术等。在软件工程中,这些领域不可或缺,但往往对工程的效率影响并不一定都是正向的,比如安全技术对互联网软件工程进度的影响往往就是负面的,而且还做不到对程序员无感。
运维领域在最近的十年里面发展迅猛,这一方面有赖于企业级硬件性能的大幅度提升,另一方面和开发模式的演进、思维观念的转变不无关联。十年前,机房中还在使用 God 系统来对刀片机进行物理式断电和重启,到后来的虚拟机技术 VMWare、Xen,再到 Docker 的出现,然后 K8s 服务编排进一步模糊了运维和研发的边界,结合云服务提供商的业务,最终促成如今的云原生时代。还有区块链技术、服务网格(Service Mesh)等,提升工程效率的新技术如雨后春笋一般不断涌现。
这让我经常想起 2008 年我在日本富士通沼津市软件工场出差的那段时光,在巨大的一望无际的地下机房里,看到无数台密密麻麻的磁带阵列组成的存储矩阵,每一台阵列中都有一只机械手在不停的上下翻飞,快速插拔着几百盘磁带,实现寻址功能。
而到了今天,单块磁盘的存储容量都已经达到了 20 TB 以上,大量的企业级存储已经被更快更稳定的 SSD 所替代,无论是硬件还是软件,摩尔定律始终在操控着计算机的世界,这么想来,软件工程的效率应该也是遵循着每 18 个月翻一倍的速度前进的吧。
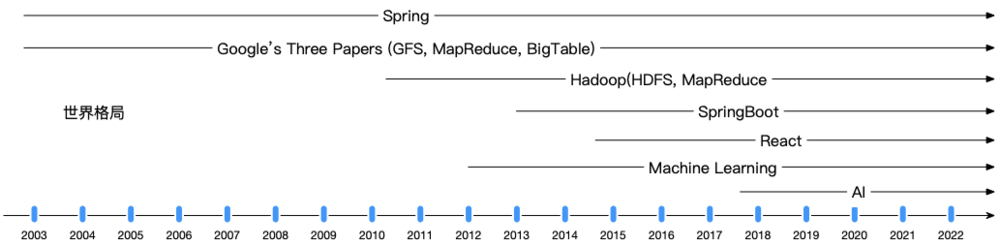
三、漫谈软件工程
20 年是个不短的过程,一个成长中的孩童都有可能经历完了自己的青春,逐渐步入中年。但对于软件技术来说,似乎永远无法越过青春。我们能看到一个个技术从诞生到壮大再到成熟,直到被新的技术汰换而走完生命周期,但是整个技术界随着新技术的诞生,又开始再次沸腾。如果说过去的 20 年有什么永恒的主题,那一定是围绕着工程效能展开的。
技术领域的素材散落在各处,如果都依赖架构师和程序员的组合拼装,效率显然极低,且无法复制。因此软件工程需要有一个组织体系,这就好比交响乐需要一名指挥家,邮轮需要一名舵手。下面这幅图展示了当前云体系下的产品地图:
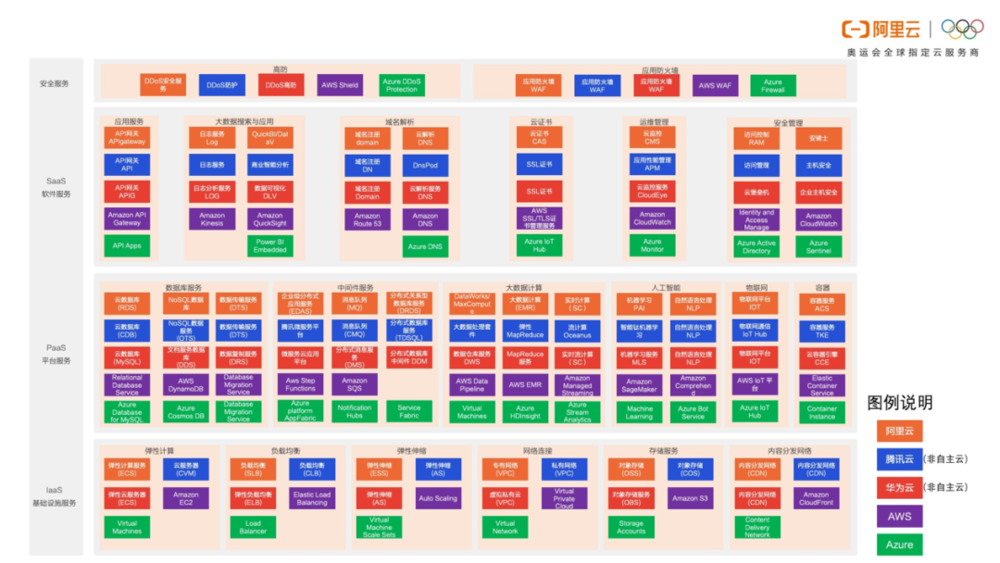
组织好这些产品,让其在合理位置上支撑业务的发展,并引导工程师的心智,倡导正确的方向,这些掌舵的工作正是研发效能团队应该承担的责任。现阶段的软件工程,已经不再是过去那种简单的围绕着数据库 CRUD 的编排服务,当一个工程在代码仓库里落下第一行代码,就意味着它需要和资源、网络、中间件、离线计算、搜索引擎、实时计算、算法、运维、测试、安全等一系列技术体系打交道。
这个时代对程序员的要求越来越高,但软件工程领域的抽象也随着这样的要求在不断聚合,从而使得门槛降低,复杂度也越来越简化。持续集成、持续部署、持续发布在软件工程领域成为每个人都在讨论的话题,尤其当蓝海逐步转向红海,从烧钱转向比拼效率,研发效能以及服务工程师的底层基础设施的重要性尤其凸显。最近看到一张图很好地诠释了研发基础设施在组织软件工程上的重要性。
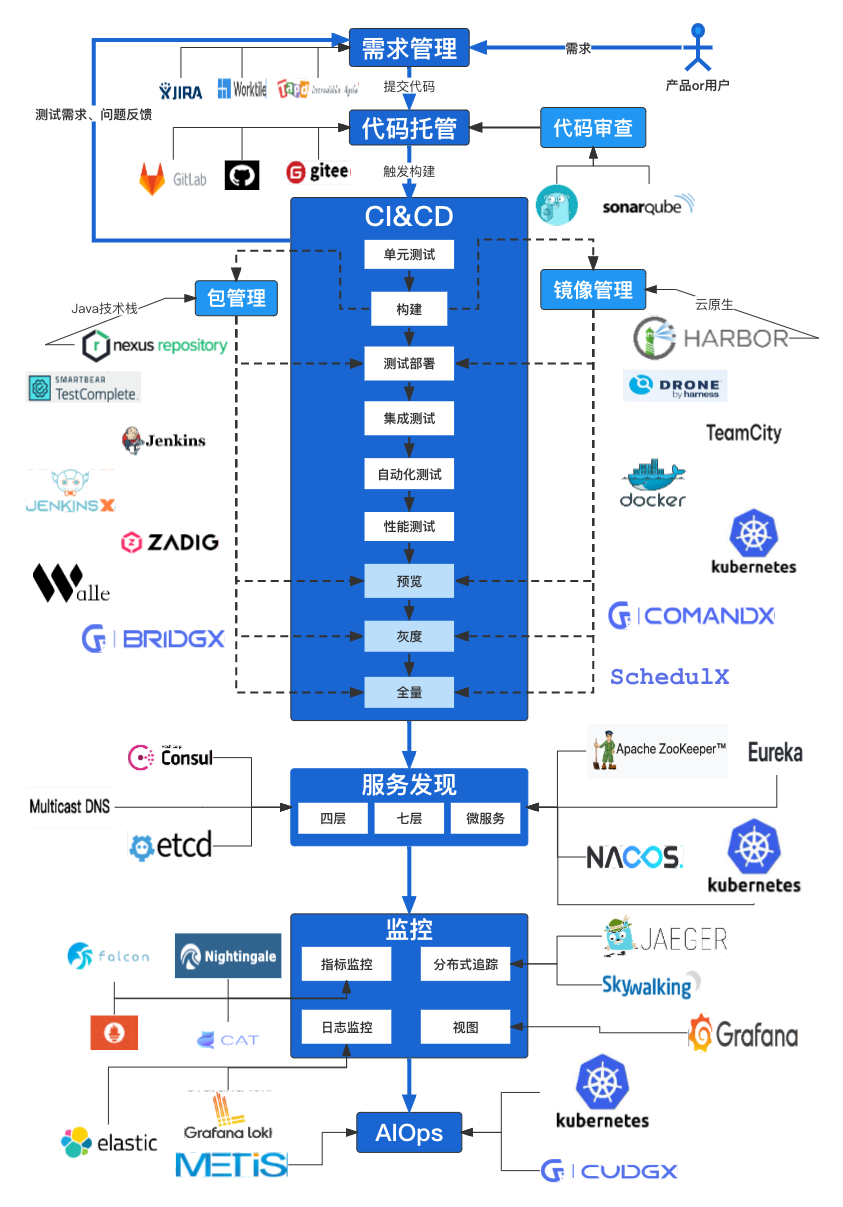
当我们站起身来环顾世界,Google 作为技术界风向标,正在通过大库寻找工程的稳重和灵活的平衡点,Github Actions 正在通过代码驱动持续集成,而 K8s 社区正在努力探索 IaC 的可行性。未来的世界一切皆为代码驱动,元宇宙正在向我们走来,而这一切都要基于一套易用好用且可靠的基础设施,来帮助未来的工程师们高效研发。
四、研发基础设施
何谓基础设施,类比于生活中的水电煤,美好的生活离不开这些现代化的设施,但每个人都已经习以为常他们的存在,甚至感知不到这些设施在生活中的重要性。而研发基础设施也正是要向这样的方向努力。
过去 20 年间,与研发效能相关的工具很多,但平台其实寥寥无几。往往也只有大型软件公司才能够自建配套的基础设施体系,提供从需求到编码再到发布上线的全套辅助。作坊式的小企业,大多通过人工伺服软件工程的开发流程。所以在 2015 年前的阿里巴巴,虽然 Aone 不算好用,但毕业的同学大多会在别的公司怀念 Aone。
直到虚拟技术的发展,K8s 的出现,终于打破了大公司才能拥有自己的发布体系的神话,即使是小作坊,也可以快速搭建一套符合自身业务特点的发布管控平台。发布运维的门槛在软硬件的配套发展下,也最终臣服于工程师的脚下。而恰恰在过去的 5 年时光里,我司的 CICD 体系却因为种种原因停滞不前,错过了最好的发展时机。然而一切并未太晚,我们引以为傲的数万工程师群体,必将鞭策我们热爱的研发基础设施继续进化,并超越时代。
而好的基础设施,最好是对用户来说是透明的,无感的,丝般顺滑的。这对于深后台类型的基础设施来说,做到对用户无感相对会更容易些,但对于代码仓库、CICD、协作、应用等前台功能为主的研发基础设施来说,优良的体验能够极大的提升工程师的幸福感从而提升研发效率。程序员的日常工作沉浸在其中,代码仓库在评审体验、搜索体验、阅读体验上逐步精进,围绕代码做文章,引入我们想要倡导的代码规范和度量指标,让工程师们能够像享受一杯咖啡一样享受写代码的过程。
而工程师之间的技术探讨、需求沟通,我们可以通过功能极简的工作项体系进行相互之间的协作。到了编码之后,所有工作通过自动化流程实现快速可靠的 CICD,我们需要的是将这些基础设施串联成一个有机的整体,最终还能够通过度量洞察体系来汇总整个集团的效能。
美好的愿景,在波澜壮阔的20年中经常被提起,可以看见的未来,史诗般宏大的工程必将诞生于即将到来的万物互联的智能化时代。当社会的组织与研发的协作在追光灯下同频共舞,开启的必将是更加大气磅礴的人类智慧之光。
曾经的技术梦想在大神的努力下已经成为历史,镌刻在博物馆的石牌上,还有更多理性的憧憬和创新的火花在更加遥远的未来闪耀,静候着年轻的大神们踩过前人的脚印前来捡拾,待若干年后,会有另一位记叙者重新开始漫谈这个世界曾经的辉煌,记录这隶属于人类独有智慧的软件工程。
(附录 Spring 编年史和 Hadoop 编年史可参见原文)
参考链接:https://www.infoq.cn/article/hadoop-ten-years-interpretation-and-development-forecast
本文来自微信公众号:InfoQ(ID:infoqchina),作者:刘星